TICS-411 Minería de Datos
Clase 13: Detección de Anomalías
Más ejemplos
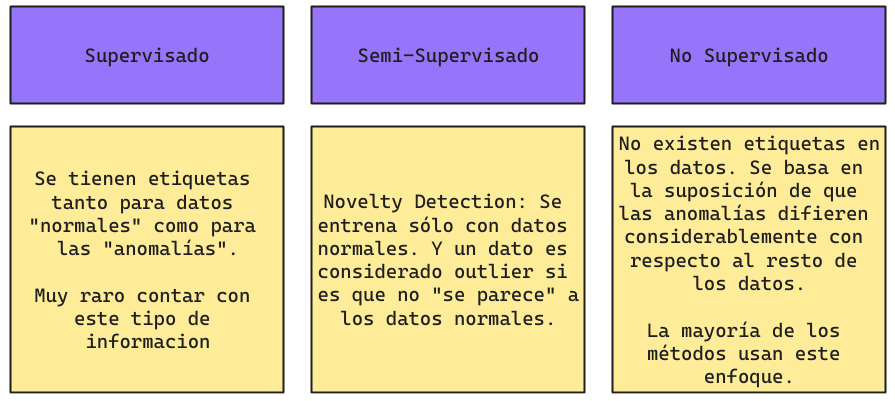
La definición de Anomalía es altamente subjetiva y depende mucho del Dominio en el cuál se está trabajando.
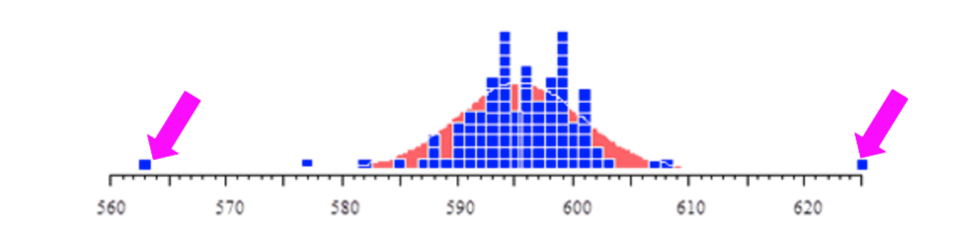
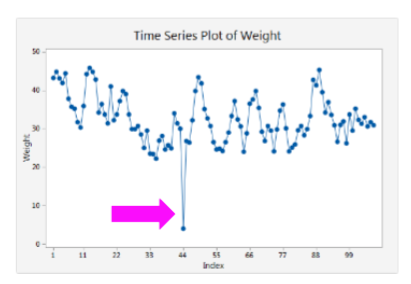
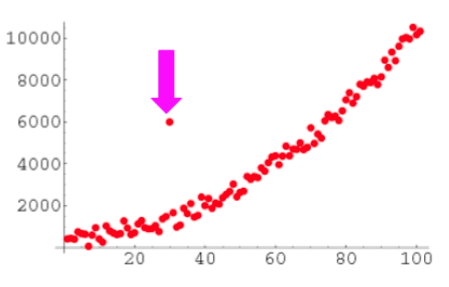
Tipos de Anomalías (Series de Tiempo)
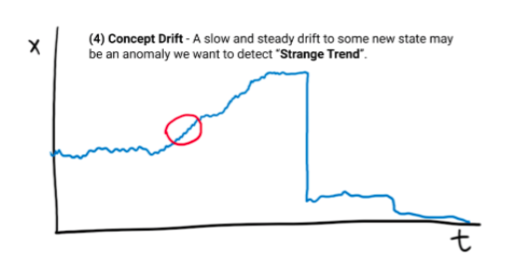
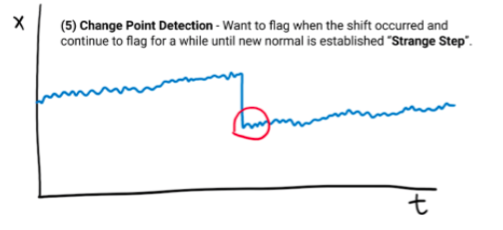
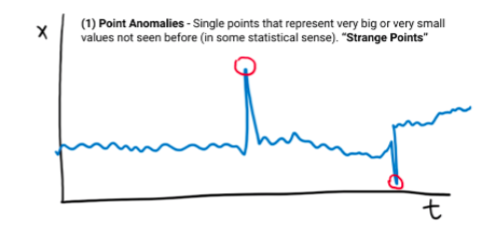
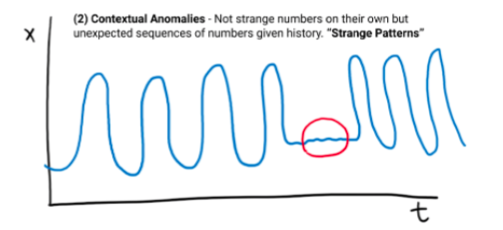

Enfoques
Técnicas Visuales
Estas técnicas son muy subjetivas ya que dependen del criterio/apreciación del usuario.
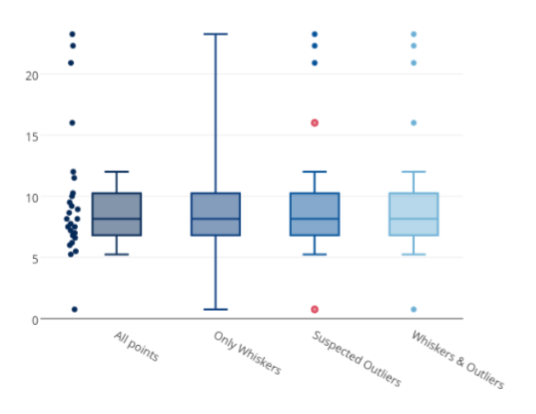
Box Plots
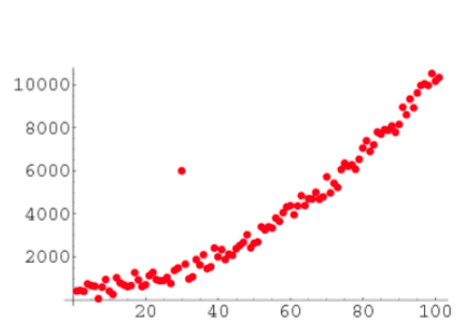
Scatter Plots
Caso Multivariado
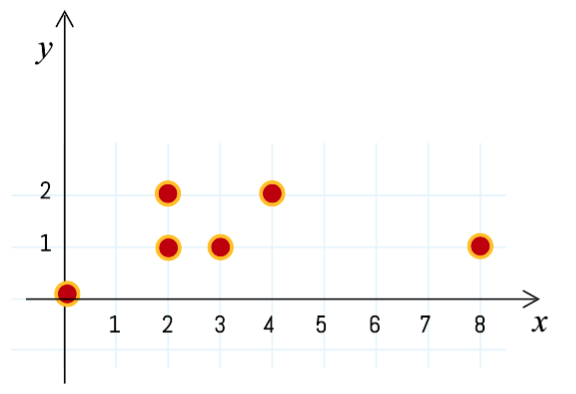
La idea es calcular la distancia de cada punto al centro tomando en consideración la covarianza.
Caso Multivariado
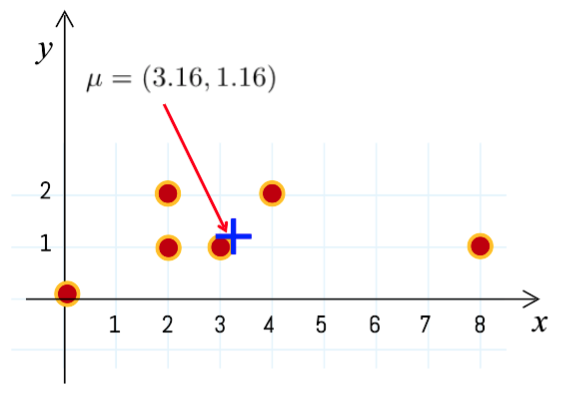
Paso 1
- Calcular el punto central de todos los puntos (Promedio) \[\mu = (3.16, 3.16)\]
Paso 2
- Calcular la Inversa de la Matriz de Covarianza:
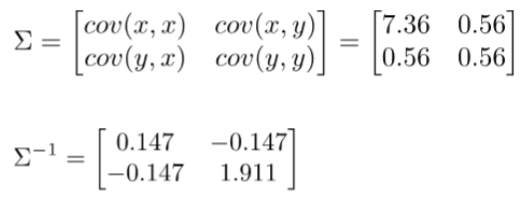
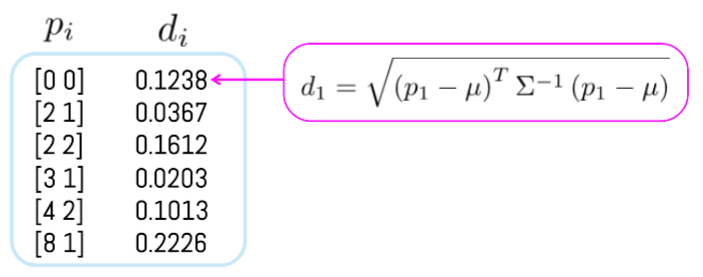
Caso Multivariado: Continuación
Paso 4:
Se debe calcular el punto crítico según t-student con 95% confianza, y orden de magnitud \(m\) dimensiones.
\[t_{(\alpha = 0.95,2)} = 5.99\]
Paso 5
Comparar, Si \(d_i>t_{crit}\) entonces \(d_i\) es Outlier.

En este caso ningún valor de \(d_i\) es mayor al $t_{(crit)}, por lo tanto, no hay outliers.
Distancia de Mahalanobis
La distancia de Mahalanobis corresponde a:
\[d_i = \sqrt{(p_i - \mu)^T \Sigma^{-1}(p_i - \mu)}\]
Se puede repetir el mismo procedimiento anterior, sólo que se define una Distancia de Mahalonobis umbral. Las que superen dicho umbral son considerados como Outliers.
DBSCAN
Podemos utilizar el procedimiento que aprendimos de DBSCAN. Todos los puntos Noise serán considerados como Anomalías.
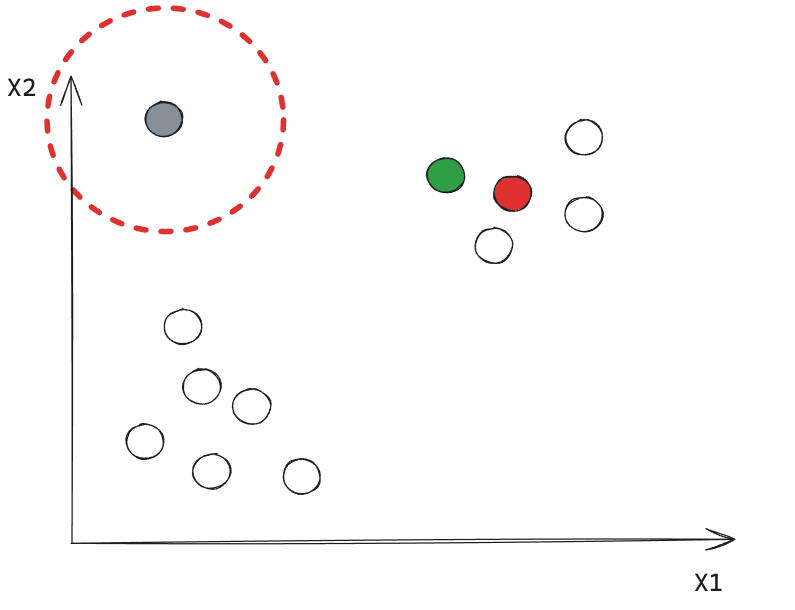
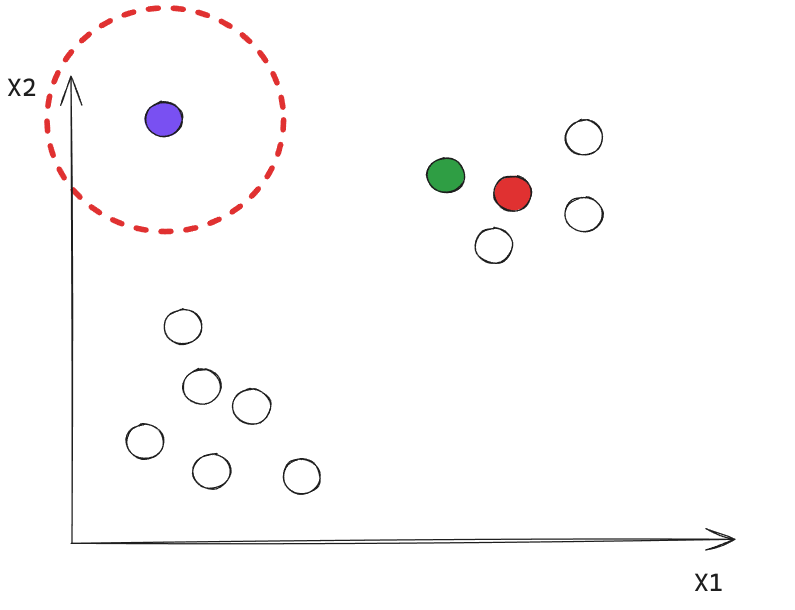
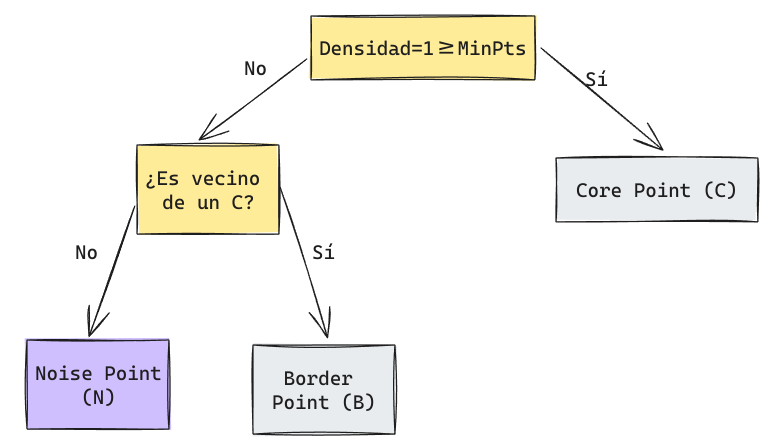
Este punto corresponde a un Noise Point. Lo cuál en nuestro caso particular se considerará una Anomalía.
K-Nearest Neighbor
Se puede utilizar los modelos de vecinos más cercanos para determinar outliers siguiendo el siguiente procedimiento:

Paso 1: Definir el valor de \(k\) para encontrar los vecinos más cercanos.
Ej: Sea \(k=3\)
Paso 2: Calcular la Matriz de Distancias y determinar los vecinos más cercanos.
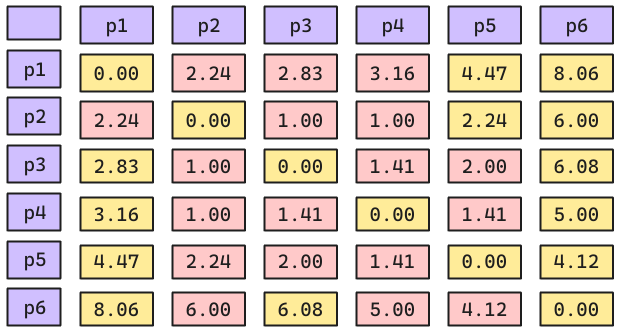
K-Nearest Neighbor: Continuación
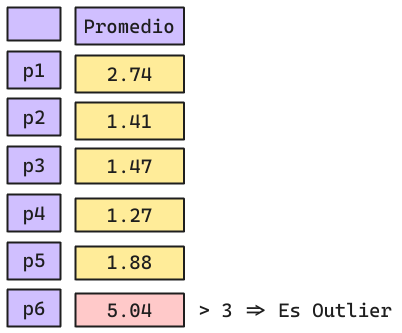
Paso 3: Calcular la distancias Promedio.

Paso 4: Escoger un Umbral. Si es que la distancia es mayor al Umbral entonces es un Outlier. Ej: \(Dist_crit: 3\)
Local Outlier Factor (LOF)
- Local Outlier Factor (LOF) detecta anomalías con sus vecindarios locales, en lugar de la distribución glocal de los datos.
En la Figura, \(O1\) y \(O2\) son anomalías locales en comparación con \(C1\), \(O3\) es una anomalía global, y \(O4\) no es una anomalía.
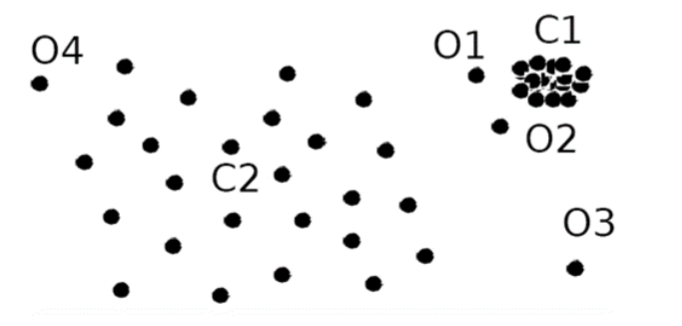
Ejemplo Local Outlier Factor
Utilizar \(K = 2\) y Distancia Manhattan.
Paso 1: Calcular Distancias
- dist(a,b) = 1
- dist(a,c) = 2
- dist(a,d) = 3
- dist(b,c) = 1
- dist(b,d) = 4
- dist(c,d) = 3
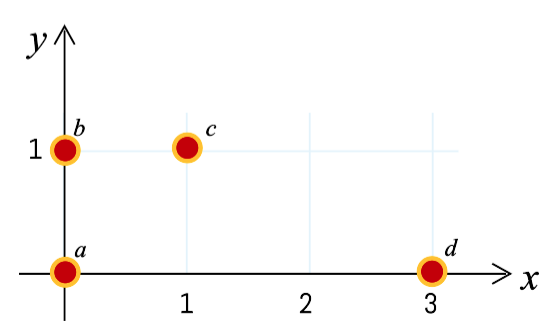
Ejemplo Local Outlier Factor: Continuación
Paso 2: Para todo punto \(y\), calcule la distancia a su k-ésimo vecino más cercano.
- \(dist_2(a) = dist(a,c) = 2\) (c es el 2do vecino más cercano)
- \(dist_2(b) = dist(b,a) = 1\) (a/c es el 2do vecino más cercano)
- \(dist_2(c) = dist(c,a) = 2\) (a es el 2do vecino más cercano)
- \(dist_2(d) = dist(d,a) = 3\) (a/c es el 2do vecino más cercano)
Ejemplo Local Outlier Factor: Continuación
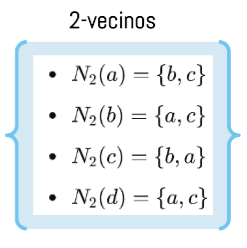
Paso 3: Calcular la reach-distance entre todos los puntos, es decir, los puntos vecindarios a una distancia k.
- \(N_2(a) = \{b,c\}\)
- \(N_2(b) = \{a,c\}\)
- \(N_2(c) = \{b,a\}\)
- \(N_2(d) = \{a,c\}\)
Ejemplo Local Outlier Factor: Continuación
Paso 4: Calcular la densidad del vecinadario local sobre sus \(k\) vecinos.
- \(reach-dist_2(b \leftarrow a) = max\{dist_2(b), dist(b,a)\} = max\{1,1\} = 1\)
- \(reach-dist_2(c \leftarrow a) = max\{dist_2(c), dist(c,a)\} = max\{2,2\} = 2\)
Calcular el resto de manera análoga.
Ejemplo Local Outlier Factor: Continuación
Paso 5: Calcular el Local Outlier Factor para el punto \(x\) como la proporción de la densidad de sus \(k\) vecinos más cercanos, con respecto a la densidad del punto \(x\).
\[LOF(x) = \frac{\sum_{y \in N(x,k)} density(y,k)}{|N(x,k)|density(x,k)}\]
\[LOF_2(a) = \frac{lrd_2(b) + lrd_2(c)}{N_2(a) \cdot lrd_2(a)} = \frac{0.5 + 0.667}{2 \cdot 0.667} = 0.87\] \[LOF_2(b) = \frac{lrd_2(a) + lrd_2(c)}{N_2(b) \cdot lrd_2(b)} = \frac{0.667 + 0.667}{2 \cdot 0.5} = 1.334\] \[LOF_2(c) = \frac{lrd_2(b) + lrd_2(a)}{N_2(c) \cdot lrd_2(c)} = \frac{0.5 + 0.667}{2 \cdot 0.667} = 0.87\] \[LOF_2(d) = \frac{lrd_2(a) + lrd_2(c)}{N_2(d) \cdot lrd_2(d)} = \frac{0.667 + 0.667}{2 \cdot 0.33} = 2\]