TICS-411 Minería de Datos
Clase 5: DBSCAN
Clustering: Densidad
Se basan en la idea de continuar el crecimiento de un cluster a medida que la densidad (número de objetos o puntos) en el vecindario sobrepase algún umbral.

En nuestro caso utilizaremos DBSCAN (Density-Based Spatial Clustering Applications with Noise).
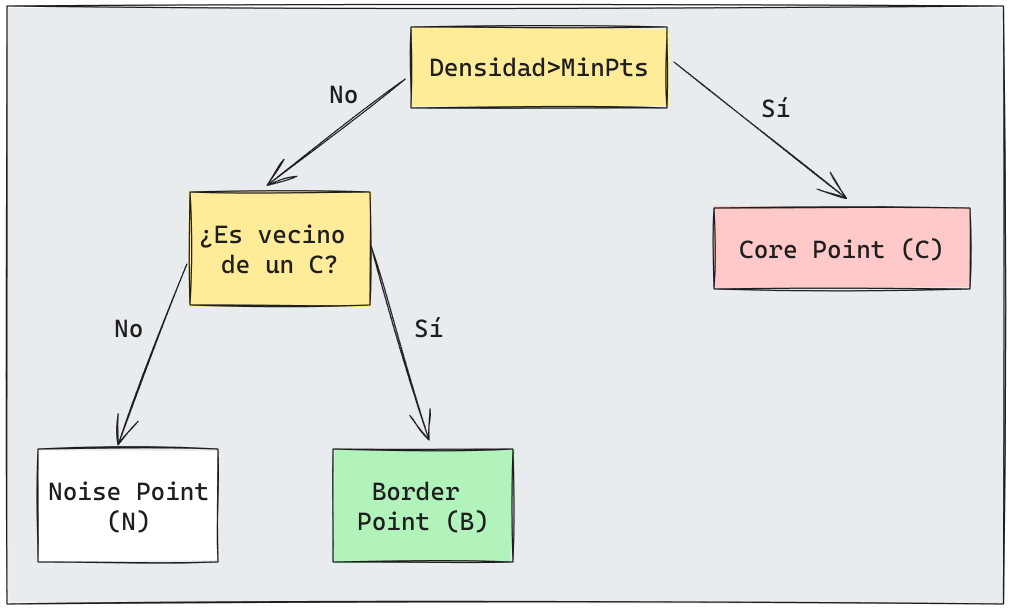
DBSCAN: Algoritmo categorización de puntos
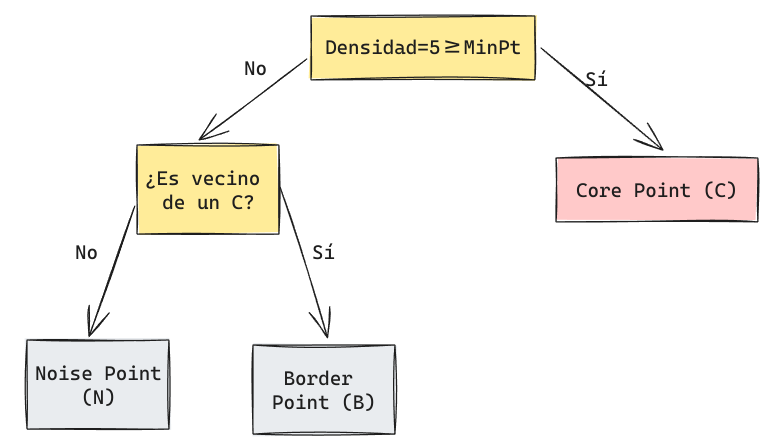
Primeramente se aplica un algoritmo para categorizar cada punto de acuerdo a las definiciones anteriores.
- Para cada punto en el espacio:
- Calcular su densidad en EPS y aplicar el siguiente algoritmo:
Ejemplo: Iteración 1
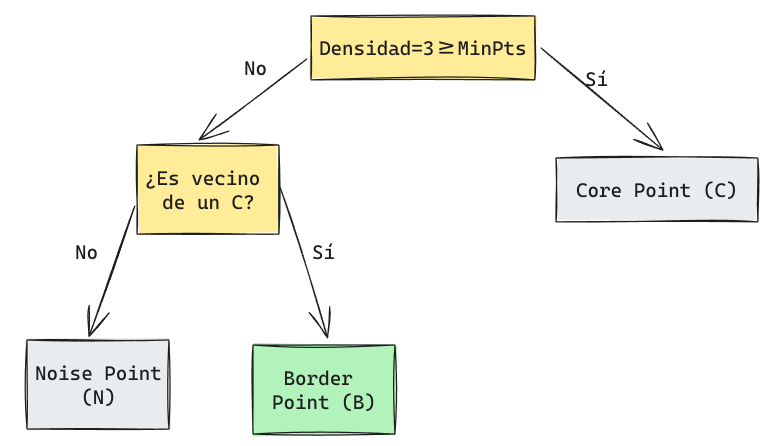
Supongamos un ejemplo con \(MinPts=4\).
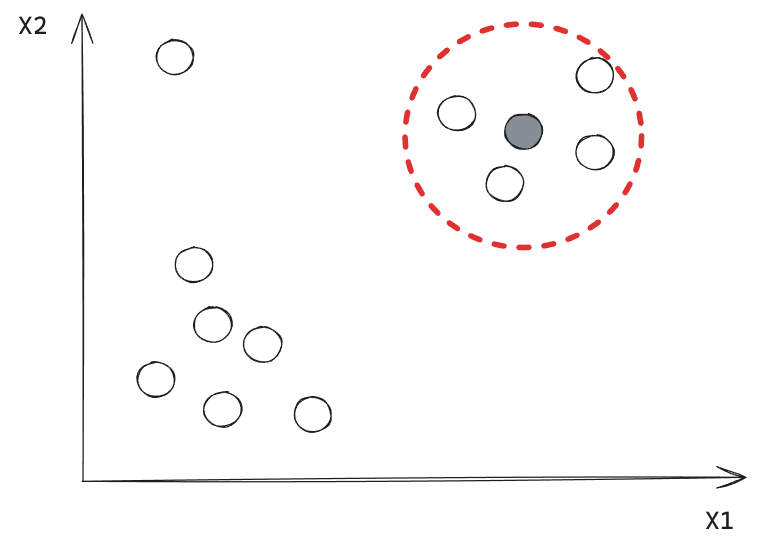
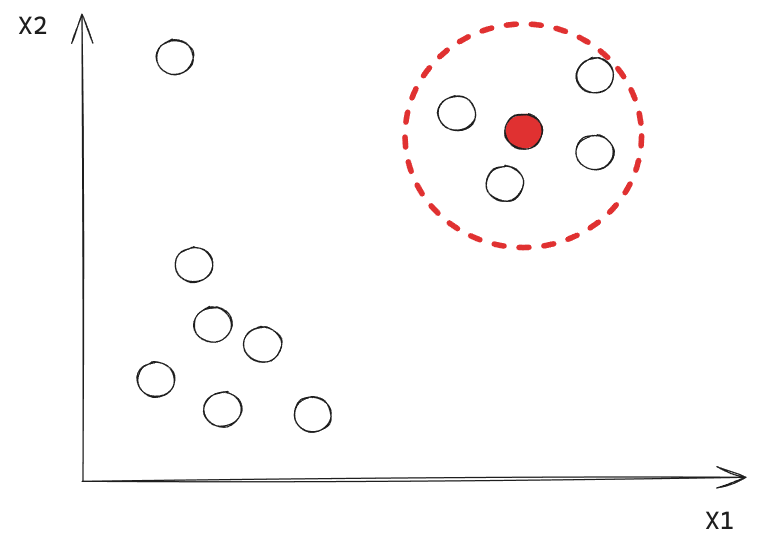
Este punto corresponde a un Core Point.
Ejemplo: Iteración 2
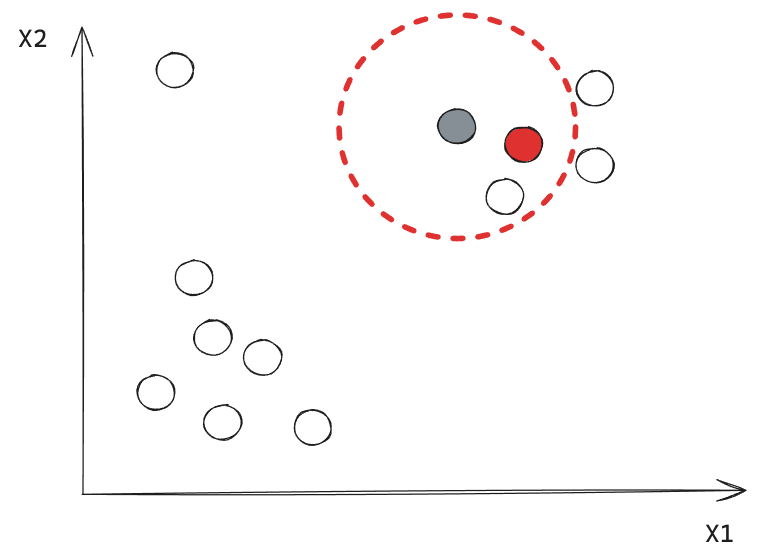
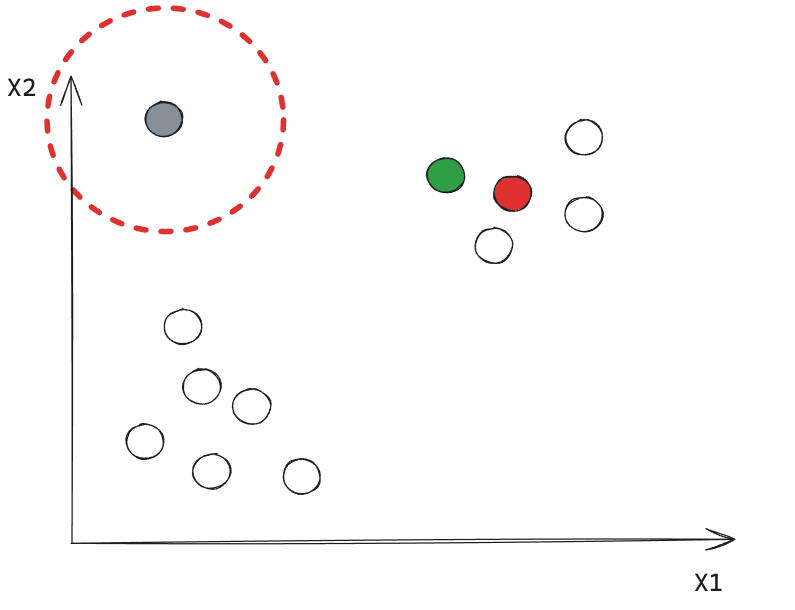
Este punto corresponde a un Border Point.
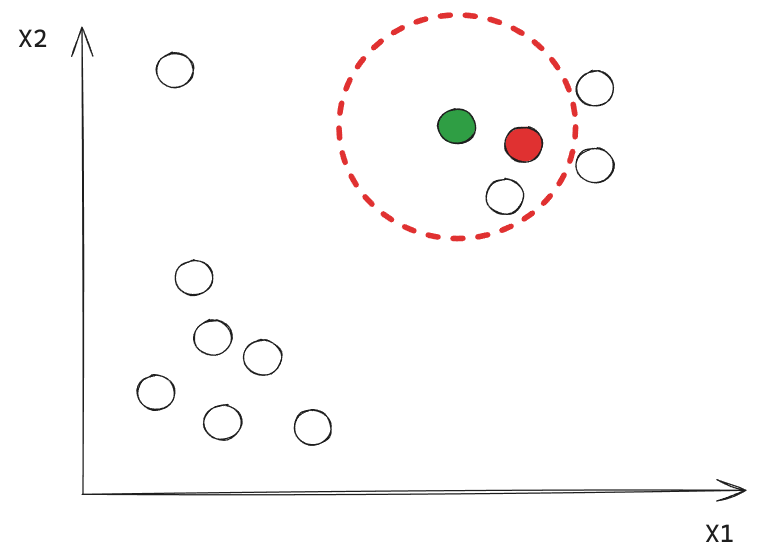
Ejemplo: Iteración 3
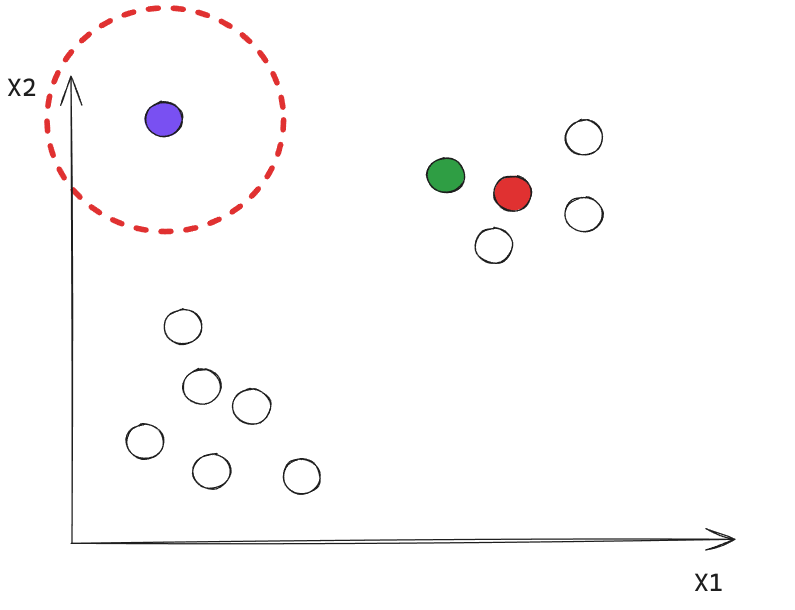
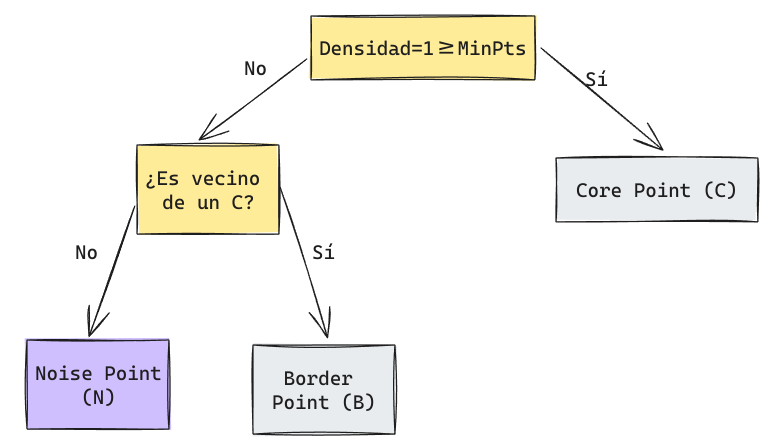
Este punto corresponde a un Noise Point.
Ejemplo: Iteración Final
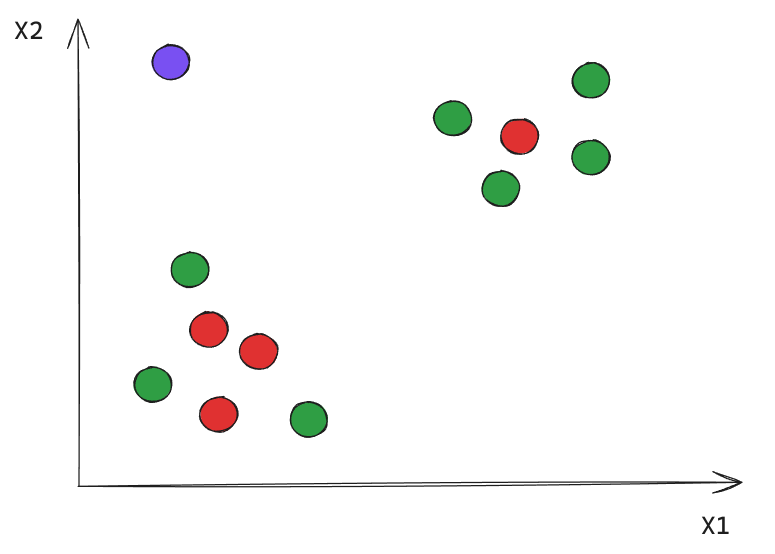
Ahora, ¿Cómo definimos que partes son clusters o no?
Iteración 1
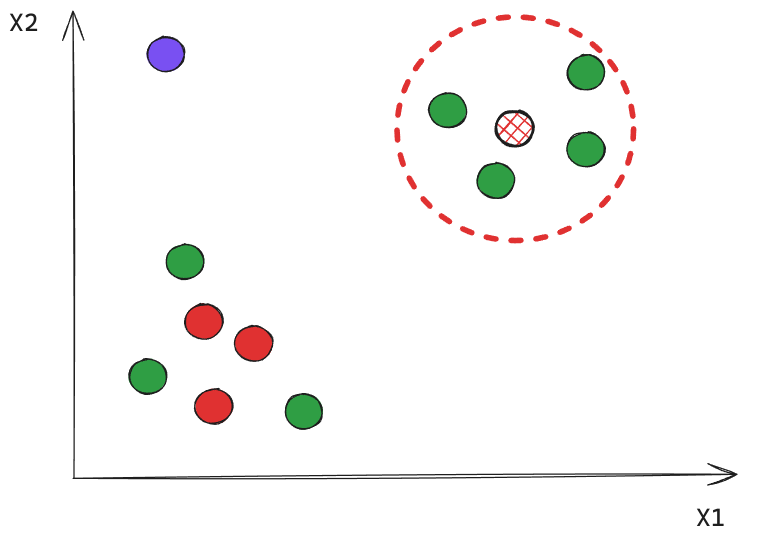

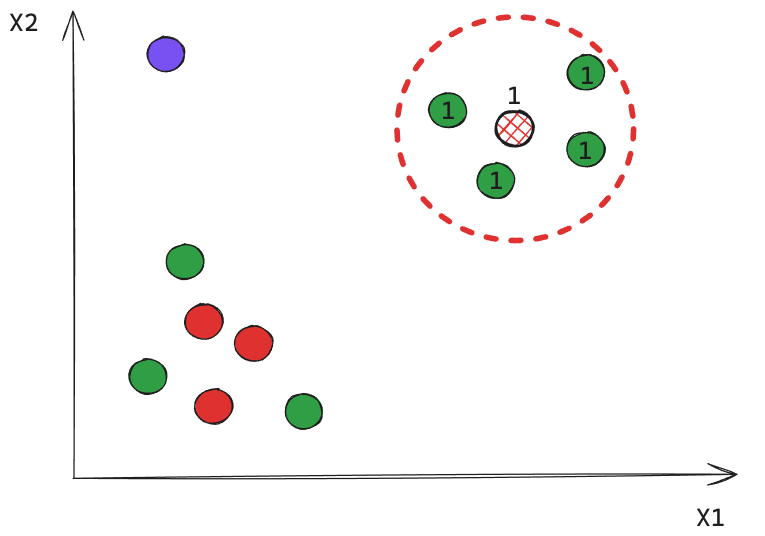
Todos los puntos cercanos a un Core reciben la misma etiqueta.
Iteración 2
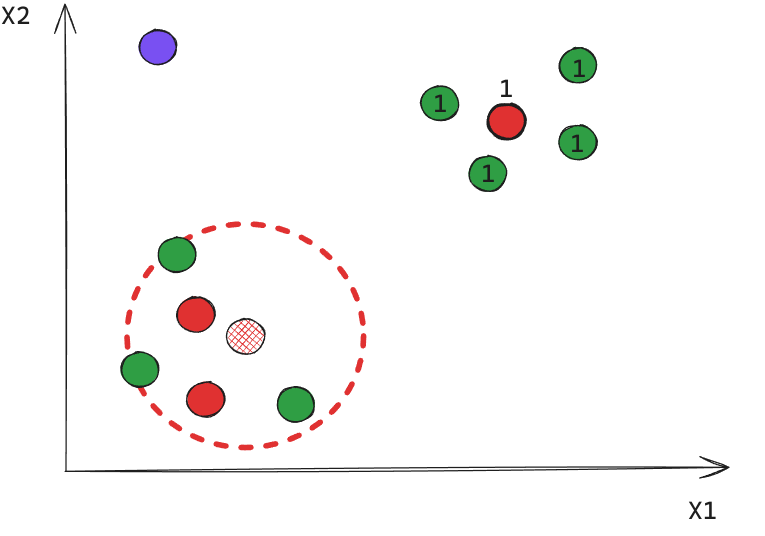
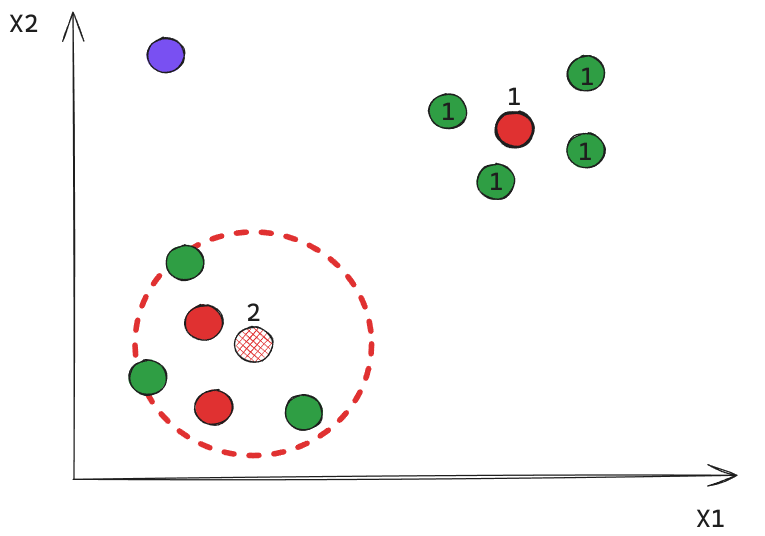
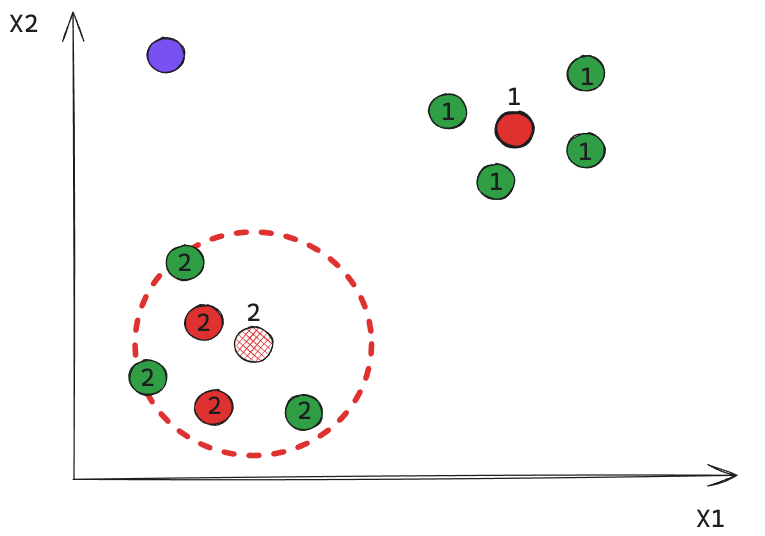
En este caso obtuvimos 2 clusters, e indirectamente un 3er de puntos ruido.
DBSCAN
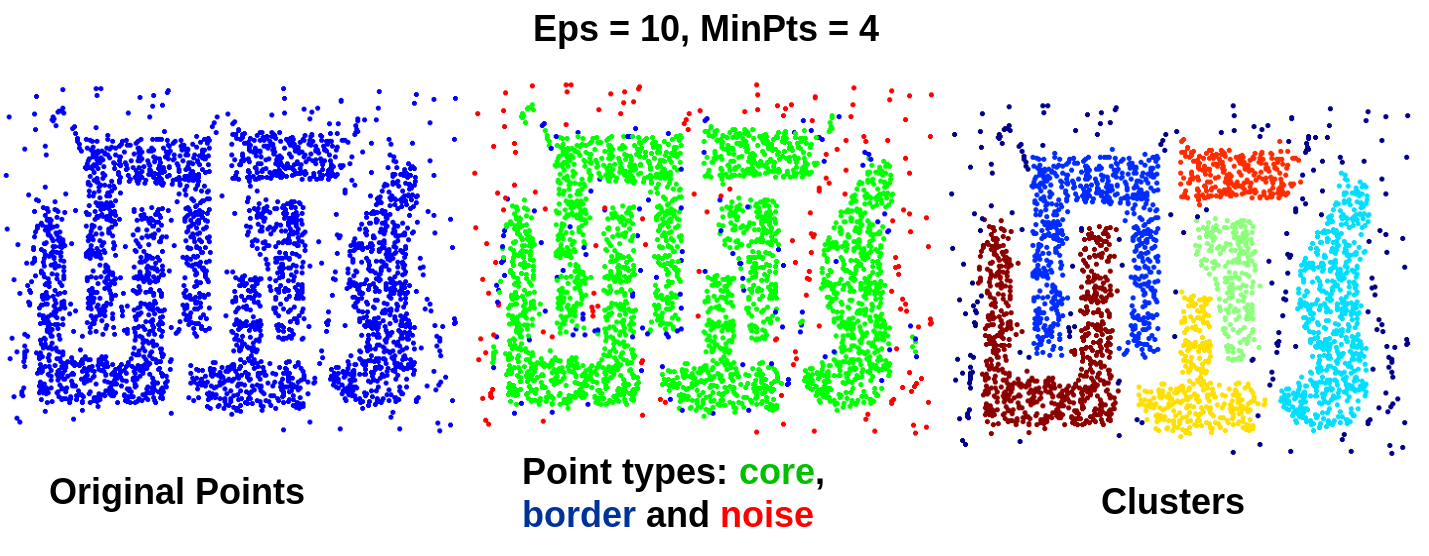
¿Sería posible replicar un proceso de Clustering similar utilizando K-Means? ¿Por qué?
¿Cómo encontrar los Hiperparámetros?
minPts
Para datasets multidimensionales grandes, la regla es:
\[minPts \ge dim + 1\]
Otras recomendaciones:
- Para dos dimensiones: \(minPts=4\) (Ester et al., 1996)
- Para más de 2 dimensiones: \(minPts = 2 \cdot dim\) (Sander et al., 1998)
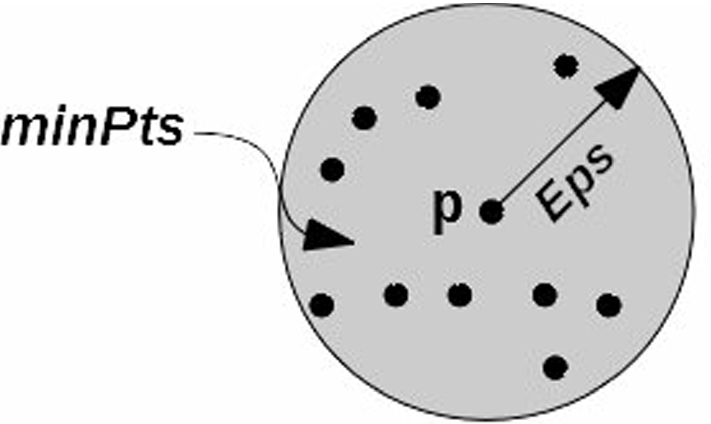
¿Cómo encontrar los Hiperparámetros?
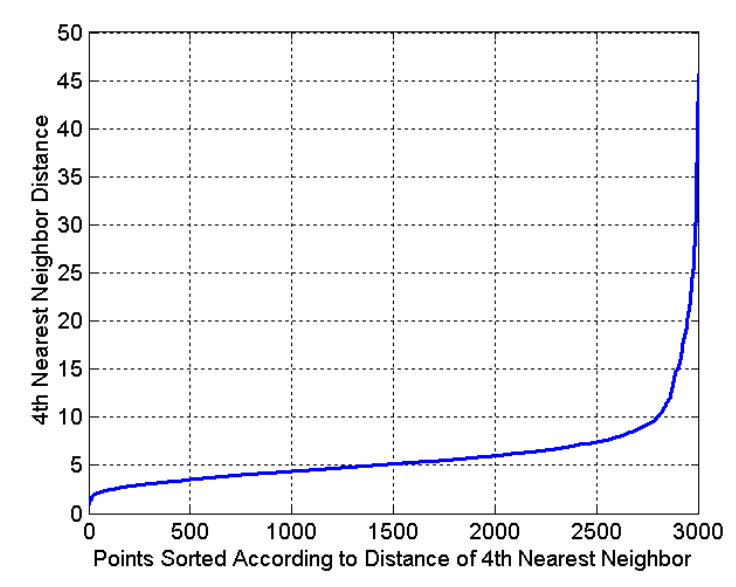
Para encontrar EPS se suele utilizar el método de Vecinos más cercanos.
Idea
La distancia de los puntos dentro de un cluster a su k-ésimo vecino deberían ser similares.
Luego, los puntos atípicos (o ruidosos) tienen el k-ésimo vecino a una mayor distancia.
💡 Podemos plotear la distancia ordenada de cada punto a su k-ésimo vecino y seleccionar un eps cercano al crecimiento exponencial (codo).