TICS-411 Minería de Datos
Clase 6: Evaluación de Clusters
Evaluación
Pensemos en la Evaluación como una medida de desempeño el cuál “evalúa” qué tan bien realizado está el clustering. El objetivo principal del Clustering debe ser siempre la generación de
clusters compactosque esténdiferenciadoslos unos a los otros.
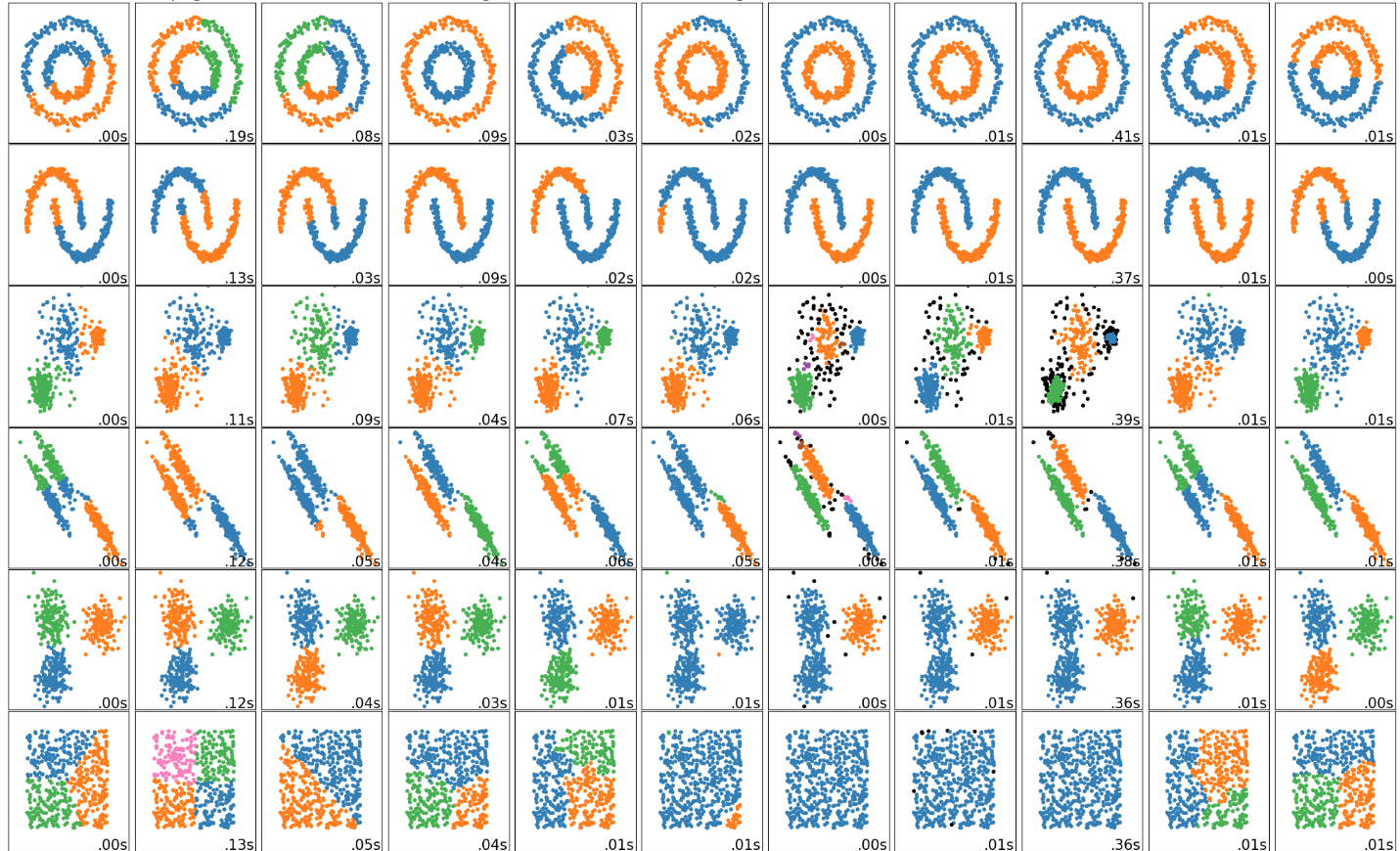
¿Cuál es el Clustering que mejor describe el problema.
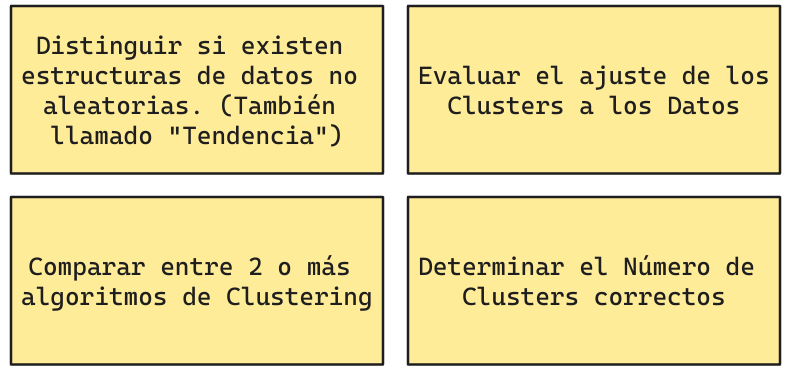
Objetivos de la Evaluación
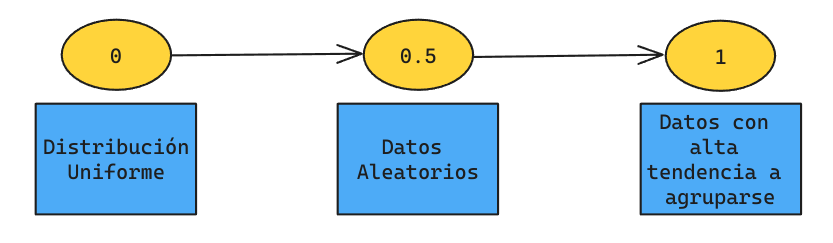
Tendencia: Hopkins
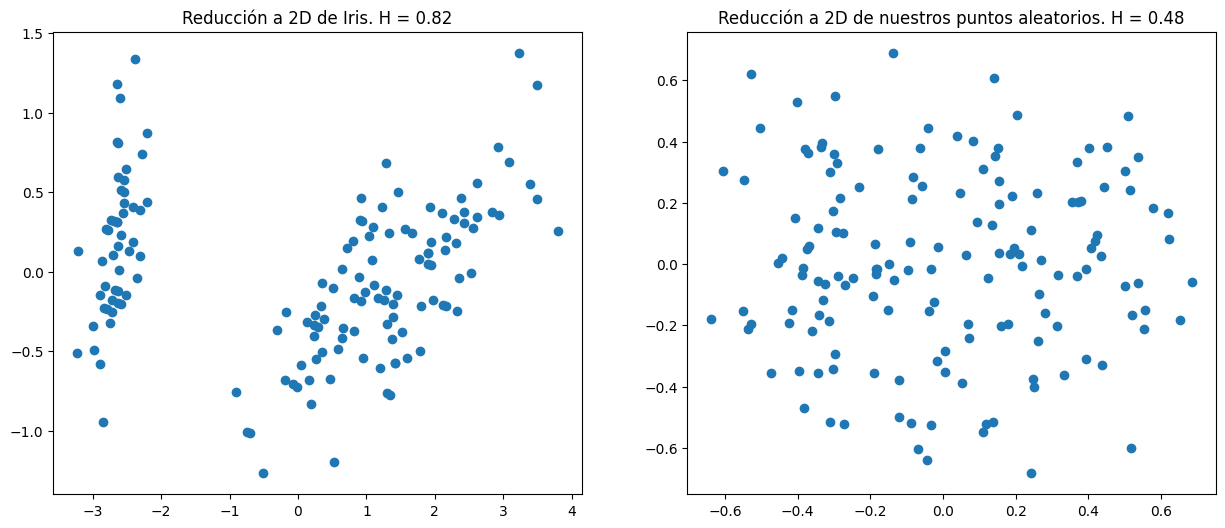
Cálculo Hopkins: Ejemplo p=2
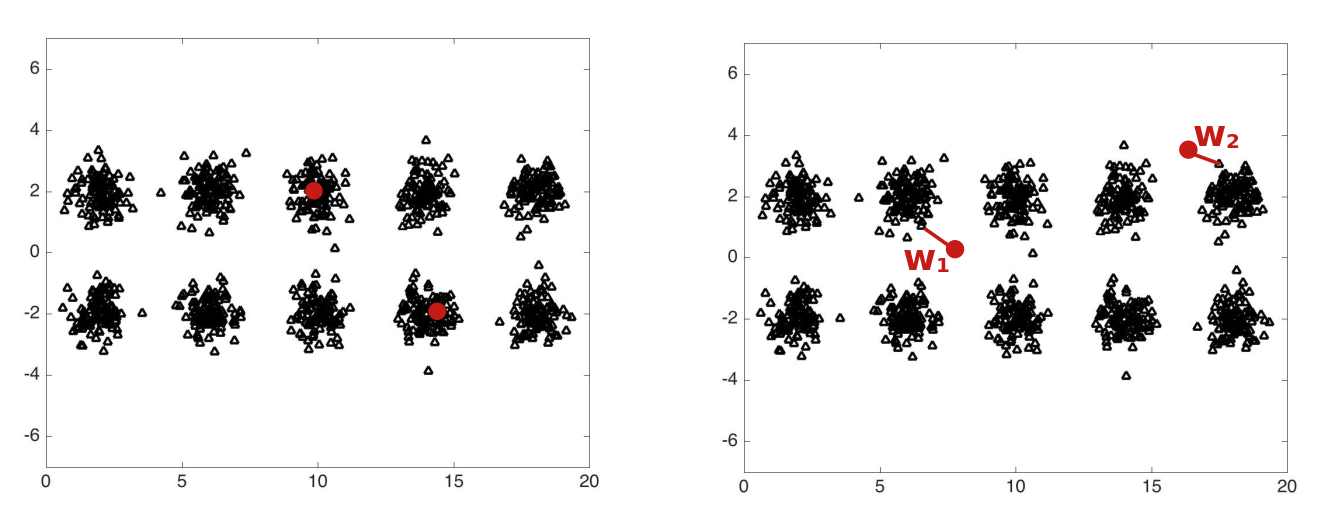
Puntos obtenidos de los Datos
\[u_1\approx 0\]
\[u_2\approx 0\]
Puntos Aleatorios en el Espacio de los Datos
\[w_1\approx 1.8\]
\[w_2\approx 1.12\]
Cálculo Hopkins
\[ H = \frac{w_1 + w_2}{u_1 + u_2 + w_1 + w_2}\] \[ H = \frac{1.8 + 1.12}{0 + 0 + 1.8 + 1.8} = 1\]
Visual Assesment of Tendency (VAT)
Corresponde a una inspección visual de la distancia entre los puntos (matriz de distancia). Colores más oscuros indican menor distancias entre dichos puntos lo que indica mayor cohesión.
Se pueden ver claramente dos bloques.
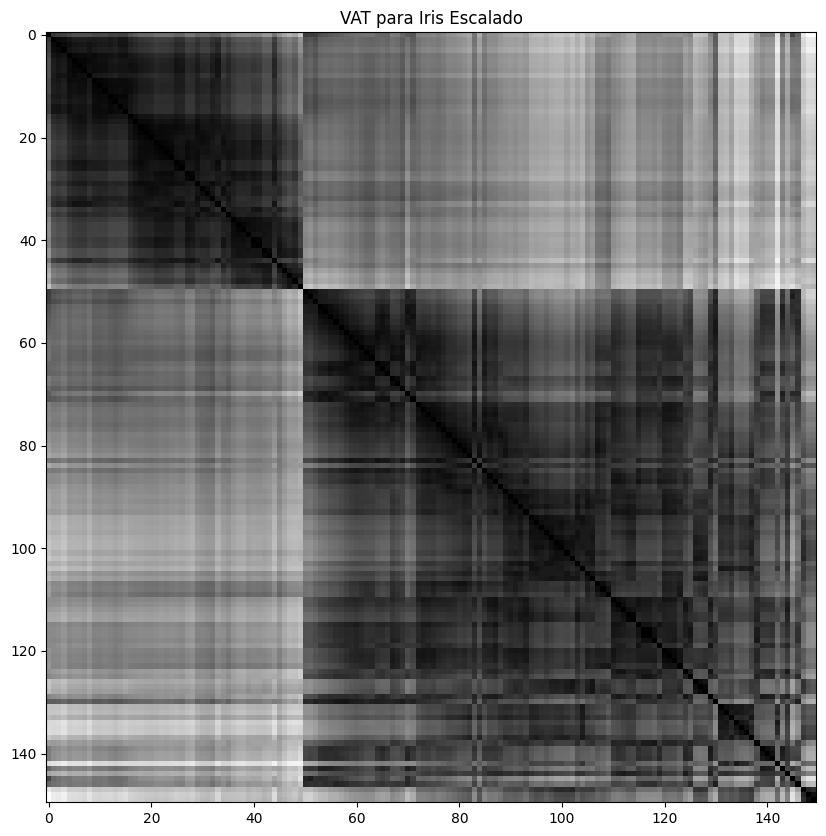
No es posible ver bloques importantes.

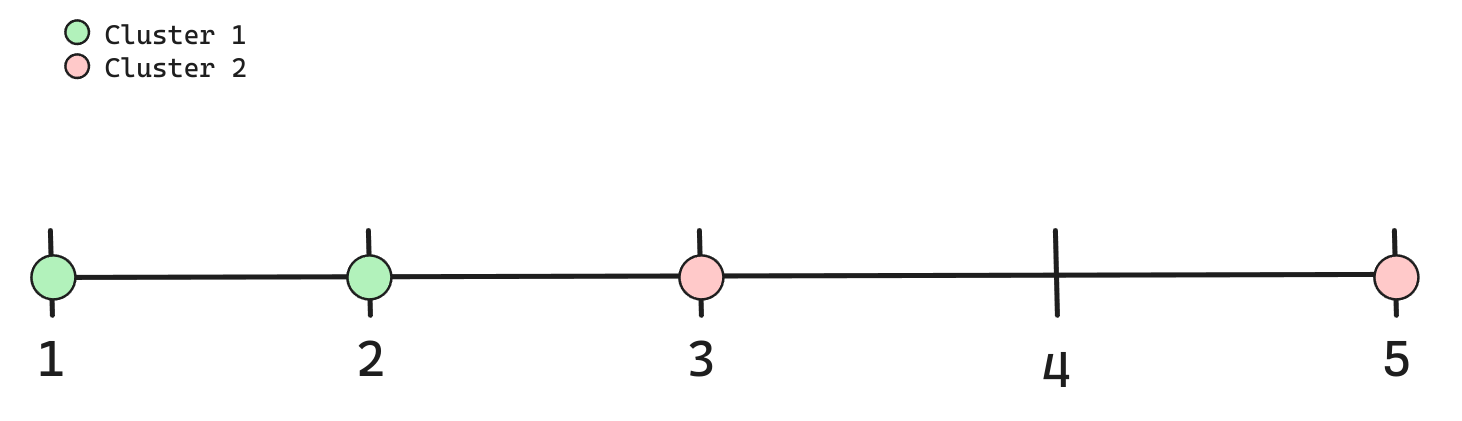
Coeficiente de Silhouette: Ejemplo
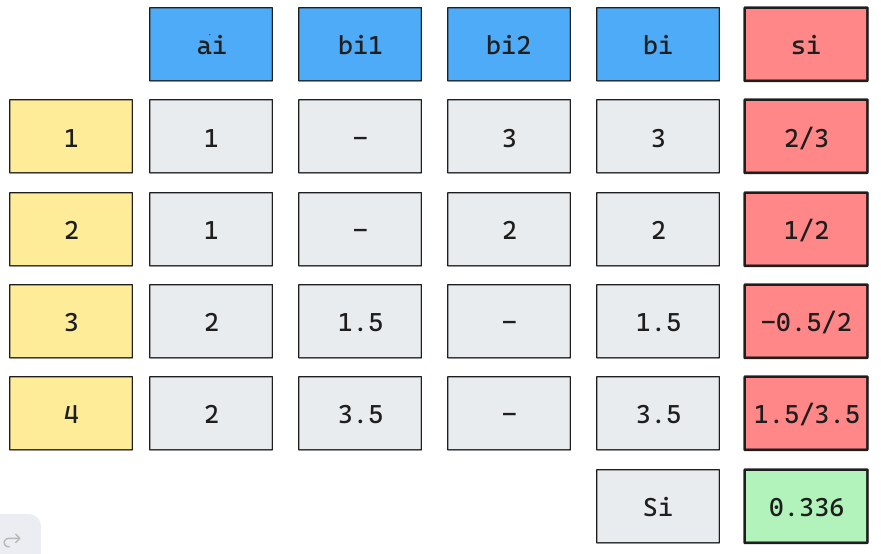
\[C_{silueta} = \frac{1}{n}\sum_{i} s_i\]
- \(a_i\): Distancia promedio del punto \(i\) a todos los
otrospuntos del mismo cluster. (Cohesión) - \(b_{ij}\): Distancia promedio del punto \(i\) a todos los puntos del cluster \(j\) donde no pertenezca \(i\). (Separación)
- \(b_j\): Mínimo de \(b_{ij}\) tal que el punto i no pertenezca al cluster \(j\). (Menor Separación)
Ejercicio Propuesto
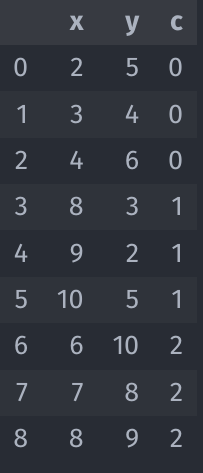
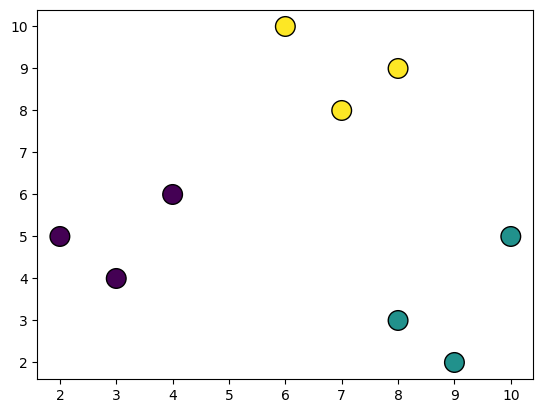
Ejercicio Propuesto
Calcule el coeficiente de Silueta. Tabla de resultado al final de las Slides.
Curvas de Silueta
Es común mostrar los resultados del coeficiente de silueta como gráficos de este estilo:
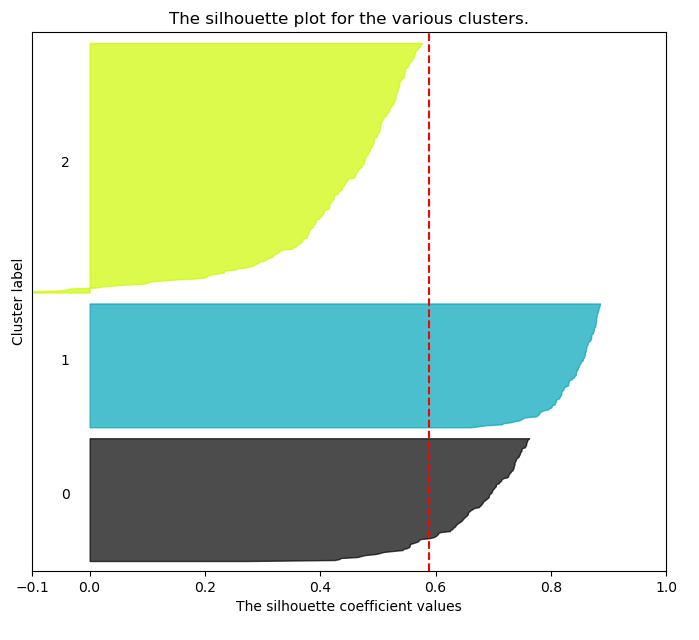
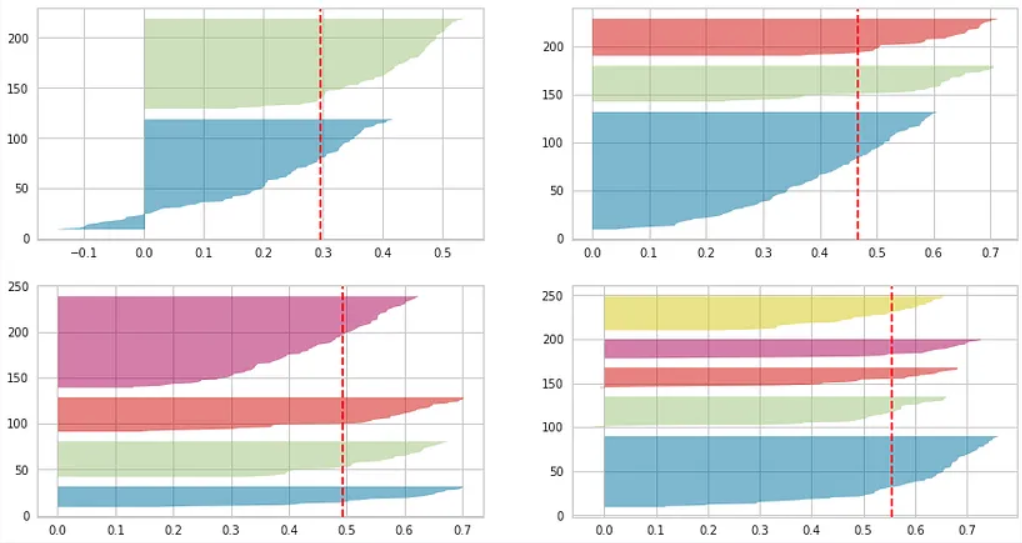
Problemas
- Siluetas negativas.
- Clusters bajo el promedio.
- Mucha variabilidad de Silueta en un sólo cluster.
Resultados Ejercicio Propuesto
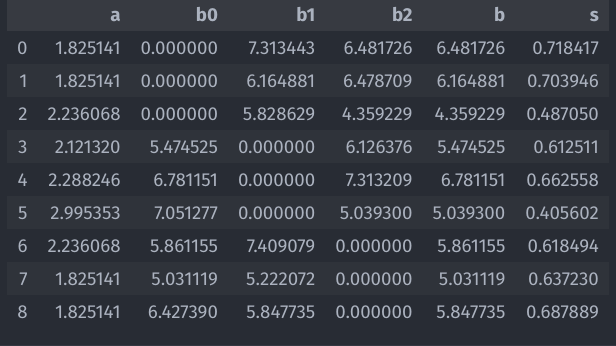
Coeficiente de Silhouette = 0.6148
Comprobar utilizando Scikit-Learn