TICS-411 Minería de Datos
Clase 9: Evaluación de Modelos
Uso de un Modelo
¿Cómo saber que el modelo está funcionando como esperamos?
Métricas: Matriz de Confusión
La Matriz de Confusión ordena los valores correctamente predichos y también los distintos errores que el modelo puede cometer.
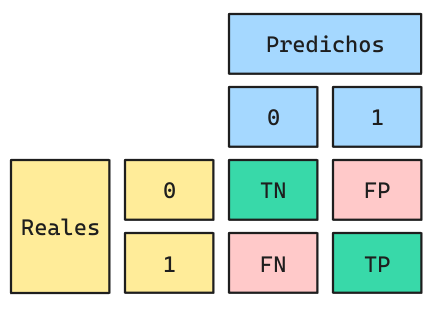
- TP (Verdaderos Positivos)
- Corresponde a valores reales de la clase 1 que fueron correctamente predichos como clase 1.
- TN (Verdaderos Negativos)
- Corresponde a valores reales de la clase 0 que fueron correctamente predichos como clase 0.
- FP (Falsos Positivos)
- Corresponde a valores reales de la clase 0 que fueron incorrectamente predichos como clase 1.
- FN (Falsos Negativos)
- Corresponde a valores reales de la clase 1 que fueron incorrectamente predichos como clase 0.
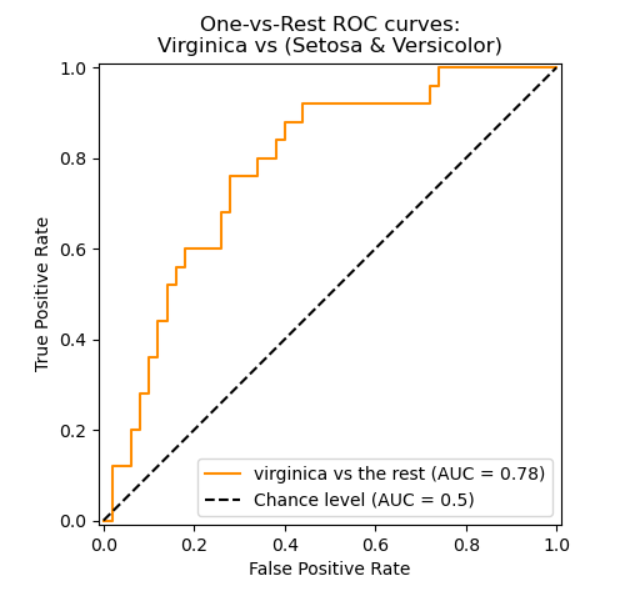
Curva ROC
La curva ROC fue desarrollada en 1950 para analizar señales ruidosas. La curva ROC permite al operador contrapesar la tasa de verdaderos positivos (Eje \(y\)) versus los falsos positivos (Eje x).
El área bajo la curva representa la
calidad del modelo. Una manera de interpretarla es como la probabilidad de que una predicción de la clase positiva tenga mayor probabilidad que una de clase negativa. En otras palabras, mide que las probabilidades se encuentren correctamente ordenadas. Por lo tanto varía entre 0.5 y 1.
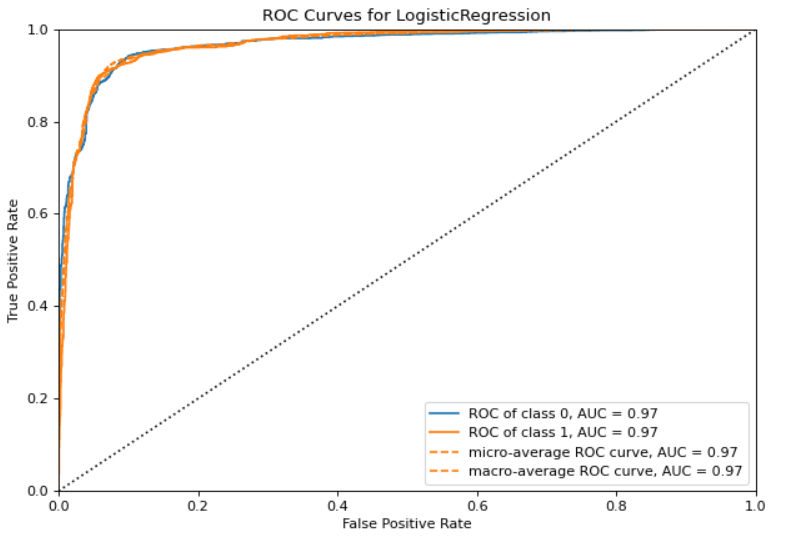
ROC \(\sim\) 0.5

ROC \(\sim\) 1

Implementación en Python: Matriz de Confusión
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(y_true, y_pred)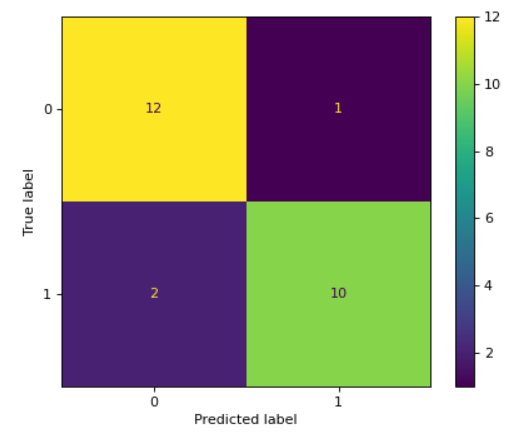
Implementación en Python: Curva ROC
Curva de Aprendizaje: Training
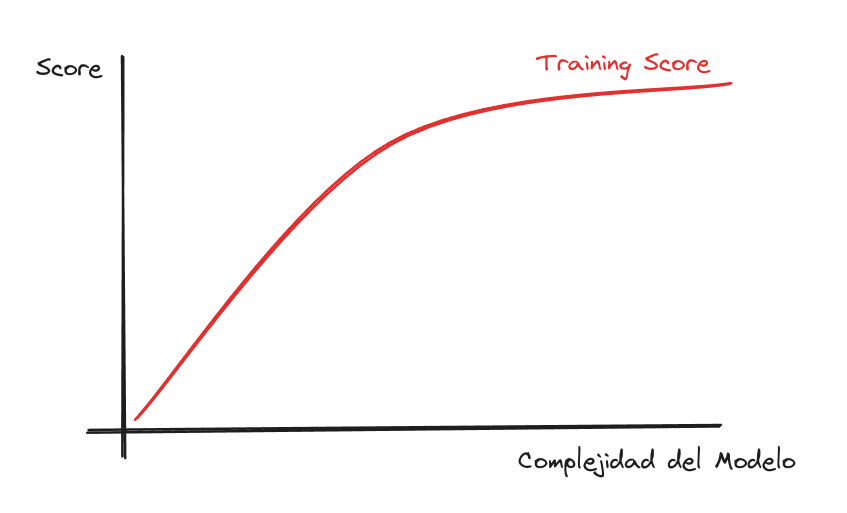
¿Qué sería la Complejidad del Modelo?
Curva de Aprendizaje: Validación
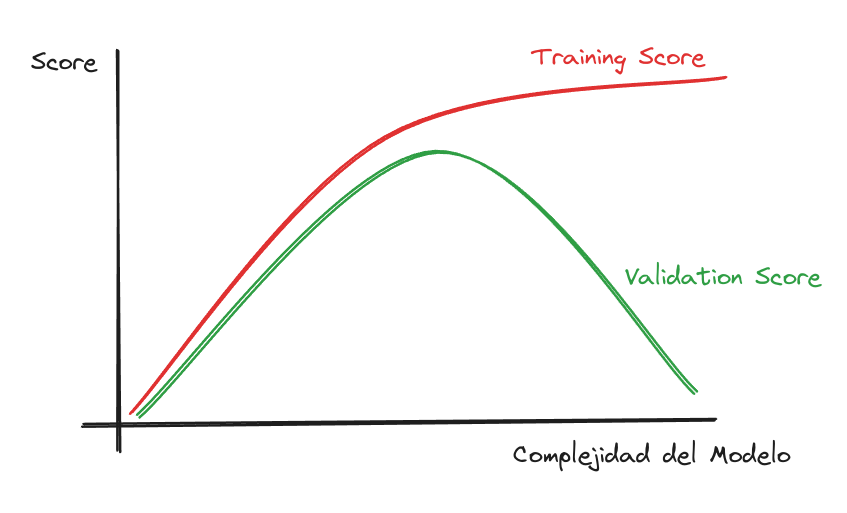
¿Por qué el modelo pierde rendimiento cuando aumenta su Complejidad?
Curva de Aprendizaje: Mejor Ajuste
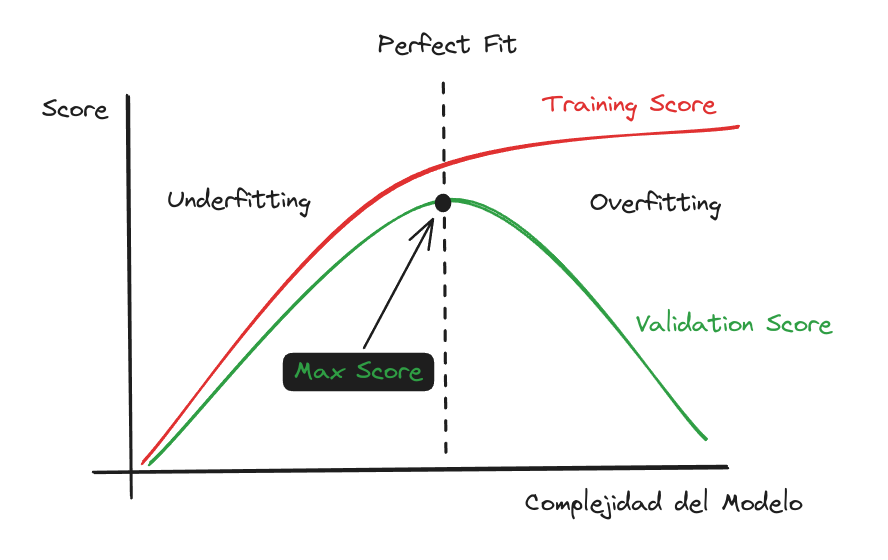
Overfitting:
Gran diferencia entre Training y Validation Score.
Underfitting:
Poca diferencia entre Training y Validation Score, pero con ambos puntajes “relativamente bajos”.
Proper fitting o Sweet Spot:
Corresponde al mejor puntaje en el set de Validación. Donde también la distancia entre Train y Test es poca.
Complejidad de un Modelo
¿Qué modelo es un mejor clasificador?
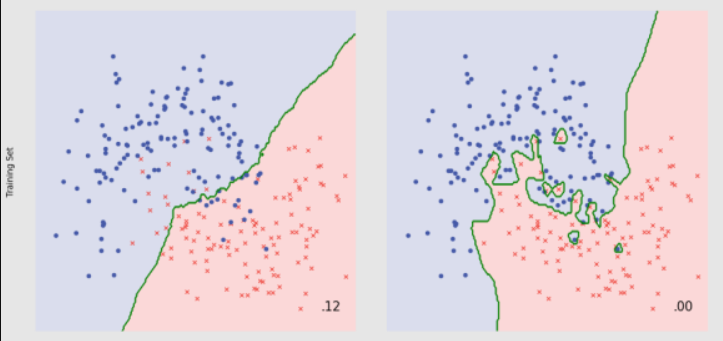
Bias Variance Tradeoff
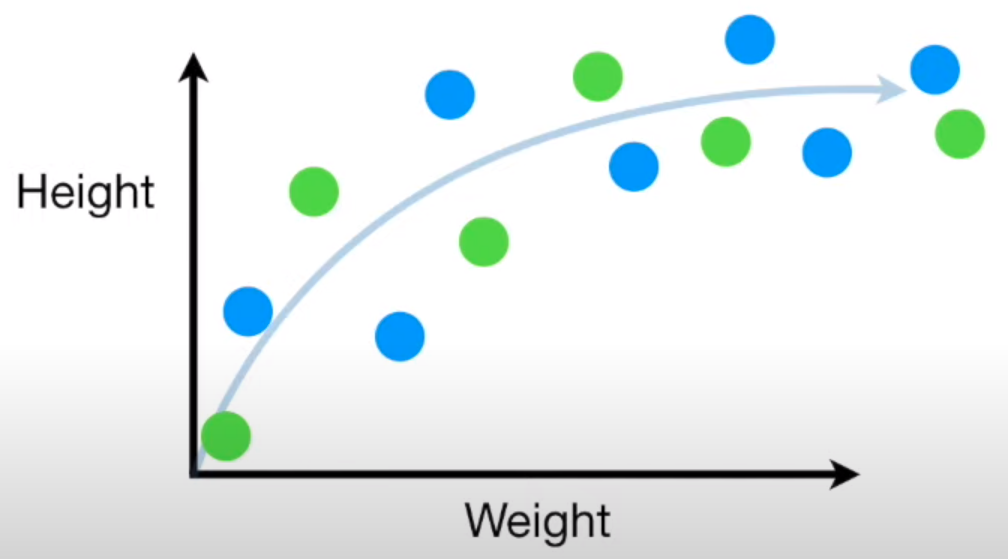
- Los puntos azules serán puntos que usaremos para entrenar.
- Los puntos verdes serán puntos que usaremos para validar.
Bias Variance Tradeoff: Bias
- Bias
-
Se refiere a la incapacidad de un modelo de capturar la verdadera relación entre los datos.
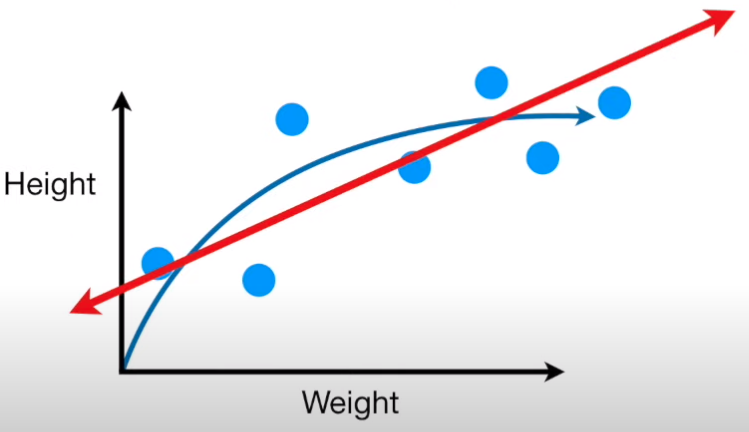
El modelo está “sesgado” a tomar una cierta relación que no necesariamente existe.
Bias Variance Tradeoff: Variance
- Variance
-
Se refiere a la diferencia de ajuste entre datasets (Train y Validación).
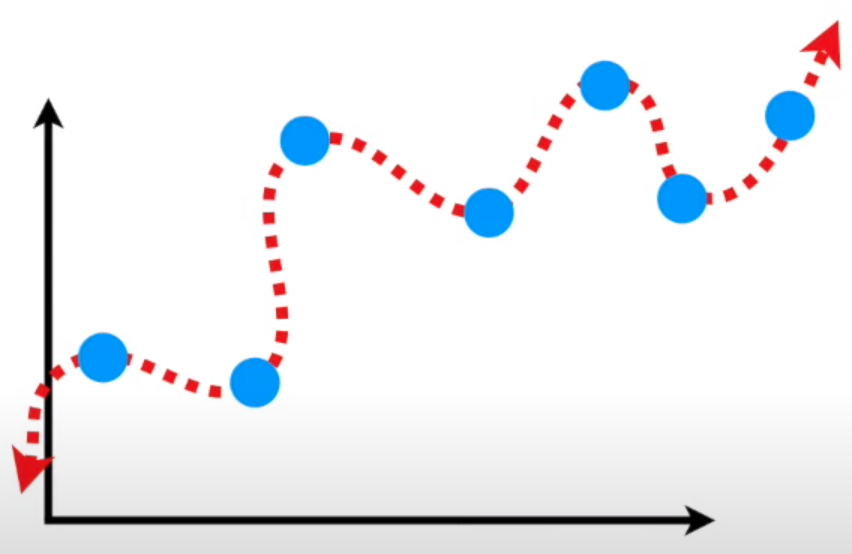
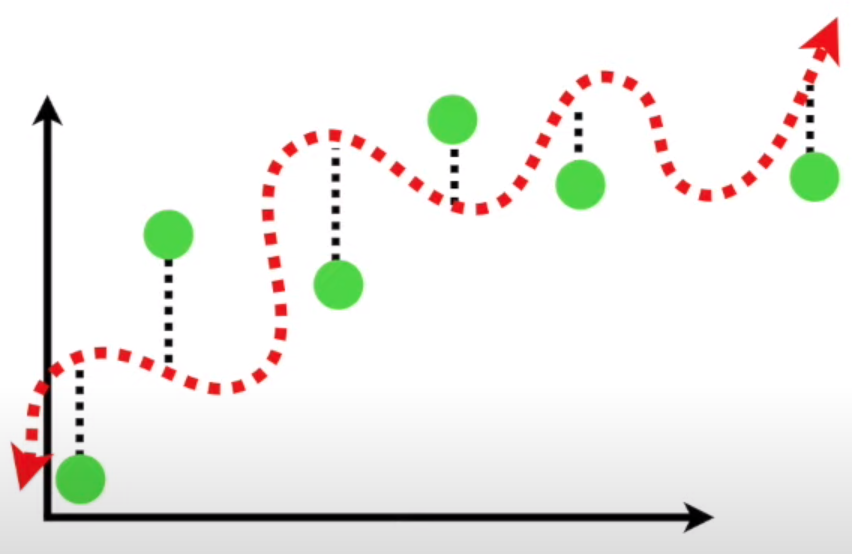
El modelo varía demasiado su comportamiento entre Training y Testing Time.
Complejidad de un Modelo
Overfitting
Regularización: Se refiere a una penalización para disminuir su complejidad.
Modelos más simples: Utilizar modelos con una Frontera de Decisión más simple.
Más datos!!! Más datos más dificil aprender, por lo tanto, modelos complejos se ven más beneficiados de esto.
Underfitting

Quitar Regularización
Modelos más complejos
Más variabilidad en los datos!!! Podría ser que los datos no permitan aprender patrones más complejos.
Validación Cruzada: Holdout
También es conocido como
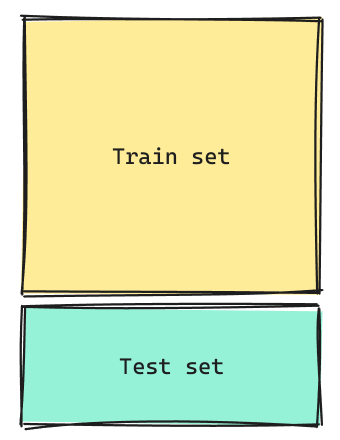
Train Test Splito simplementeSplit. Corresponde a la separacion de nuestra data cuando con el proposito de aislar observaciones que el modelo no vea para una correcta evaluación.

- El
train setes la porción de los datos que se utilizaráexclusivamentepara entrenar los datos.
- El
test setes la porción de los datos que se utilizará exclusivamente para validar los datos. - El
test setsimula los datos que eventualmente entrarán el modelo para obtener una predicción.
- Normalmente se utilizan splits del tipo 70/30, 80/20 o 90/10.
- ¿Cuál es el problema con este tipo de validación?
Variante Holdout
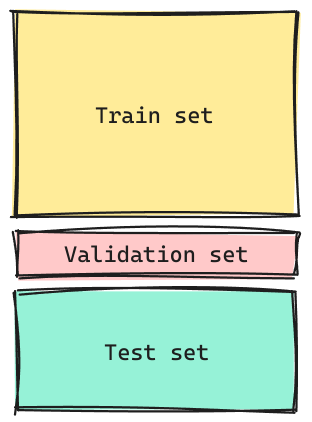
- Se agrega un
validation setel cuál se utilizará para escoger loshiperparámetrosque muestren un mejor poder de generalización.
- El
train sety eltest setcumplen la misma función que tenían antes.
Variante Holdout: Procedimiento
Procedimiento
- Repetir para cada
Modeloa probar.
- Vamos a entender un modelo como la combinación de un
Algoritmo de Aprendizaje+Hiperparámetros+Preprocesamiento.
- Se entrena cada
Modeloen eltrain set. Se mide una métrica de Evaluación apropiada utilizando elValidation Set. La llamaremos métrica de Validación. - Se escoge el mejor
Modelocomo el que tenga la mejor métrica de Validación. - Se reentrena el modelo escogido pero ahora en un “nuevo set” compuesto por el
Train set+ elValidation set. - Se reporta el rendimiento final del mejor modelo (al momento del diseño) utilizando métricas medidas en el
Test Set.
K-Fold CV
- El proceso de Holdout podría llevar a un proceso de overfitting del Test Set si el modelo no es lo suficientemente robusto.
El K-Fold CV se aplica sólo al Train Set y la métrica final que se reporta utilizando el Test Set.
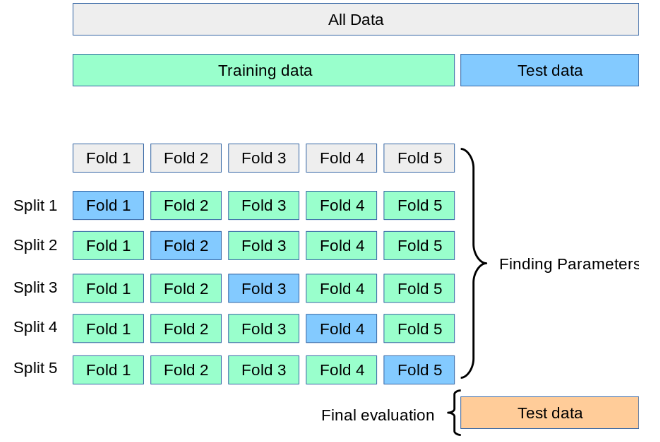
- Fold
- Entenderemos Folds como divisiones que haremos a nuestro dataset. (En el ejemplo se divide el dataset en 5 Folds).
- Split
-
Entenderemos Splits, como iteraciones. En cada iteración utilizaremos un Fold como
Validation Sety todos los Folds restantes comoTrain Set.
- La métrica final se calculará como el promedio de las Métricas de Validación para cada
Split. - A veces la variabilidad (medido a través de la Desviación Estándar) también es usado como criterio para elegir el mejor modelo.
En la práctica se le llama incorrectamente Cross Validation al K-Fold.
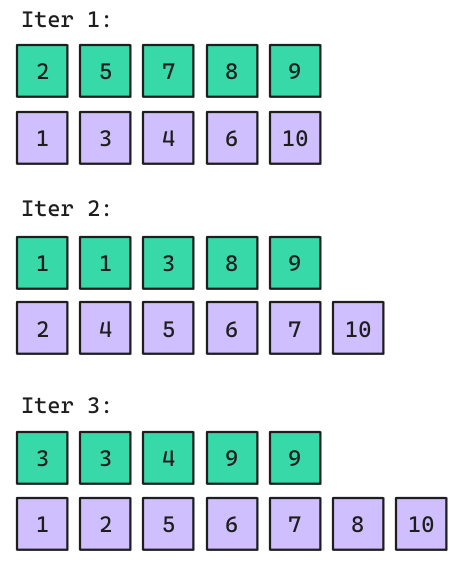
Bootstrap
Consiste en generar subgrupos aleatorios con repetición. Normalmente requiere específicar el tamaño de la muestra de entrenamiento. Y la cantidad de repeticiones que del proceso. Los sets de validación (en morado) acá se denominan out-of-bag samples.
- La métrica final a reportar se mide como el promedio de los out-of-bag samples.