TICS-411 Minería de Datos
Clase 10: Árboles de Decisión
Árboles de Decisión
Técnica de clasificación supervisada que genera una decisión basada en
árboles de decisiónpara clasificar instancias no conocidas.
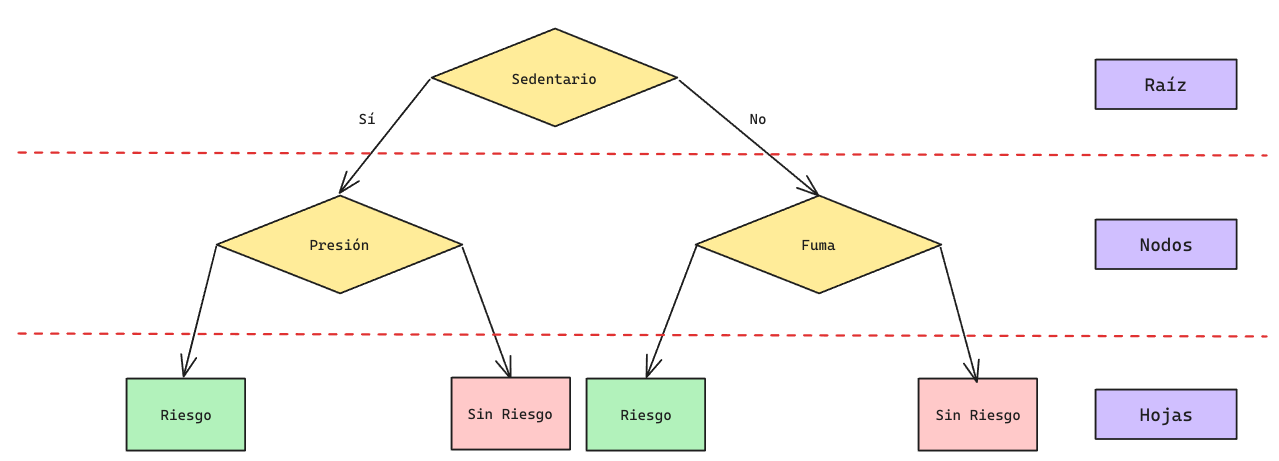
Árboles de Decisión: Ejemplo
Visualmente, un árbol de decisión segmenta el espacio separando los datos en subgrupos.
Esto permite la generacion de fronteras de decisión sumamente complejas.
Supongamos el siguiente ejemplo:
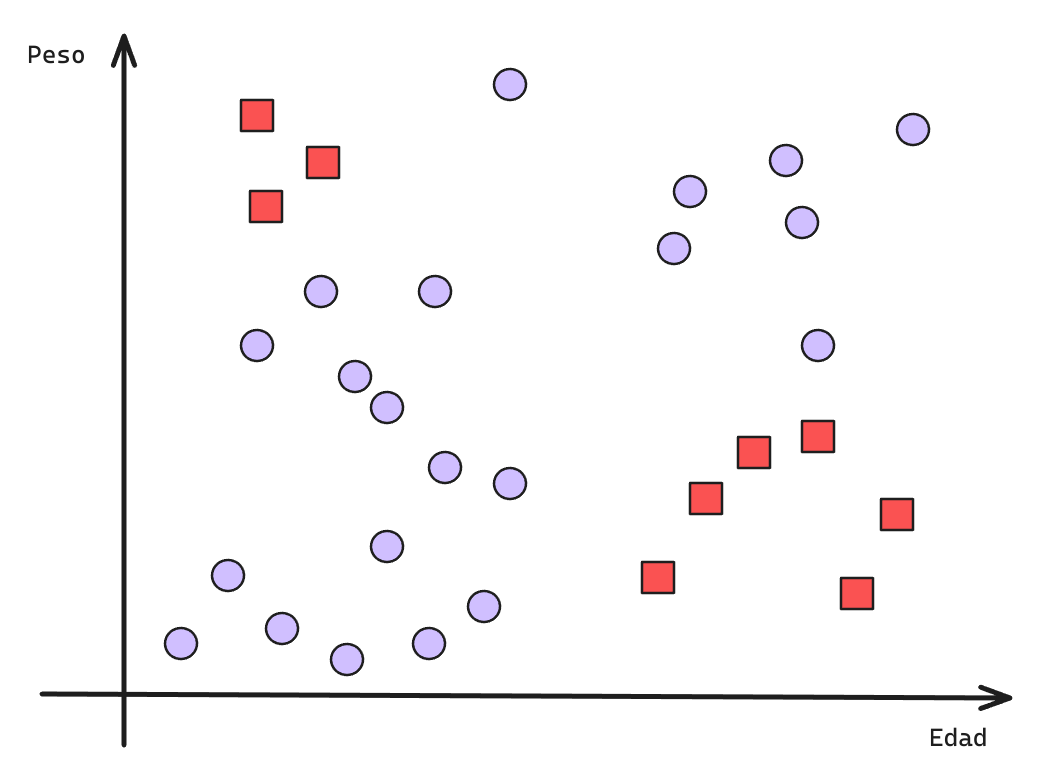
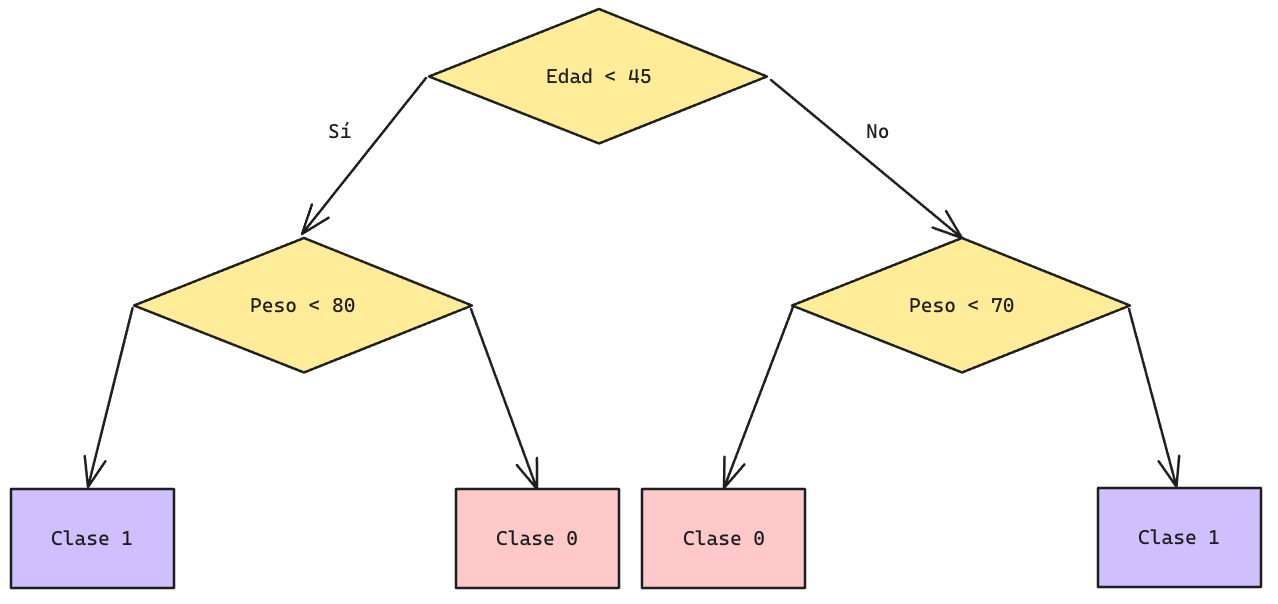
Árboles de Decisión: Frontera de Decisión
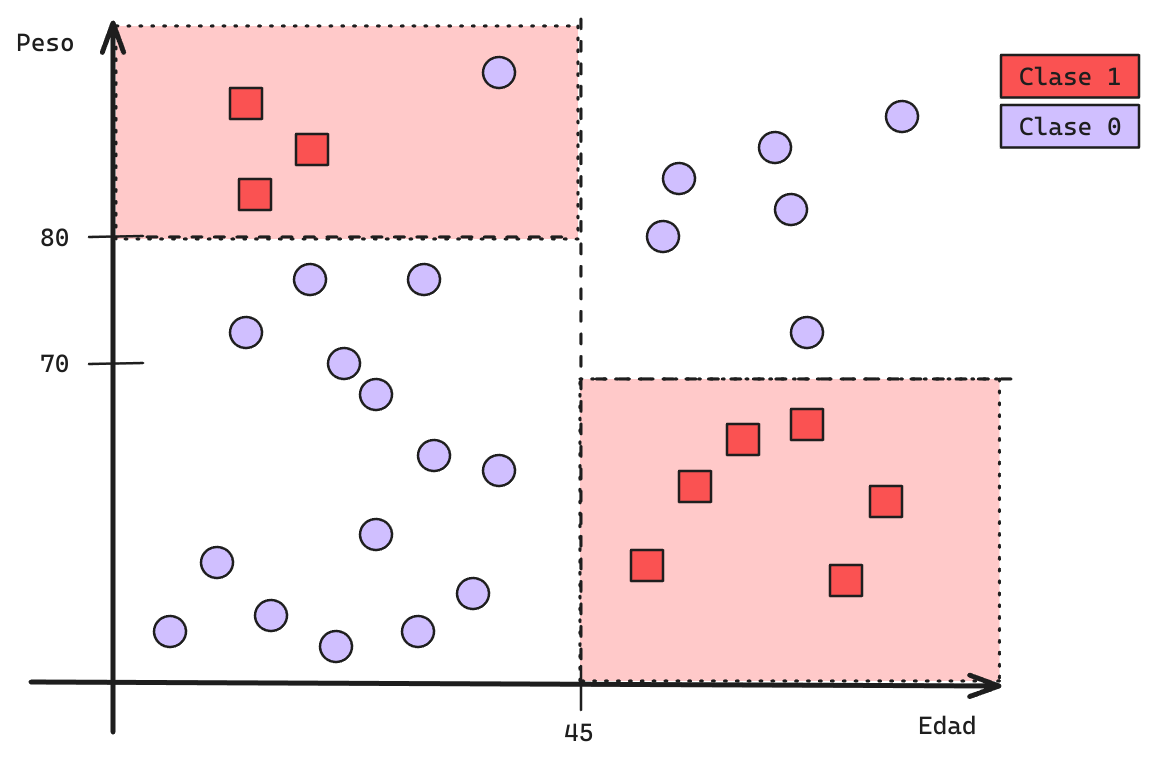
Árboles de Decisión: Frontera de Decisión
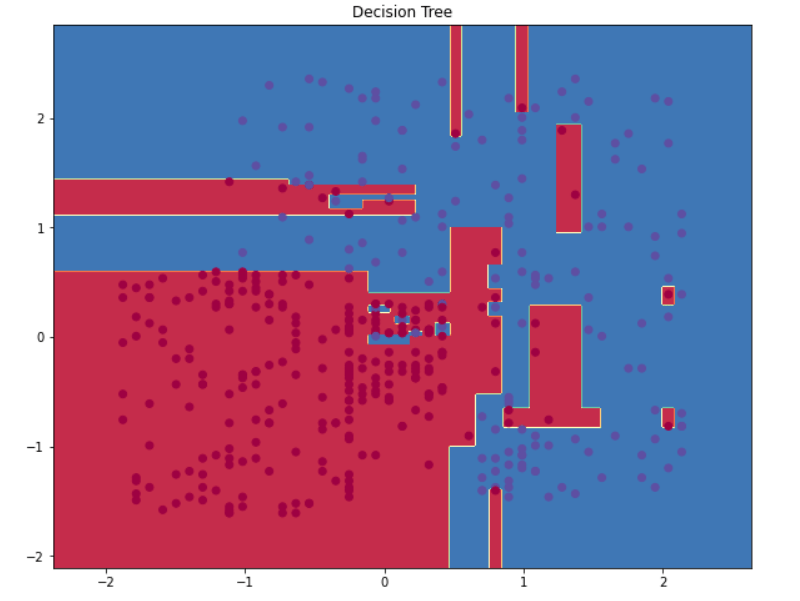
¿Cuál sería el Nivel de Ajuste de un modelo de este tipo?
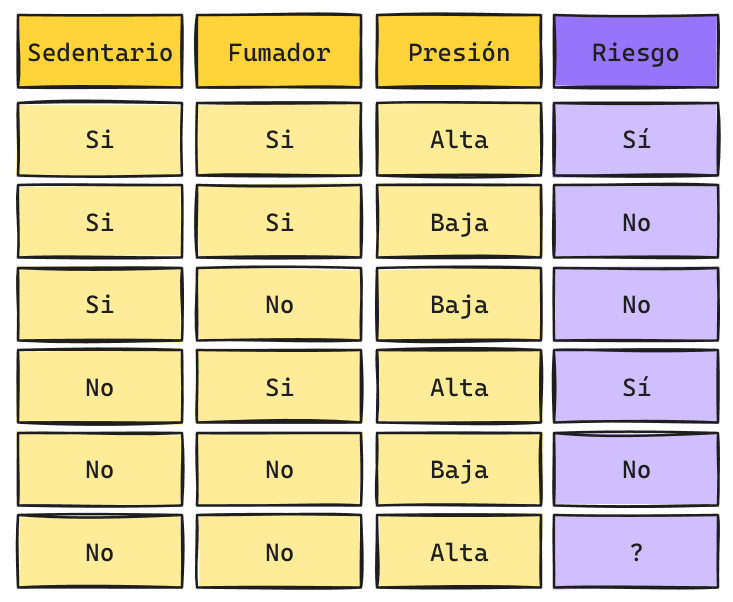
Árboles de Decisión: Inferencia
Una vez construido el árbol de decisión basta con recorrerlo para poder generar la predicción para una instancia dada:
Tipos de Árboles de Decisión
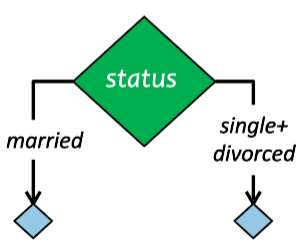
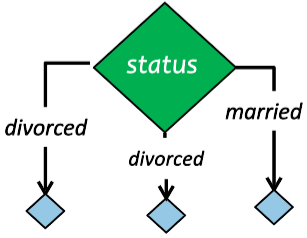
Los CARTs son por lejos los árboles más utilizados en las librerías más famosas y potentes: Scikit-Learn, XGboost, LightGBM, Catboost.
Árbol de Decisión: Ejemplo
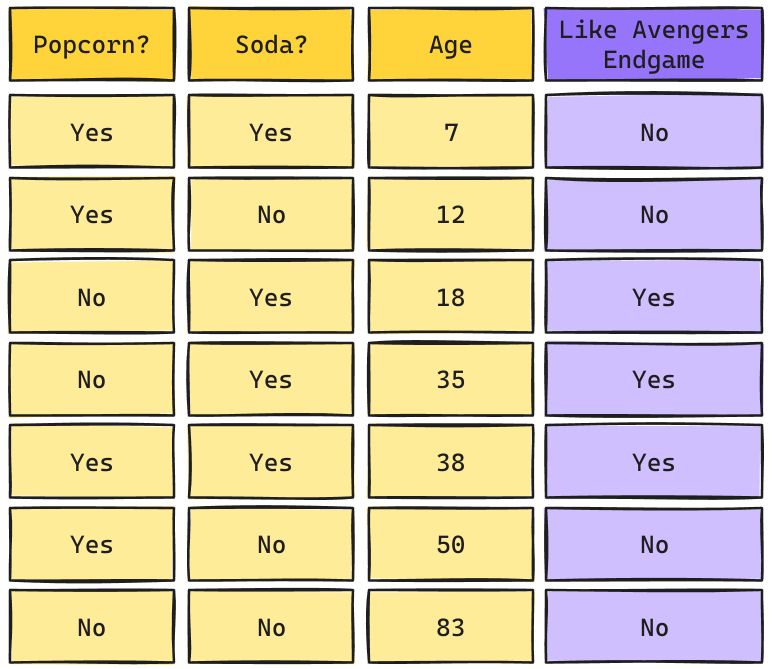
Cálculo de Impureza en Hoja
\[Gini_{(leaf)} = 1 - p(Yes)^2 - p(No)^2\]
Cálculo de Impureza en Split
\[ Gini_{(split)} = \frac{n_{(yes)}}{n} Gini_{(yes)} + \frac{n_{(no)}}{n} Gini_{(no)}\]
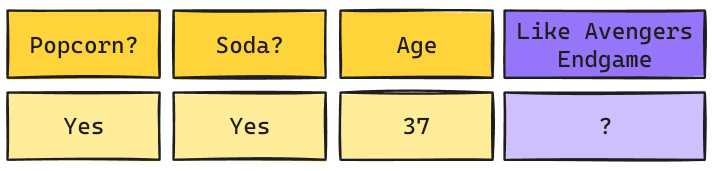
Árbol de Decisión: Raíz Popcorn
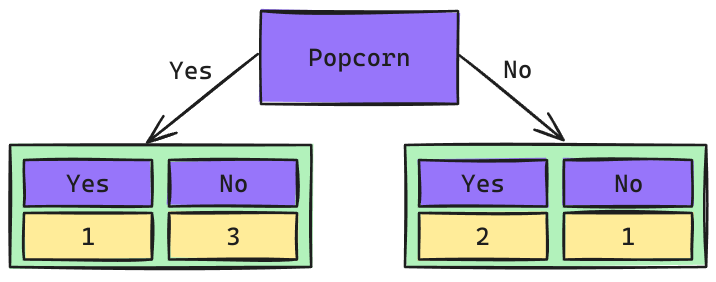
\[Gini_{(yes)} = 1 - \left(\frac{1}{4}\right)^2 - \left(\frac{3}{4}\right)^2 = 0.375\] \[Gini_{(no)} = 1 - \left(\frac{2}{3}\right)^2 - \left(\frac{1}{3}\right)^2 = 0.444\]
Árbol de Decisión: Raíz Soda
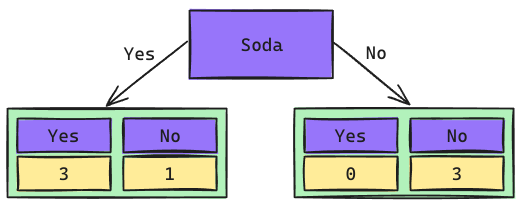
\[Gini_{(yes)} = 1 - \left(\frac{3}{4}\right)^2 - \left(\frac{1}{4}\right)^2 = 0.375\] \[Gini_{(no)} = 1 - \left(\frac{0}{3}\right)^2 - \left(\frac{3}{3}\right)^2 = 0\]
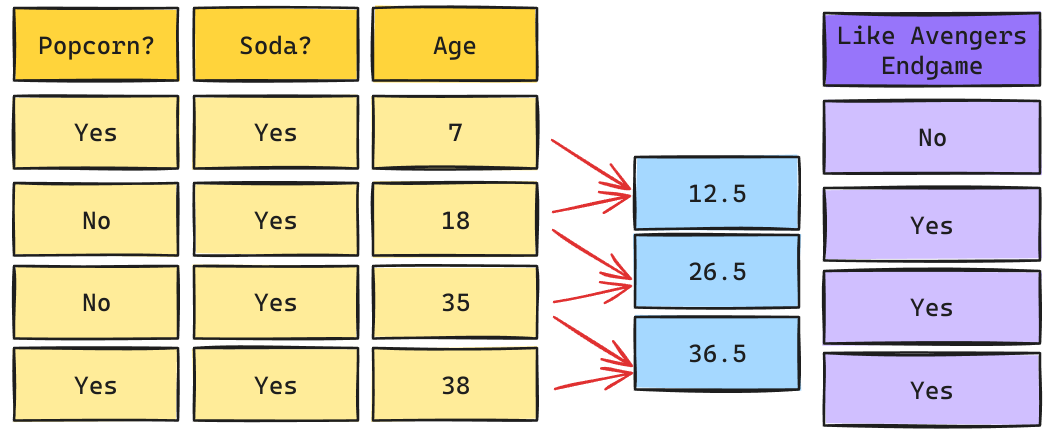
Árbol de Decisión: Raíz Age
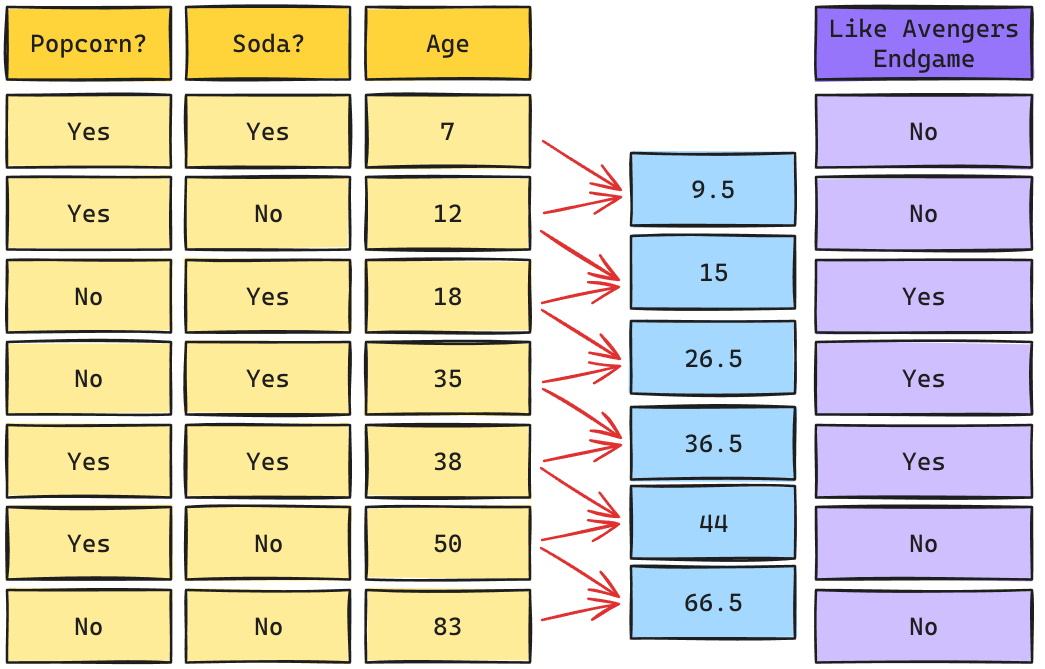
Los cortes de posibles Splits se calculan como el promedio de los valores adyacentes una vez que han sidos ordenados de mayor a menor.
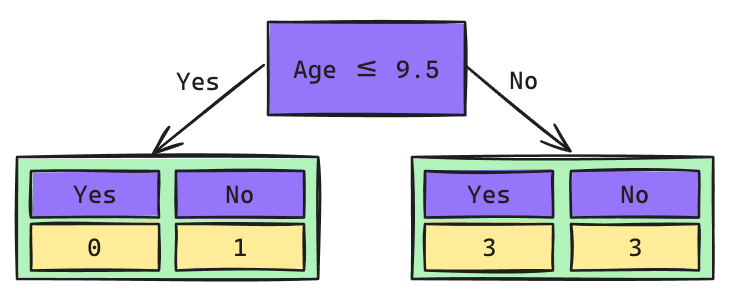
\[Gini_{(yes)} = 1 - \left(\frac{0}{1}\right)^2 - \left(\frac{1}{1}\right)^2 = 0\] \[Gini_{(no)} = 1 - \left(\frac{3}{6}\right)^2 - \left(\frac{3}{6}\right)^2 = 0.5\]
Árbol de Decisión: Raíz Age
Los cortes de posibles Splits se calculan como el promedio de los valores adyacentes una vez que han sidos ordenados de mayor a menor.
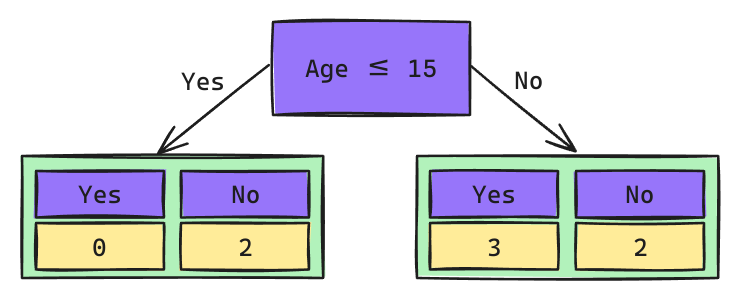
\[Gini_{(yes)} = 1 - \left(\frac{0}{2}\right)^2 - \left(\frac{2}{2}\right)^2 = 0\] \[Gini_{(no)} = 1 - \left(\frac{3}{5}\right)^2 - \left(\frac{2}{5}\right)^2 = 0.48\]
Árbol de Decisión: Raíz Age
Los cortes de posibles Splits se calculan como el promedio de los valores adyacentes una vez que han sidos ordenados de mayor a menor.
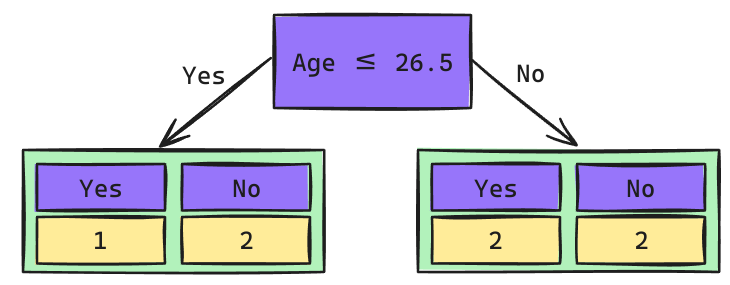
\[Gini_{(yes)} = 1 - \left(\frac{1}{3}\right)^2 - \left(\frac{2}{3}\right)^2 = 0.444\] \[Gini_{(no)} = 1 - \left(\frac{2}{4}\right)^2 - \left(\frac{2}{4}\right)^2 = 0.5\]
Árbol de Decisión: Raíz Age
Los cortes de posibles Splits se calculan como el promedio de los valores adyacentes una vez que han sidos ordenados de mayor a menor.

\[Gini_{(yes)} = 1 - \left(\frac{2}{4}\right)^2 - \left(\frac{2}{4}\right)^2 = 0.5\] \[Gini_{(no)} = 1 - \left(\frac{1}{3}\right)^2 - \left(\frac{2}{3}\right)^2 = 0.444\]
Árbol de Decisión: Raíz Age
Los cortes de posibles Splits se calculan como el promedio de los valores adyacentes una vez que han sidos ordenados de mayor a menor.
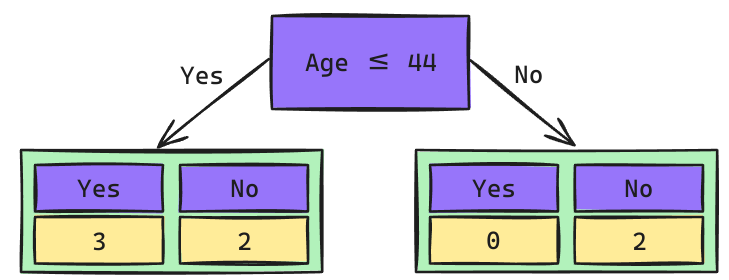
\[Gini_{(yes)} = 1 - \left(\frac{3}{2}\right)^2 - \left(\frac{2}{5}\right)^2 = 0.48\] \[Gini_{(no)} = 1 - \left(\frac{0}{2}\right)^2 - \left(\frac{2}{2}\right)^2 = 0\]
Árbol de Decisión: Raíz Age
Los cortes de posibles Splits se calculan como el promedio de los valores adyacentes una vez que han sidos ordenados de mayor a menor.
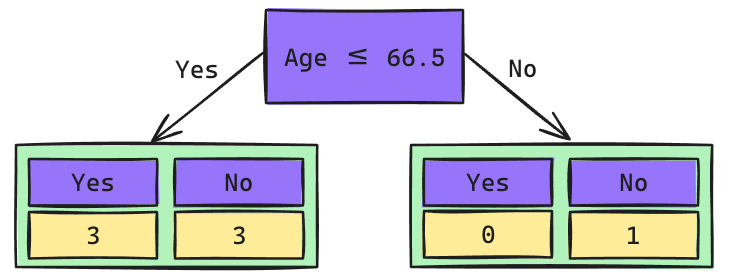
\[Gini_{(yes)} = 1 - \left(\frac{3}{6}\right)^2 - \left(\frac{3}{6}\right)^2 = 0.5\] \[Gini_{(no)} = 1 - \left(\frac{0}{1}\right)^2 - \left(\frac{1}{1}\right)^2 = 0\]
¿Qué Split elegiremos?
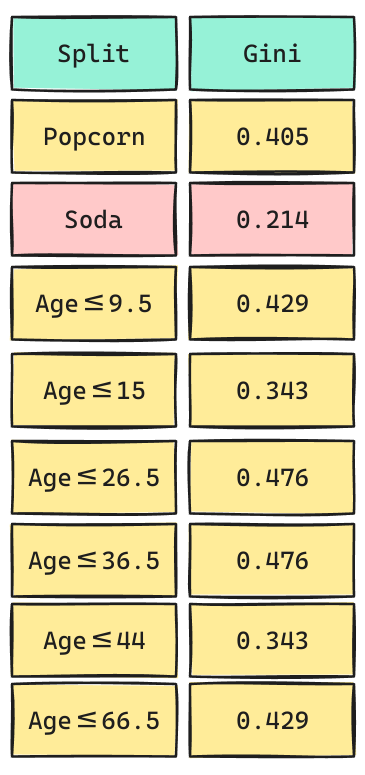
Escogeremos el Split más pequeño que representa el que genera más pureza.
El nodo que no le gusta la Soda quedó completamente puro. Por lo tanto, no puede seguir dividiéndose. Seguiremos trabajando sólo con aquellos que sí les gusta la Soda.
Árbol de Decisión: 2do Nivel

\[Gini_{(yes)} = 1 - \left(\frac{1}{2}\right)^2 - \left(\frac{1}{2}\right)^2 = 0.5\] \[Gini_{(no)} = 1 - \left(\frac{2}{2}\right)^2 - \left(\frac{0}{2}\right)^2 = 0\]
Árbol de Decisión: 2do Nivel
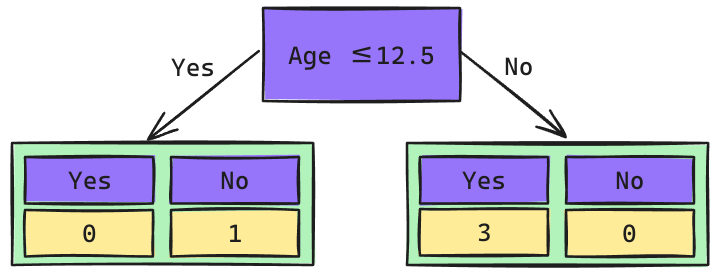
\[Gini_{(yes)} = 1 - \left(\frac{0}{1}\right)^2 - \left(\frac{1}{1}\right)^2 = 0\] \[Gini_{(no)} = 1 - \left(\frac{3}{3}\right)^2 - \left(\frac{0}{3}\right)^2 = 0\]
Árbol de Decisión: 2do Nivel
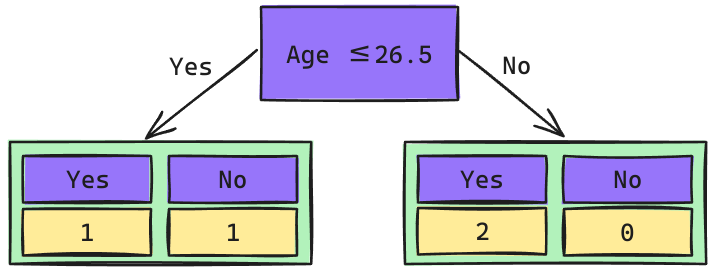
\[Gini_{(yes)} = 1 - \left(\frac{1}{2}\right)^2 - \left(\frac{1}{2}\right)^2 = 0.5\] \[Gini_{(no)} = 1 - \left(\frac{2}{2}\right)^2 - \left(\frac{0}{2}\right)^2 = 0\]
Árbol de Decisión: 2do Nivel
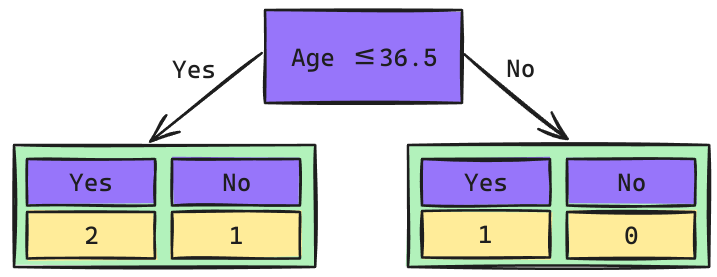
\[Gini_{(yes)} = 1 - \left(\frac{2}{3}\right)^2 - \left(\frac{1}{3}\right)^2 = 0.444\] \[Gini_{(no)} = 1 - \left(\frac{1}{1}\right)^2 - \left(\frac{0}{1}\right)^2 = 0\]
Árbol de Decisión
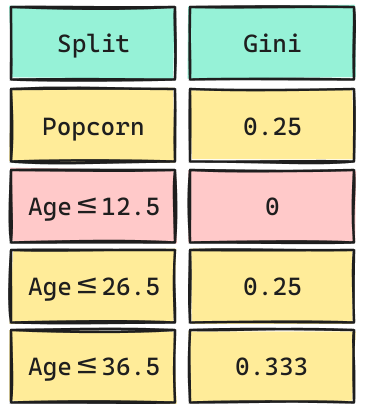
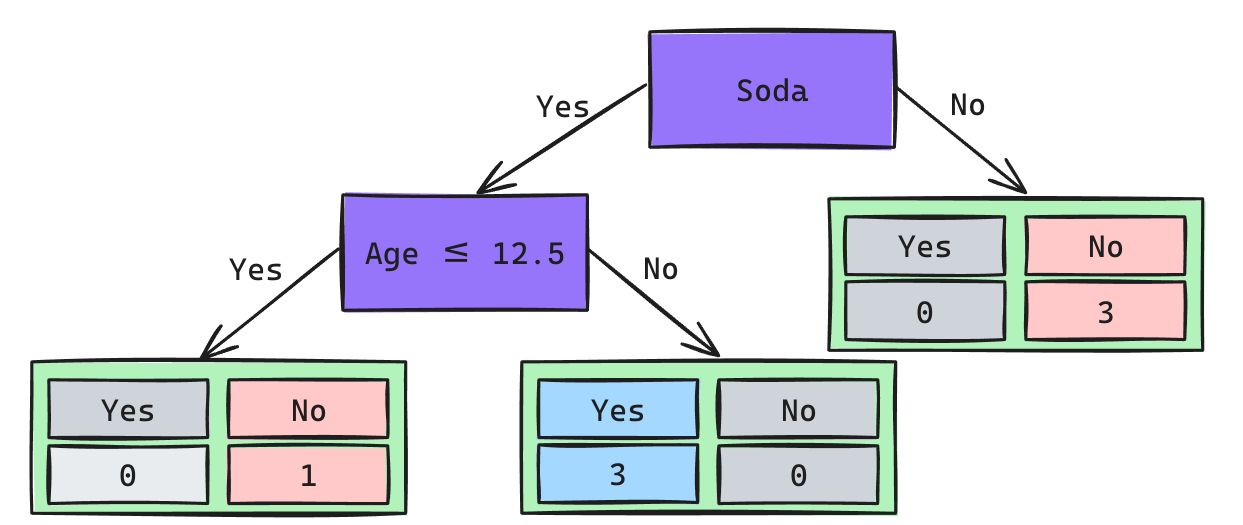
¿Cuál sería la predicción?