TICS-411 Minería de Datos
Clase 1: Calidad de los Datos y Feature Engineering
Tipos de Datos: Datos Tabulares
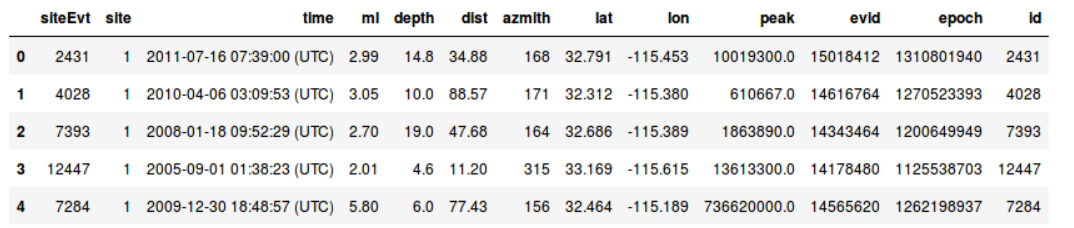
- Filas: Observaciones, registros, instancias. (Normalmente independientes).
- Columnas: Variables, Atributos, Features.
- Probablemente el tipo de datos más amigable.
- Requiere conocimiento de negocio (Domain Knowledge)
- Es un % bajísimo del total de datos existentes en el Mundo.
- Distintos tipos, por lo que normalmente requiere de algún tipo de preprocesamiento.
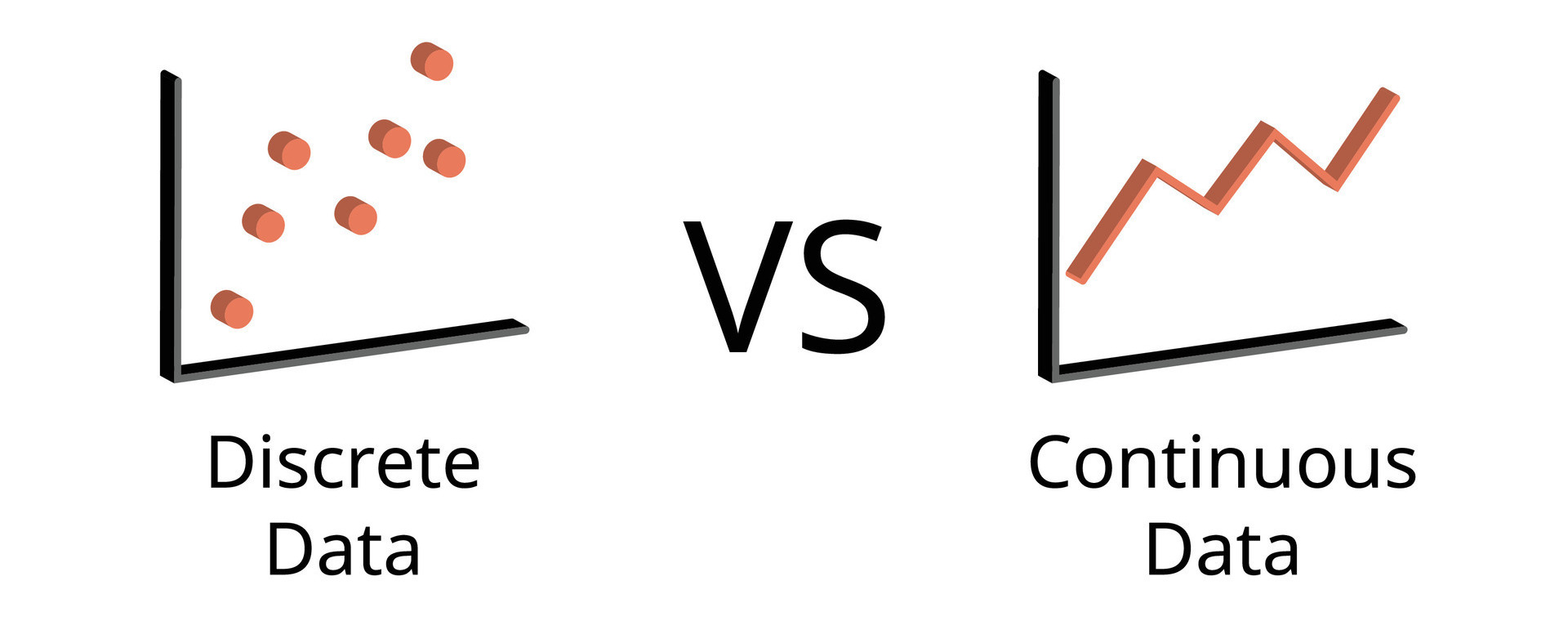
Data Types: Numéricos
- Numéricos
-
Valores a los que se les puede aplicar alguna operación matemática.
- Discretas: Número finito o contable de valores. Integers (Enteros). Ej:
Número de Hijos,Cantidad de Productos,Edad. - Continuas: Existen infinitos puntos entre dos puntos. Floats (punto flotando o decimales). Ej.
Temperatura,Peso.
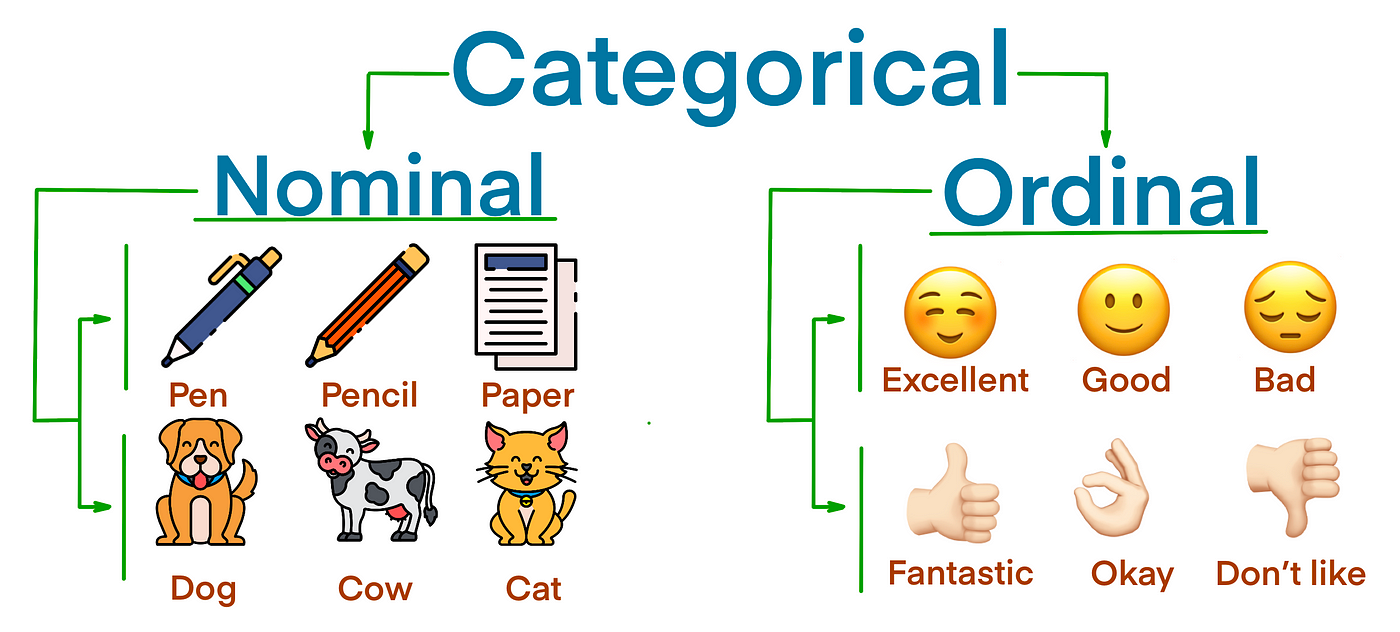
Data Types: Categóricos
- Categóricos
-
Datos que representan una categoría.
- Nominales: Sólo nombres que no representan ningún orden. Ej:
Nacionalidad,género,ocupación. - Ordinales: Que tienen un orden o jerarquía inherente. Ej:
Nivel de Escolaridad,tamaño.
No todas las operaciones matemáticas son aplicables. Ej: Media, Mediana, Sumas, Restas, etc.
Calidad de los Datos: Ruido
- Ruido
- Corresponde al error y extrema variabilidad en la medición en los datos. Este error puede ser aleatorio o sistemático.
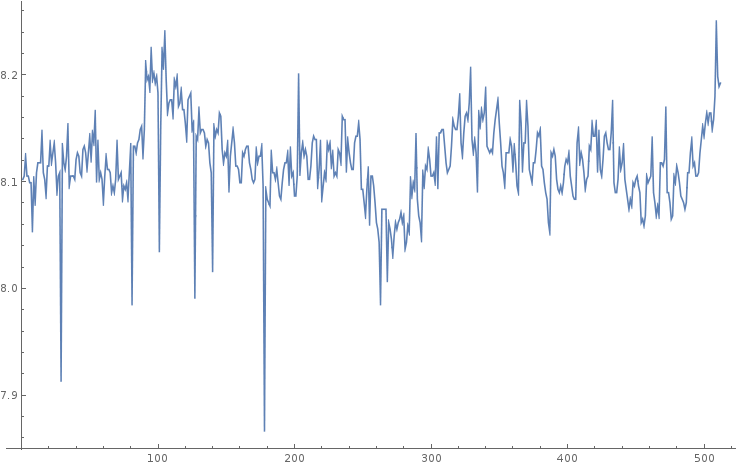
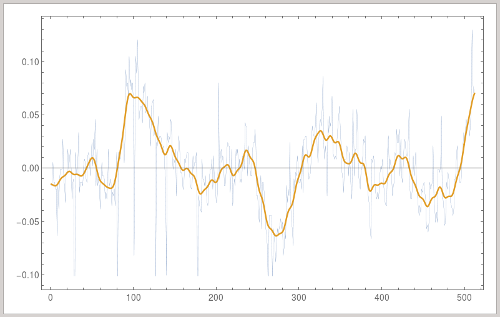
Se le llama Señal a la tendencia principal y representa la información significativa y valiosa de los datos.
Calidad de los Datos: Outliers
- Outliers
-
Son datos considerablemente diferentes a la mayoría del dataset. Dependiendo del caso pueden indicar casos
"interesantes"oerrores de medición.
- Es importante notar que dependiendo del caso puede ser una buena idea deshacerse de ellos. ¿En qué casos podría no ser necesario eliminarlos?
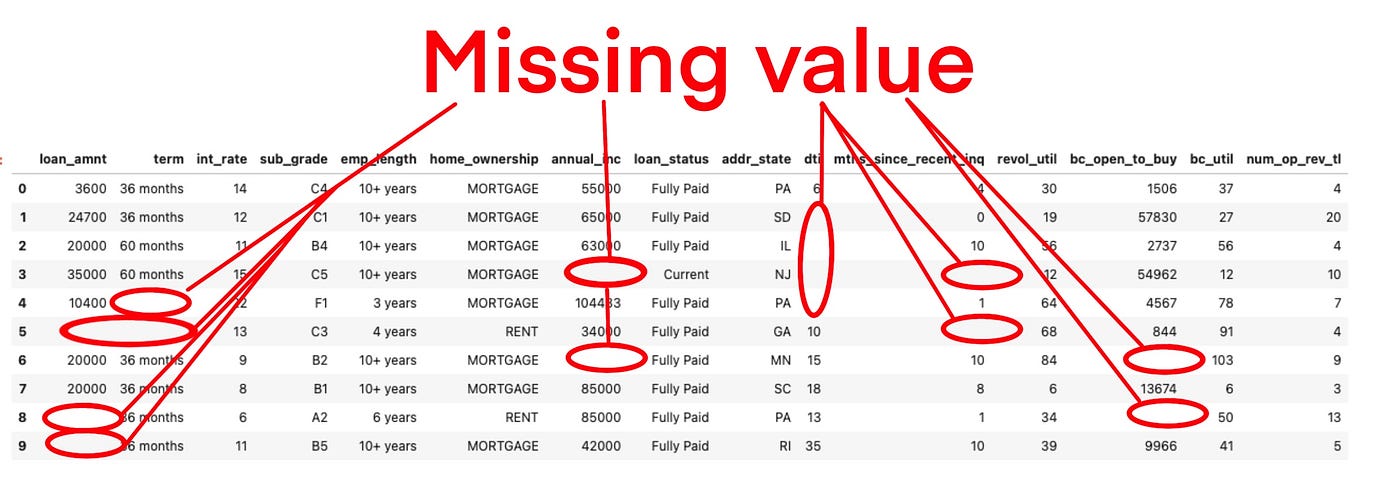
Calidad de los Datos: Valores Faltantes
- Missing Values
-
Son valores que por alguna razón no están presentes.
Missing at Random (MAR): Son valores que no están presentes por causas que no se pueden controlar. Ej: No se registró, no se preguntó, fallas en el sistema de recolección de datos, etc.
Informative Missing: Es un valor no aplicable. Ej: Sueldo en niños, Precio de la entrada de un concierto si es que NO compró entrada.
Calidad de los Datos: Datos Duplicados
- Duplicates
- Se refiere a registros que pueden estar total o parcialmente duplicados.
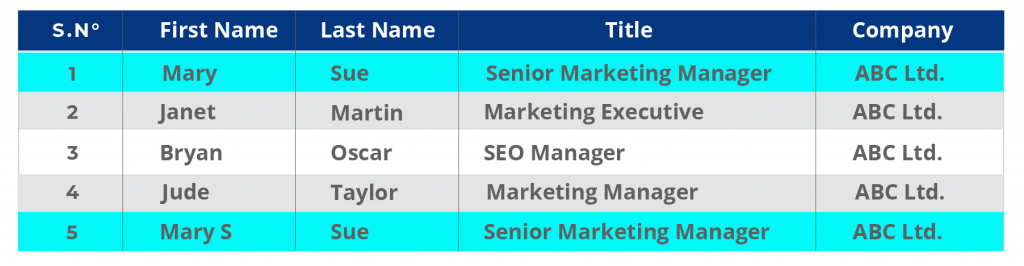
Esto genera problemas en la confiabilidad de los datos. ¿Cuál es el registro correcto?
Ej: Caso particular de una Jooycar (una startup de seguros).
Calidad de los Datos: Dominio del Problema
- Por lejos el problema de calidad más difícil de encontrar.
- Se requiere experiencia y conocimiento profundo del negocio para detectarlo.
Ej: Caso de Super Avances en Cencosud.
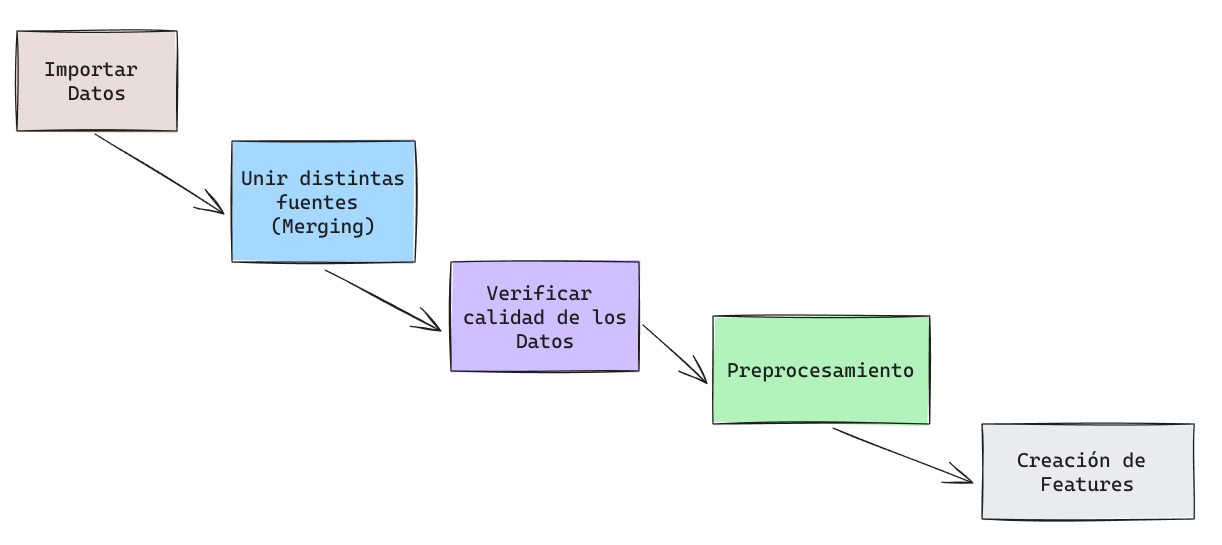
Feature Engineering
- No existe un procedimiento estándar.
- Revisar los datos y ver potenciales errores que puedan afectar el funcionamiento de un modelo.
Preprocesamiento: Valores Faltantes
Imputación: Se refiere al proceso de rellenar datos faltantes.
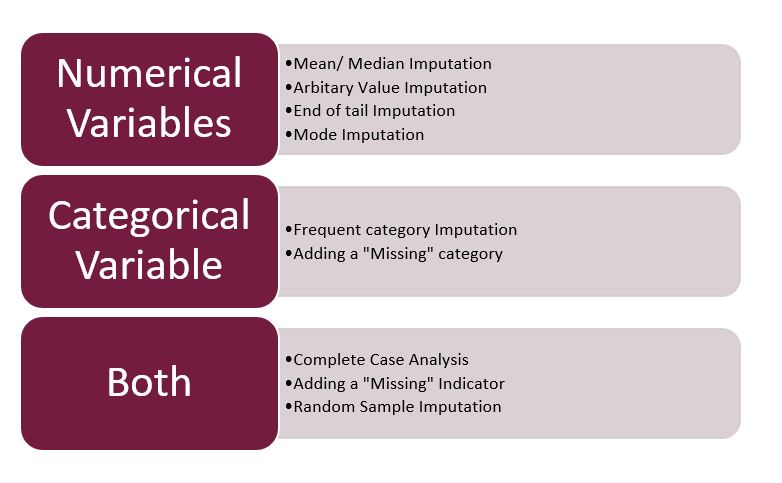

Dependiendo del nivel de valores faltantes, es necesario evaluar la eliminación de registros o atributos completos de ser necesario.
Preprocesamiento: Manejo de Outliers
- Capping
- Se refiere al proceso de acotar un atributo eliminando los valores extremos o atípicos (outliers).
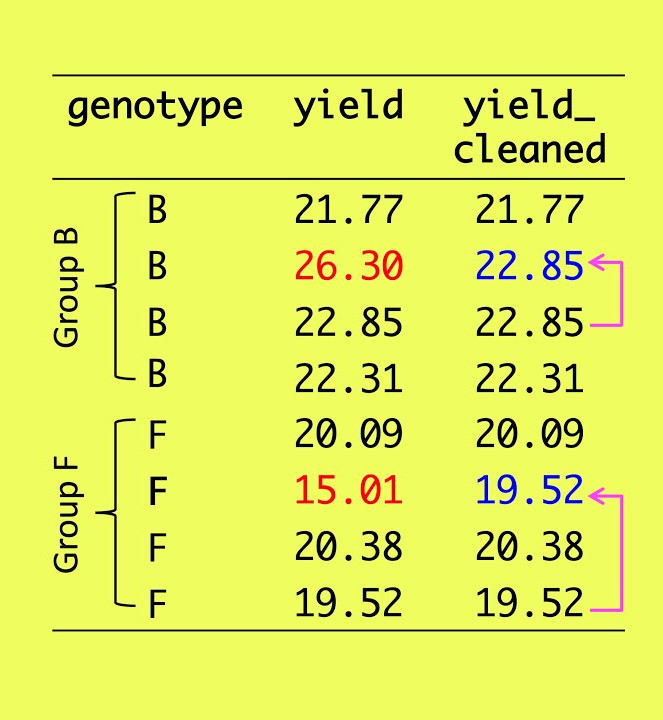
Al igual que en el caso anterior, es necesario evaluar la eliminación de registros si es que representan valores atípicos.
Preprocesamiento: Manejo de Variables Categóricas
La mayoría de los modelos no tienen la capacidad de poder lidiar con variables categóricas por lo que deben ser transformadas en una representación numérica antes de ingresar a un modelo.
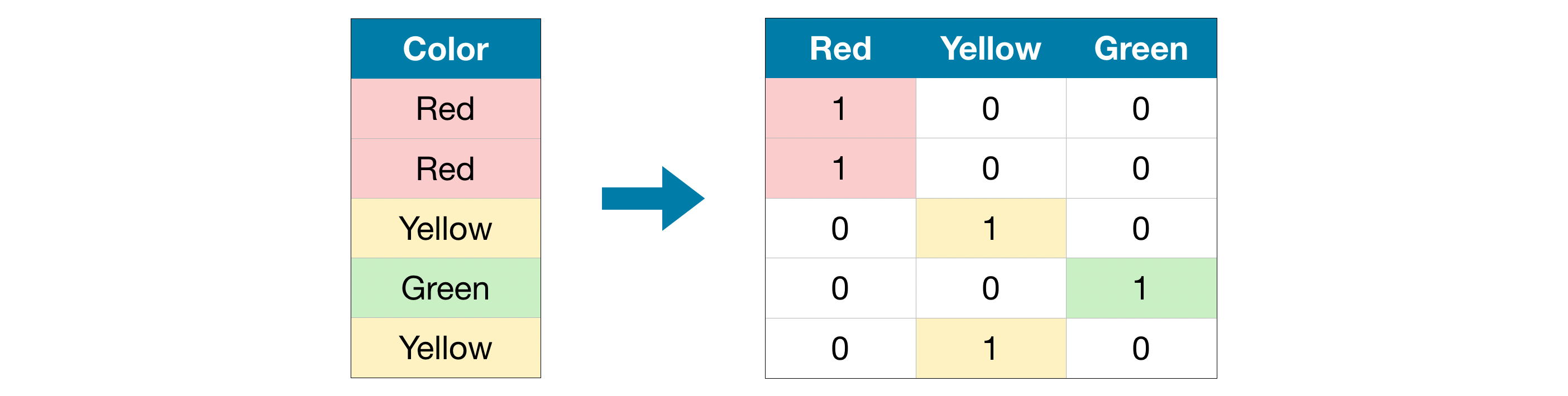
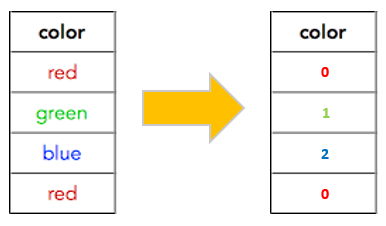
One Hot Encodersuele dar mejores resultados en modelos lineales modelos que dependan de distancias.Ordinal Encodersuele dar mejores resultados en modelos de árbol.
¿Son necesarias todas las columnas en un One Hot Encoder?
Preprocesamiento: Escalamiento
El
escalamientose refiere al proceso de llevar distintas variables a una misma escala.
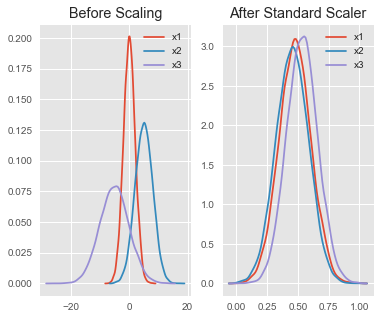
- Evitar que la escala de una “sobre-importancia” a una cierta variable.
- Permitir una mejor convergencia de los algoritmos.
StandardScaler (Normalización)
\[x_j=\frac{x_j-\mu_x}{\sigma_x}\]
- Este proceso fuerza (en la medida de lo posible) a tener media 0 y std 1.
- Notar que \(\sigma_x\) hace referencia a la varianza poblacional.
MinMax Scaler
\[x_j=\frac{x_j-min(x_j)}{max(x_j)-min(x_j)}\]
Este proceso fuerza a los datos a distribuirse entre 0 y 1.
Preprocesamiento: Escalamiento
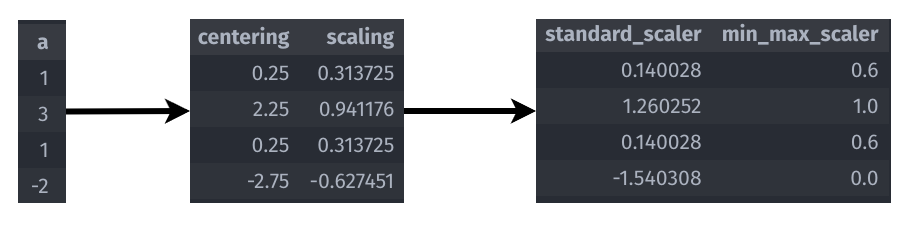
- Media: 0.75
- Std: 3.1875
- Min: -2
- Max: 3
- Centering (Centrado): Se le llama a la diferencia entre la variable y su media.
- Scaling (Escalado): Se le llama al cuociente entre la variable y su Desviación Estándar.
- StandardScaler (Normalización): Es Centrado y Escalado.
Creación de Variables
- Combinación
-
Combinar 2 o más variables. Ej: Calcular el área de un sitio a partir del ancho y largo.
- Transformación
-
Aplicar una operación a una variable. Ej: El logaritmo de las ganancias.
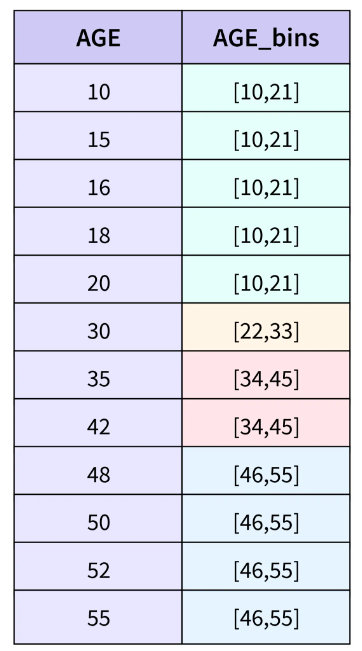
- Discretización (Binning)
-
Generar categorías a partir de una variable continua.
Selección de Variables
Se refiere al proceso de eliminar variables que pueden ser irrelevantes o poco significativas.

- Procesos Manuales.
- Procesos Automáticos:
- PCA (Principal Component Analysis).
- Recursive Feature Elimination.
- Recursive Feature Addition.
- Eliminación mediante alguna medida.
Objetivo
- Puede ser una técnica apropiada para combatir la
Maldición de la Dimensionalidad(Curse of Dimensionality).
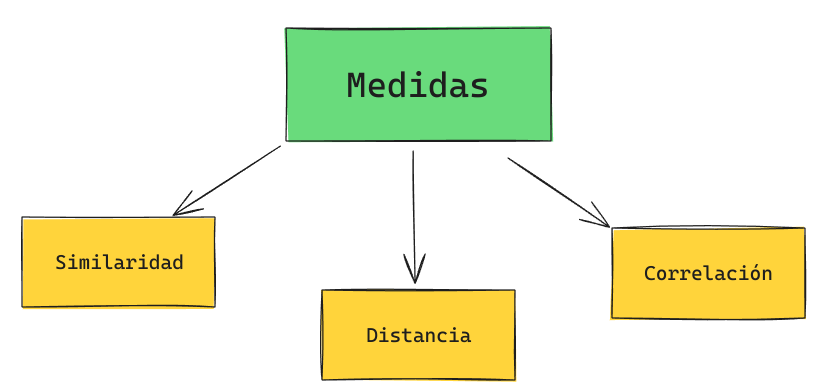
Medidas
Son métricas que permiten cuantificar la relación existente entre dos o más objetos.
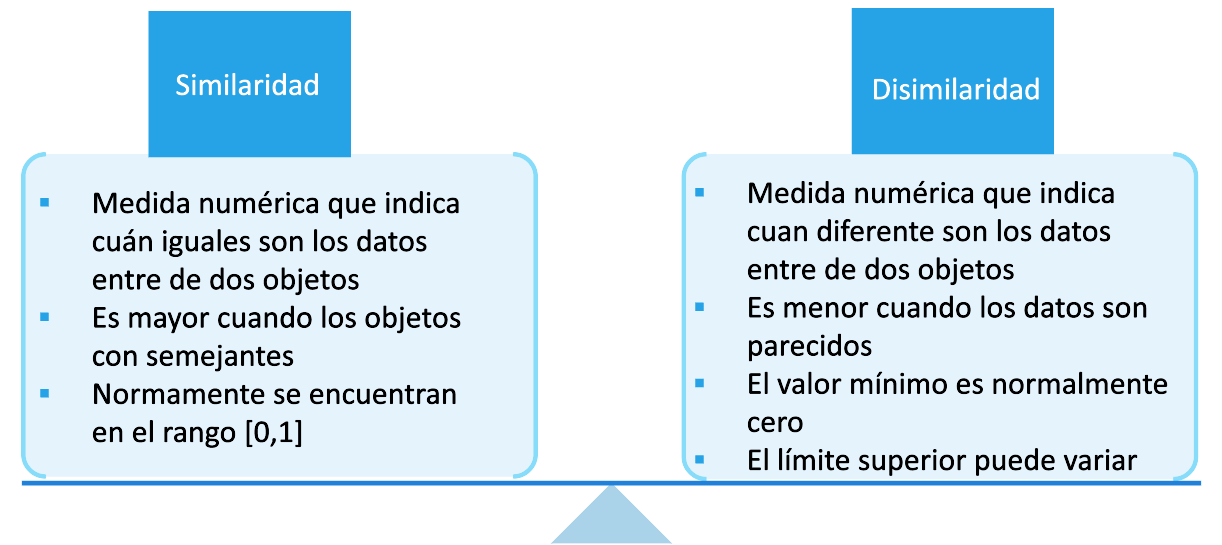
Medidas: Similaridad
Medidas: Similaridad Nominal
- Disimilaridad: \[D = \begin{cases} 0, & \text{if $p=q$} \\[2ex] 1, & \text{if $p\neq q$} \end{cases} \]
- Similaridad:
\[S = \begin{cases} 1, & \text{if $p=q$} \\[2ex] 0, & \text{if $p\neq q$} \end{cases} \]
\[S(p,q) = 0\] \[D(p,q) = 1\]
Medidas: Similaridad Ordinal
- Disimilaridad: \[D = \frac{|p-q|}{n}\]
- Similaridad:
\[S = 1 - \frac{|p-q|}{n}\]

\[S(p,q) = 1 - \frac{5 - 4}{5} = 0.8\]
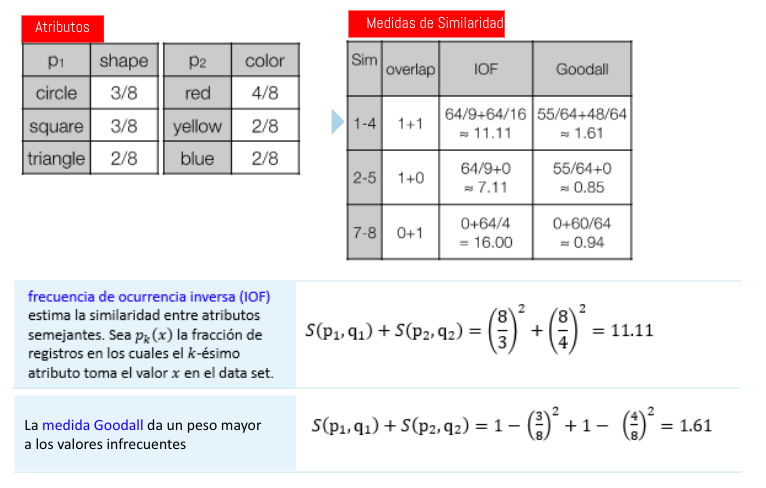
Medidas: Similaridad Datos Categóricos
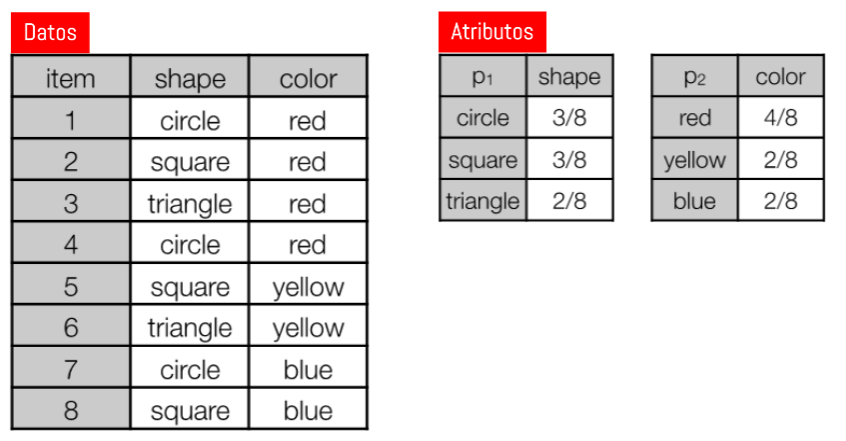
Ejercicio Propuesto: ¿Cuánto vale la similaridad entre los siguientes registros?
- 1-4
- 2-5
- 7-8
Medidas: Similaridad Datos Binarios
Sea
pyqvectores de dimensión \(m\) con sólo atributos binarios. Para calcular la similaridad entre vectores se usa lo siguiente:
\[SMC = \frac{M_{00} + M_{11}}{M_{00} + M_{01} + M_{10} + M_{11}}\]
- Simple Matching Coefficient = Número de Coincidencias / Total de Atributos
\[JC = \frac{M_{11}}{M_{01} + M_{10} + M_{11}}\]
- Jaccard Coefficient = Número de Coincidencias 11 / Número de Atributos distintos de Ceros.

Distancias: Distancia Minkowski
\[d(p,q) = \left(\sum_{k=1}^m |p_k - q_k|^r\right)^{1/r}\]
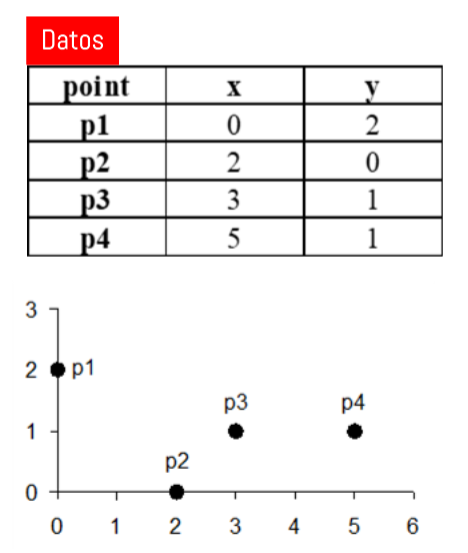
- \(r=1 \rightarrow\) Distancia Manhattan (L1).
- \(r=2 \rightarrow\) Distancia Euclideana (L2).
- \(r=\infty \rightarrow\) Distancia Chebyshev (L\(\infty\)). \[D_{ch}(p,q) = \underset{k}{max} |p_k - q_k|\]
Resolvamos en Colab
- Se denomina
Matriz de Distanciasa la Matriz que contiene la distancia \(d(p_i,p_j)\) en la coordenada \(i,j\).
Distancias: Distancia Minkowski (Resultados)
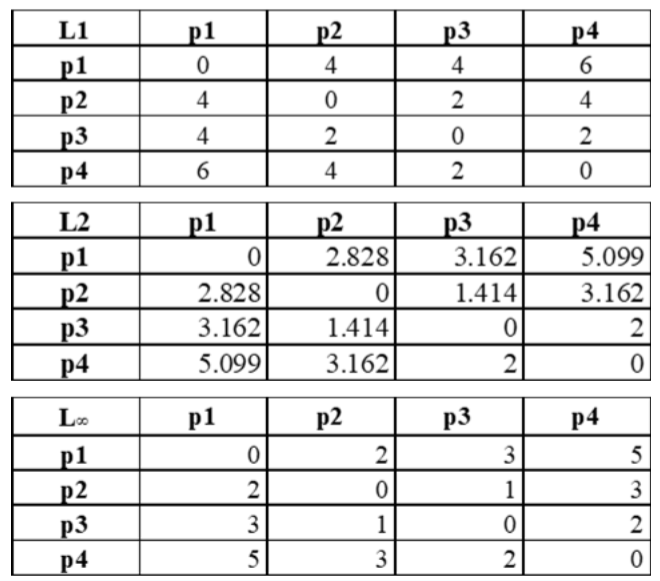
Distancias: Distancia Mahalanobis (Resultados)
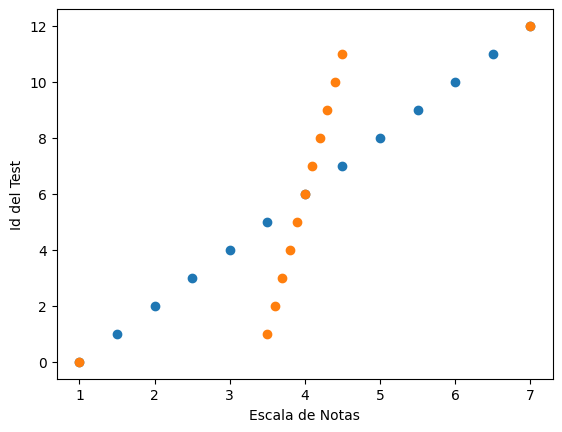
- test #1: \(d(7.0,1.0) = \sqrt{(7-1)\frac{1}{3.79}(7-1)} = 3.08\)
- test #2: \(d(7.0,1.0) = \sqrt{(7-1)\frac{1}{1.59}(7-1)} = 4.76\)
- Es importante notar que la
covarianzaexistente entre los datosinfluye en la distancia.
Correlación
La correlación mide la relación lineal entre 2 atributos.
- Correlación Poblacional
- \[\rho(X,Y) = corr(X,Y) = \frac{cov(X,Y)}{\sigma_X\sigma_Y}\]
- Correlación Muestral o Pearson
- \[r(X,Y) = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i-\bar{y})}{S_xS_y}\]
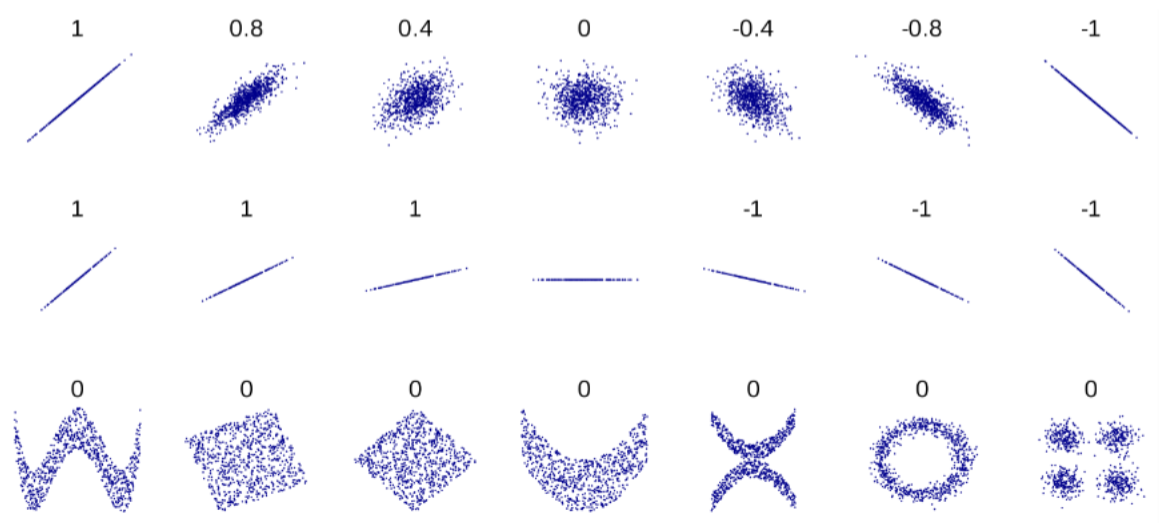
Correlación no es Causalidad
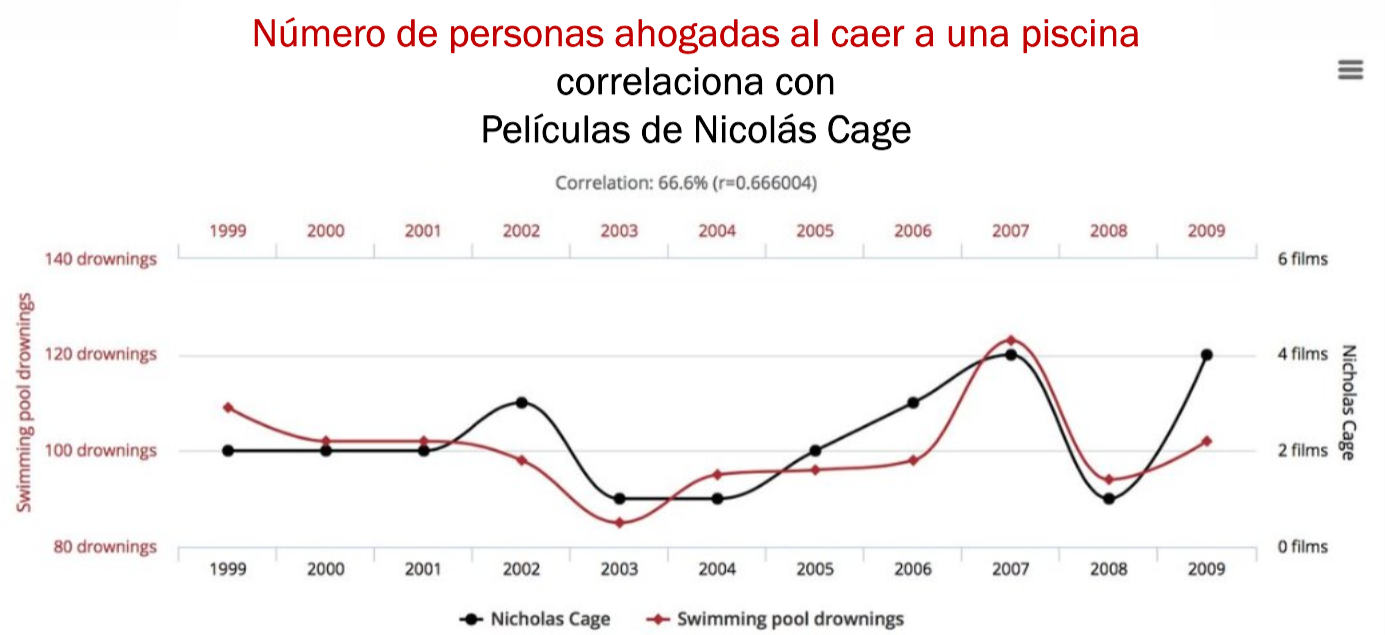
- Es importante recalcar que
Causalidadno es igual aCorrelación. Ver video. - La
Correlaciónno se ve afectada por la escala de los datos.
Danke Schön
Medidas: Similaridad Datos Categóricos