TICS-411 Minería de Datos
Clase 11: Naive Bayes
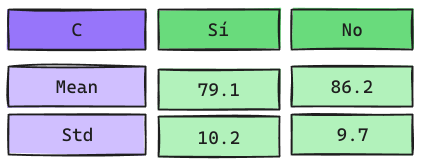
Ejemplo
Smoothing
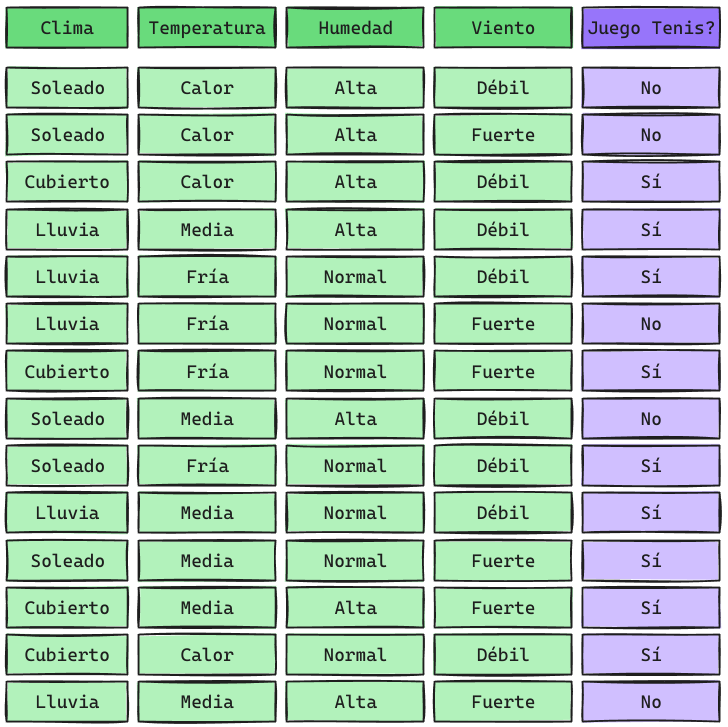
Supongamos otro dataset más pequeño:
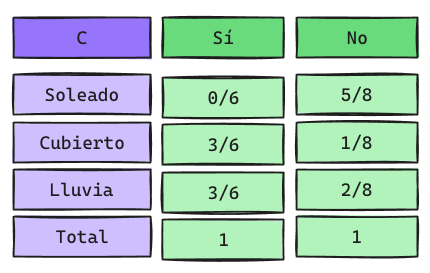
Dado que Naive Bayes se calcula como una Productoria, al tener probabilidades 0 inmediatamente la Probabilidad a Posteriori es 0.
\[ P(Clima = Soleado|y = Sí) = \frac{0}{6}\] \[ P(Clima = Soleado|y = No) = \frac{5}{8}\]
\[P(X_j|C = i) = \frac{N_{yj} + \alpha}{N_y + M\alpha}\]
- \(\alpha\): Es un Hiperparámetro. Si \(\alpha = 1\) se le llama Laplace Smoothing, si \(\alpha <1\) entonces se le llama Lidstone Smoothing.
- M: Corresponde al número de posibles valores que puede tomar \(X_j\)
- \(N_{yj}\): Corresponde a la cantidad de registros que toman el valor de la variable \(X_j\) solicitado en la clase \(y\).
- \(N_{y}\): Corresponde a la cantidad de registros totales que tienen la clase \(y\).
Laplace Smoothing
Sin Laplace
Con Laplace
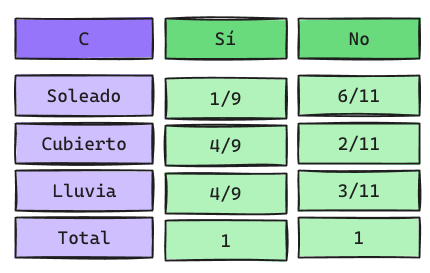
En este caso \(\alpha = 1\) y \(M=3\) ya que Clima puede tomar 3 valores: Soleado, Cubierto y Lluvia.
Variables Continuas
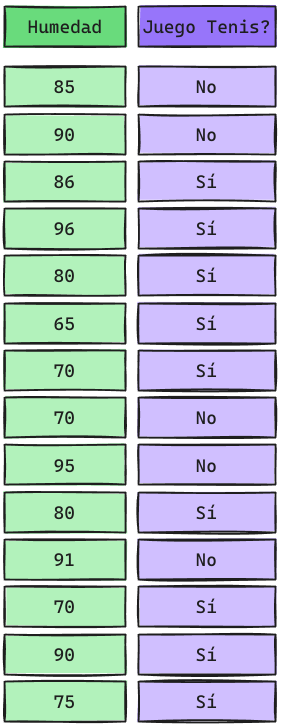
Podemos calcular el Likelihood como una PDF (Probability Density Function). La más común: Distribución Normal (Gaussian Naive Bayes).
\[f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]