TICS-411 Minería de Datos
Clase 12: Regresión Logística
Intuición
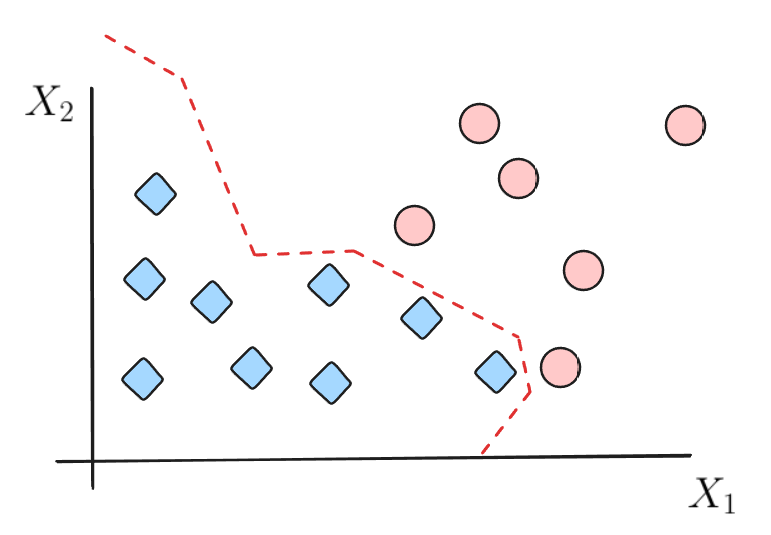
Supongamos el siguiente dataset:
¿Cómo puedo separar ambas clases?
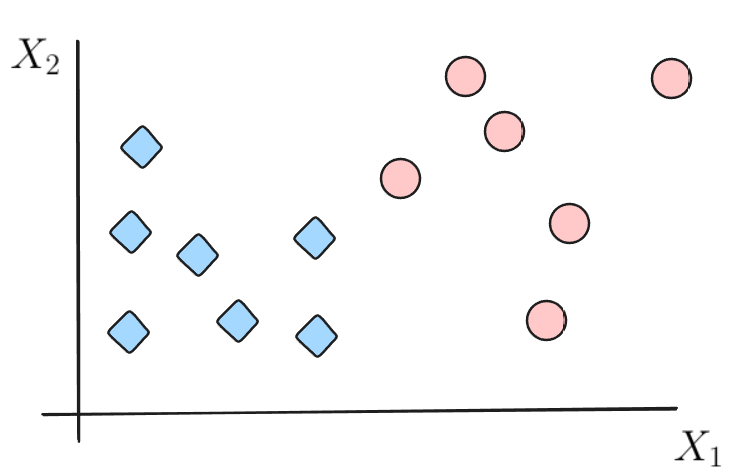
Intuición
Intuición
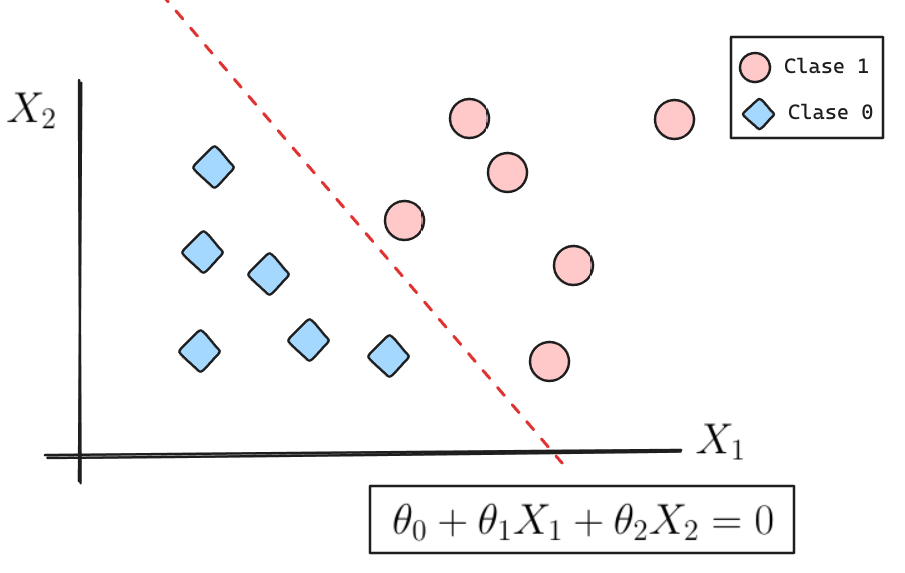
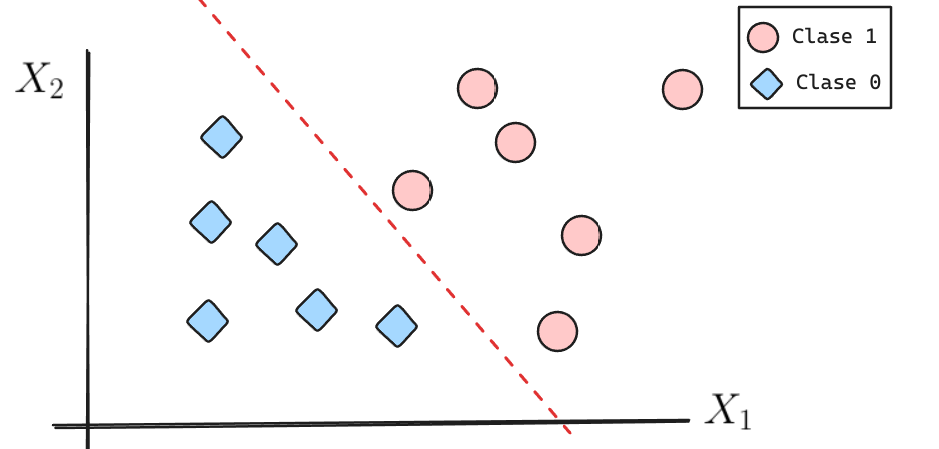
La frontera de decisión se puede caracterizar como la ecuación de una recta (en forma general).
Además definiremos \(h_\theta(X) = \theta_0 + \theta_1 X_1 + \theta_2 X_2\).
Intuición
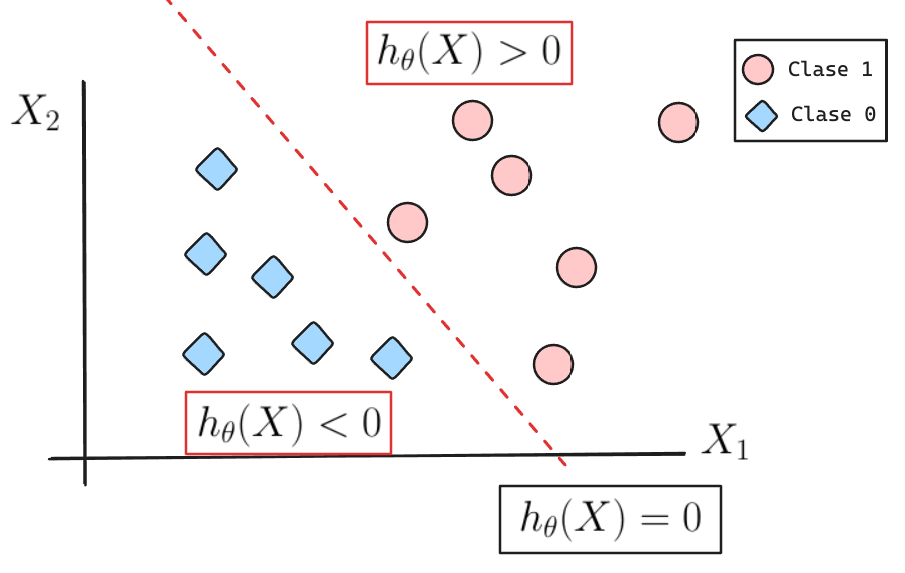
Podríamos pensar que si \(h_\theta(X)\) es positivo entonces pertenece a la clase 1 y si \(h_\theta(X)\) es negativo pertenece a la clase 0.
La Función Sigmoide o Logística
\[ g(z) = \frac{1}{1 + e^{-z}}\]
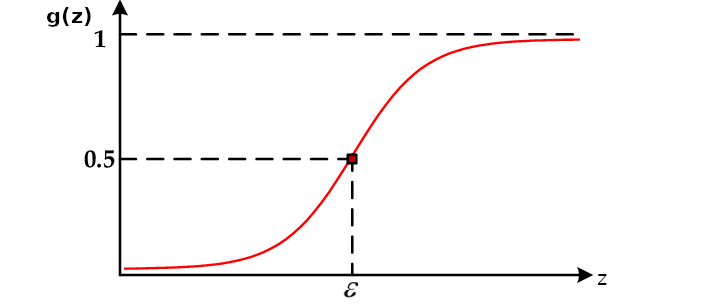
- Función no lineal.
- Función acotada entre 0 y 1.
- \(g(\varepsilon) = 0.5\), \(\varepsilon = 0\)
De acá sale la noción del umbral 0.5 que hemos visto en clases anteriores.
¿Qué pasaría si ahora decimos que \(z = \theta_0 + \theta_1 X_1 + \theta_2 X_2\)?
Frontera de Decisión
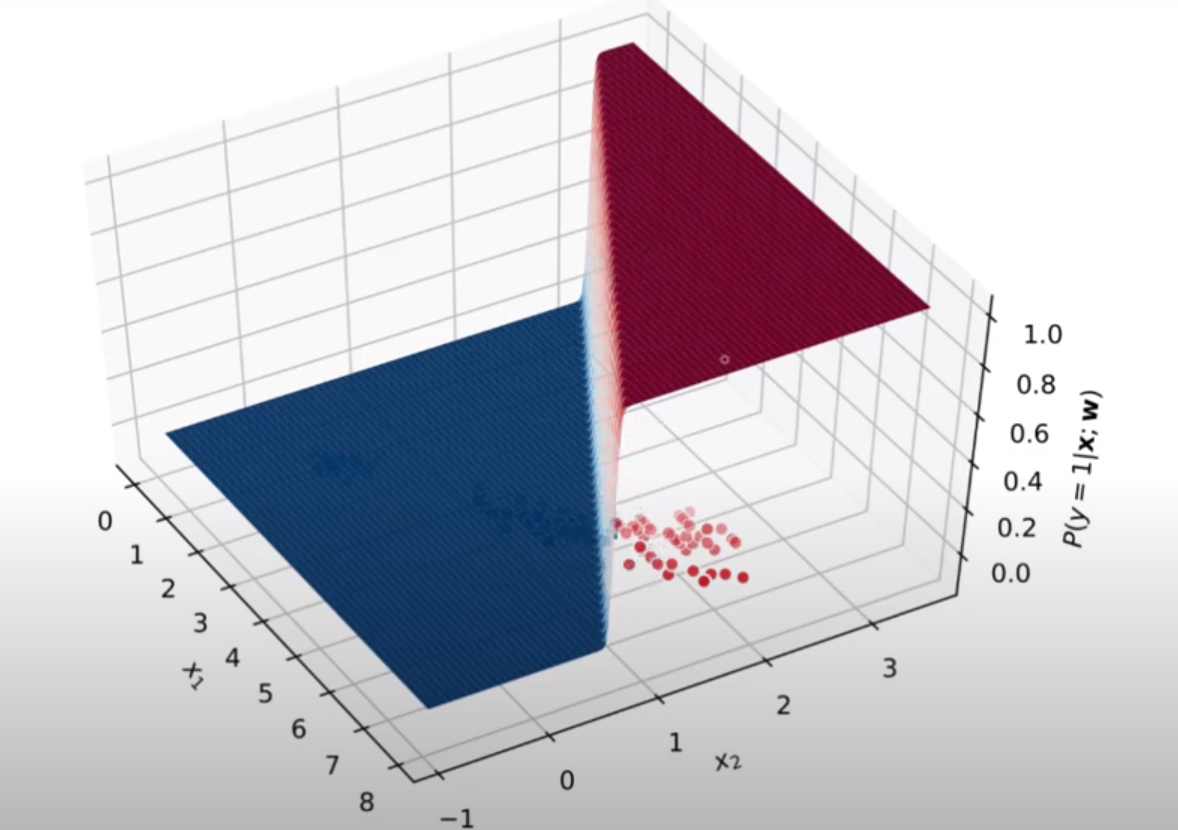
Inference Time
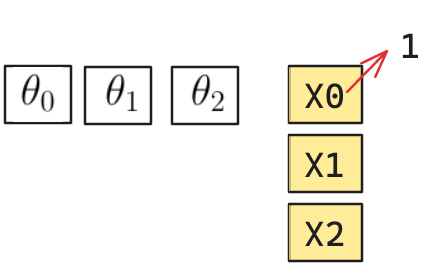
En este caso se calcula: \[g_\theta(x^{(i)})=sigmoid(\theta^t x^{(i)})\]
- \(\theta\): Corresponde a un vector con todos los parámetros calculados.
- \(x^{(i)}\): Corresponde a una instancia de \(m\) variables la cual generará una probabilidad.
- \(\theta^t x^{(i)}\) corresponde al producto punto de dos vectores, que es equivalente a una “suma producto”.
- \(g_\theta(x^{(i)})\): Generará un valor entre 0 y 1 al cuál se le aplica la Regla de Decisión.
Sugerencias
- Estandarización/Normalización de datos: Permite que la escala de los datos no afecte en la interpretabilidad.
- One Hot Encoder: En general tiende a dar mejores resultados que el Ordinal.
- Interacciones: Combinación de variables.
- Variables no Lineales: Permite que la frontera de Decisión no sea necesariamente lineal (Regresión Polinómica).