TICS-411 Minería de Datos
Clase 8: Introducción al Aprendizaje Supervisado
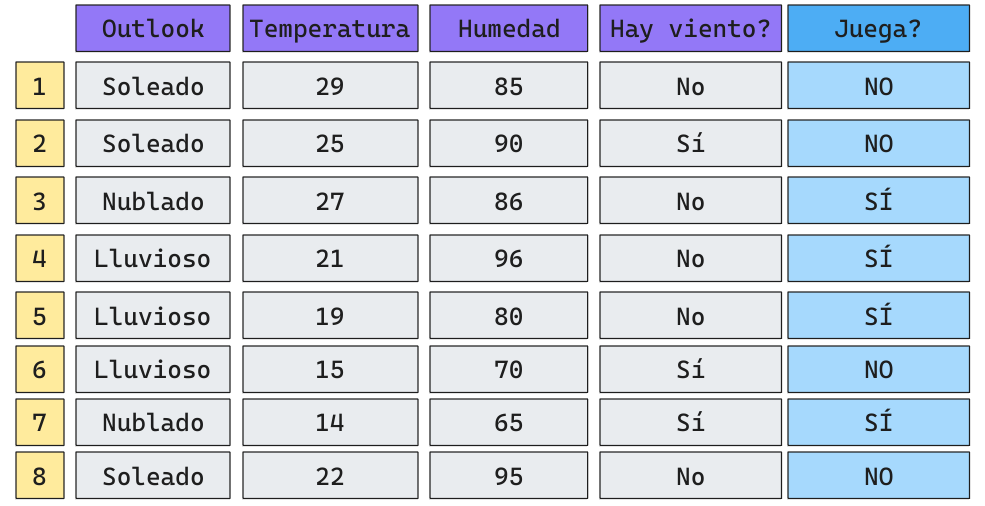
Ejemplo
Queremos generar un algoritmo de aprendizaje tal que dado un cierto set de datos predigamos si es que a un niño se le dará o no permiso para jugar.
Problema de Clasificación Binaria (Dos clases opuestas).
Clasificación: Intuición
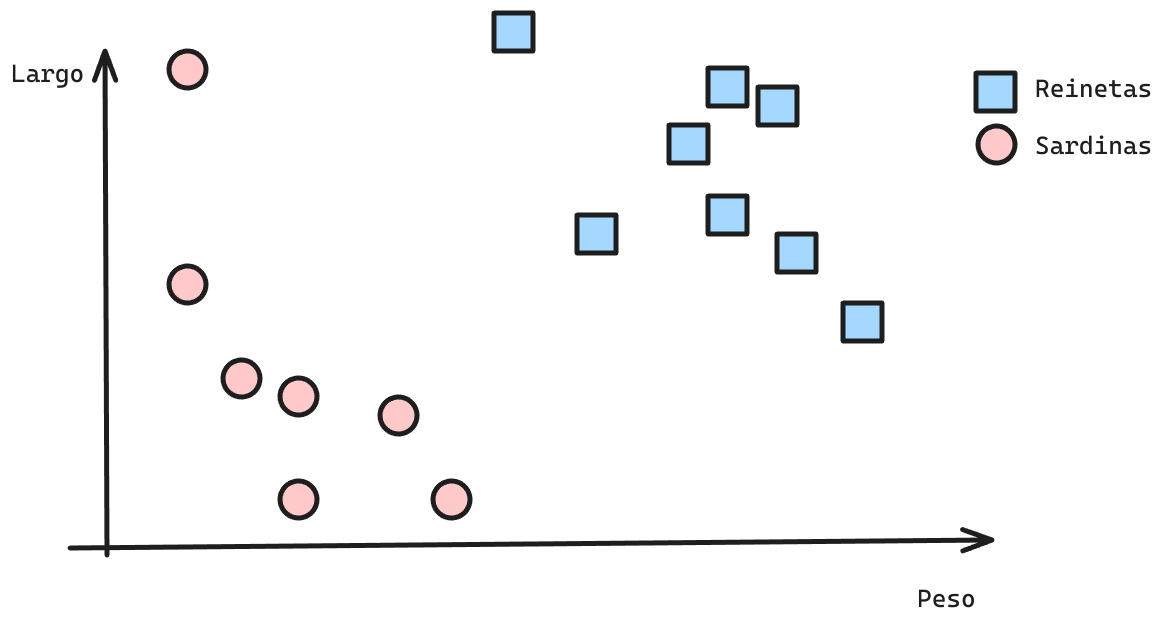
Supongamos el siguiente problema de clasificación. Tenemos un algoritmo, que dadas las variables
LargoyPesosean capaces de predecir si es que un Pez es una Reineta o una Sardina.
Clasificación: Intuición
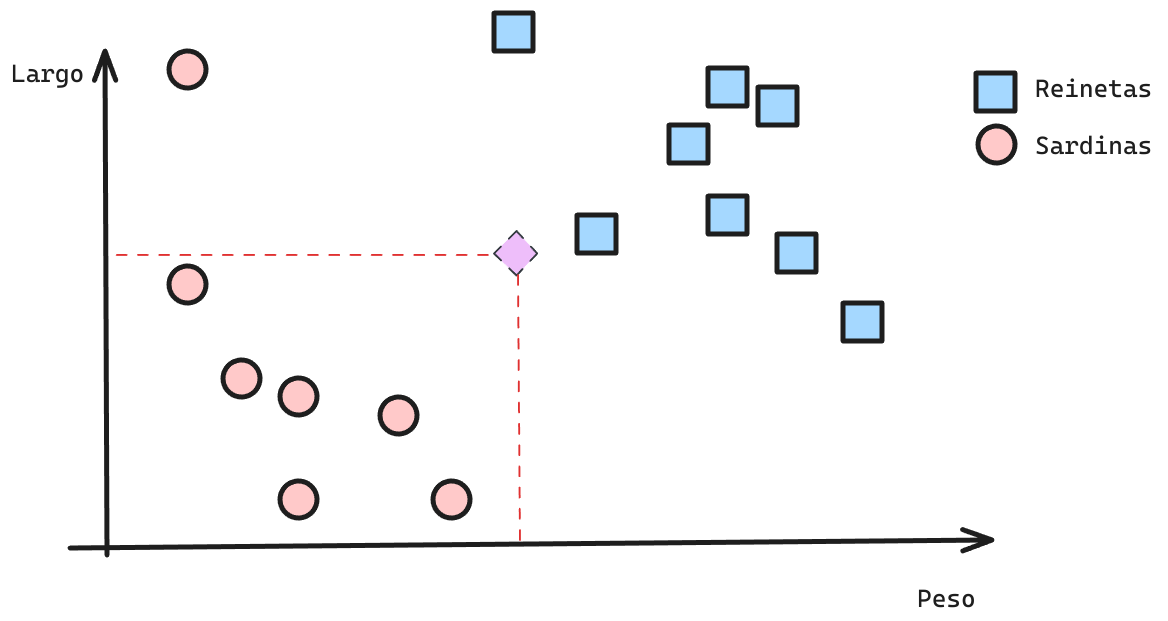
- Queremos encontrar una
Regla de Decisión(Decision Rule) que permita clasificar correctamente un punto nuevo. - Distintos modelos son capaces de encontrar distintas reglas de decisión. Por lo tanto, sus predicciones pueden ser completamente distintas.
K-Nearest Neighbors
El modelo de vecinos más cercanos, o KNN por sus siglas en Inglés es un modelo basado en
distancias. Suregla de decisiónse basa en imitar el comportamiento de sus \(K\) vecinos más cercanos por votación (para clasificación) o la media (para regresión).
K es un hiperparámetro de este modelo.
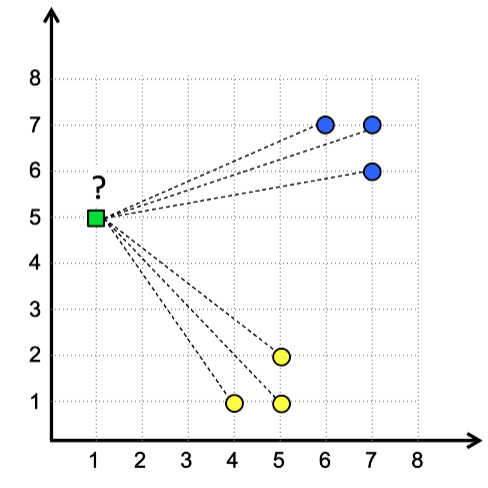
- Supongamos \(K = 3\).
- Es decir, tomaremos los 3 vecinos más cercanos.
En general es una buena idea elegir vecinos impares. ¿Por qué?
KNN: Paso 2 (Test Time)
- Inference Time
- Corresponde al periodo donde el modelo debe emitir una predicción.
En este caso, KNN calcula las distancias del punto a predecir (en verde) a todos los otros puntos existentes (proceso caro).
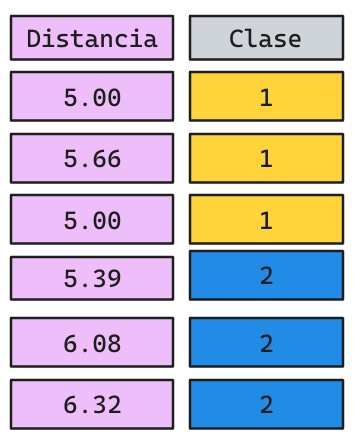
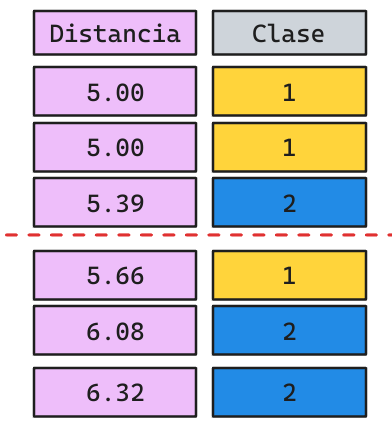
- La predicción corresponderá a la etiqueta mayoritaria por
votacioń
- La predicción corresponderá a la etiqueta mayoritaria por
votacioń. - ¿Cuál sería una buena estrategia de predicción para un modelo de Regresión?
Fronteras de Decisión
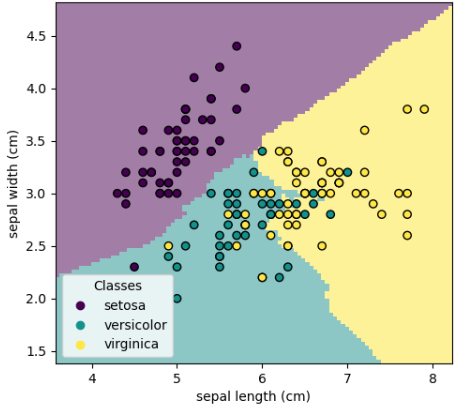
- Implicitamente, todo modelo de Machine Learning generará lo que se llama una Frontera de Decisión.
- Si un punto no visto cae dentro de su frontera entonces se le asigna dicha etiqueta.