TICS-411 Minería de Datos
Clase 0: Presentación del Curso
¿Quién soy?


- Alfonso Tobar-Arancibia, estudié Ingeniería Civil pero llevo 9 años trabajando como:
- Data Analyst.
- Data Scientist.
- ML Engineer.
- Data Engineer.
- Terminando mi Msc. y empezando mi PhD en la UAI.
- Me gusta mucho programar (en vivo).
- Contribuyo a HuggingFace y Feature Engine.
- He ganado 2 competencias de Machine Learning.
- Publiqué mi primer paper el año pasado sobre Hate Speech en Español.
- Juego Tenis de Mesa, hago Agility con mi perrita Kira y escribo en mi Blog.
Objetivos del Curso

- Identificar Elementos Claves del Machine Learning (Terminología, Nomenclatura, Intuición).
- Entender como interactúan los algoritmos más importantes.
- Aprender a seleccionar el mejor Algoritmo para el Problema.
- Ejecutar y aplicar algoritmos clásicos de Machine Learning.
- Evaluar el desempeño esperado del Modelo.
Material Complementario


Revolución de los Datos

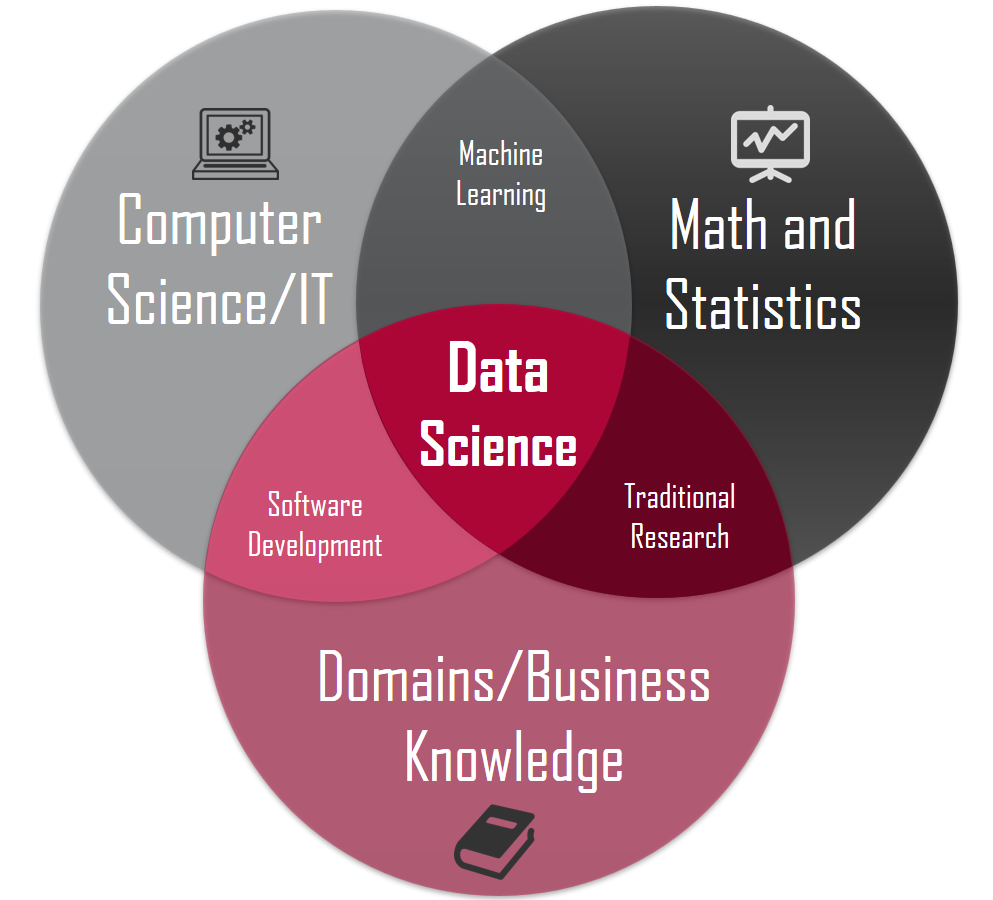
Nace el Data Science (Ciencia de Datos)
Tipos de Datos
Datos Estructurados
Datos No Estructurados




Tipos de Datos: Datos Tabulares
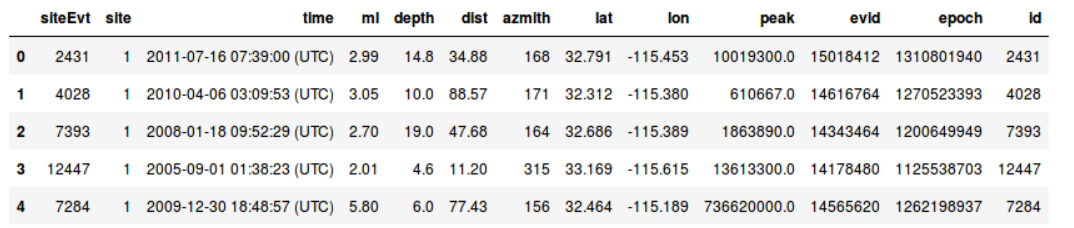
- Filas: Observaciones, instancias, registros. (Normalmente independientes).
- Columnas: Variables, Atributos, Features.
- Probablemente el tipo de datos más amigable.
- Requiere conocimiento de negocio (Domain Knowledge)
- Es un % bajísimo del total de datos existentes en el Mundo. También el que más disponible está en las empresas.
- Distintos
data types, por lo que normalmente requiere de algún tipo de preprocesamiento.
Tipos de Datos: Series de Tiempo
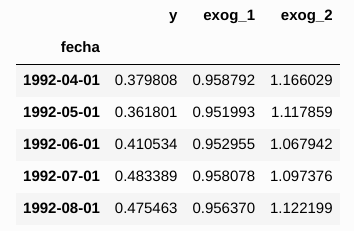
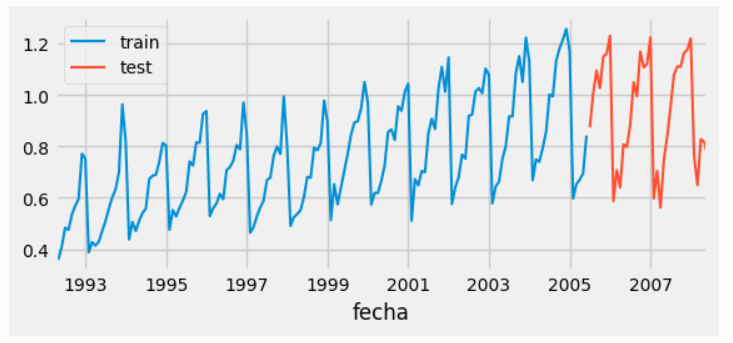
- Filas: Instancias temporales (Normalmente interdependientes).
- Columnas: Variables, Atributos, Features (Univariada o Multivariada).
- Es un % bajísimo del total de datos existentes en el Mundo.
- Propiedad temporal requiere preprocesamiento y modelos especiales.
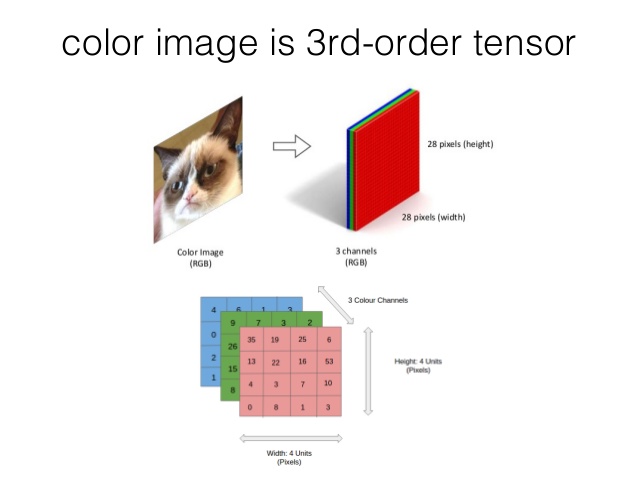
Tipos de Datos: Imágenes

- Este es el tipo de Datos que disparó la Inteligencia Artificial.
- ¿Cuántos computadores para identificar un Gato? 16,000
Tipos de Datos: Texto Libre

- Datos Masivos.
- Dificiles de lidiar ya que deben ser llevarse a una representación numérica.
- Alto nivel de Sesgo y Subjetividad.
- Gracias a este tipo de datos se han producido los avances más increíbles del último tiempo: Transformers
Tipos de Aprendizaje
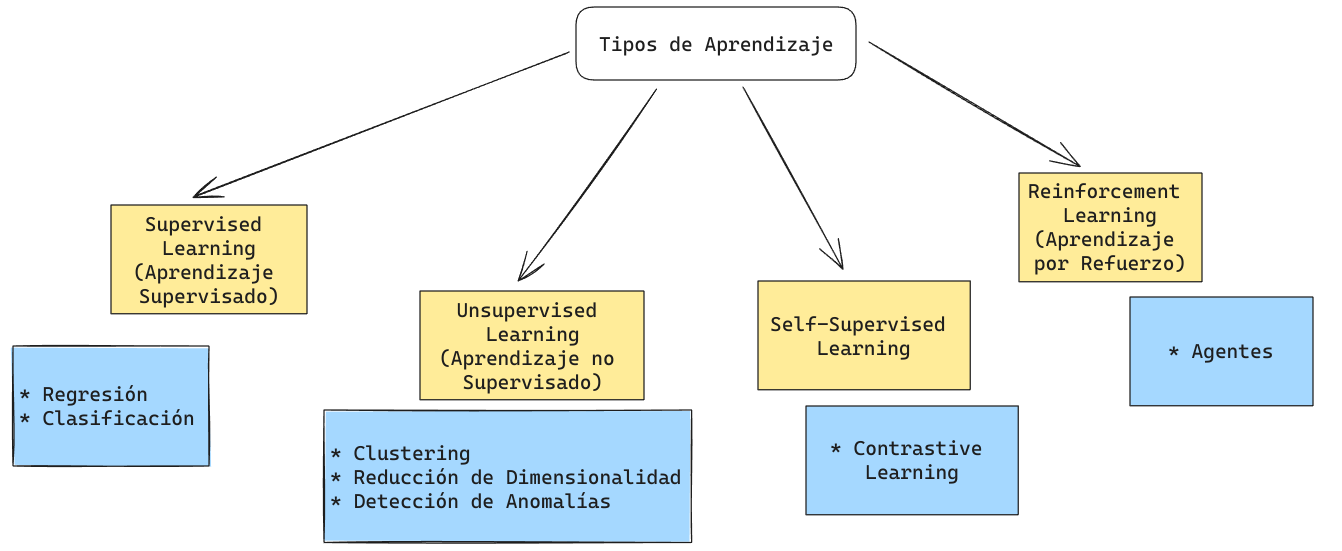
Reinforcement Learning




En este tipo de aprendizaje se enseña por refuerzo. Es decir se da una recompensa si el sistema aprende lo que queremos.
Si el premio es mayor, se pueden obtener aprendizajes mayores.
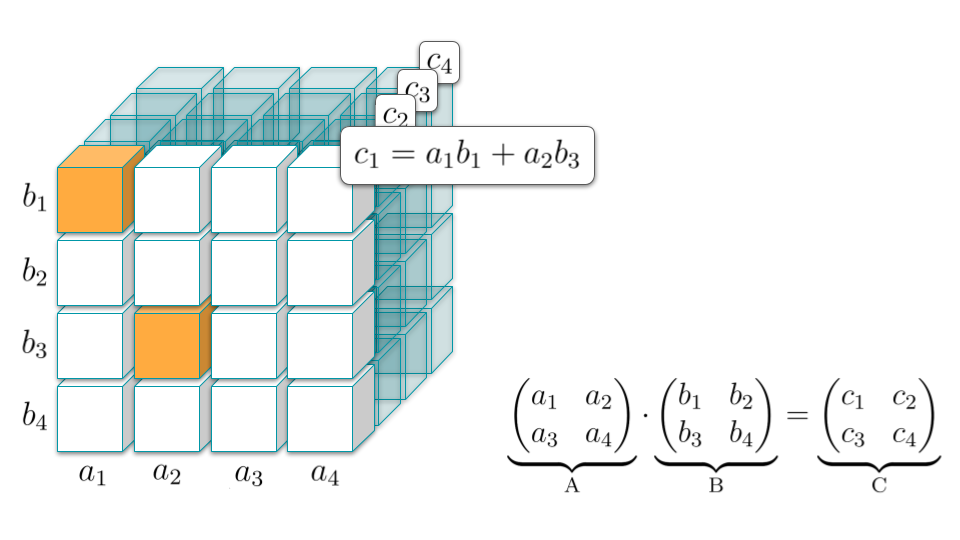
Un ejemplo de esto es AlphaTensor en el cual un modelo aprendió una nueva manera de multiplicar matrices que es más eficiente.
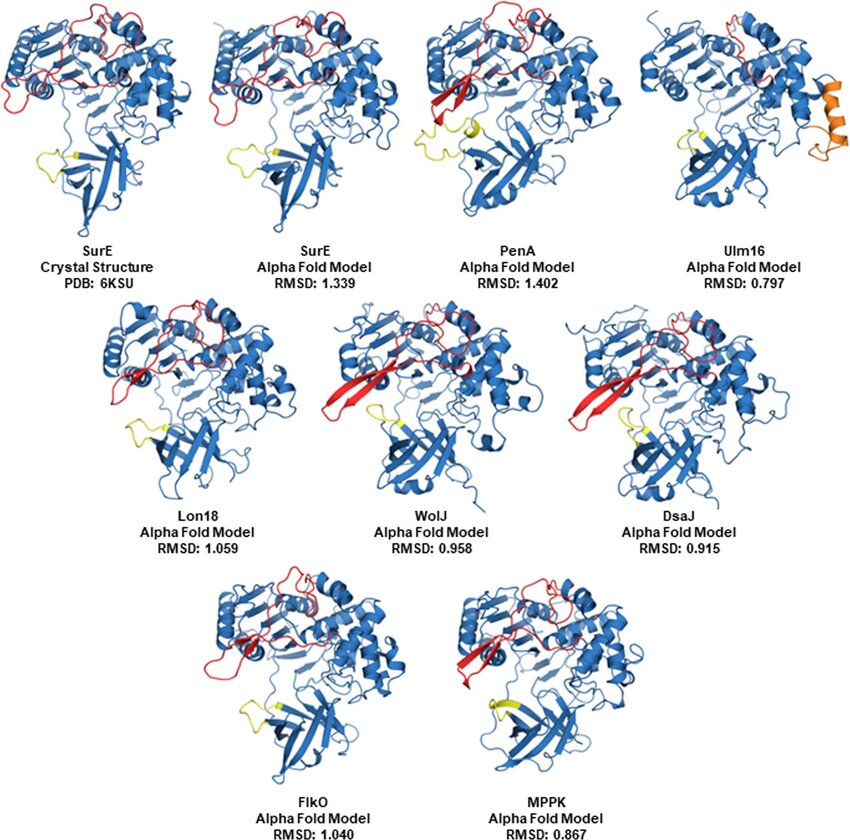
Otro ejemplo es AlphaFold donde el modelo aprendió/descubrió cómo se doblan las proteínas cuando se vuelven aminoácidos.
Problemas Supervisados: Regresión y Clasificación
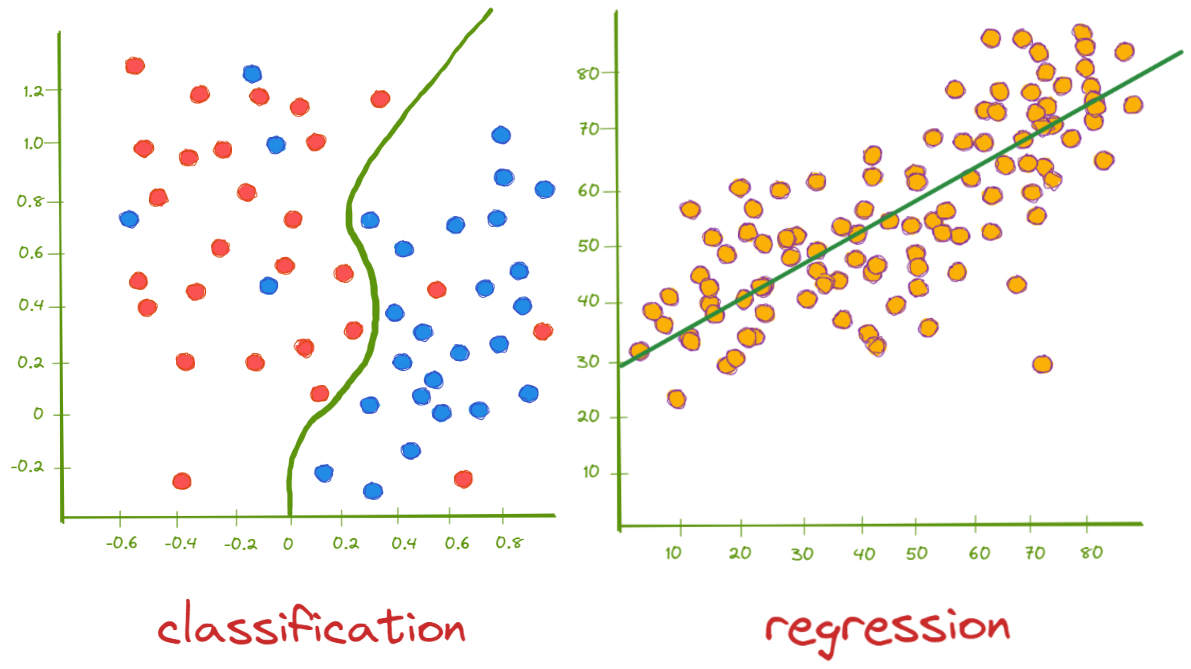
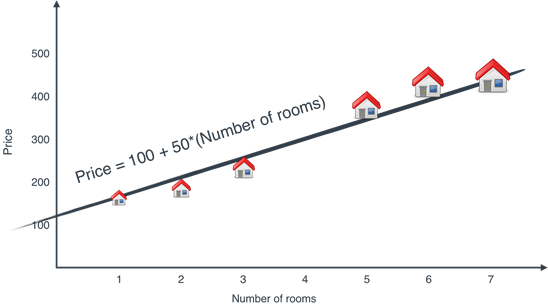
- Regresión: Se busca estimar un valor continuo.
(Estimar el valor de una casa).
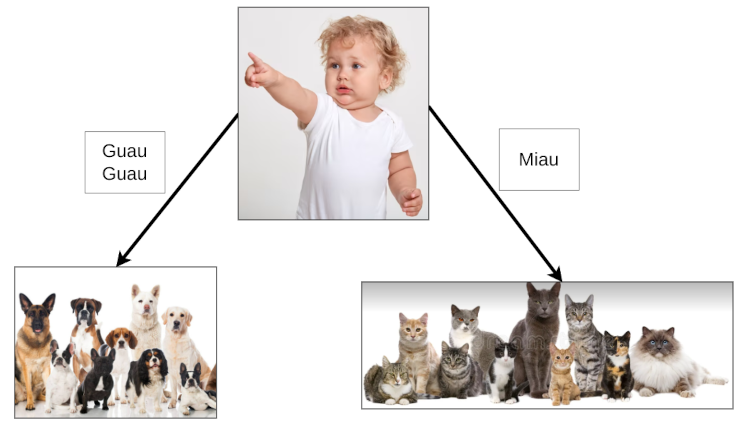
- Clasificación: Se busca encontrar una categoría o un valor discreto.
(Clasificar una imagen como Perro o Gato).
- Para entrenar este tipo de modelos se necesitan
etiquetas, es decir, la respuesta esperada del modelo.

Clustering
- Clusters: Una categoría en la que sus componentes son similares. Los clusters normalmente no tienen un nombre propio, sino que uno les asigna uno.
- También se les llama segmentos. No usar la palabra
clase.
- No requiere de etiquetas, por lo tanto, no es posible evaluar su desempeño de manera 100% acertada.
Reducción de Dimensionalidad
- Reducción de la Dimensionalidad: Eliminar complejidad sin perder información clave para poder entender su comportamiento.
Nuestro Sistema de ML
Creemos un Sistema de ML que sea capaz de ver una imágen y pronunciar correctamente el uso de la letra C.
Vamos a Entrenar un Modelo.
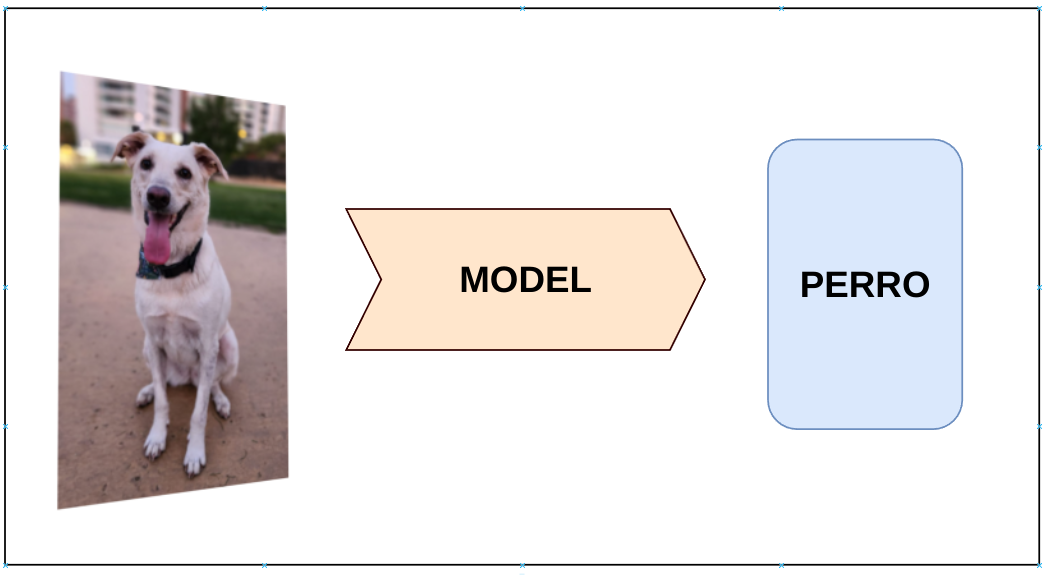
Nuestro Sistema de ML: Entrenamiento

Kasa
Kokodrilo
Kubo¿Qué patrones está aprendiendo el modelo?
- Entrenamiento
-
Es el proceso en el cuál se permite al modelo aprender. En este proceso se le entregan ejemplos (
Train Set) para que el modelo de maneraautónomapueda aprenderpatronesque le permitan resolver la tarea dada.
Nuestro Sistema de ML: Inferencia
- Inferencia/Predicción
-
Se refiere al proceso en el que el modelo tiene que demostrar cuál sería su decisión de acuerdo a los patrones aprendidos en el proceso de entrenamiento. Los ejemplos en los que se prueba se le denomina
Test Set.




Kollar
Konejo
Kukillo
Bikikleta
- Generalización
-
Se le llama generalización a la capacidad del modelo de aplicar lo aprendido de manera correcta en ejemplos no vistos.
Nuestro Sistema de ML: Nuevas instancias de Entrenamiento
Kuchillo
Chokolate
SinselNo es bueno entrenar con las mismas instancias de de Test, es decir, con las cuales se evalúa el modelo. ¿Por qué?
Nuestro Sistema de ML: Reevaluemos nuestro Modelo
Kollar
Konejo
Kuchillo
Bisikleta
- Evaluación
-
Utilizar una métrica que permita
ponerle notaal modelo.
- 1er Modelo: 2 correctas de 4, es decir 50%.
- 2do Modelo: 4 correctas de 4, es decir 100%.
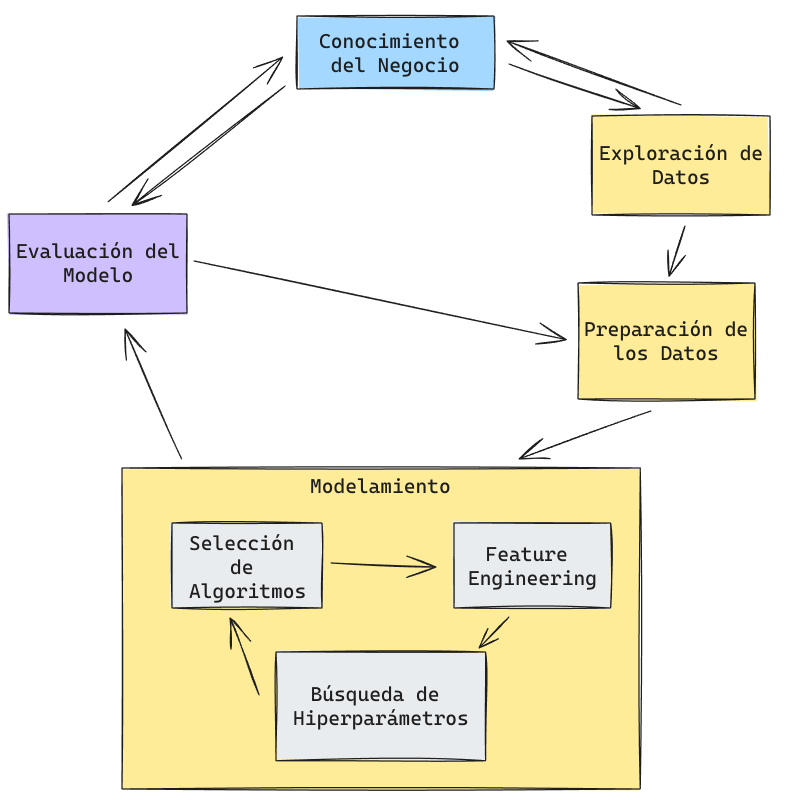
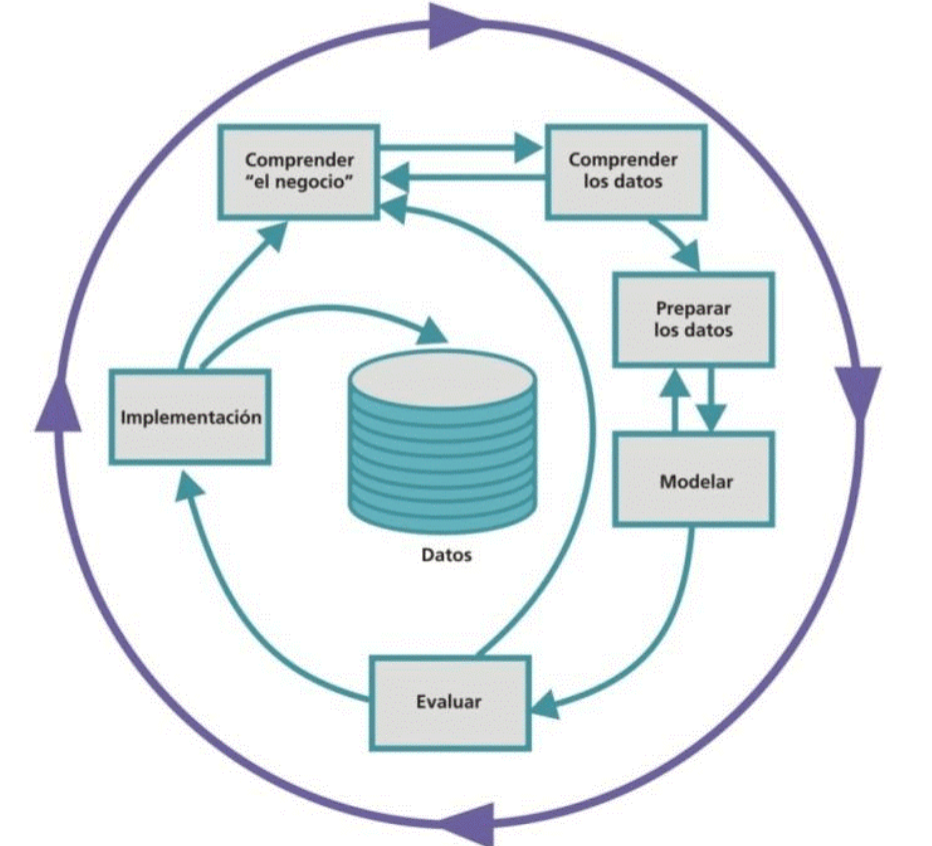
Etapas del Modelamiento: Crisp-DM
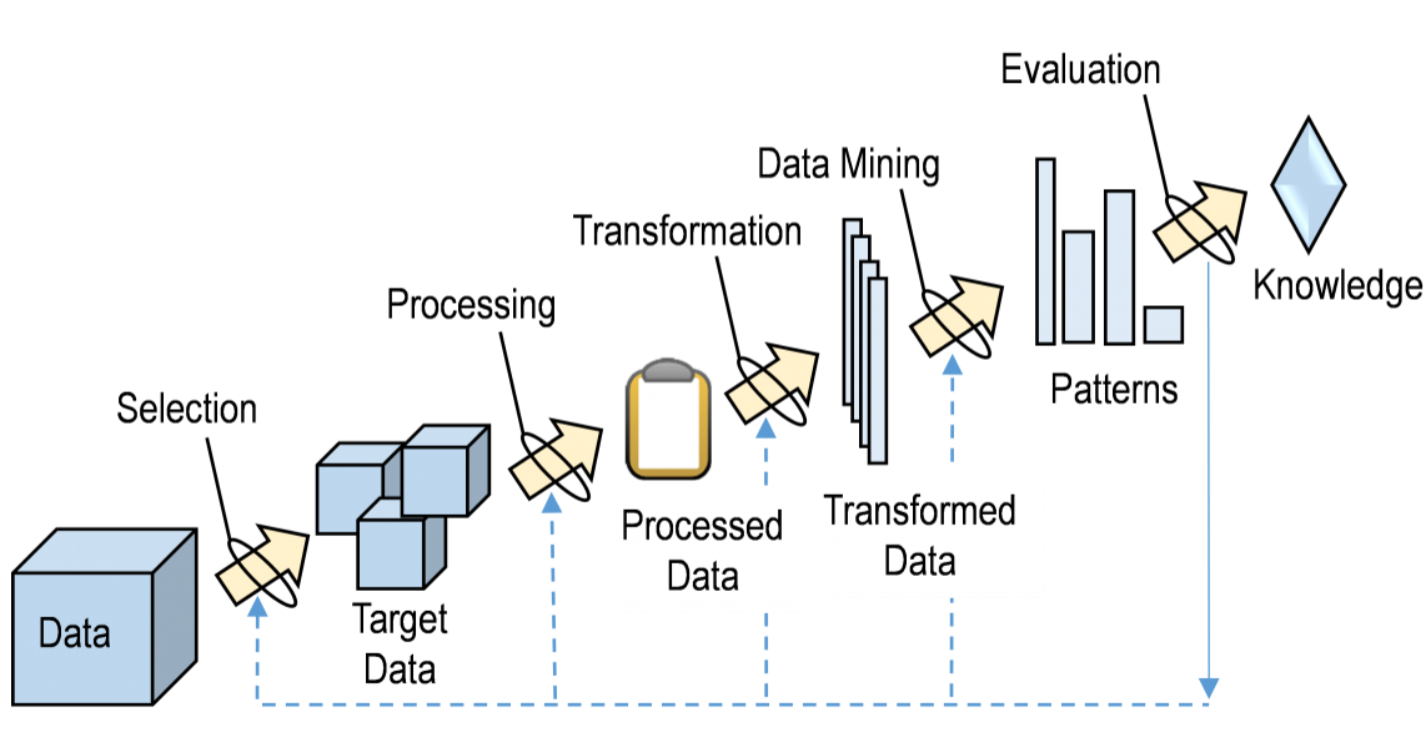
Etapas del Modelamiento: KDD
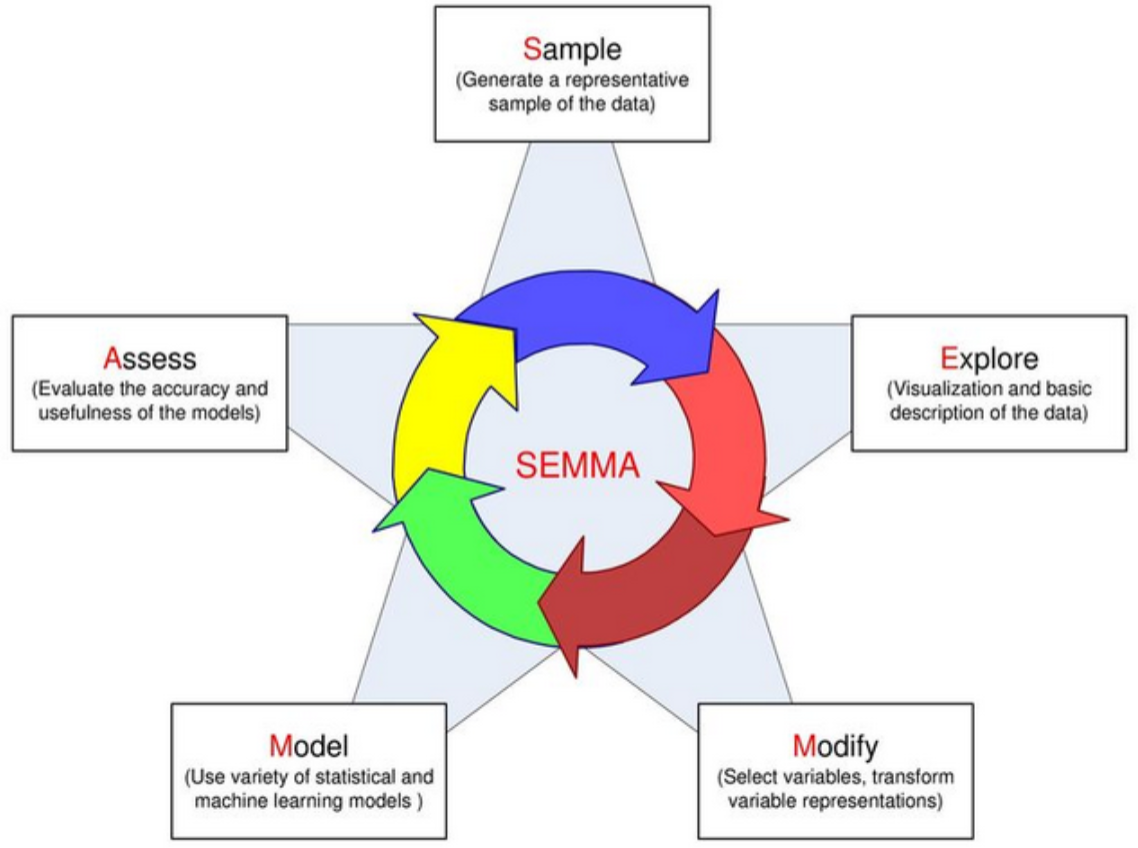
Etapas del Modelamiento: Semma
Etapas del Modelamiento: Metodología Propia