TICS-411 Minería de Datos
Clase 7: Algoritmo Apriori
Ejemplo: Datos Supermercado
- Datos Transaccionales
-
Una transacción involucra un conjunto de elementos. Una boleta de supermercado muestra el conjunto de elementos comprados por un cliente. Los productos involucrados en una transacción se denominan
items.
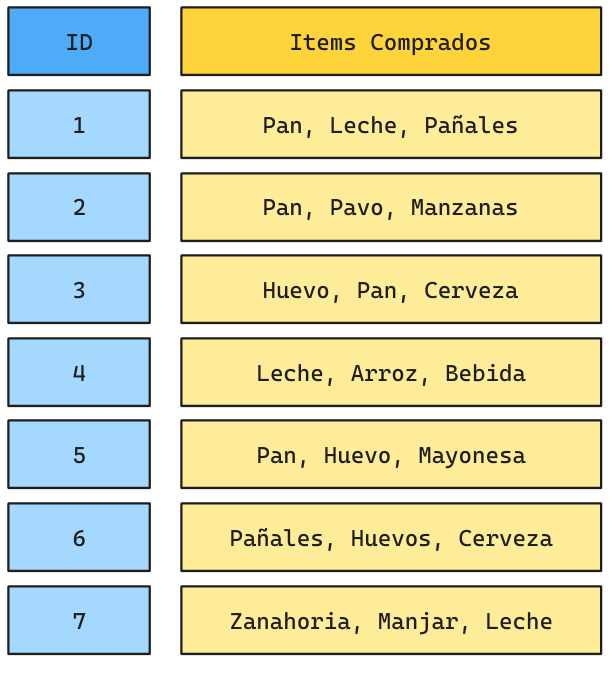

Ejemplo: Datos Supermercado

Ejemplos: Support y Confidence

\[ Supp({Pan}) = 4/7\] \[ Supp({Leche}) = 3/7\] \[ Supp({Pan, Huevo}) = 2/7\]
\[ Conf({Pan} \implies {Huevo}) = \frac{Supp({Pan, Huevo})}{Supp(Pan)} = \frac{2/7}{4/7}\]
\[ Conf({Pan} \implies {Leche}) = \frac{Supp({Pan, Leche})}{Supp(Pan)} = \frac{1/7}{4/7}\] \[ Conf({Leche} \implies {Pan}) = \frac{Supp({Pan, Leche})}{Supp(Leche)} = \frac{1/7}{3/7}\]
Problema
En un dataset transaccional de n productos totales y \(|U_i|\) elementos para la Transacción \(i\).
Se pueden generar un total de \(N_{reglas}\) de asociación:
\[N_{reglas} = \sum_{i=1}^{2^{n}} \sum_{j=0}^{|U_i|}\binom{|U_i|}{j}\]
Si suponemos un supermercado que tiene 1000 productos, y transacciones que pueden ir entre 1 y 50 productos. El problema es muy costoso, y se podrían eventualmente generar demasiadas combinaciones.

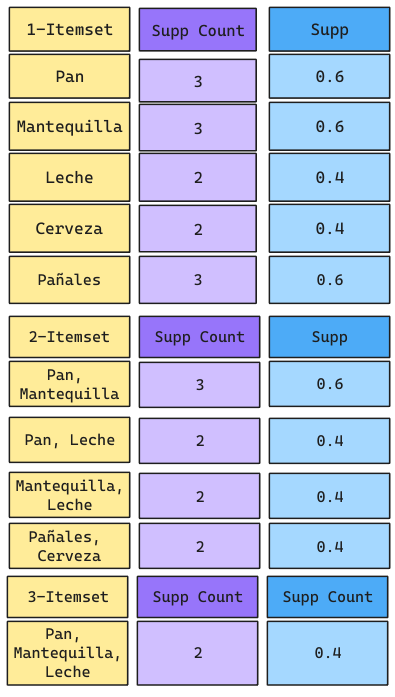
Ejemplo Apriori
Supongamos el siguiente dataset transaccional:
Supongamos que queremos calcular las reglas de asociación que tengan un MinSupp=40% y un MinConf=70%.
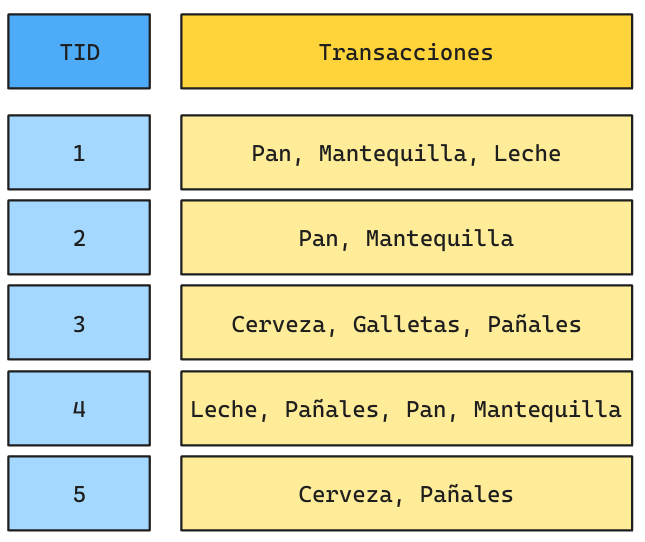
Podríamos pensar que MinSupp y MinConf son los hiperparámetros de este algoritmo.
Ejemplo Apriori: Iteración 1
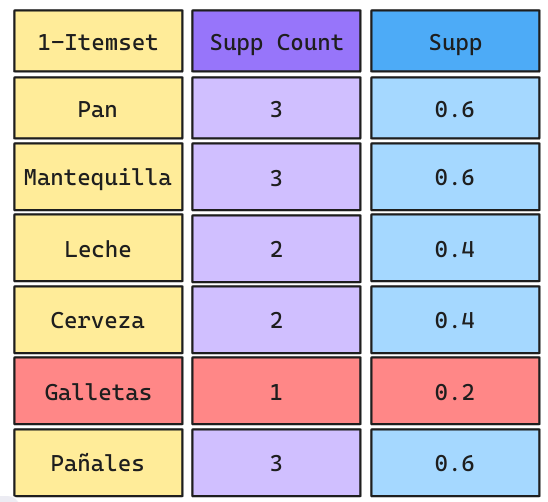
Galletas NO CUMPLE con el Soporte Mínimo solicitado. Por lo tanto, lo elimino y genero relaciones de 2 productos sin considerar Galletas.
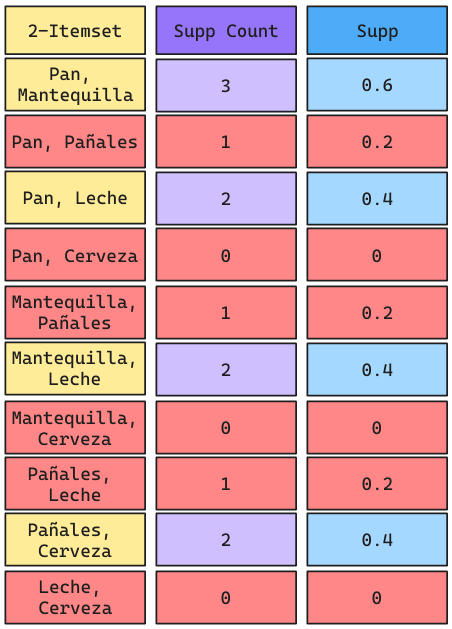
Ejemplo Apriori: Iteración 2
Acá NO SE ELIMINA ningún producto, ya que en los itemsets que sobrevivieron hay Pan, Mantequilla, Leche, Pañales y Cerveza.
Ejemplo Apriori: Iteración 3
Se puede apreciar que los únicos 3 productos que sobreviven son Pan, Mantequilla y Leche. Por lo tanto, NO ES POSIBLE generar reglas con 4 productos.
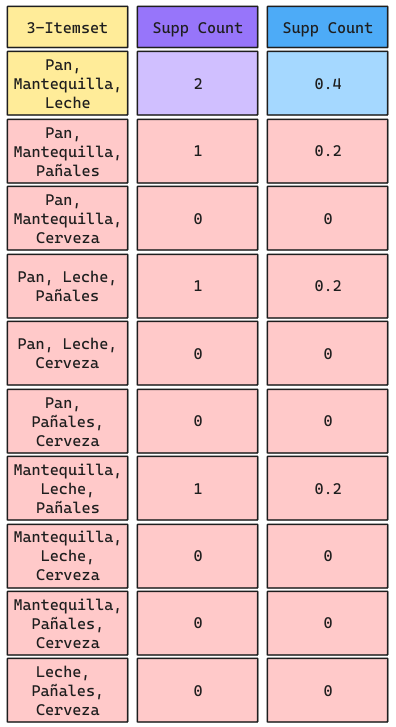
Ejemplo Apriori: Generación de Reglas
- Para
{Pan, Mantequilla}:
\(Conf(Pan \implies Mantequilla) = \frac{Supp(Pan, Mantequilla)}{Supp(Pan)} = \frac{3}{3}\)✅ \(Conf(Mantequilla \implies Pan) = \frac{Supp(Pan, Mantequilla)}{Supp(Mantequilla)} = \frac{3}{3}\)✅
- Para
{Pan, Leche}:
\(Conf(Pan \implies Leche) = \frac{Supp(Pan, Leche)}{Supp(Pan)} = \frac{2}{3}\) ❌ \(Conf(Leche \implies Pan) = \frac{Supp(Pan, Leche)}{Supp(Leche)} = \frac{2}{2}\) ✅
- Para
{Mantequilla, Leche}:
\(Conf(Mantequilla \implies Leche) = \frac{Supp(Mantequilla, Leche)}{Supp(Mantequilla)} = \frac{2}{3}\) ❌ \(Conf(Leche \implies Mantequilla) = \frac{Supp(Mantequilla, Leche)}{Supp(Leche)} = \frac{2}{2}\) ✅
Ejemplo Apriori: Generación de Reglas
- Para
{Pañales, Cerveza}:
\(Conf(Pañales \implies Cerveza) = \frac{Supp(Pañales, Cerveza)}{Supp(Pañales)} = \frac{2}{3}\)❌ \(Conf(Cerveza \implies Pañales) = \frac{Supp(Pañales, Cerveza)}{Supp(Cerveza)} = \frac{2}{2}\)✅
- Para
{Pan, Mantequilla, Leche}:
\(Conf({Pan, Mantequilla} \implies {Leche}) = \frac{Supp(Pan, Mantequilla, Leche)}{Supp(Pan, Mantequilla)} = \frac{2}{3}\)❌ \(Conf({Pan, Leche} \implies {Mantequilla}) = \frac{Supp(Pan, Mantequilla, Leche)}{Supp(Pan, Leche)} = \frac{2}{2}\)✅ \(Conf({Mantequilla, Leche} \implies {Pan}) = \frac{Supp(Pan, Mantequilla, Leche)}{Supp(Mantequilla, Leche)} = \frac{2}{2}\)✅
\(Conf({Leche} \implies {Pan, Mantequilla}) = \frac{Supp(Pan, Mantequilla, Leche)}{Supp(Leche)} = \frac{2}{2}\)✅ \(Conf({Mantequilla} \implies {Pan, Leche}) = \frac{Supp(Pan, Mantequilla, Leche)}{Supp(Mantequilla)} = \frac{2}{3}\)❌ \(Conf({Pan} \implies {Mantequilla, Leche}) = \frac{Supp(Pan, Mantequilla, Leche)}{Supp(Pan)} = \frac{2}{3}\)❌
Resultado Final
Itemset MinSupp = 40%
Reglas Finales MinConf = 70%
\[Pan \implies Mantequilla\] \[Mantequilla \implies Pan\] \[Leche \implies Pan\] \[Leche \implies Mantequilla\] \[Cerveza \implies Pañales\] \[\{Pan, Leche\} \implies Mantequilla\]
\[\{Mantequilla, Leche\} \implies Pan\] \[Leche \implies \{Pan, Mantequilla\}\]
Insights:
- El Pan, la Leche y la Mantequilla están relacionados.
- Parece ser que si llevo Cervezas también llevo Pañales.