TICS-579-Deep Learning
Clase 11: Transformers
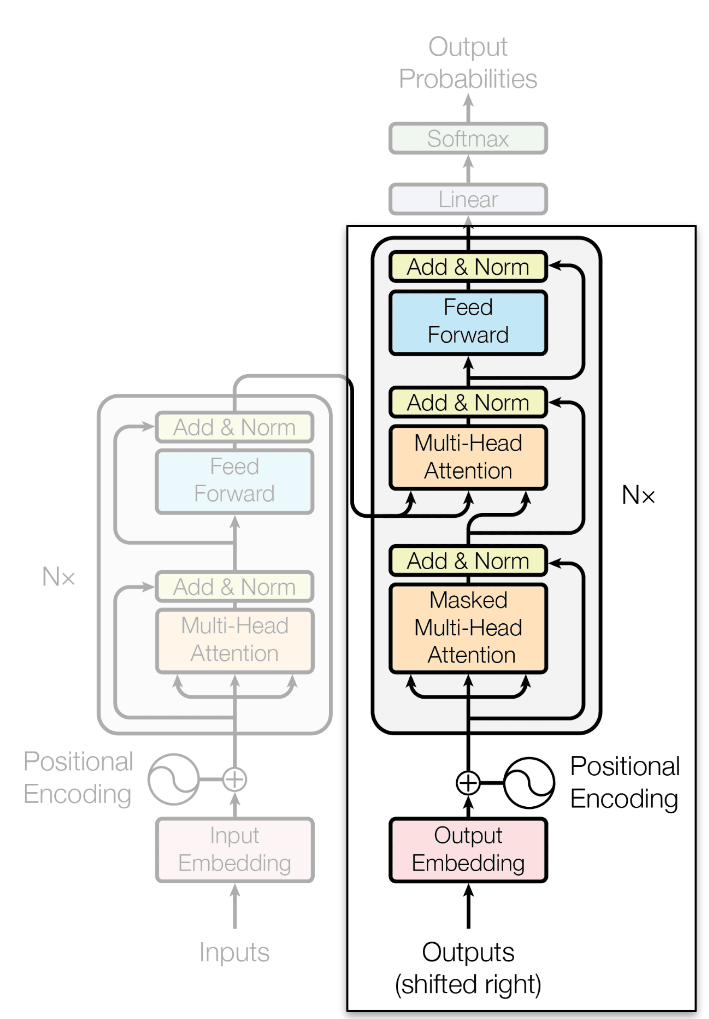
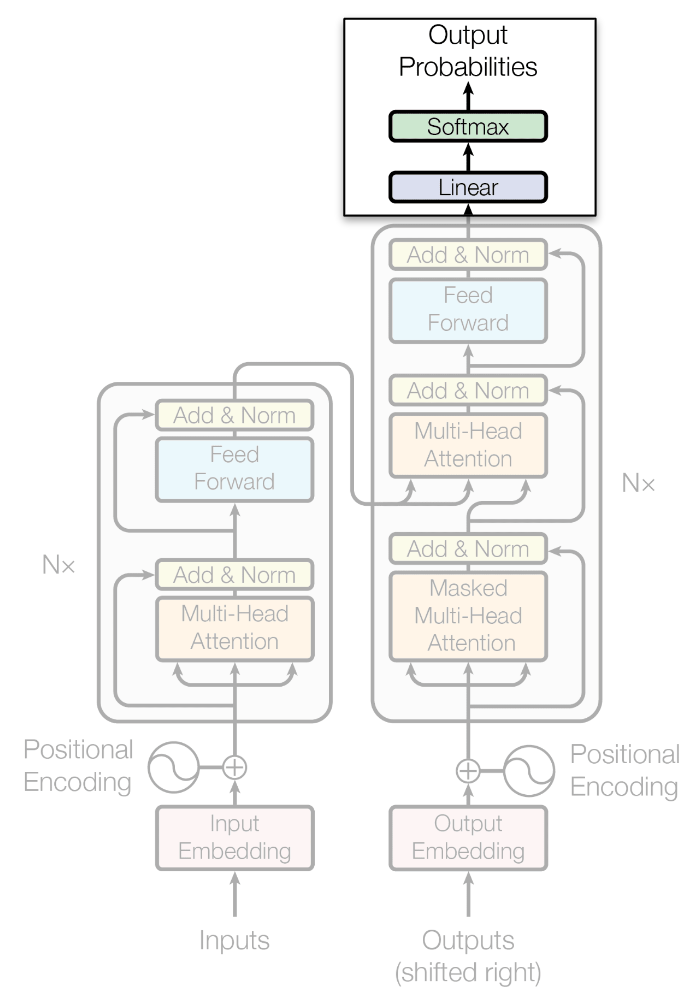
Transformers (Attention is all you need, 2017)
- Transformers
- Corresponden a la arquitectura más moderna diseñada al día de hoy. Está basado en mecanismos de atención y posee hasta 4 tipos de atención distintos.
![]()
Encoder

Decoder
Embedding
- Embedding
- No es más que una Lookup Table. Es una tabla de parámetros entrenables que permitirá transformar índices enteros en vectores de una dimensión determinada.
Esta clase permite el ingreso de tensores de cualquier tamaño \((*)\) y devuelve tensores de tamaño \((*,H)\). Donde \(H\) es el embedding_dim.
La sección 3.1 del paper se refiere al tamaño del embedding como \(d_{model}=512\).
En la sección 3.4 del paper se menciona que los parámetros de los embeddings son multiplicados por \(\sqrt{d_{model}}\).
![]()
Embedding
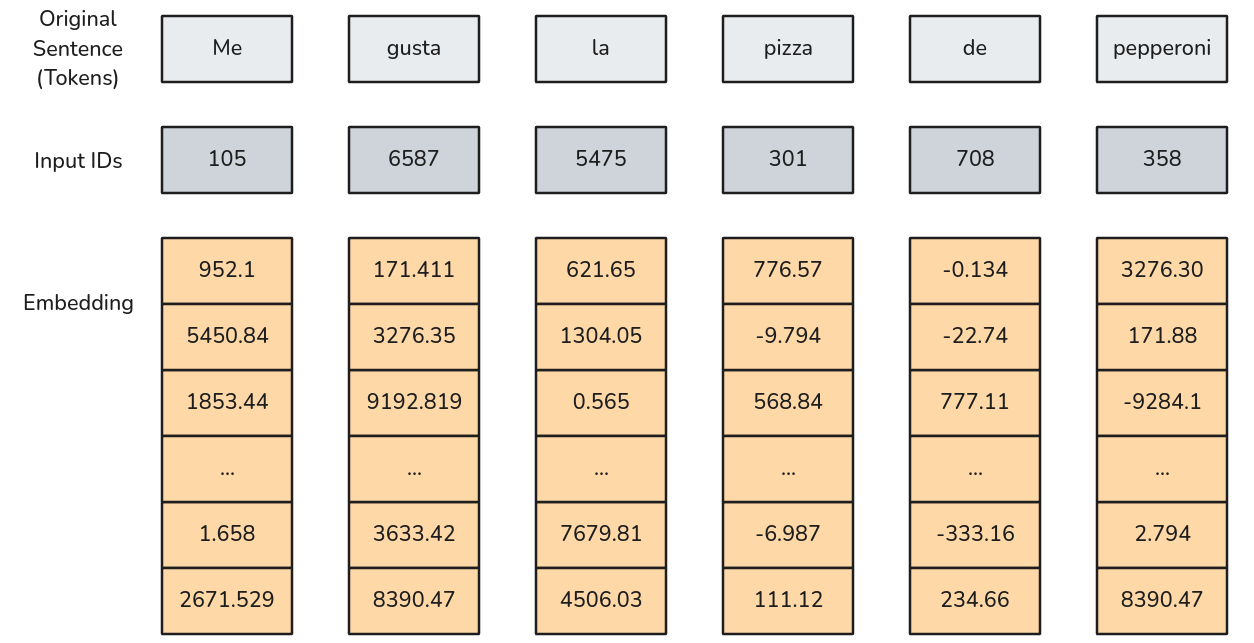
Cada token está representado por un Embedding de \(d_{model}\) dimensiones.
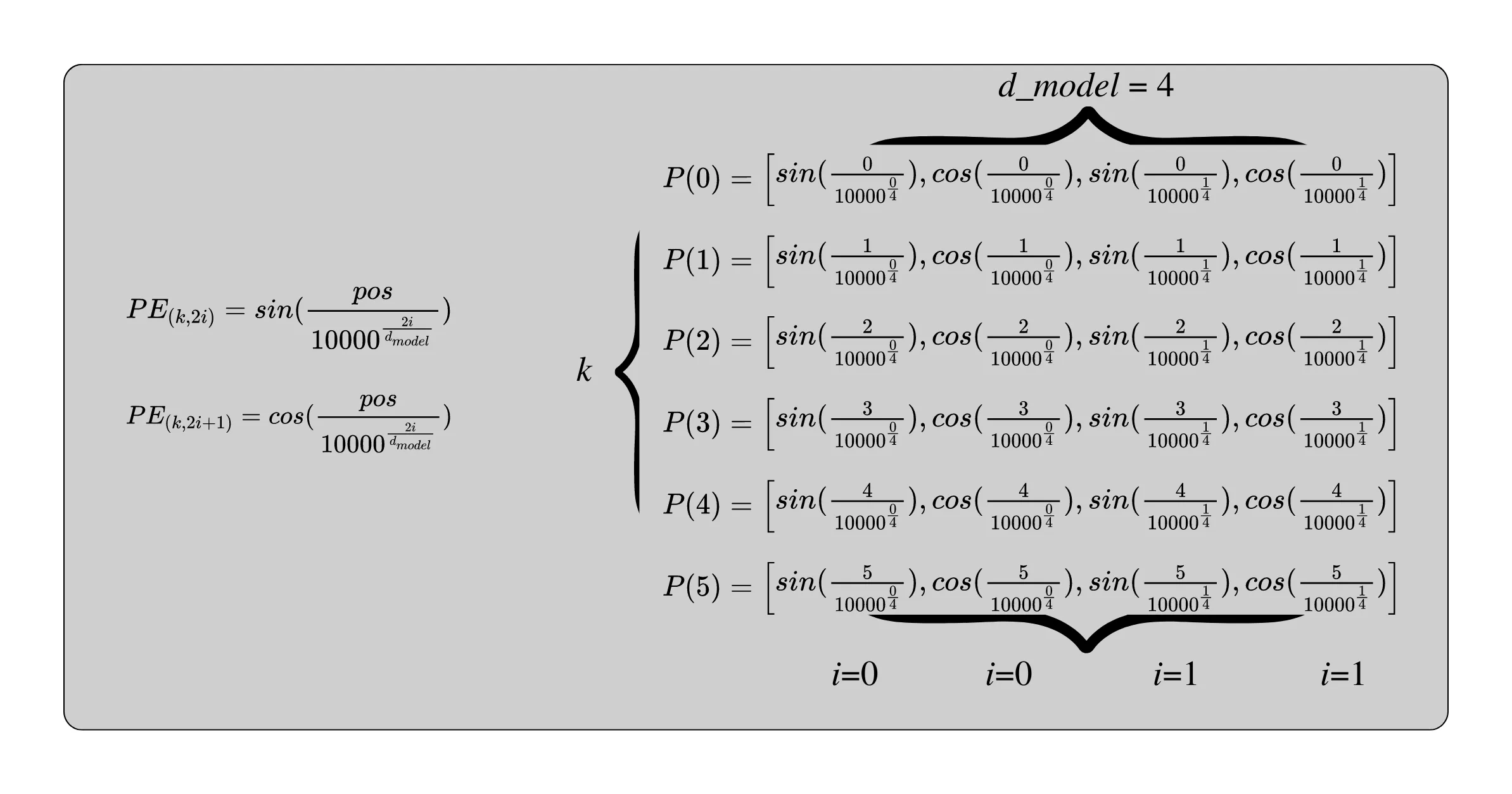
Positional Encoder
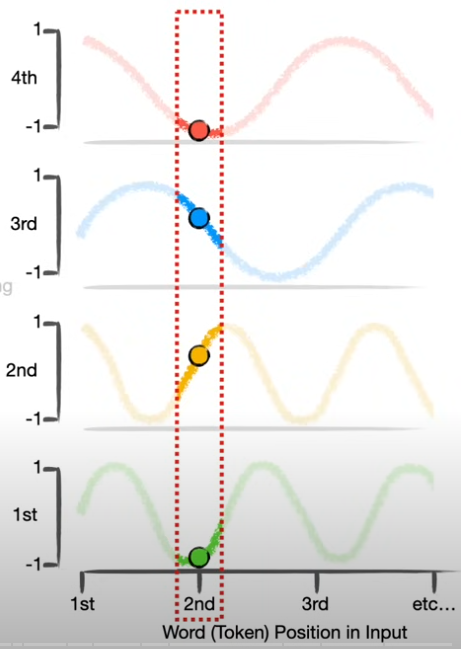
Un potencial problema que puede tener un transformer es reconocer el orden de las frases.
No es lo mismo decir “El perro del papá mordió al niño” que “El perro del niño mordió al papá”. Las palabras usadas en ambas frases son exactamente las mismas, pero en un orden distinto implican desenlaces distintos. ¿Cómo podemos entender el concepto de orden si no tenemos recurrencia?
Incluso algunos órdenes no tienen tanto sentido lógico: “El niño del perro mordió al papá”.
- Positional Encoder
-
Corresponden a una manera en la que se pueden generar un vector único que representa el orden en el que aparece cada token.
![]()
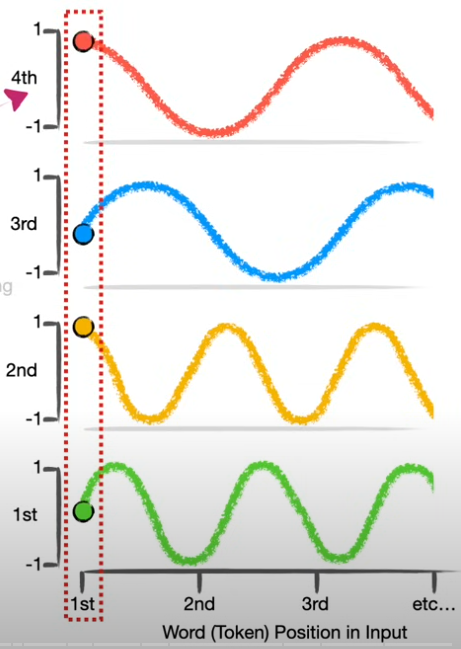
Positional Encoder: Ejemplo
Encoder: Self-Attention
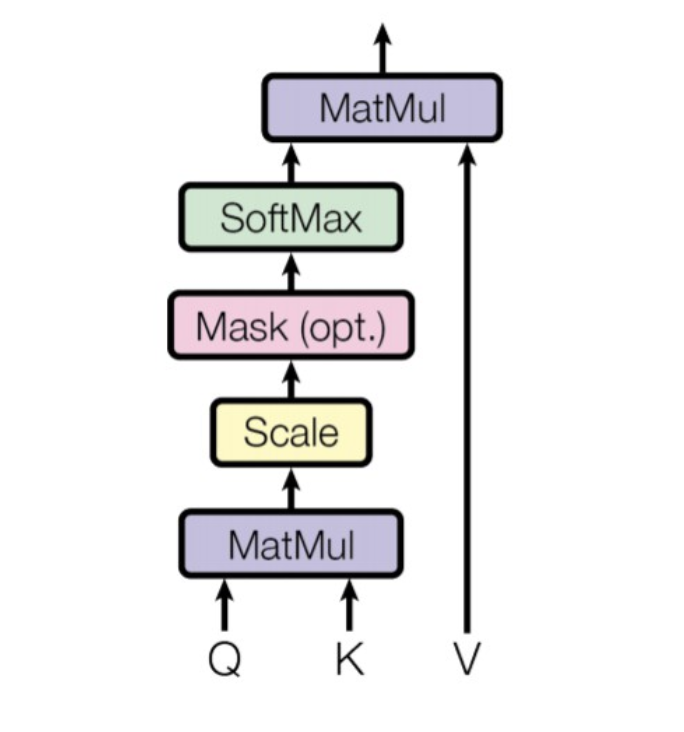
\[Attention(Q,K,V) = Softmax\left(\frac{Q \cdot K^T}{\sqrt{d_k}}\right) V\]
El Scaled Dot-Product, más conocido como Self-Attention, es el mecanismo clave en las redes neuronales modernas. Permite determinar la atención/relación que existe entre palabras de una misma secuencia.
- Está compuesto por 3 proyecciones lineales las cuales reciben los nombres de Query (Q), Key (K) y Value (V).
- Estás 3 proyecciones se combinan para poder determinar la atención/relación que cada Token tiene con los otros tokens de una misma secuencia.
- Varios procesos de
Self-Attentiondan pie alMultihead Attention.
- El
Self-Attentiontiene la capacidad de acceder a toda la secuencia, por ende modelar relaciones a larga distancia. - El
Causal Self-Attention, una variante que se utiliza en el Decoder sólo puede ver la relación con tokens pasados.
- Su característica más importante es que el
Multihead Attentiones paralelizable y no secuencial como las RNN. - Tiene capacidad de escalabilidad para secuencias largas.
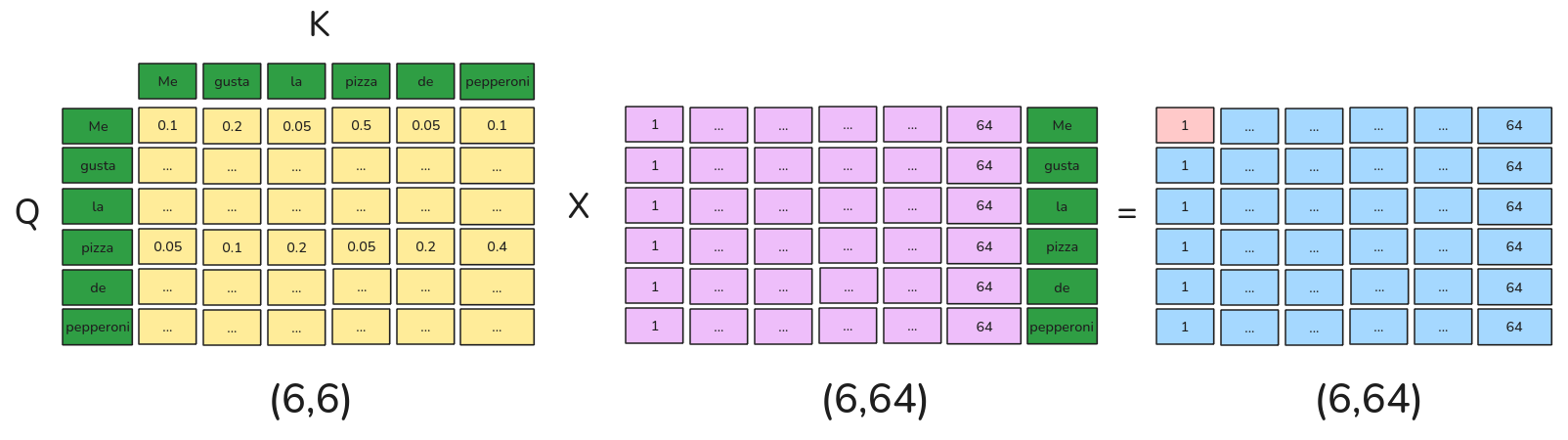
Encoder: Self-Attention (Scale Dot Product)
\[\frac{Q \cdot K^T}{\sqrt{d_k}}\]
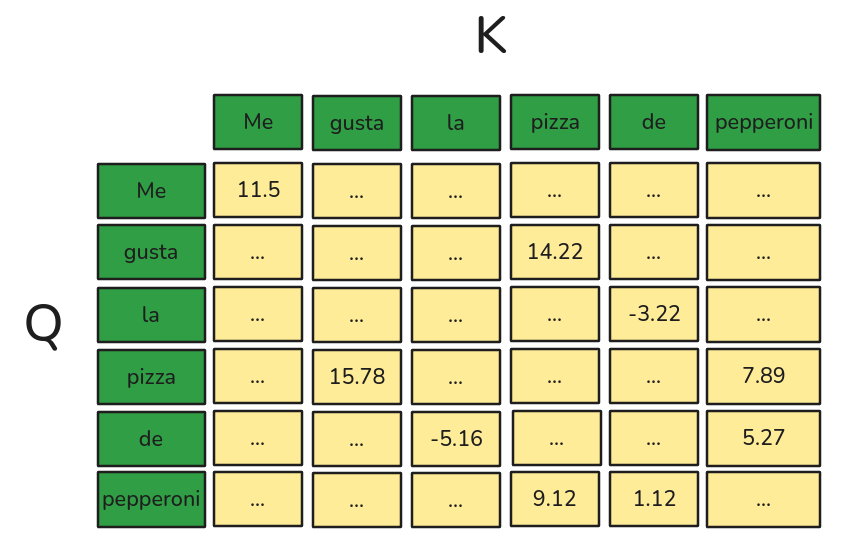
Encoder: Self-Attention (Scale Dot Product)
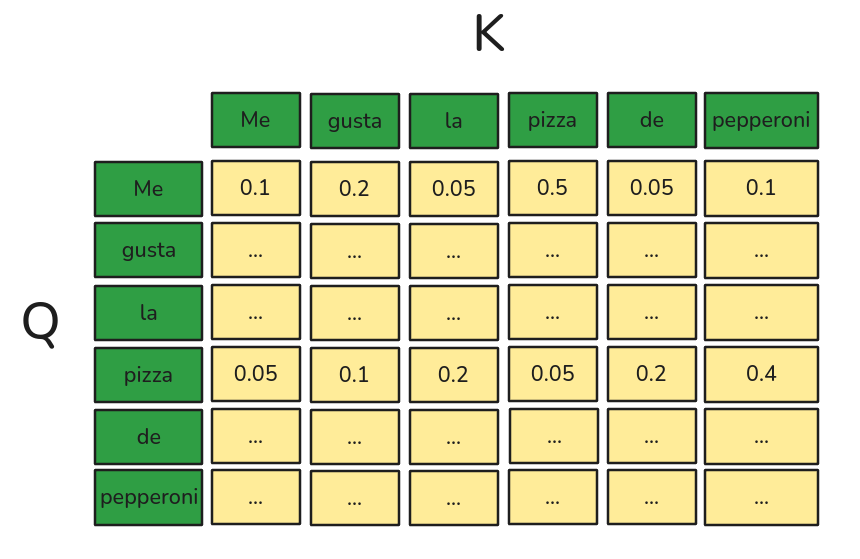
Encoder: Self-Attention (Scale Dot Product)
\[Attention(Q,K,V) = Softmax\left(\frac{Q \cdot K^T}{\sqrt{d_k}}\right) V\]
Encoder: Multihead Attention
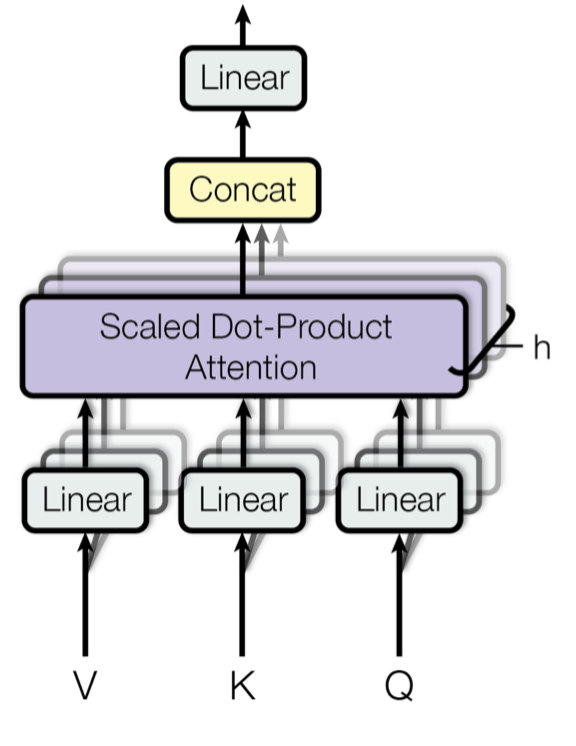
Normalmente se calculan entre \(h=8\) y \(h=12\) attention heads, las cuales se concatenan para luego pasar por una proyección lineal.
Encoder: Add + LayerNorm
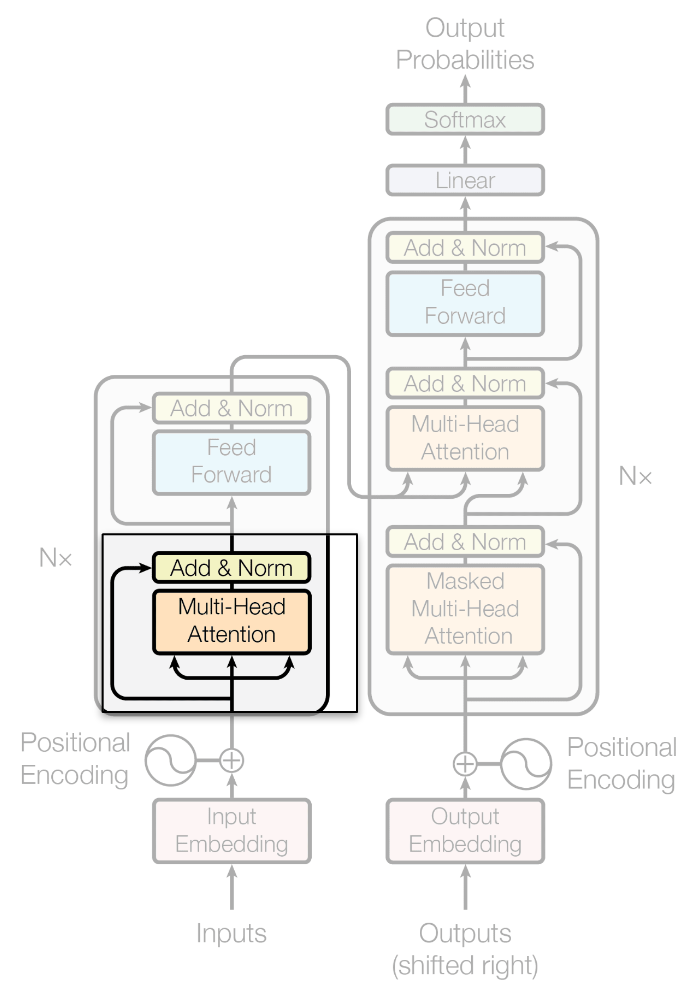
- \(\gamma\) y \(\beta\) son parámetros entrenables.
Encoder: Feed Forward (MLP)
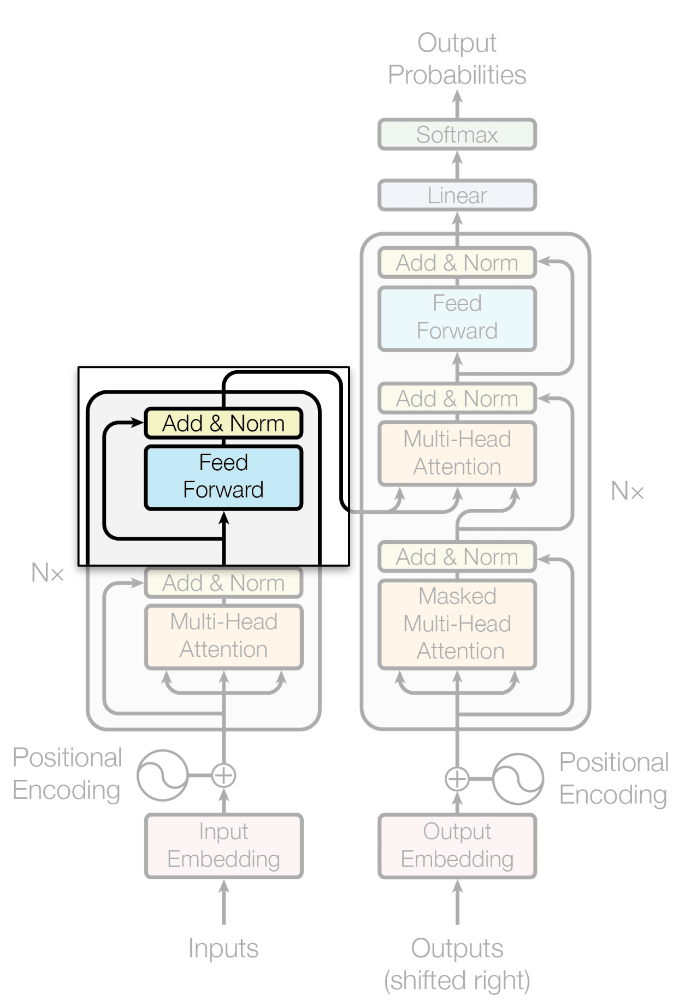
La sección 3.3 del paper define el bloque Feed Forward de la siguiente manera:
\[FFN(x) = max(0,x \cdot W_1+b_1)W_2 + b_2\]
Donde \(W_1 \in \mathbb{R}^{d_{model} \times {d_{ff}}}\) y \(W_2 \in \mathbb{R}^{d_{ff} \times {d_{model}}}\).
Encoder: Output Final
Decoder: Causal Self-Attention
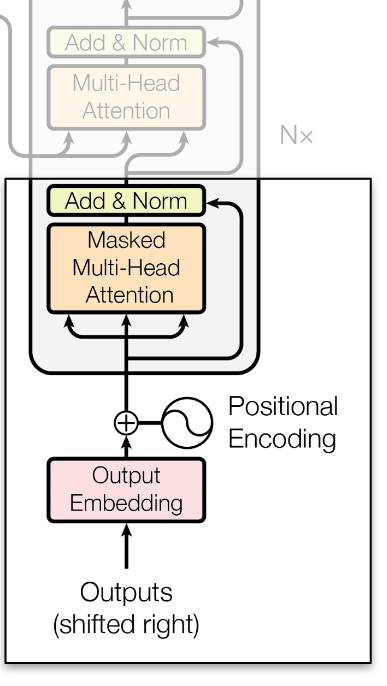
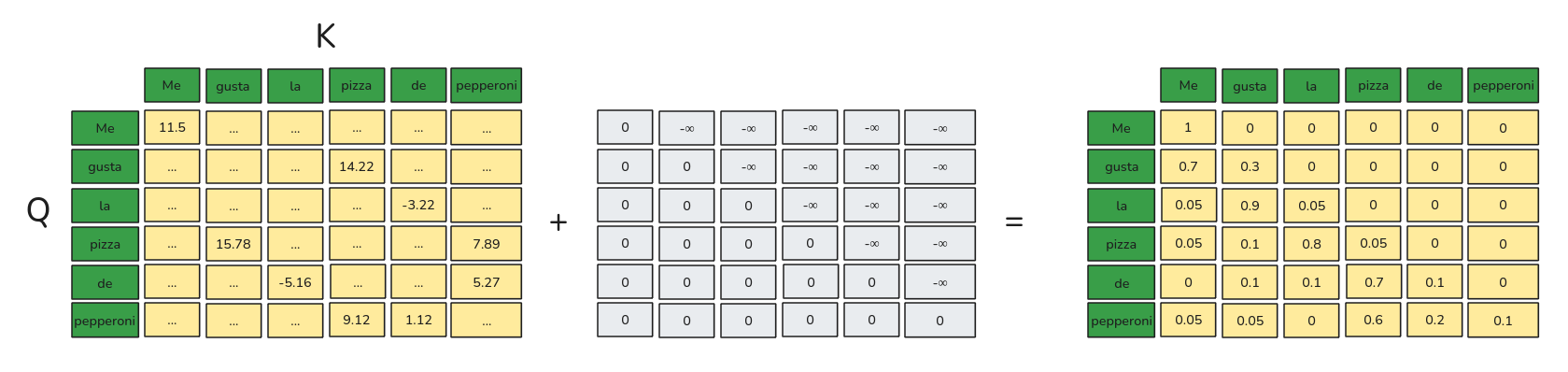
\[Attention(Q,K,V) = Softmax\left(\frac{Q \cdot K^T + Mask}{\sqrt{d_k}}\right) V\]
Corresponde a una variante del Self-Attention en el cuál sólo se presta atención a Tokens pasados, esto para preservar las propiedades auto-regresivas.
Decoder: Cross Attention
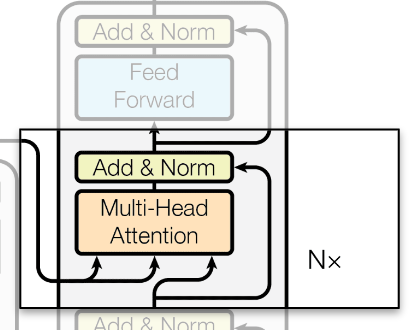
Opcionalmente podría utilizar una Máscara en caso de querer evitar el Look Ahead.
\[Attention(Q_{decoder},K_{encoder},V_{encoder}) = Softmax\left(\frac{Q_{decoder} \cdot K_{encoder}^T + Mask}{\sqrt{d_k}}\right) V_{encoder}\]
Prediction Head
Gracias Totales
![]()