TICS-579-Deep Learning
Clase 2: Introducción a las Redes Neuronales
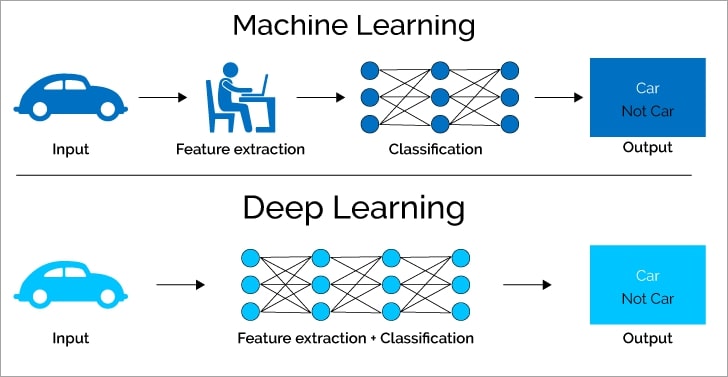
Machine Learning vs Deep Learning
Es sabido que la mejor manera de mejorar el performance de un algoritmo en partícular no es con ajuste de Hiperparámetros sino crear features que sean representativas del problema.
¿Cómo se crean features?
Normalmente un approach es agregar features externas/exógenas, pero también es completamente válido crear features nuevas por medio de las existentes.
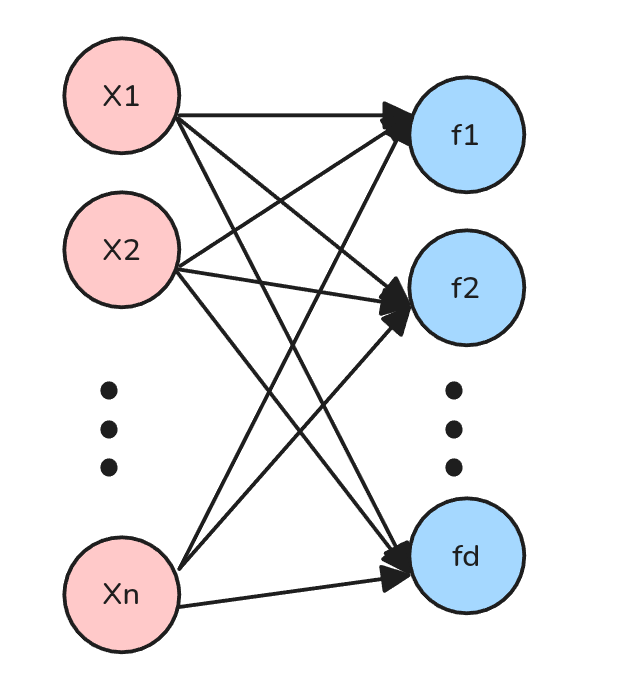
Es decir:
\[f_j^{(i)} = (\bar{x}^{(i)})^T W_{:,j} = \sum_{k=1}^n x_k^{(i)} W_{k,j}\]
Donde \(j=1,...,d\) y \(i=1,...,m\).
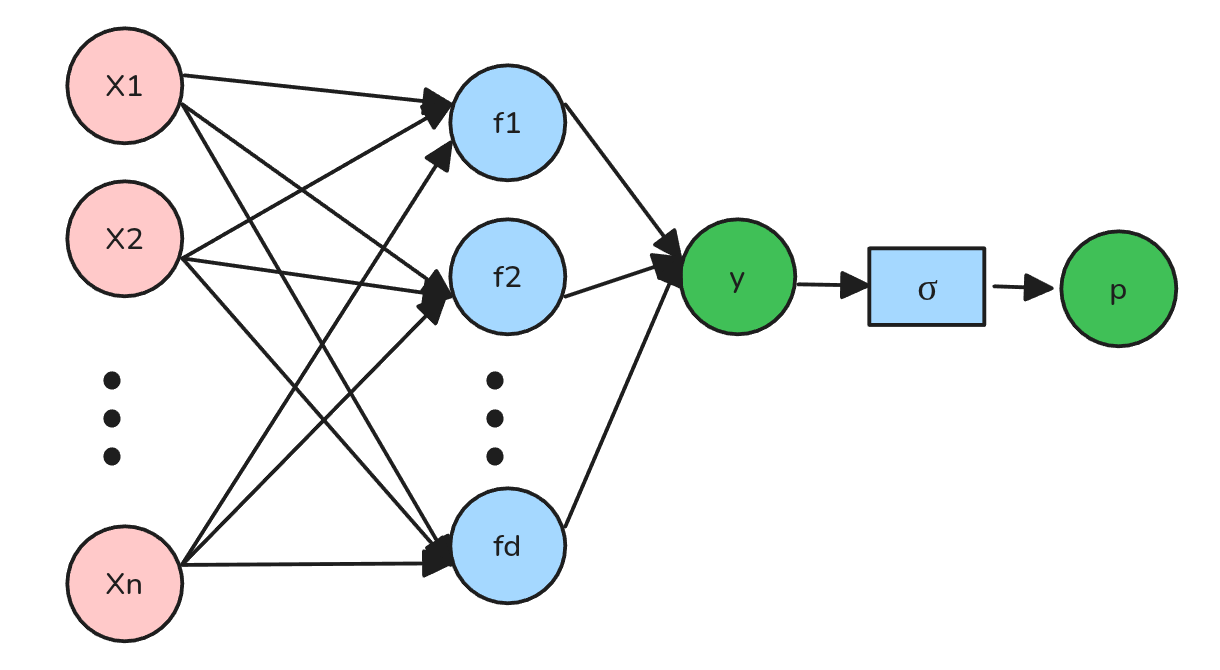
Regresión Logística + Features
👀 Ojo
- Existen convenciones donde cada conjunto de nodos es una capa.
- A la primera capa de nodos se le llama Capa de
Entrada/Input Layer. - A la última capa de nodos se le llama Capa de
Salida/Output Layer. - A las capas intermedias se les llama
Hidden Layers.
- A la primera capa de nodos se le llama Capa de
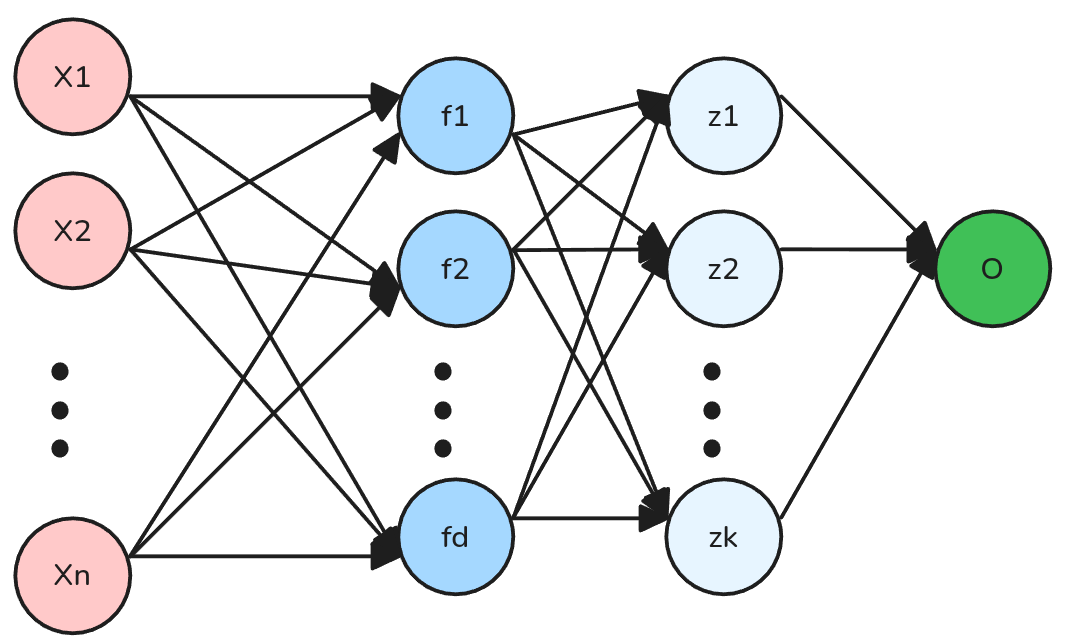
¿Y si hacemos nuestro modelo más profundo?
Podemos hacer nuestro modelo más profundo, agregando más capas de features. Por ejemplo:
\[h_\theta(X) = \sigma(X W_1 W_2 \theta)\]
Donde \(X \in \mathbb{R}^{m \times n}\), \(W_1 \in \mathbb{R}^{n \times d}\), \(W_2 \in \mathbb{R}^{d \times k}\) y \(\theta \in \mathbb{R}^{k \times 1}\).
Atención: En este caso \(\sigma(\cdot)\) tiene como único propósito acotar la salida entre 0 y 1.
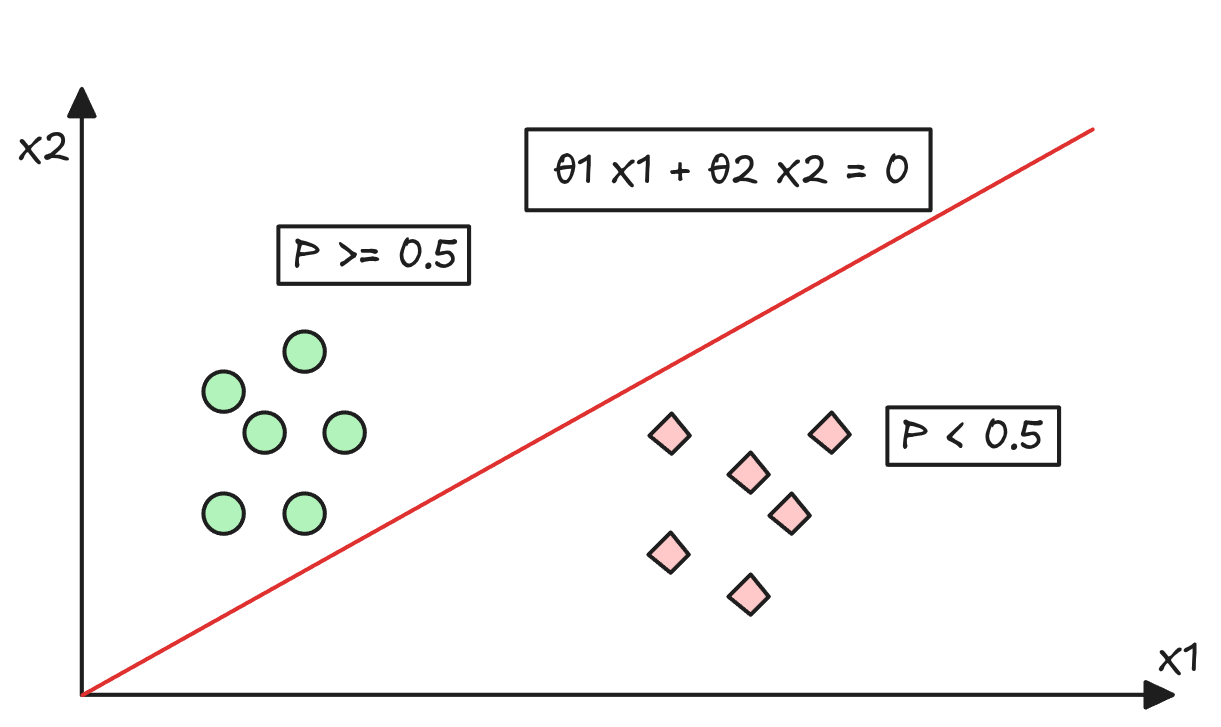
El problema de una Hipótesis Lineal
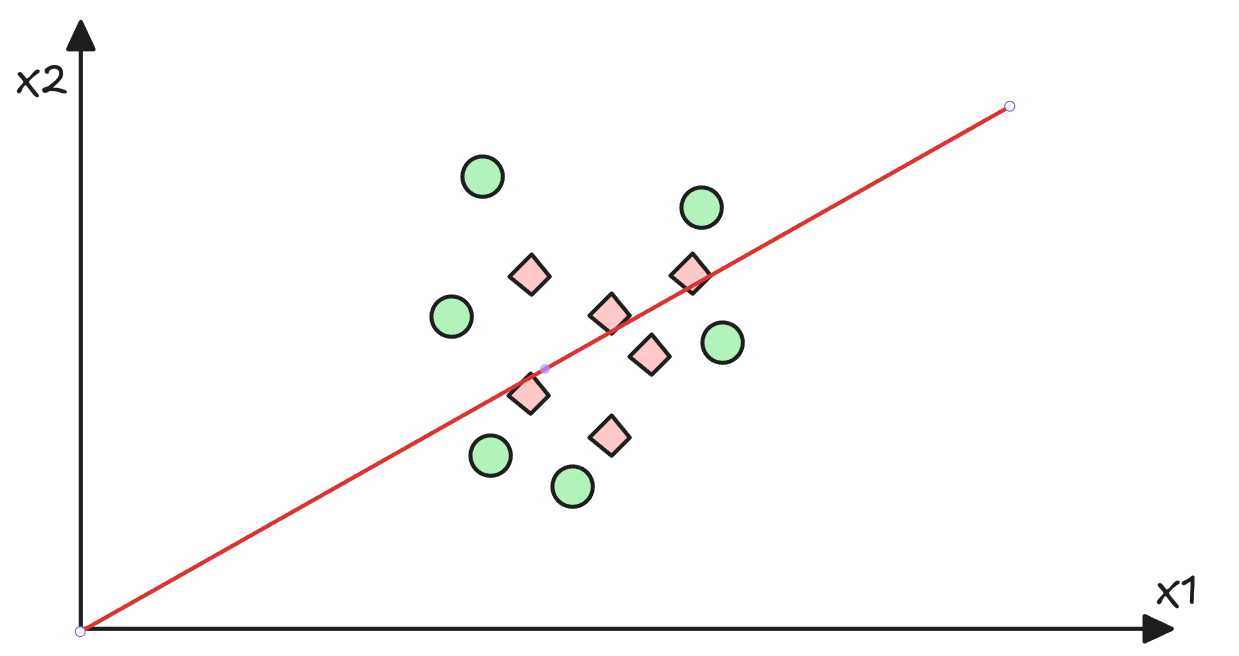
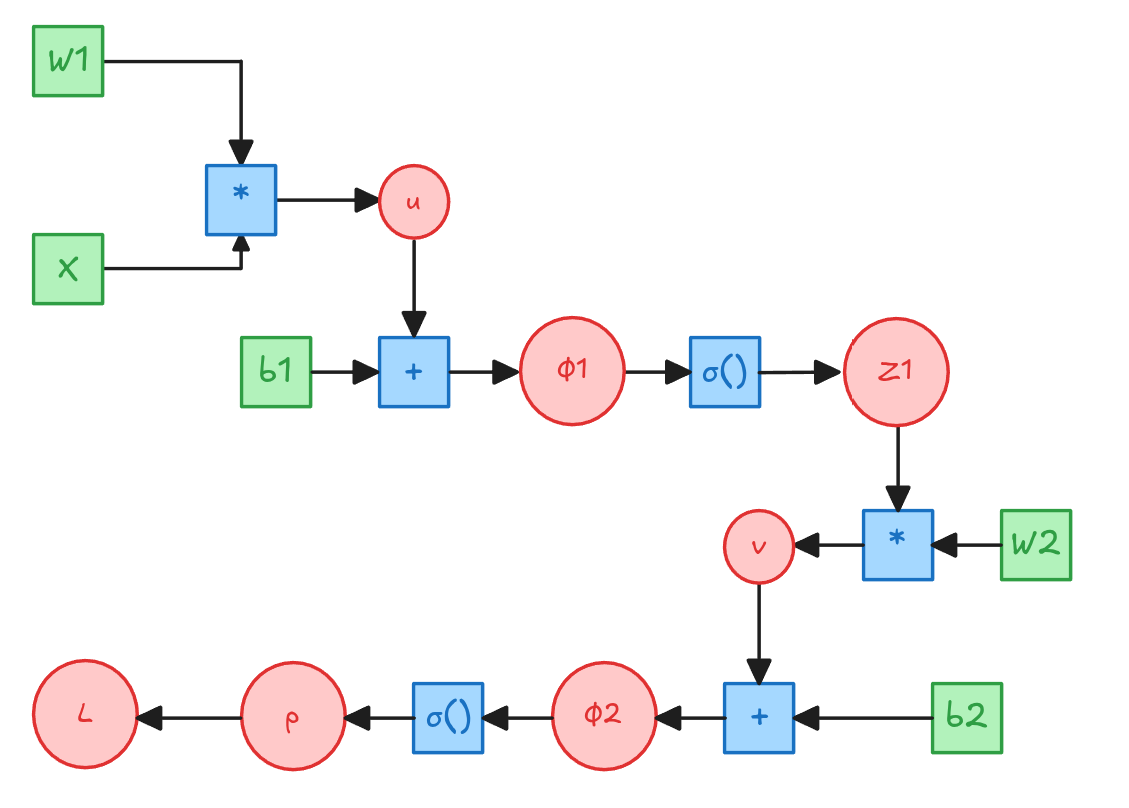
Entrenemos una Red Neuronal a mano
\(W_1 \in \mathbb{R}^{n \times d1}\)
\(\bar{b_1}^T \in \mathbb{R}^{1 \times d1}\)
\(W_2 \in \mathbb{R}^{d1 \times d2}\)
\(\bar{b_2}^T \in \mathbb{R}^{1 \times d2}\)
\[u=X W_1\] \[\phi_1 = u + 1_m\bar{b_1}^T\] \[Z_1 = \sigma(\phi_1)\] \[v=Z_1 W_2\] \[\phi_2 = v + 1_m\bar{b_2}^T\] \[p = \sigma(\phi_2)\] \[L = -\frac{1}{m}\left[y^T log(p) + (1-y)^T log(1-p)\right]\]