TICS-579-Deep Learning
Clase 3: Feed Forward Networks
Feed Forward Networks (FFN)
Este tipo de Redes tiene distintos nombres que son usados de manera intercambiable:
- Capas Lineales: Probablemente por su denominación en Pytorch.
- Capas/Redes Densas: Probablemente por su denominación en Tensorflow.
- Multilayer Perceptron: O también conocido como MLP, debido a que es la generalización del Perceptrón, la primera propuesta de Redes Neuronales de Rosenblatt en 1958.
- Projection Layers: Probablemente por su denominación en algunos papers. Se usa en el contexto de proyectar de \(n\) dimensiones a \(d\) dimensiones.
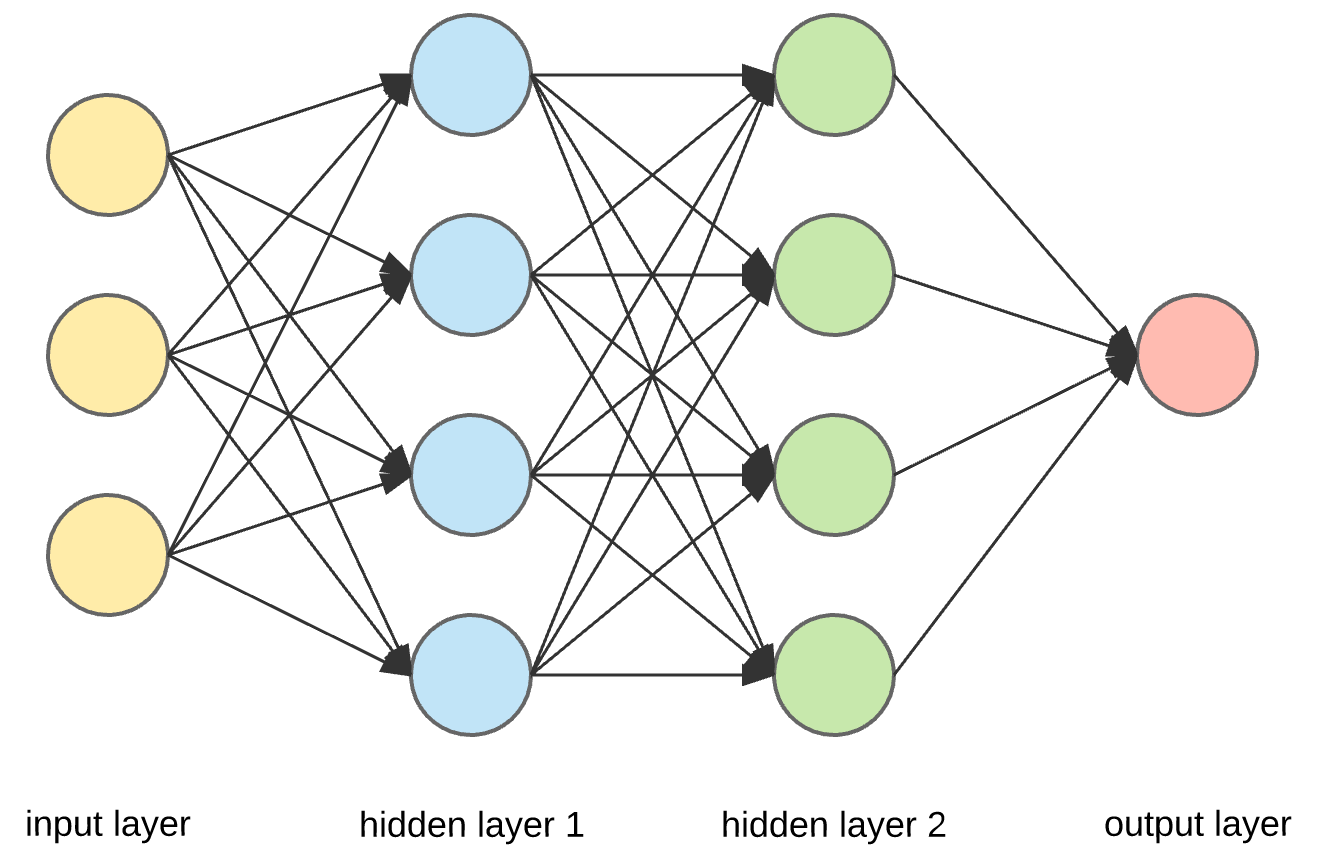
De ahora en adelante utilizaremos las siguiente notación para referirnos a una Red Neuronal Feed Forward:
\[h_\theta(X) = \sigma_s(Z)\]
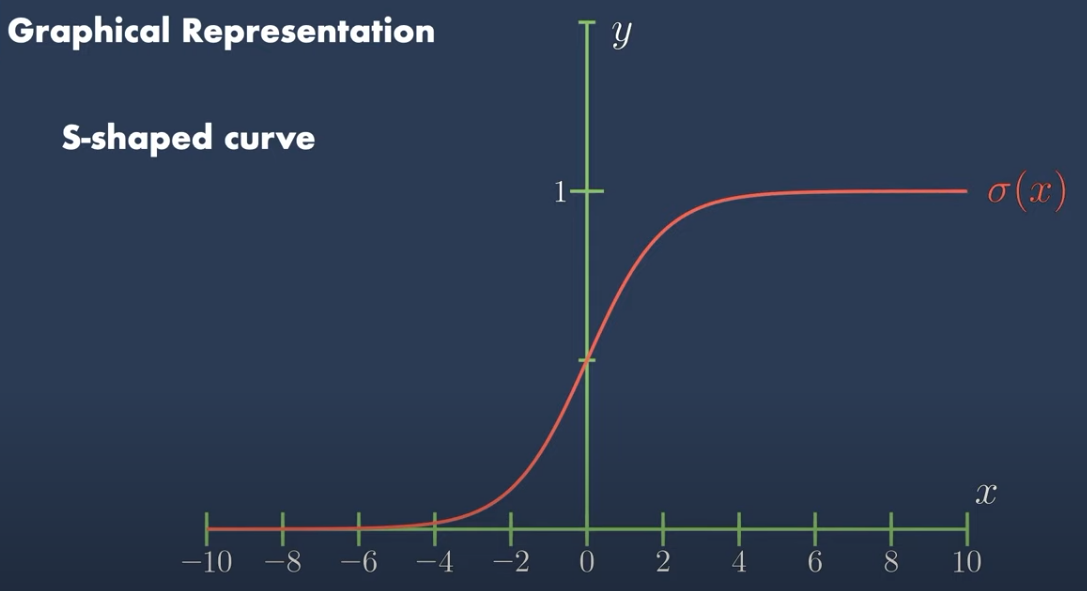
Funciones de Activación
Sigmoide
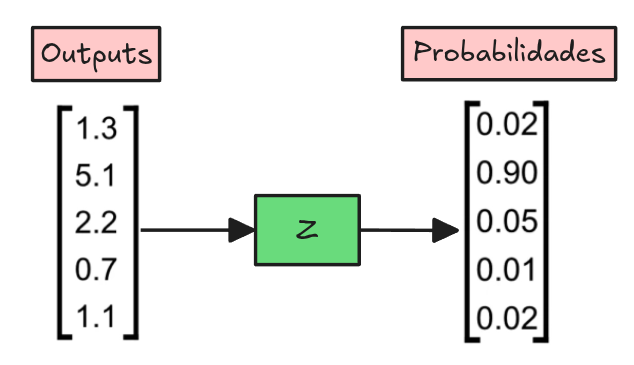
Funciones de Activación
Softmax
Funciones de Activación
Tanh
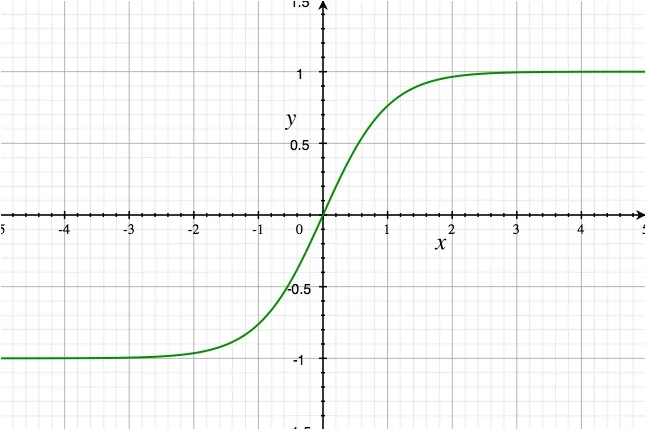
Funciones de Activación
ReLU (Rectified Linear Unit)
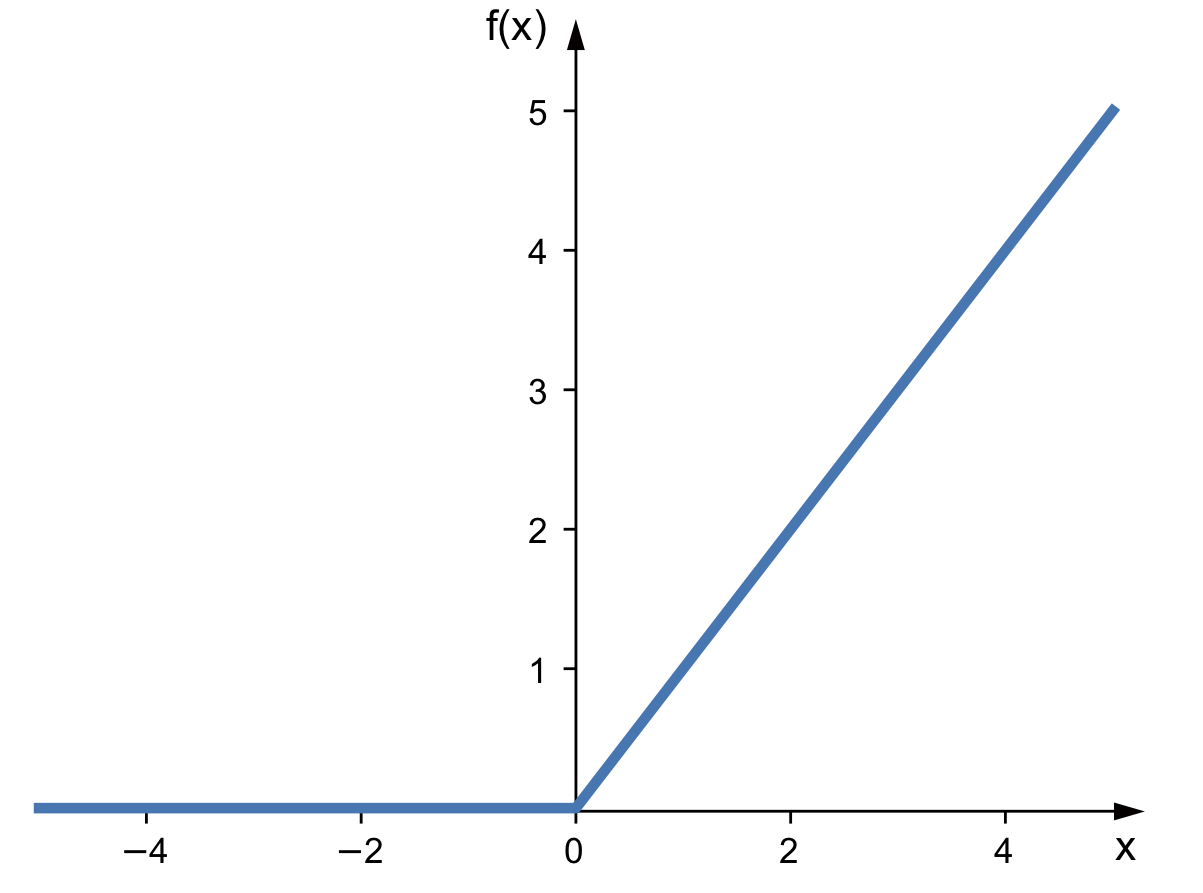
Funciones de Activación Modernas
Leaky ReLU
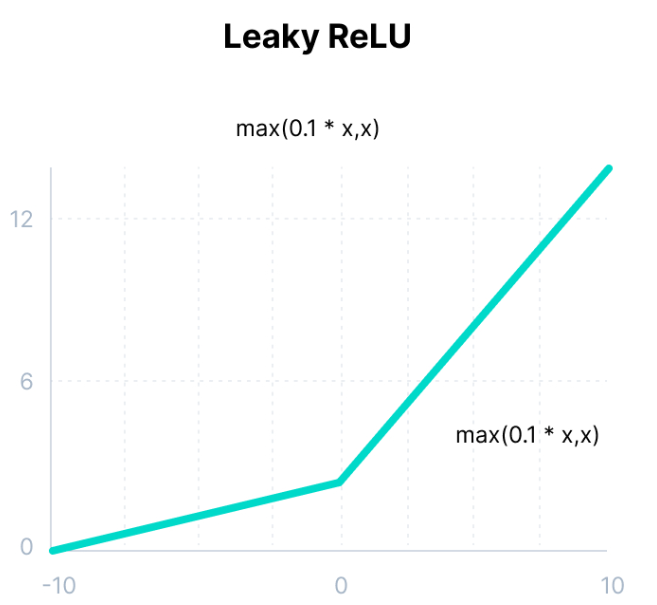
\[g(z) = max(0.1z, z)\]
Parametrized ReLU (PReLU)
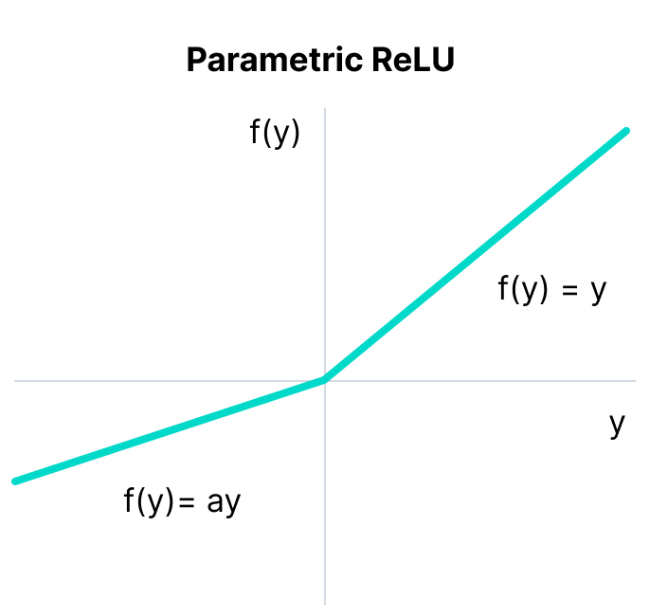
\[g(z) = max(az, z)\]
Funciones de Activación
ELU
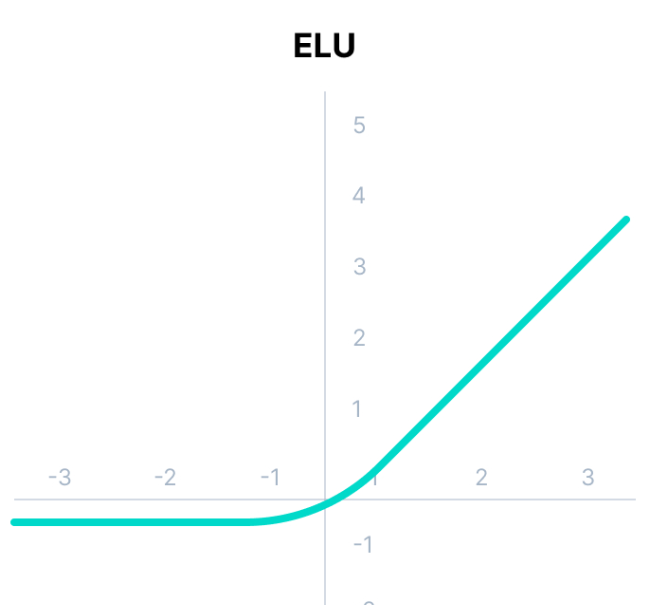 \(g(z) =
\begin{cases}
z, & \text{if $z \ge$ 0} \\[2ex]
\alpha(e^{z}-1), & \text{if $z < 0$}
\end{cases}\)
\(g(z) =
\begin{cases}
z, & \text{if $z \ge$ 0} \\[2ex]
\alpha(e^{z}-1), & \text{if $z < 0$}
\end{cases}\)
GELU
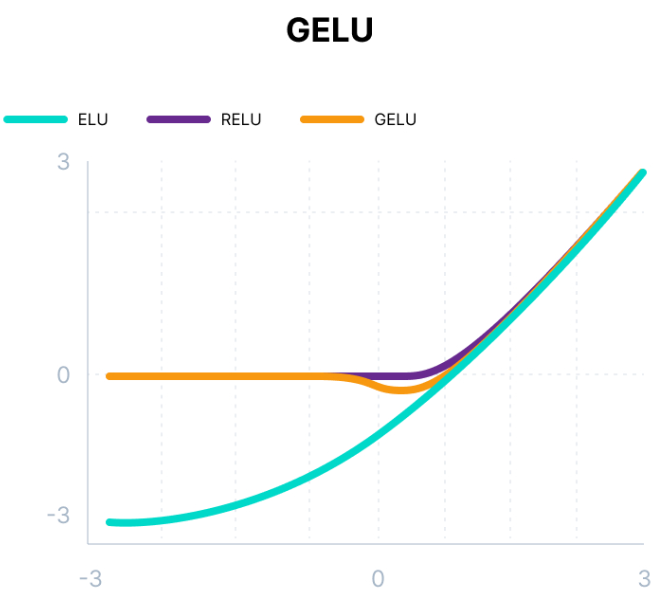 \[\begin{align} g(z) &= z \cdot \Phi(z) \\
g(z)&= 0.5 \cdot z \cdot \left(1 + Tanh\left(\sqrt{2/\pi}\right) \cdot \left(z + 0.044715 \cdot z^3\right)\right)\end{align}\]
\[\begin{align} g(z) &= z \cdot \Phi(z) \\
g(z)&= 0.5 \cdot z \cdot \left(1 + Tanh\left(\sqrt{2/\pi}\right) \cdot \left(z + 0.044715 \cdot z^3\right)\right)\end{align}\]
Funciones de Activación
SELU
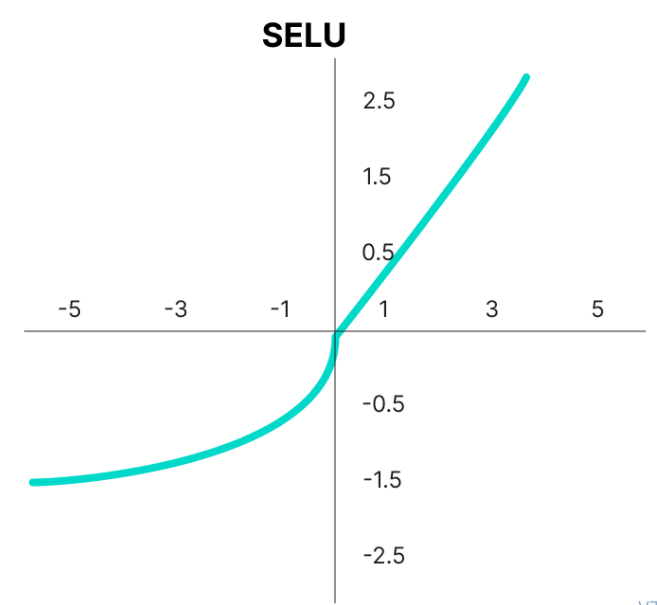 \[ g(z) = scale \cdot (max(0,z) + min(0,\alpha(e^z - 1)))\]
\[ g(z) = scale \cdot (max(0,z) + min(0,\alpha(e^z - 1)))\]
con \(\alpha=1.6732632423543772848170429916717\) y \(scale = 1.0507009873554804934193349852946\)
Swish
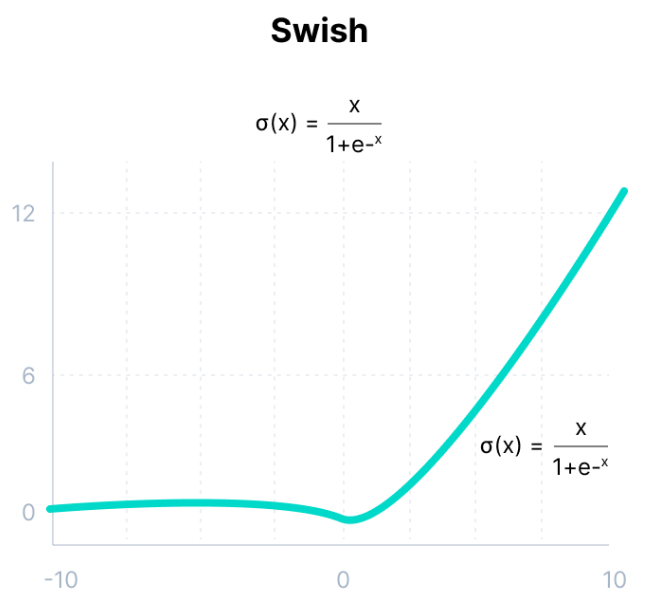 \[g(z) = z \cdot sigmoid(z)\]
\[g(z) = z \cdot sigmoid(z)\]
Ejemplo de Cálculo Cross Entropy Loss
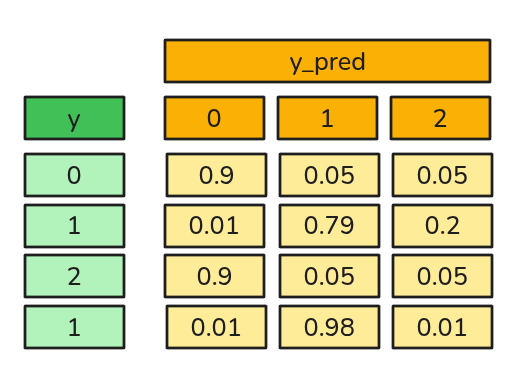
\[Y = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix}\]
\[Log(\hat{Y}) = \begin{bmatrix} -0.1054 & -2.9957 & -2.9957 \\ -4.6052 & -0.2357 & -1.6094 \\ -0.1054 & -2.9957 & -2.9957 \\ -4.6052 & -0.0202 & -4.6052 \end{bmatrix} \]
\[Y^T \cdot Log(\hat{Y}) = \begin{bmatrix} -0.1054 & ... & ... \\ ... & -0.2357 - 0.0202 & ... \\ ... & ... & -2.9957 \end{bmatrix} \]
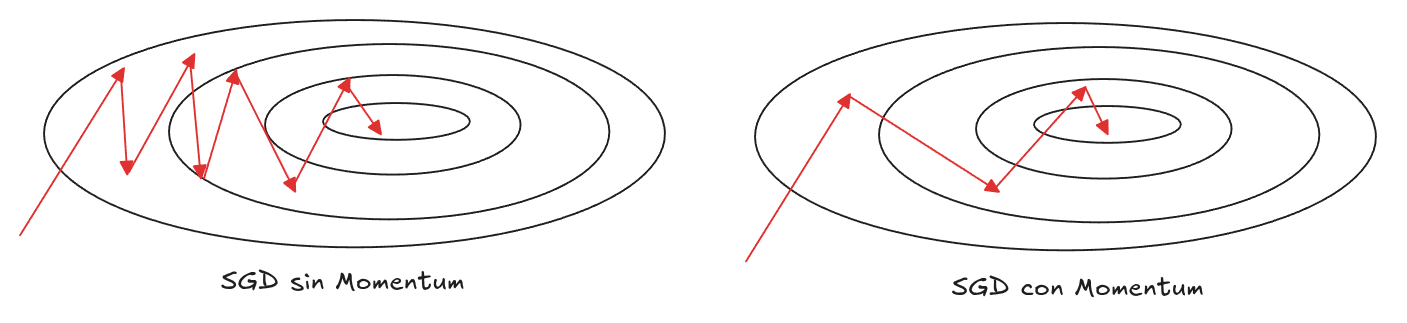
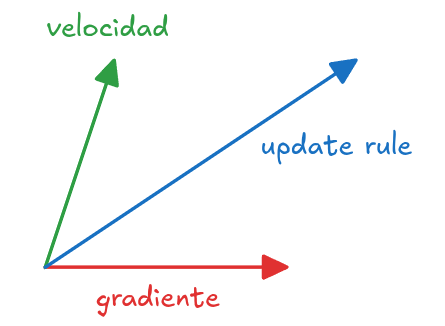
SGD with Momentum
Update Rule
\[\theta_{t+1} = \theta_t - \alpha v_{t + 1}\] \[v_{t+1} = \beta v_{t} + (1-\beta) \nabla_\theta L(\theta_{t+1})\]
donde \(0<\beta<1\), pero normalmente \(\beta=0.9\).
\[\begin{align} v_{t+1}&=(1-\beta)\nabla_\theta L(\theta_{t}) + \beta v_t \\ v_{t+1}&=(1-\beta)\nabla_\theta L(\theta_{t}) + \beta \left[(1-\beta) \nabla_\theta L(\theta_{t-1}) + \beta v_{t-1}\right] \\ v_{t+1}&=(1-\beta)\nabla_\theta L(\theta_{t}) + \beta (1-\beta) \nabla_\theta L(\theta_{t-1}) + \beta^2 (1-\beta) \nabla_\theta L(\theta_{t-2})... \\ \end{align}\]
SGD with Nesterov Momentum
\[\theta_{t+1} = \theta_t - \alpha u_{t + 1}\] \[v_{t + 1} = \beta v_t + (1-\beta) \nabla_\theta f(\theta_{t+1} + \beta v_t)\]
donde \(0<\beta<1\), pero normalmente \(\beta=0.9\).
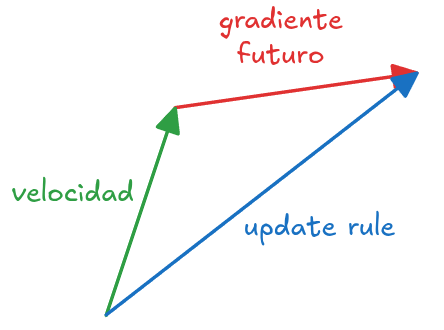
Efecto del Momentum en el Update Rule