TICS-579-Deep Learning
Clase 1: Introducción a los Shallow Models
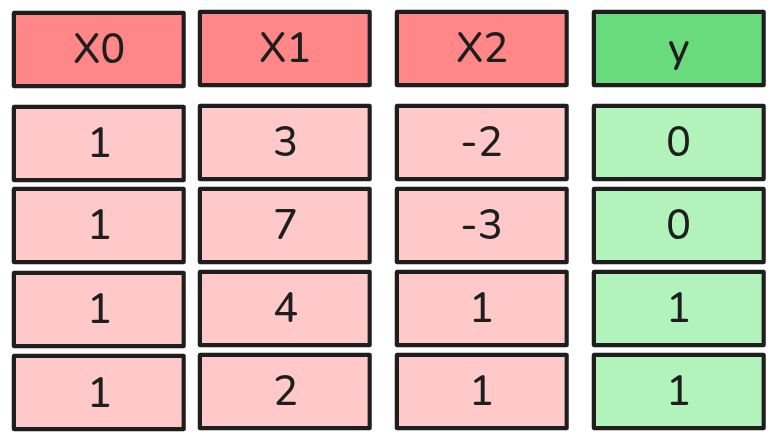
Modelo Básico de Clasificación Binaria
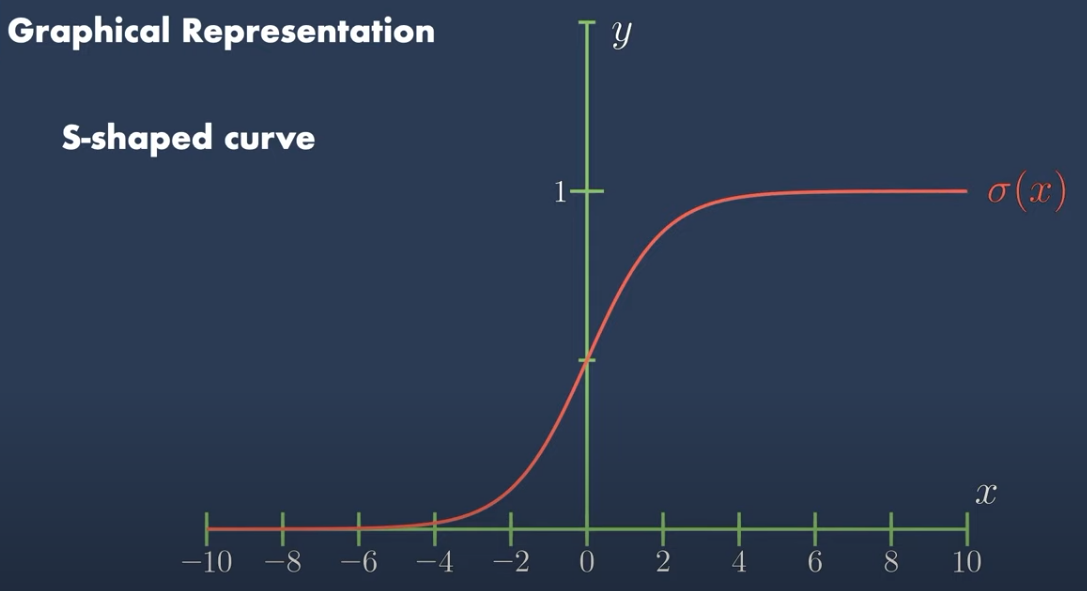
Pero tenemos el problema de que \(y\) puede tomar cualquier valor real (no está acotada), y necesitamos que \(p\) esté entre 0 y 1. Para ello podemos aplicar la función Logística o Sigmoide.
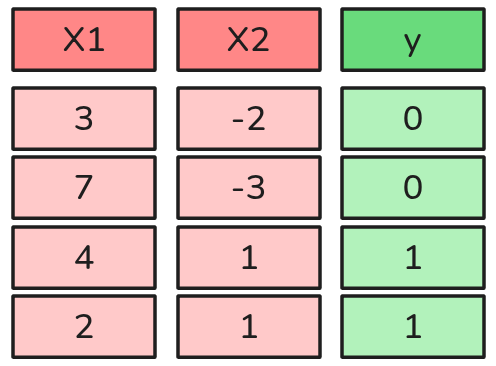
Modelo Básico de Clasificación Binaria
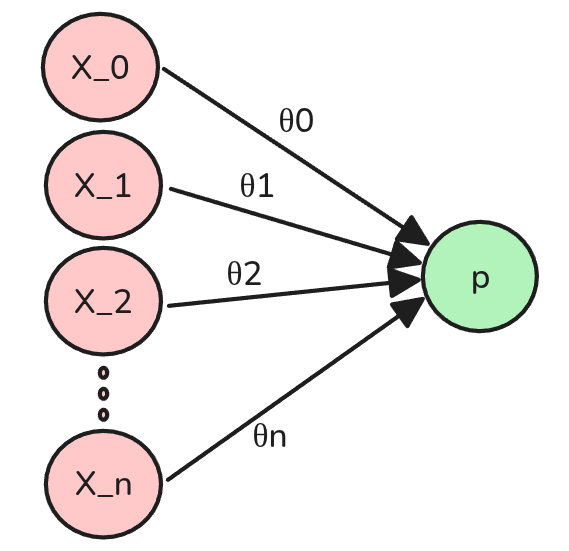
Redes Neuronales
El término Red Neuronal es un término marketero, lo único que hace es mostrar de manera gráfica lo que nosotros acabamos de definir.
Regresión Logística: Método de Optimización
Parámetros óptimos se encuentran con:
\[\theta = \theta - \alpha \nabla_\theta L(\theta)\]
😇 ¿Cuánto vale el gradiente de la Función de Pérdida?
Vamos a calcular el gradiente haciendo trampa. Puede que algunos se enojen, pero para nosotros es suficiente.

Regresión Logísitca: Gradiente
Supongamos lo siguiente:
- \(a= X \theta\)
- \(b = \sigma(a)\)
- \(c = log(b)\)
- \(d = log(1-b)\)
- \(e = y^T c\)
- \(f = (1-y)^T d\)
- \(L* = e + f\)
- \(L = -\frac{1}{m} L*\)
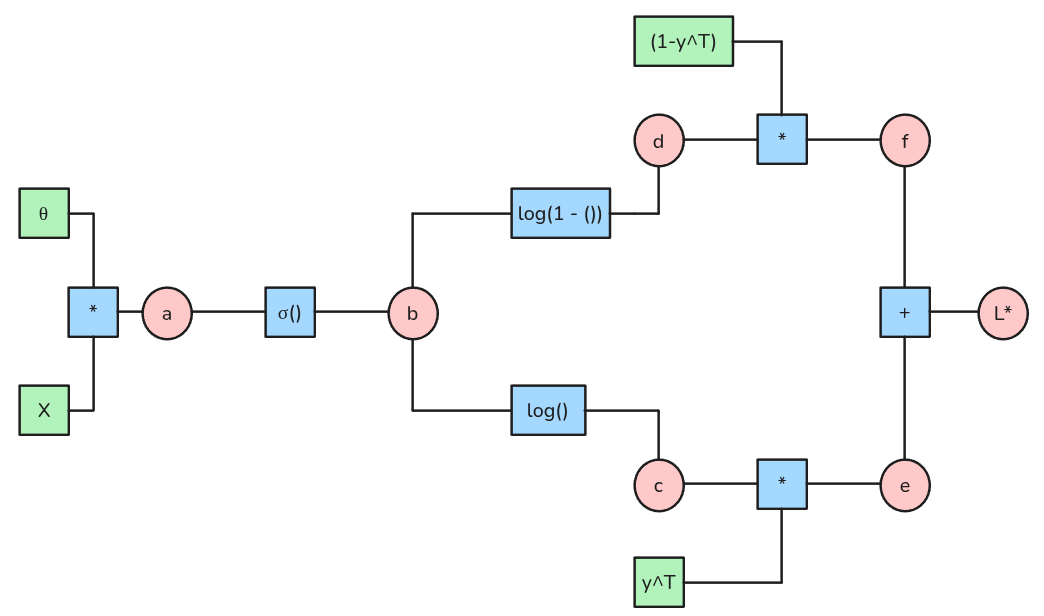
Regresión Logísitca: Gradiente
\[\frac{\partial L*}{\partial \theta} =\left[\frac{y^T - b}{b(1-b)}\right] \cdot \sigma(a)' \cdot X\]
Luego reemplazamos que \(b=\sigma(a)\) y \(\sigma(a)'=\sigma(a)(1-\sigma(a))\):
Obtenemos que:
\[\frac{\partial L}{\partial \theta} = \frac{1}{m}\left[\sigma(X\theta)_{m \times 1} - y^T_{1 \times m}\right]X_{m \times (n+1)}\]