TICS-411 Minería de Datos
Clase 4: Clustering Jerárquico
Clustering: Jerarquía
Los algoritmos basados en jerarquía pueden seguir 2 estrategias:
Aglomerativos: Comienzan con cada objeto como un grupo (bottom-up). Estos grupos se van combinando sucesivamente a través de una métrica de similaridad.
Para n objetos se realizan n-1 uniones.Divisionales: Comienzan con un solo gran cluster (bottom-down). Posteriormente este mega-cluster es dividido sucesivamente de acuerdo a una métrica de similaridad.
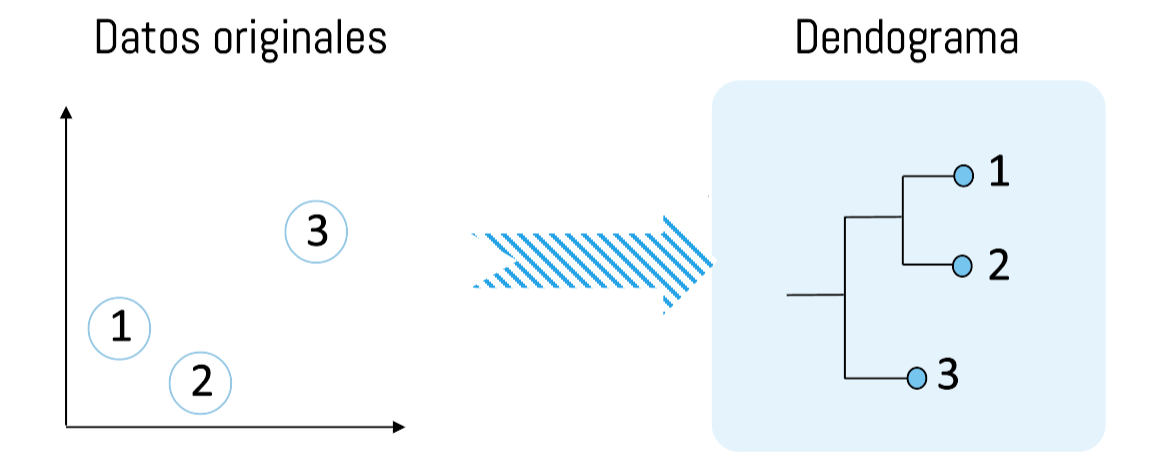
Clustering Aglomerativo: Ejemplo
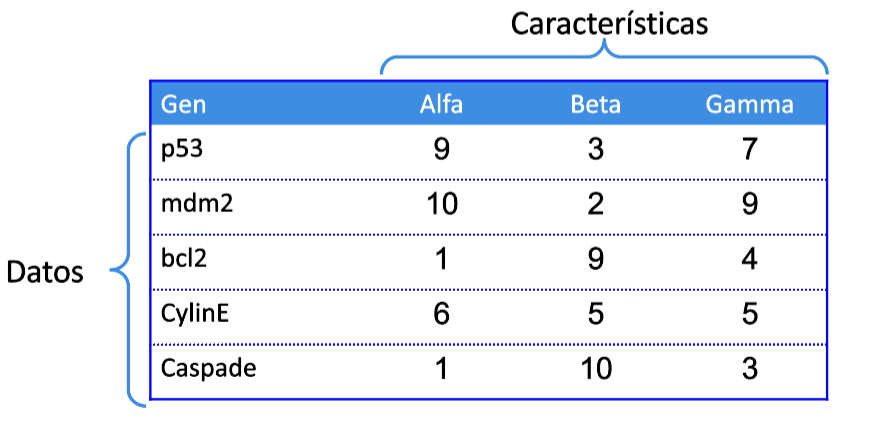
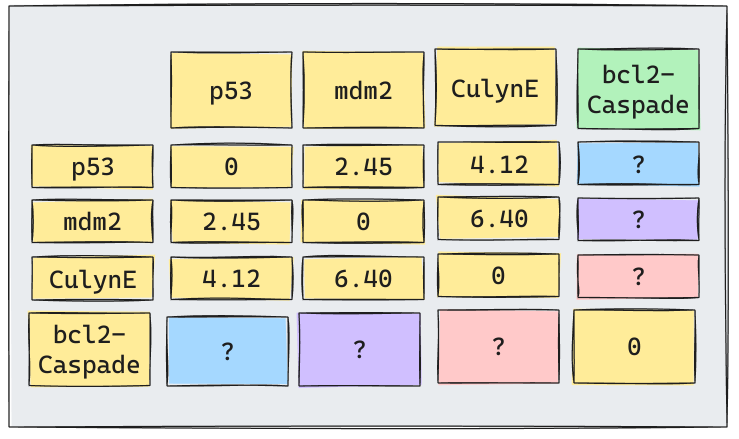
Supongamos que tenemos cinco tipos de genes cuya expresión ha sido determinada por 3 caracteríticas. Las siguientes expresiones pueden ser vistas como la expresión dados los genes en tres experimentos.
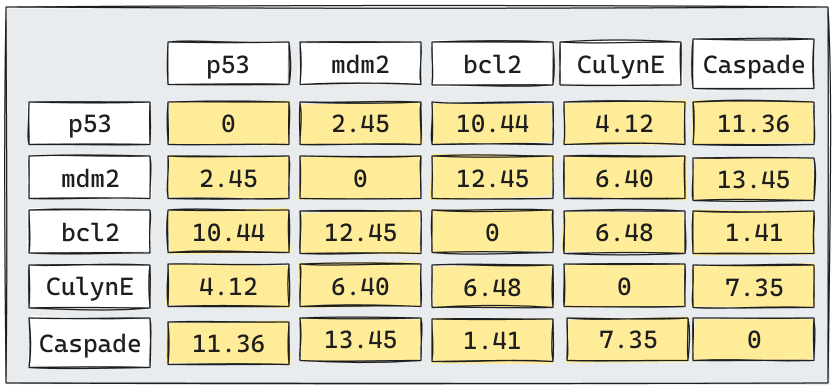
Apliquemos un Clustering Jerárquico Aglomerativo utilizando como medida de similaridad la
Distancia Euclideana.
Otros tipos de distancia también son aplicables siguiendo un procedimiento análogo.
Algoritmo: 1era Iteración
El algoritmo considerará que todos los puntos inicialmente son un cluster. Por lo tanto, tratará de encontrar los 2 puntos más cercanos e intentará unirnos en un sólo cluster.
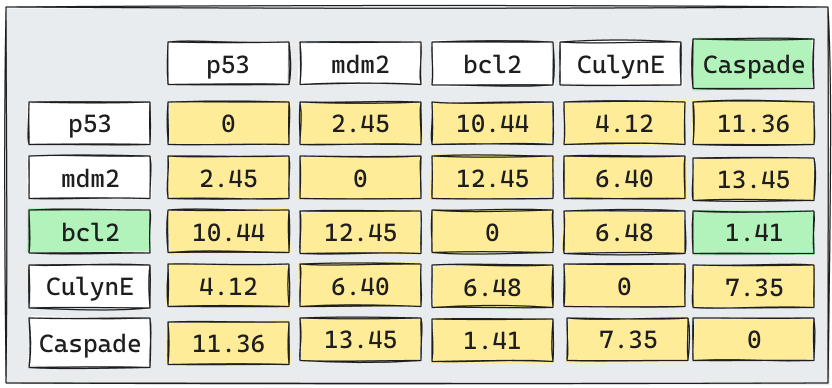
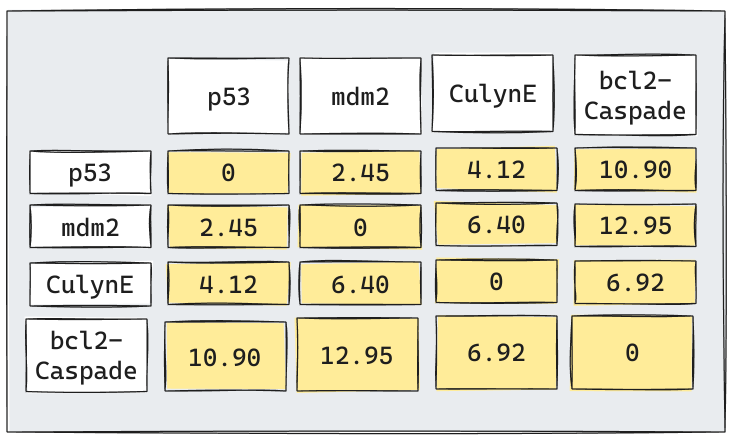
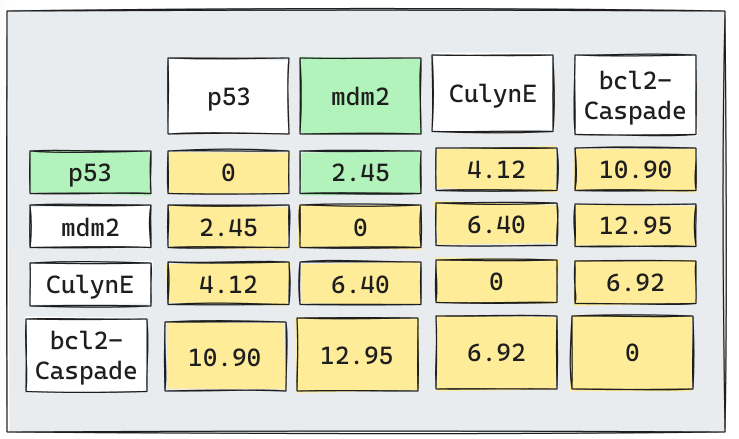
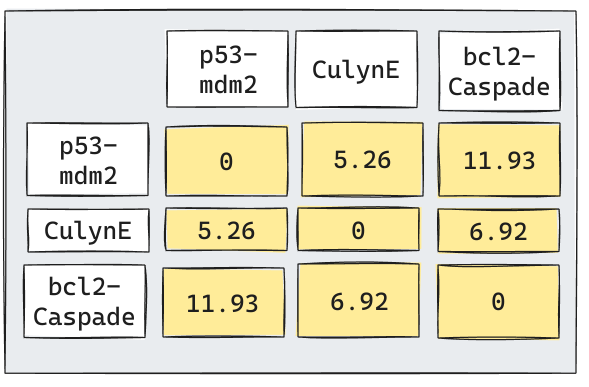
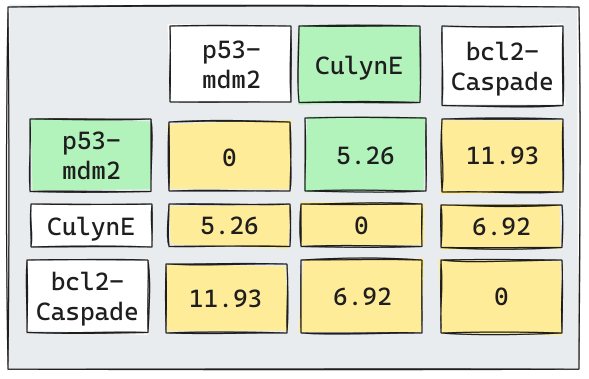
Problema: ¿Cómo actualizamos la matriz de Distancias?
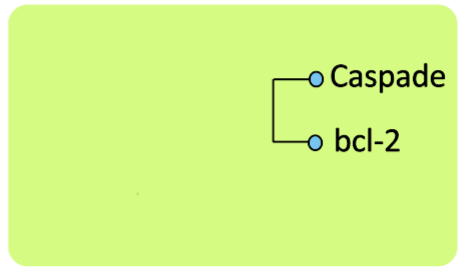
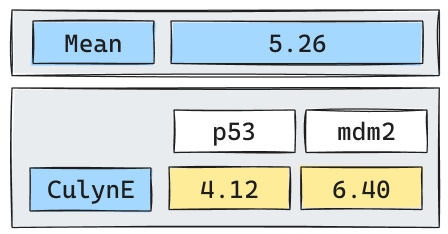
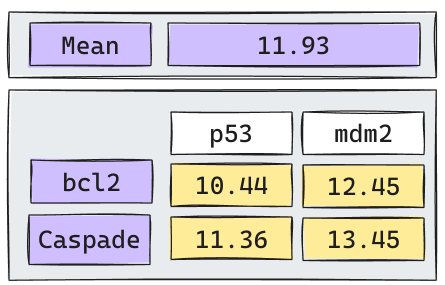
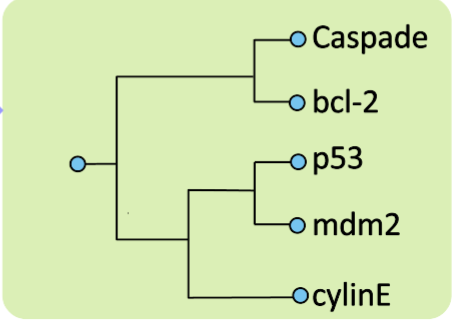
Entonces crearemos un nuevo cluster: bcl2-Caspade.
Clustering Aglomerativo: Single Linkage
- Distancia entre clusters determinada por los puntos más
similaresentre los clusters.
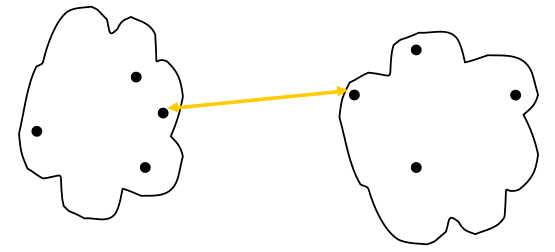
\[D(C_i, C_j) = min\{d(x,y) | x \in C_i, y \in C_j\}\]
Ventajas
- Genera Clusters largos y delgados.
Limitaciones
- Afectado por Outliers
Clustering Aglomerativo: Complete Linkage
- Distancia determinada por la distancia ente los puntos más
disímilesentre los clusters.
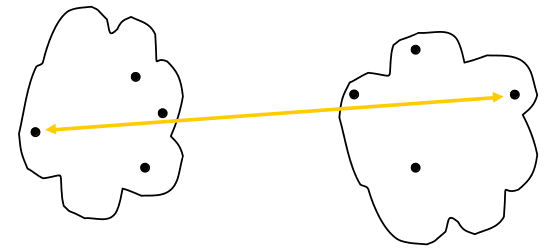
\[D(C_i, C_j) = max\{d(x,y) | x \in C_i, y \in C_j\}\]
Ventajas
- Menos suceptible a dato atípicos.
Limitaciones
- Tiende a quebrar Clusters Grandes.
- Tiene tendencia a generar Clusters circulares.
Clustering Aglomerativo: Average Linkage
- Distancia determinada por el promedio de las distancias que componen los clusters.
- Punto intermedio entre Single y Complete.
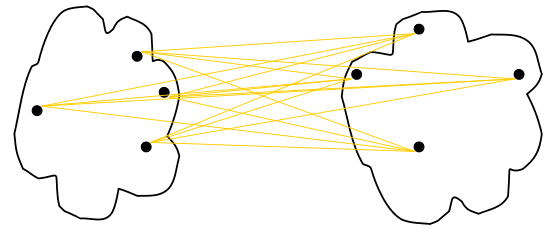
\[D(C_i, C_j) = avg\{d(x,y) | x \in C_i, y \in C_j\}\]
Ventajas
- Menos suceptible a datos atípicos.
Limitaciones
- Tiende a generar clusters circulares.
Clustering Aglomerativo: Ward Linkage
- Distancia determinada por el incremento del
Within cluster distance. - Minimiza la distancia intra cluster y maximiza la distancia entre clusters.
\[D(C_i, C_j) = wc(Cij) - wc(C_i) - wc(C_j) = \frac{n_i\cdot n_j}{n_i + n_j}||\bar{C_i} - \bar{C_j}||^2\]
Ventajas
- Menos suceptible a dato atípicos.
Limitaciones
- Tiende a generar clusters circulares.
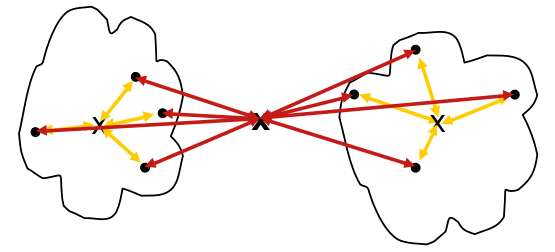
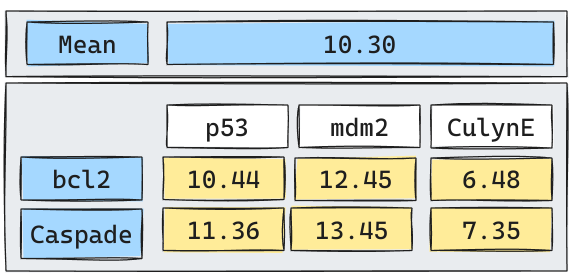
Volvamos a la Iteración 1
Supongamos que por simplicidad utilizaremos
Average Linkage. (El proceso para utilizar otro linkage es análogo).
Vamos a extraer una Matriz entre los puntos a fusionar y los puntos de los clusters restantes.
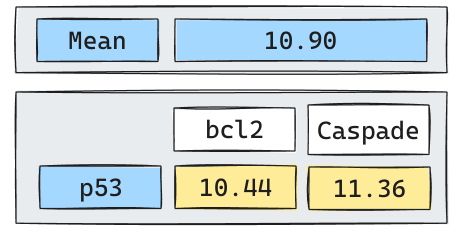
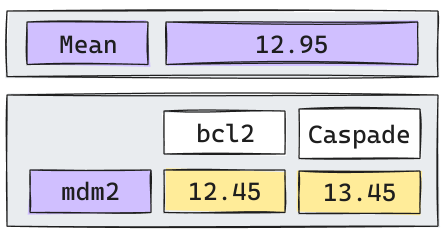
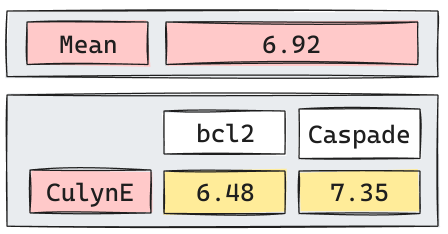
Dendograma: 1era Iteración
Iteración 2
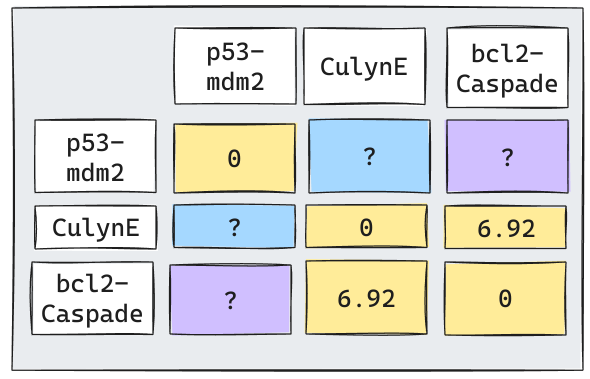
Dendograma: 2da Iteración
Iteración 3
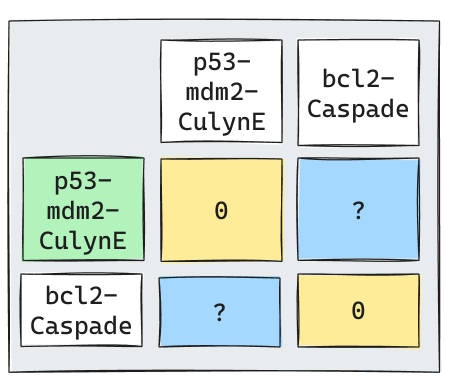
Dendograma: 3ra Iteración
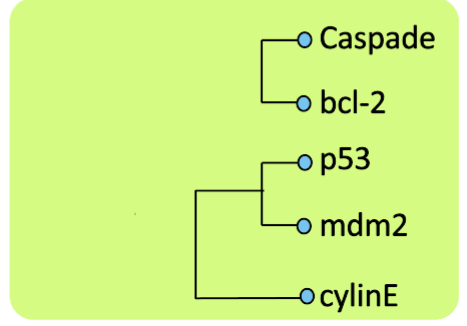
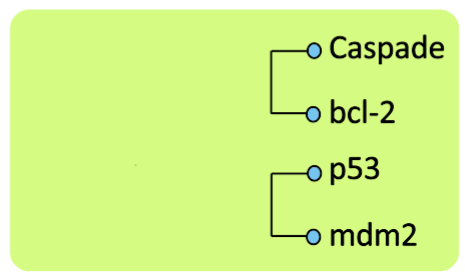
Dendograma Resultante
No es necesario realizar la última iteración ya que se entiende que ambos clusters se unen.
¿Cómo encontramos los clusters una vez que tenemos el Dendograma?
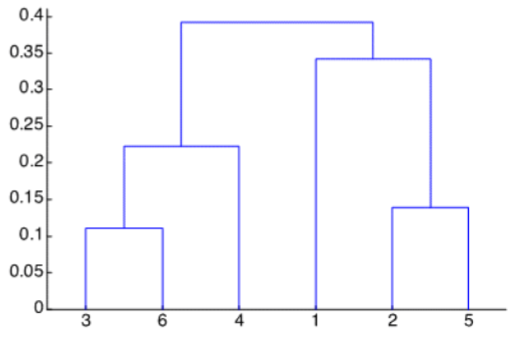
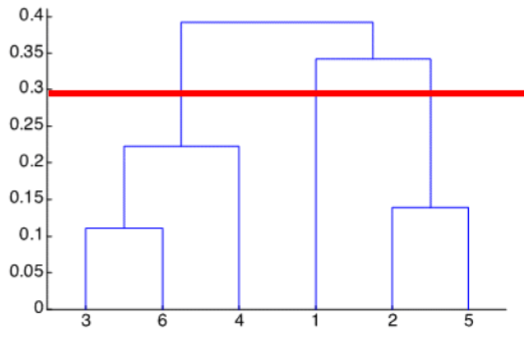
- Podemos escoger un
umbral de distanciay ver cuántos clusters se forman.
- Como regla general se deben escoger clusters más
distanciadosentre sí.
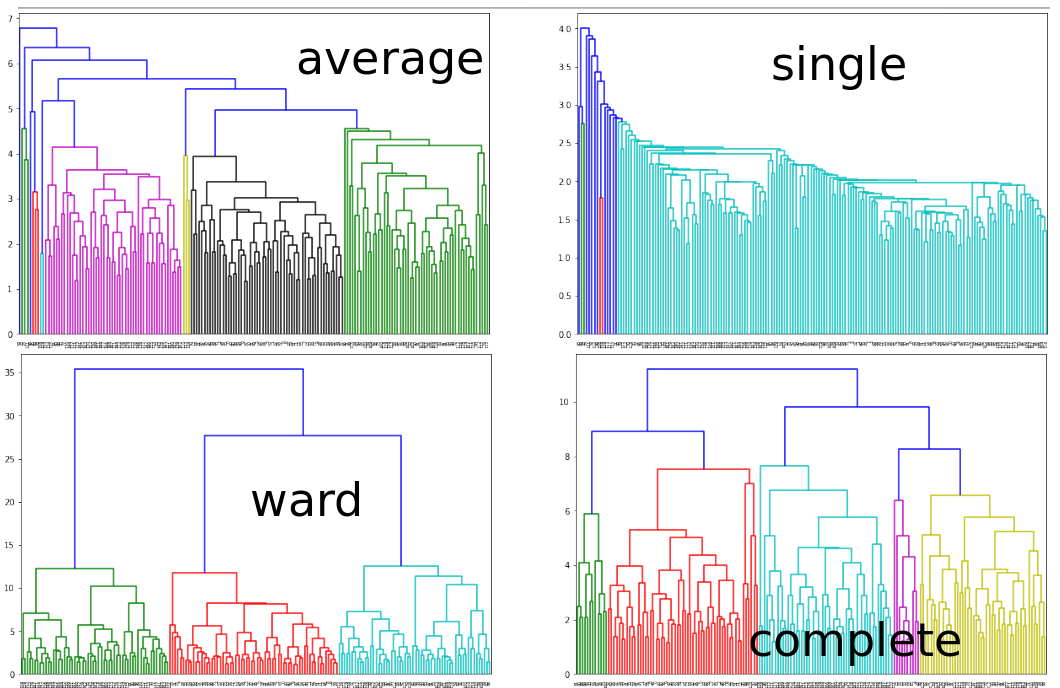
Efecto del Linkage Escogido
Variantes
En casos en los que no es posible calcular distancias debido a la presencia de datos categóricos, es posible utilizar el Gower Dissimilarity como medida de similitud.
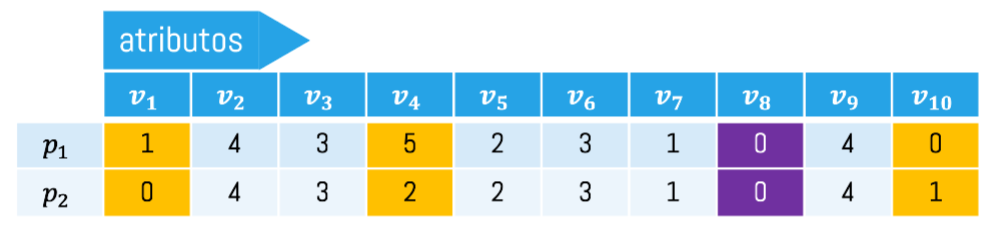
- Gower
- Se define como la proporción de variables que tienen distinto valor con respecto al total sin considerar donde ambos son ceros.
\[Gower(p1,p2) = \frac{3}{9}\]