TICS-579-Deep Learning
Clase 4: Model Training
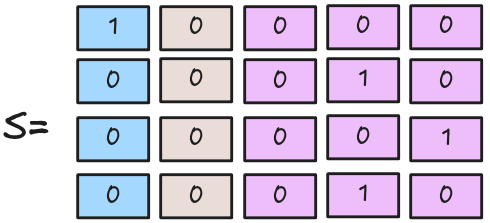
Model Validation: Holdout
A diferencia de un modelo de Machine Learning el proceso de validación del modelo se realiza en conjunto con el entrenamiento. Es decir, se entrena y valida el modelo Epoch a Epoch.
Model Validation: K-Fold
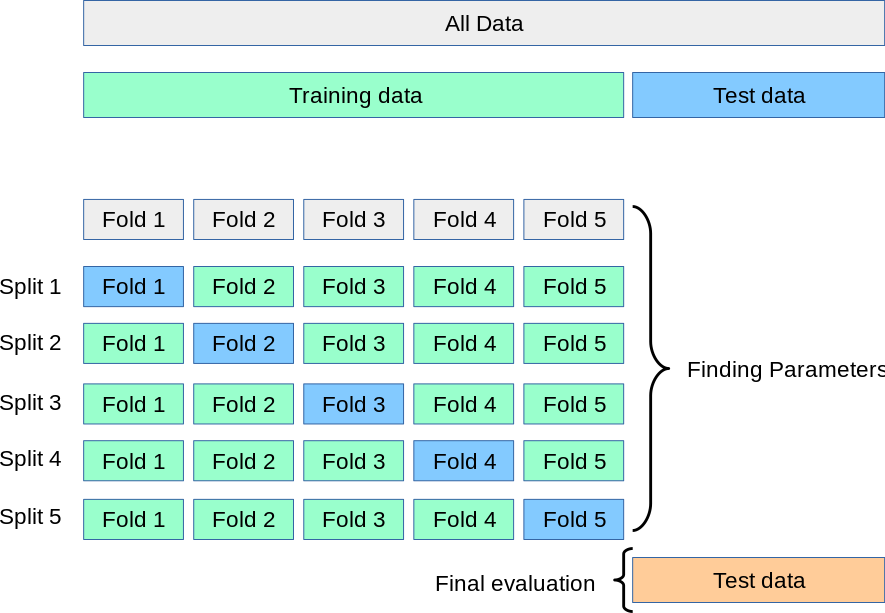
Corresponde al proceso de Holdout pero repetido \(K\) veces. No es tan utilizado en Deep Learning debido a los altos costos computacionales.
Pytorch: Crear modelos más complejos
class MLP2(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.fc1 = nn.Linear(in_features, out_features)
self.relu = nn.ReLU(inplace = True)
self.fc2 = nn.Linear(out_features, 1)
def forward(self,x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
class SuperMLP(nn.Module):
def __init__(self):
super().__init__()
self.mlp1 = MLP(in_features=4, out_features=12)
self.mlp2 = MLP2(in_features=12, out_features=8)
def forward(self, x):
x = self.mlp1(x)
x = self.mlp2(x)
return x
super_model = SuperMLP()
logits = super_model(X)
logits.shapePytorch: Visualización del Modelo
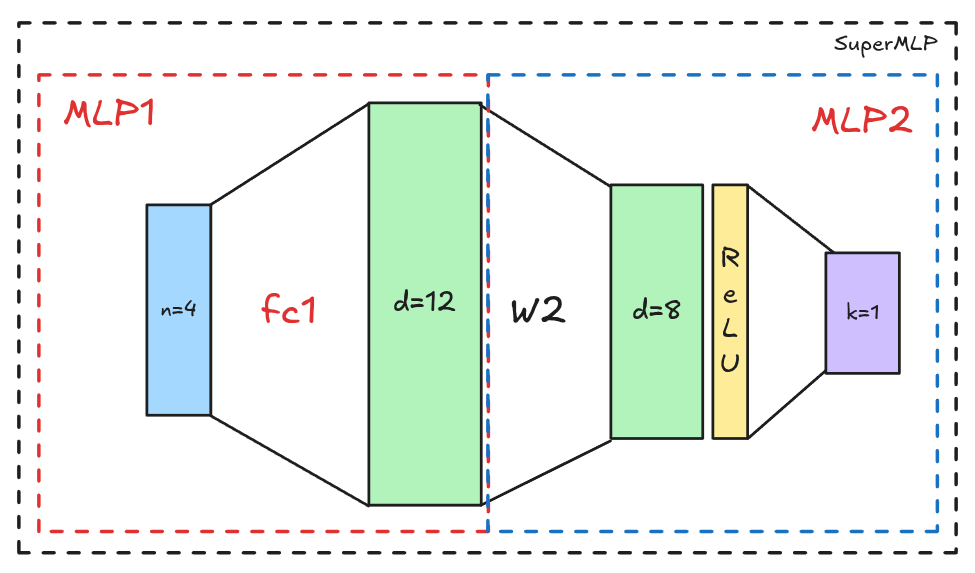
SuperMLP(
(mlp1): MLP(
(fc1): Linear(in_features=4, out_features=12, bias=True)
)
(mlp2): MLP2(
(fc1): Linear(in_features=12, out_features=8, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=8, out_features=1, bias=True)
)
)=================================================================
Layer (type:depth-idx) Param #
=================================================================
SuperMLP --
├─MLP: 1-1 --
│ └─Linear: 2-1 60
├─MLP2: 1-2 --
│ └─Linear: 2-2 104
│ └─ReLU: 2-3 --
│ └─Linear: 2-4 9
=================================================================
Total params: 173
Trainable params: 173
Non-trainable params: 0
=================================================================Pytorch: Training Loop
loss_history = []
for e in range(epochs):
# Definición del modo del Modelo
super_model.train()
optimizer.zero_grad()
# Forward Pass
logits = super_model(X)
loss = criterion(logits, y)
## Calcula los gradientes (Backward Pass)
loss.backward()
# Actualización de los Pesos
optimizer.step()
# Log del Modelo
loss_history.append(loss.item())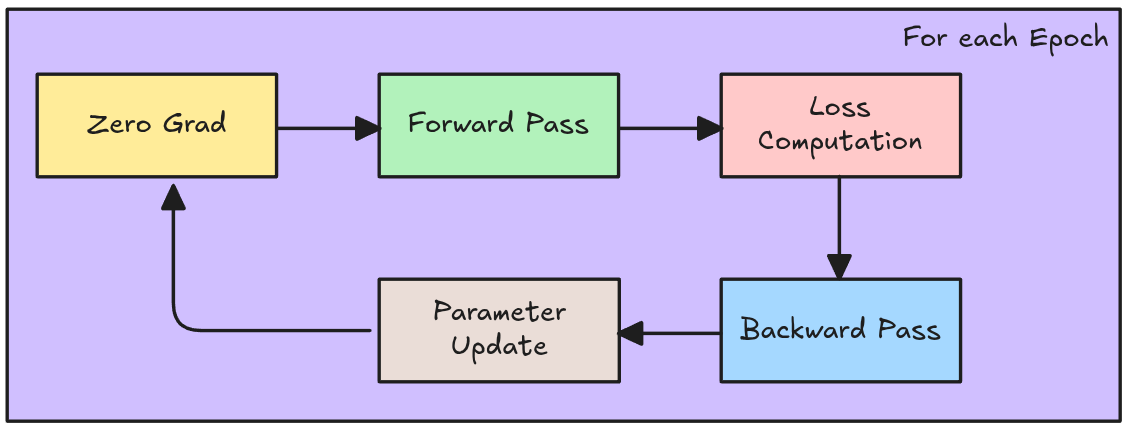
Pytorch: Validation Loop
loss_history = []
val_loss_history = []
for e in range(epochs):
# Definición del modo del Modelo
super_model.train()
optimizer.zero_grad()
# Forward Pass
logits = super_model(X)
loss = criterion(logits, y)
## Calcula los gradientes (Backward Pass)
loss.backward()
# Actualización de los Pesos
optimizer.step()
# Log de Entrenamiento
loss_history.append(loss.item())
# Validation Loop
super_model.eval()
# Evita cálculo de gradientes
with torch.no_grad():
val_logits = super_model(X_val)
val_loss = criterion(val_logits, y_val)
# Log de Validación
val_loss_history.append(val_loss.item())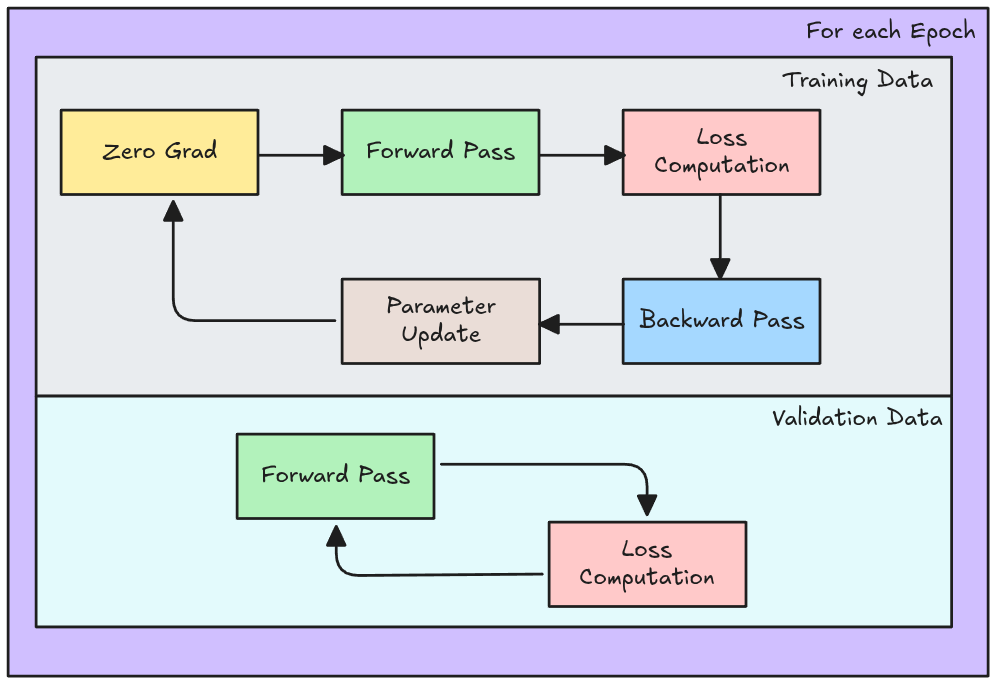
Pytorch: Training-Validation Loop + Evaluación
loss_history, val_loss_history = [], []
train_metric_history, val_metric_history = [], []
for e in range():
train_metric = BinaryAccuracy()
val_metric = BinaryAccuracy()
## Training Loop
super_model.train()
optimizer.zero_grad()
logits = super_model(X)
loss = criterion(logits, y)
loss.backward()
optimizer.step()
loss_history.append(loss.item())
acc = train_metric(logits, y)
train_metric_history.append(acc)
tr_acc = train_metric.compute()
# Validation Loop
super_model.eval()
with torch.no_grad():
val_logits = super_model(X_val)
val_loss = criterion(val_logits, y_val)
val_loss_history.append(val_loss.item())
acc = train_metric(val_logits, y_val)
val_metric_history.append(acc)
val_acc = test_metric.compute()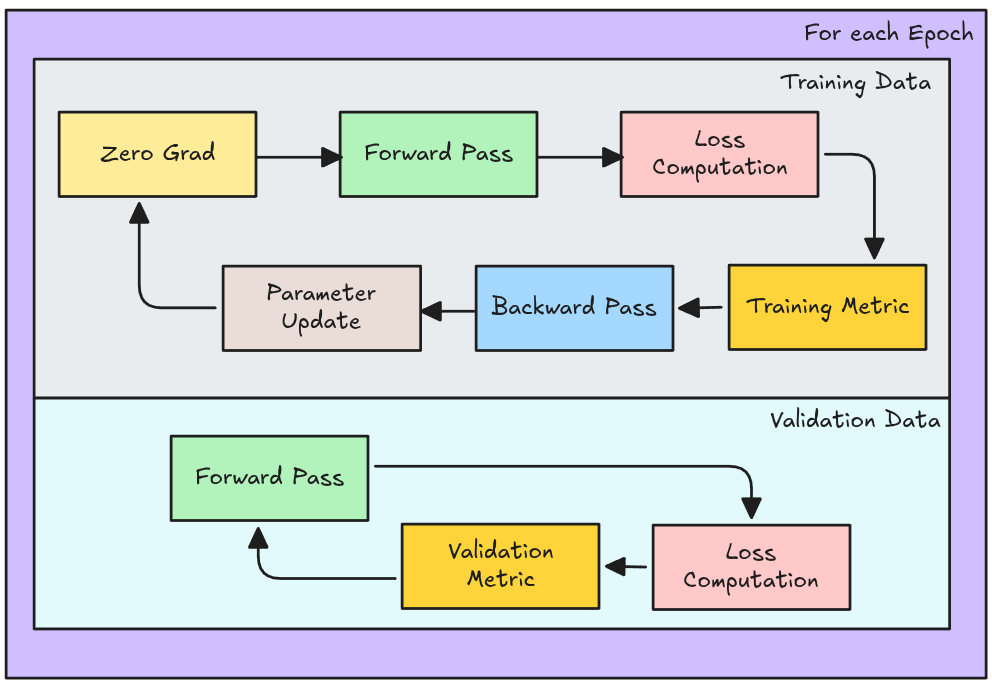
Monitoreo de un Modelo: Validation Curve
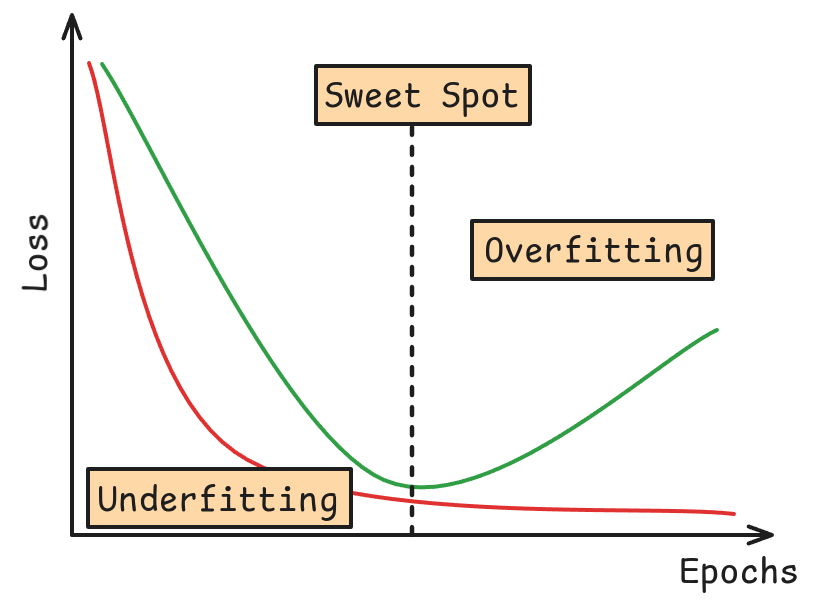
Es importante ser capaz de identificar el momento exacto en el cual el momento comienza su overfitting. Para ello se utiliza el “Checkpointing”.
Checkpoint
- Corresponde a un snapshot del modelo a un cierto punto. En la práctica se almacenan los parámetros del mejor modelo y del último Epoch.
EarlyStopping
- Teoricamente, una vez que la red Neuronal alcanza el punto de Overfitting ya no tiene sentido seguir el entrenamiento. Por lo tanto es posible detener el entrenamiento bajo una cierta condición.
Categorical Variables: One Hot Encoding
Hasta ahora hemos asumido que las variables de entrada son numéricas. Pero en la práctica es muy común encontrarse con variables categóricas. En Deep Learning existen dos técnicas para lidiar con este tipo de variables: One-Hot-Encoding y el uso de Embeddings.
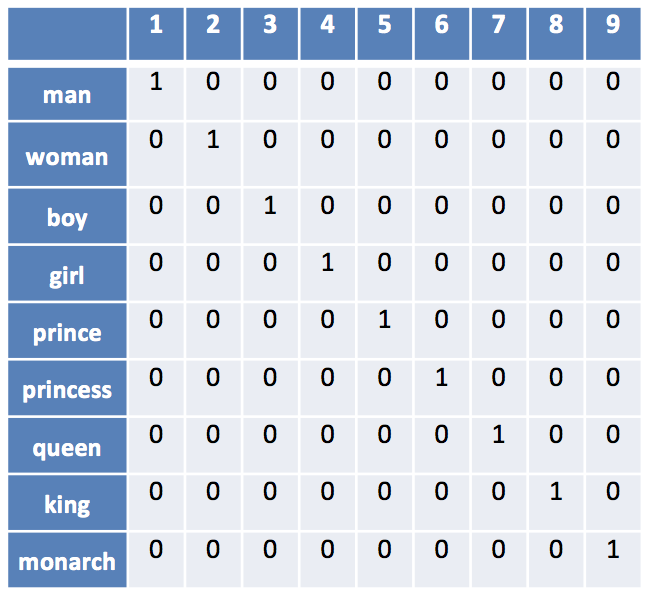
Categorical Variables: Embeddings
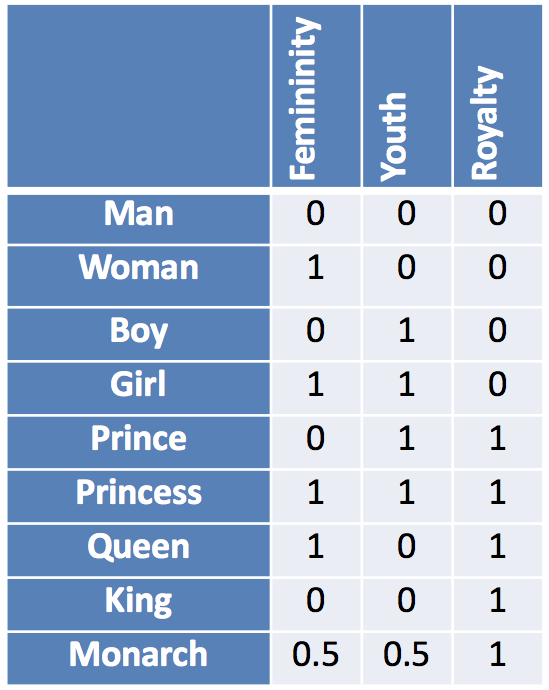
Aplicación en Pytorch
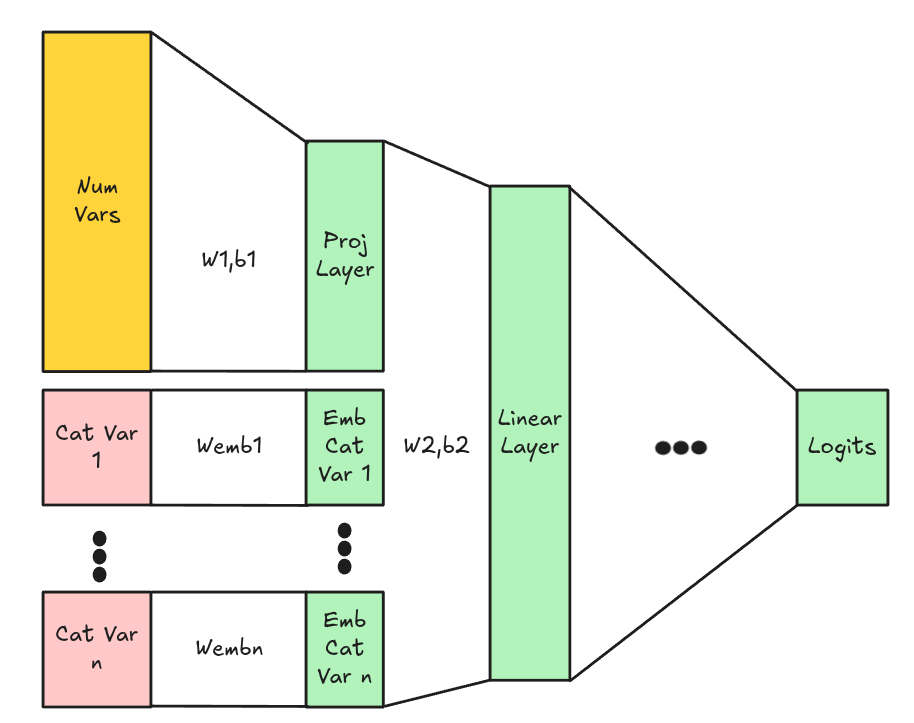
Embedding: Ejemplo
\[e=Emb(X)\] \[\phi1 = e \cdot W1\] \[Z = \phi_1 = + 1_m b^T\] \[p = \sigma(Z)\] \[L = \frac{-1}{m}\left[y^T log(p) + (1-y)^T log(1-p)\right]\]
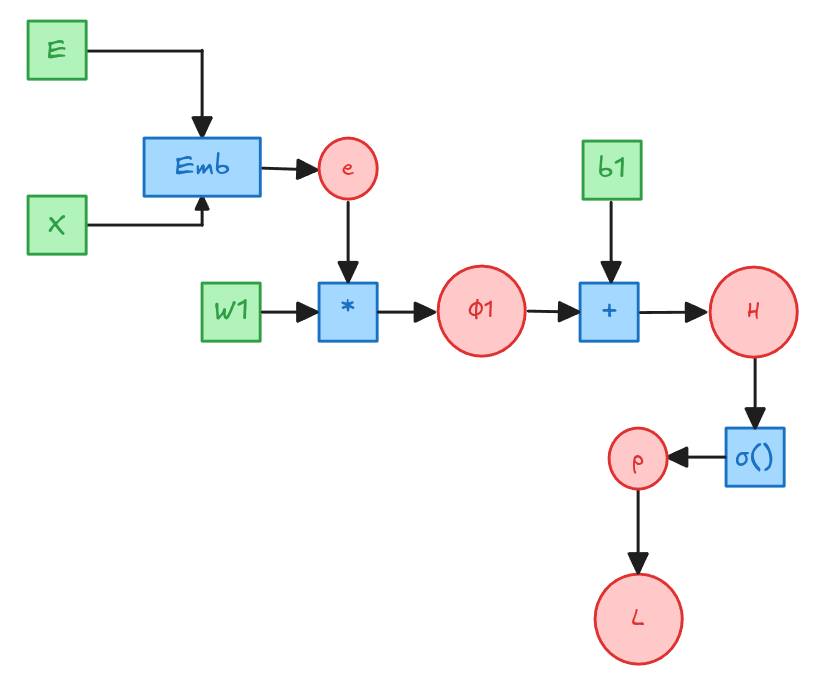
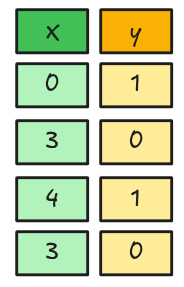
Embedding: Ejemplo Numérico

\[ e = \begin{bmatrix} 0.1000 & 0.2000 & 0.3000 \\ 0.4000 & 0.0000 & -0.1000 \\ 0.2000 & -0.2000 & 0.1000 \\ 0.4000 & 0.0000 & -0.1000 \end{bmatrix} \]