TICS-579-Deep Learning
Clase 6: Redes Convolucionales
Limitaciones de las FFN
Sin duda las Redes Feed Forward son una herramienta poderosa para resolver problemas de clasificación y regresión. Sin embargo, presentan ciertas limitaciones cuando se aplican a datos con estructuras espaciales o temporales, como imágenes o secuencias de texto.

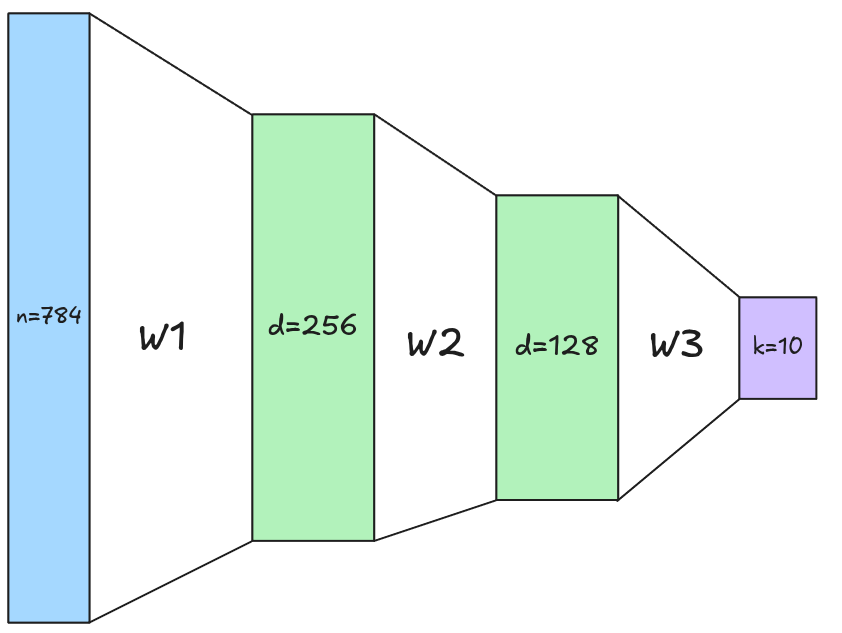
Número de Parametros
(Imagen: 28x28=784 píxeles):
- \(W_1 = 784 \cdot 256 + 256 = 200960\)
- \(W_2 = 256 \cdot 128 + 128 = 32896\)
- \(W_3 = 128 \cdot 10 + 10 = 1290\)
- Total = 235,146.
¿Y si tengo una imágen de \(512 \times 512\)? 67,143,306 de parámetros.
Limitaciones de las FFN
![]()
Limitaciones de las FFN
Imagenes actuales cada vez más grandes

Textos actuales cada vez más largos

Imágenes
- Imagen
- Definiremos una imágen como un Tensor de Orden 3. Normalmente cada dimensión representa H, W y C (Altura, Ancho y Canales).
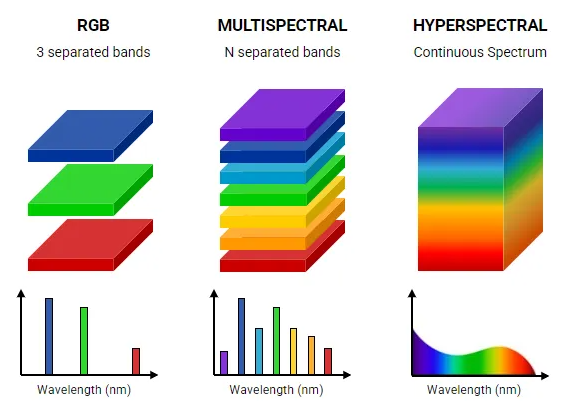
La convención más común es utilizar imágenes de 24-bits, es decir 3 canales de \(2^8\) valores (8-bits por canal). Es por eso que el valor de los píxeles va de 0 a 255 y representan la intensidad del color del canal que representan.
Imágenes
Librerías como
PILuOpenCVpermiten importar imágenes en Python. Ambas usan la convención de \((H,W,C)\), la diferencia está en el orden de los canales.PILutiliza la convención RGB, mientras queOpenCVutiliza BGR por lo que se necesitan algunas transformaciones adicionales.

Ejemplo para importar imágenes con PIL y Pytorch
from PIL import Image
import numpy as np
import torch
path = "path/to/imagen.png"
img = Image.open(path)
# Convierte a Tensor y cambia a (C,H,W)
torch_image= torch.from_numpy(np.array(img)).permute(2,0,1)
torch_image.shape(3,1200,1200)import matplotlib.pyplot as plt
## Imágen en canal Rojo
plt.imshow(torch_image[0].numpy(), cmap="Reds")
plt.axis("off")
plt.show()
## Imágen en canal Verde
plt.imshow(torch_image[1].numpy(),cmap="Greens")
plt.axis("off")
plt.show()
## Imágen en canal Azul
plt.imshow(torch_image[2].numpy(), cmap="Blues")
plt.axis("off")
plt.show()Batch de Imágenes
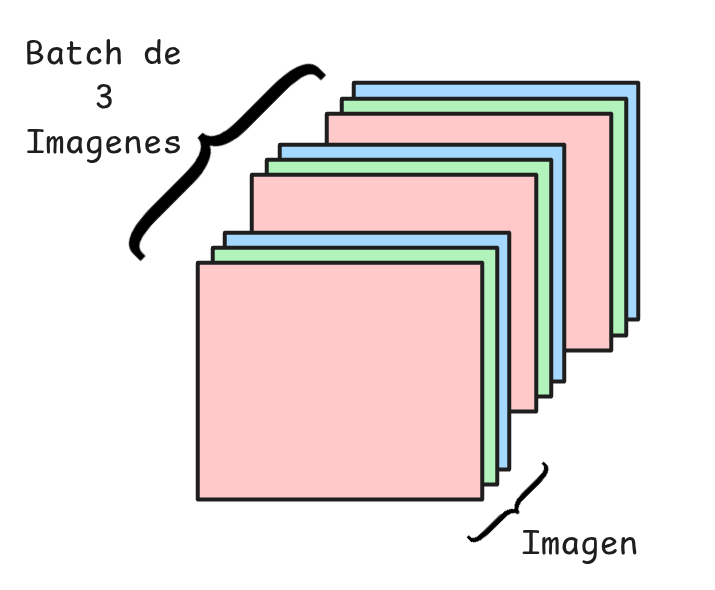
Luego un Tensor de Dimensiones (32,3,224,512) implica que tenemos 32 imágenes RGB de dimensiones \(224\times512\).
tensor([[[[248, 240, 146, 73, 228],
[ 79, 125, 191, 203, 133],
[202, 12, 237, 109, 62],
[133, 227, 148, 78, 229],
[121, 247, 202, 51, 3]],
[[253, 28, 20, 144, 255],
[115, 132, 114, 45, 164],
[ 57, 238, 117, 250, 41],
[ 58, 73, 29, 253, 240],
[246, 84, 93, 2, 145]],
[[ 83, 4, 144, 126, 202],
[ 98, 235, 55, 83, 104],
[ 21, 185, 27, 102, 117],
[255, 133, 23, 83, 150],
[ 49, 152, 81, 233, 98]]],
-----------------------------------------------
[[[216, 92, 251, 214, 178],
[252, 48, 88, 82, 79],
[168, 208, 223, 9, 169],
[145, 148, 254, 128, 156],
[238, 175, 233, 136, 118]],
[[112, 68, 143, 93, 150],
[ 32, 103, 97, 93, 223],
[205, 56, 90, 24, 108],
[ 13, 135, 98, 20, 93],
[ 20, 91, 37, 81, 10]],
[[109, 145, 90, 243, 63],
[103, 134, 130, 11, 72],
[132, 163, 153, 26, 255],
[ 45, 228, 26, 169, 212],
[ 34, 211, 229, 82, 201]]]])Redes Convolucionales: Definición e Inspiración
- Redes Convolucionales (CNN)
- Son un tipo de red neuronal cuyos parámetros entrenables son filtros (también llamados Kernels) que aprenden a detectar patrones en los datos de entrada.
El resultado de una Convolucional es un feature map, el cual representa la presencia y localización de ciertos patrones visuales.
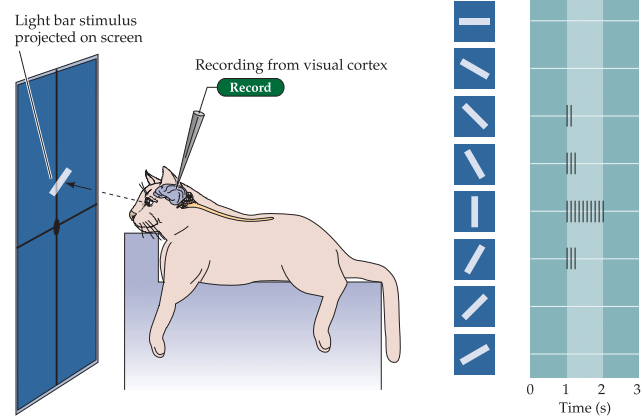
Existe el mito de que las Redes Convolucionales se inspiraron en el funcionamiento del Cortex Visual humano. No sé si es tan así.
El mito dice que las CNNs fueron diseñadas para imitar el cortex visual humano. Esto viene de los trabajos de Hubel y Wiesel (década de 1960), que estudiaron cómo las neuronas en la corteza visual de gatos respondían a estímulos:
- Descubrieron neuronas simples que respondían a líneas en cierta orientación y posición.
- Descubrieron neuronas complejas que respondían a patrones similares, pero en distintas posiciones (invarianza local).
Redes Convolucionales: Definición e Inspiración
¿Por qué necesitamos las Redes Convolucionales? Evitar la sobreparametrización. ¿Por qué esto es un problema?
🗓️ Algunos hitos importantes:
- 1990: Yann LeCun et al. propone uno de los primeros intentos de CNN, el cual va agregando features más simples en features más complejas progresivamente.
- 1998: Yann LeCun, propone LeNet-5 con 2 redes convolucionales y 3 FFN.
- 2012: Krizhevsky, Sutskever y Hinton proponen AlexNet (5 capas convolucionales y 3 FFN), el cual obtiene SOTA performance en ImageNet.

Convolutional Neural Network (CNNs)

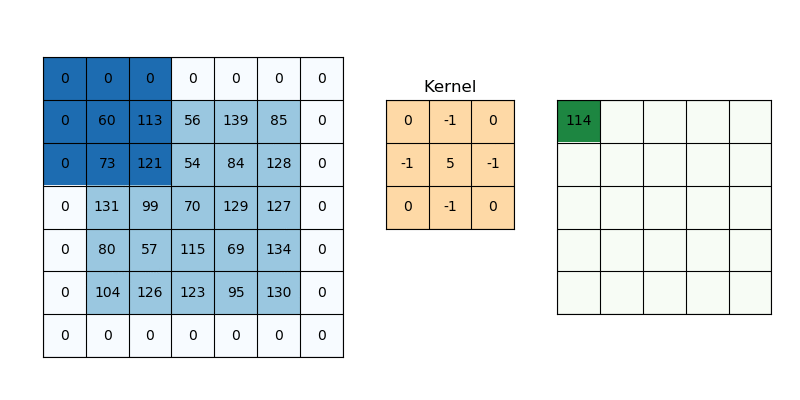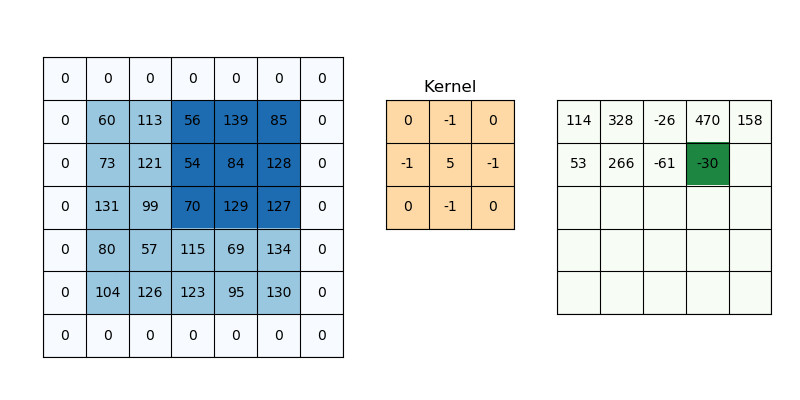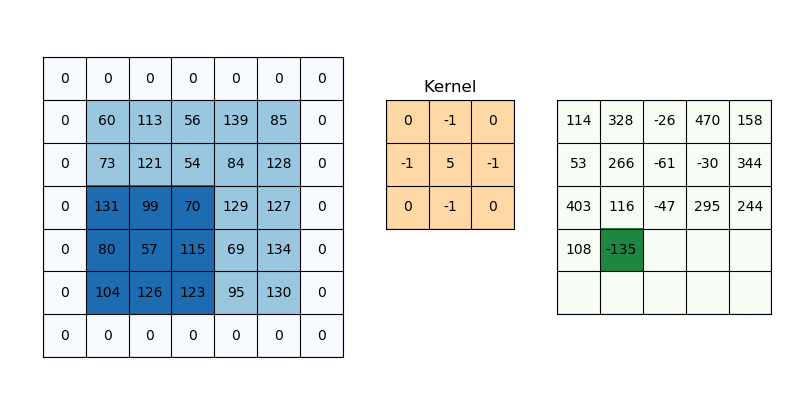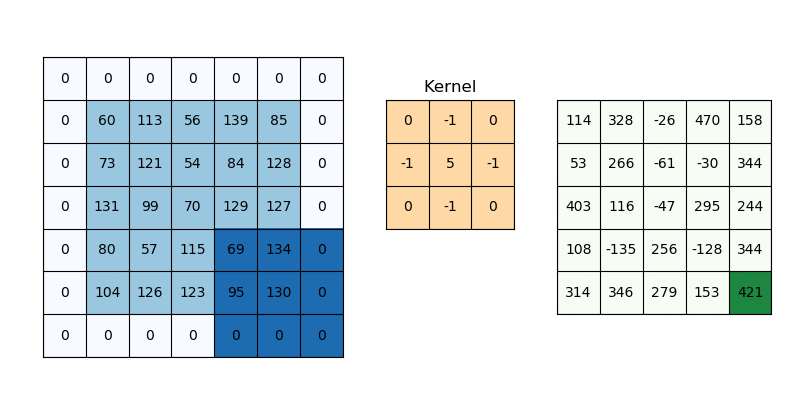
La Convolución
- Convolución
- Corresponde a una operación que permite extraer feature maps, donde un filtro o kernel se desplaza sobre distintas secciones de los datos, ya sea una secuencia, una imagen o un video, para capturar sus patrones más relevantes.
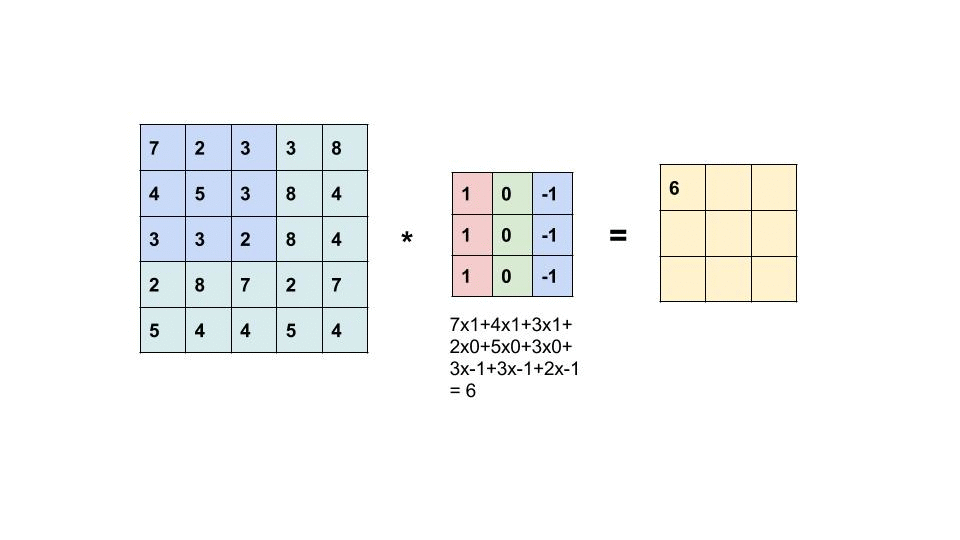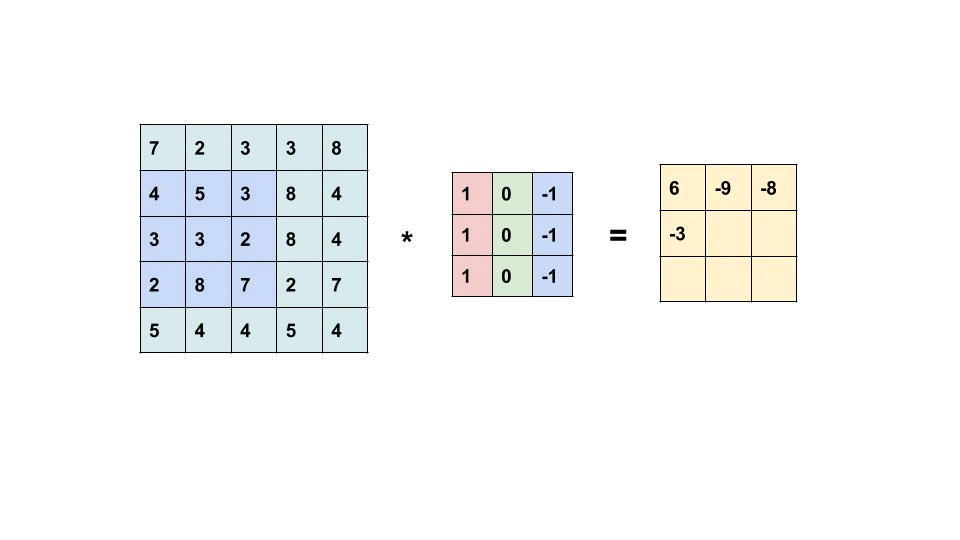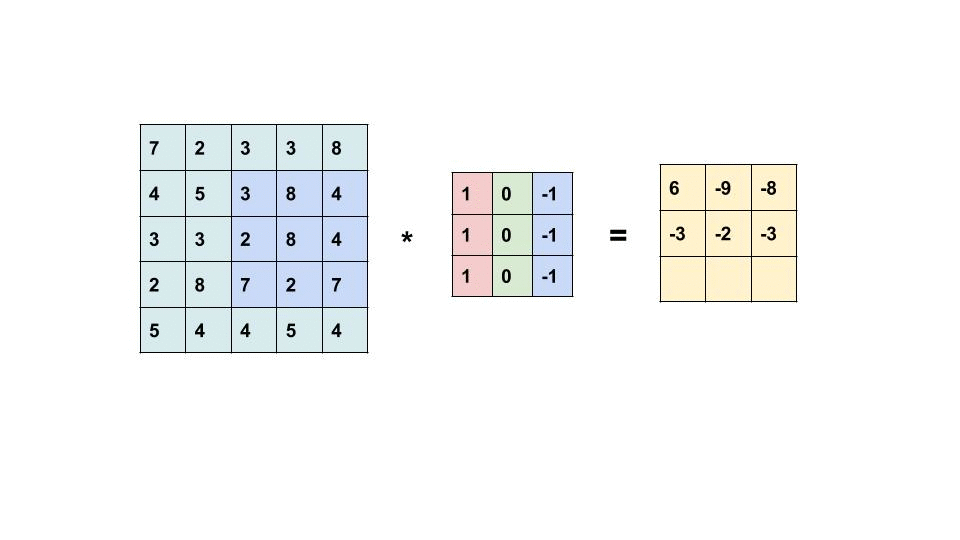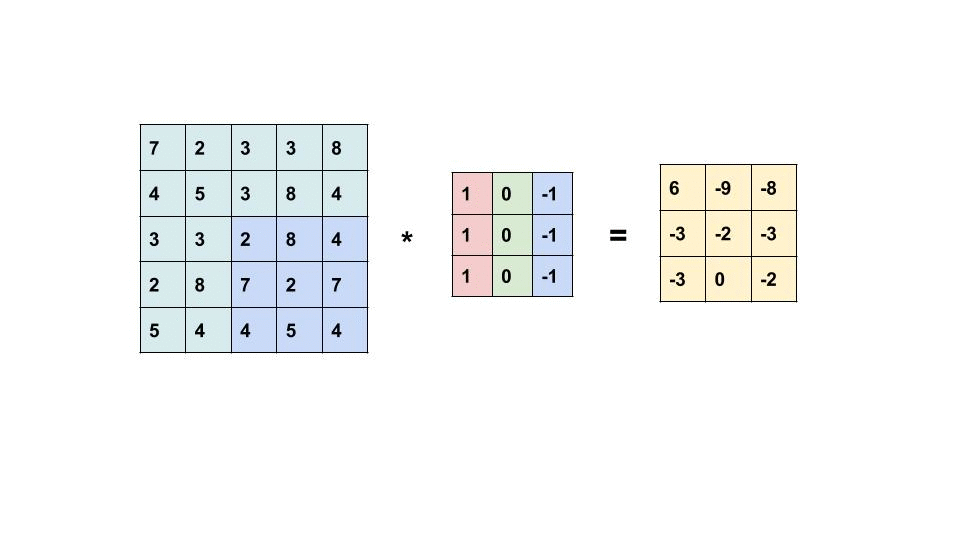
- Feature Map
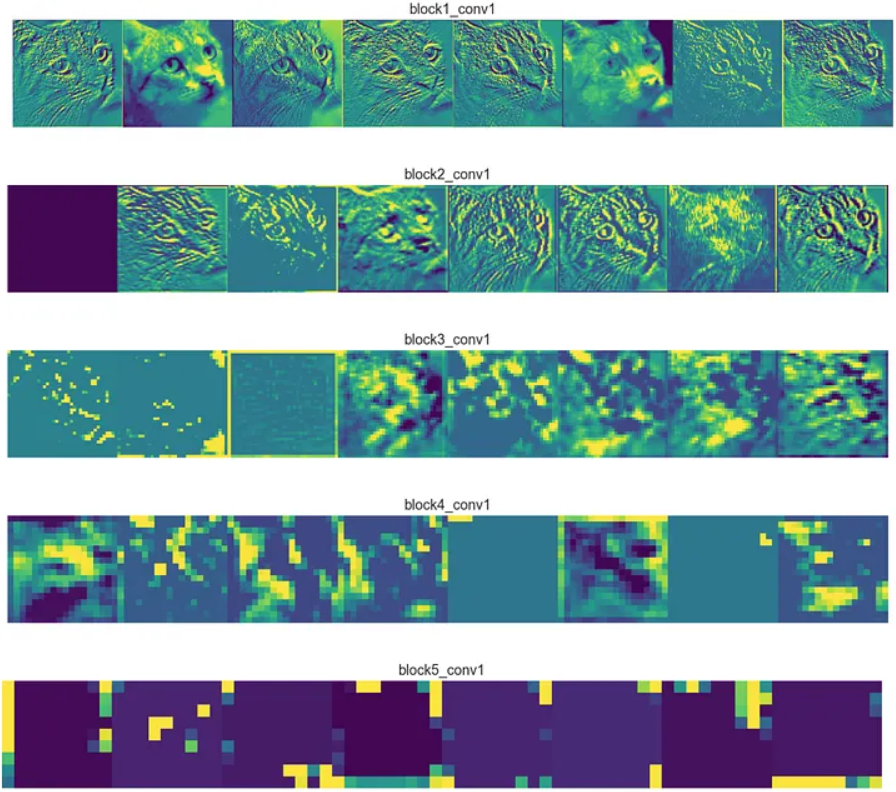
- Corresponde a la salida de una convolución (equivalente a la Activación) y es un nuevo tensor que captura ciertas características del dato (secuencia, imagen o video). Cuando se trata de imágenes, captura features como bordes, cambios de textura, color, formas, o elementos más pequeños.
Es importante notar que los features maps son de una tamaño menor a la entrada debido a la operación de Convolución.
Se obtendrán tantos feature maps como filtros se apliquen. Esto es otro hiperparámetro de la Red Convolucional que se conoce como los canales de salida o out_channels.
El filtro o Kernel
Gaussian Blur

Líneas Horizontales

Bordes

Kernel
Corresponde a una matriz pequeña que permite detectar patrones específicos en la imagen al aplicarse de manera móvil sobre ella. Estos Kernel solías estudiarse y diseñarse manualmente para tareas específicas como detección de bordes, desenfoque, realce de contraste, entre otros.
En una red convolucional, el kernel es un conjunto de pesos que se ajustan durante el proceso de entrenamiento para identificar características relevantes en las imágenes. Es decir, la CNN aprende qué Kernels son más importantes para la tarea que se está resolviendo.
El Kernel se aplica a todos los canales a la vez, lo cuál inicialmente lo hace ver como una operación bastante costosa computacionalmente.
El Kernel introduce el primer hiperparámetro de las CNN que es el Kernel Size. En general son cuadrados, y de dimensión impar.
Feature Maps
- Feature Map
- Corresponde a la salida de una convolución (equivalente a la Activación) y es un nuevo tensor que captura ciertas características del dato (secuencia, imagen o video). Cuando se trata de imágenes, captura features como bordes, cambios de textura, color, formas, o elementos más pequeños.
Hiperparámetros de la Convolución

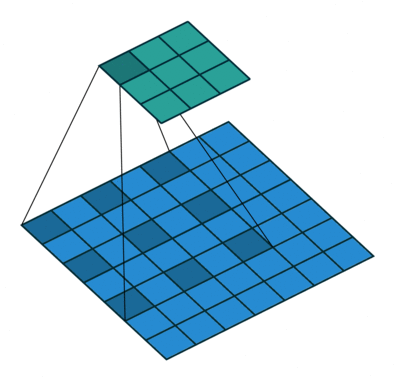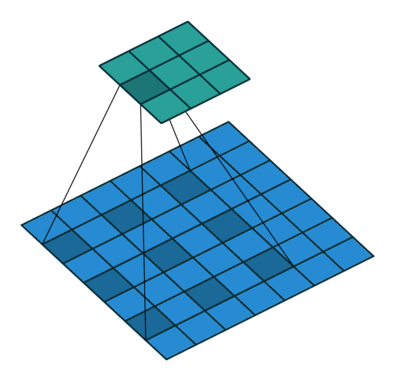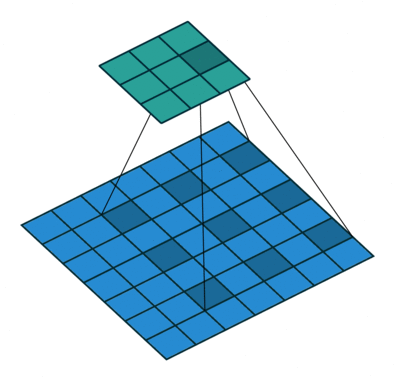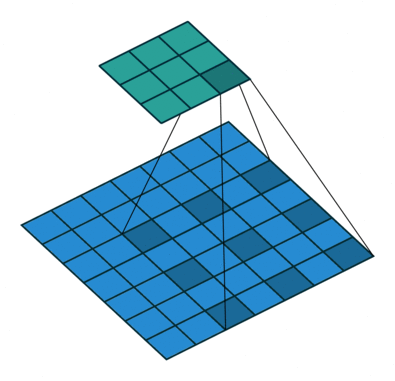
Partes de una CNN: Pooling
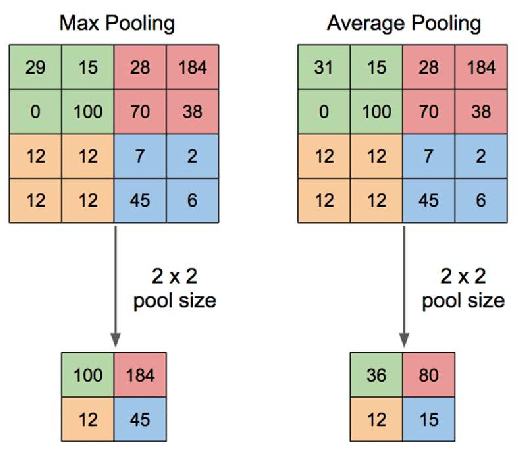
- Pooling
- El Pooling es una operación de agregación que permite ir disminuyendo el tamaño de las entradas. De esta manera la red puede comenzar a especializarse en aspectos cada vez más finos.
El Pooling también se aplica de manera móvil como una convolución. Pero a diferencia de esta normalmente no genera traslape.
Acá se introduce otro hiperparámetro que es el Pooling Size. En general es cuadrado y de dimensión par, y utiliza un stride del mismo tamaño que el Pooling Size para evitar traslapes.

AdaptivePooling
La mayoría de las arquitecturas CNN modernas aplican un procedimiento llamado Adaptive Pooling antes de la etapa de predicción (FFN). Independientemente del tamaño de la imagen de entrada, el Adaptive Pooling siempre genera una salida de tamaño fijo, ya que ajusta sus parámetros para asegurar que la dimensión de salida sea la deseada.
MNIST con CNN
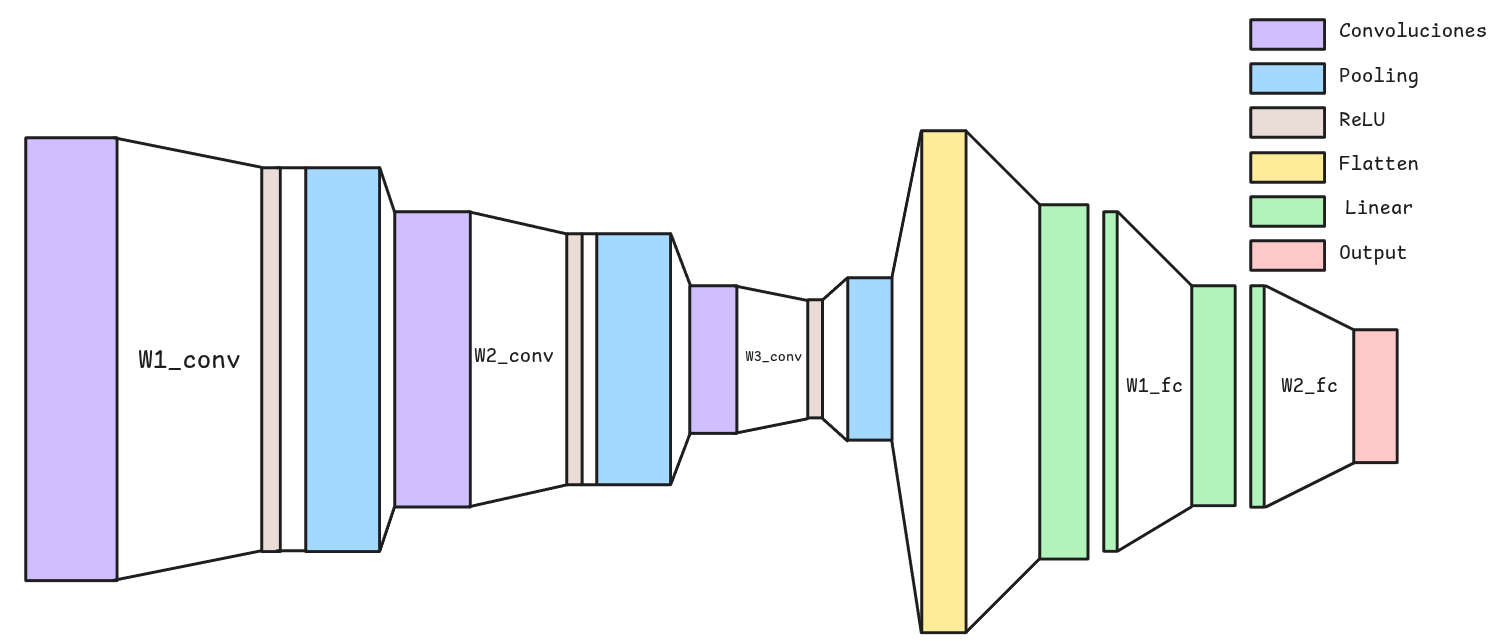
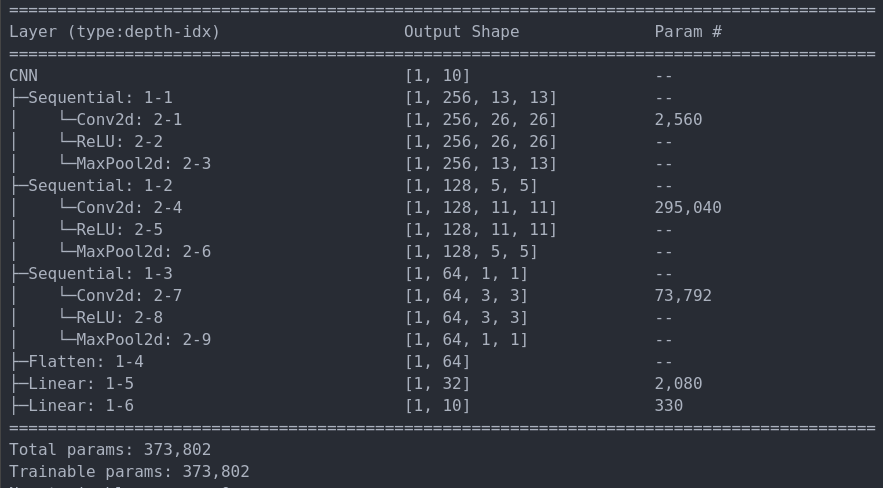
- El número de Parámetros para una Red Convolucional con muchas más capas bajó considerablemente, de 67M a 373K de Parámetros para una imagen de \(512 \times 512\).
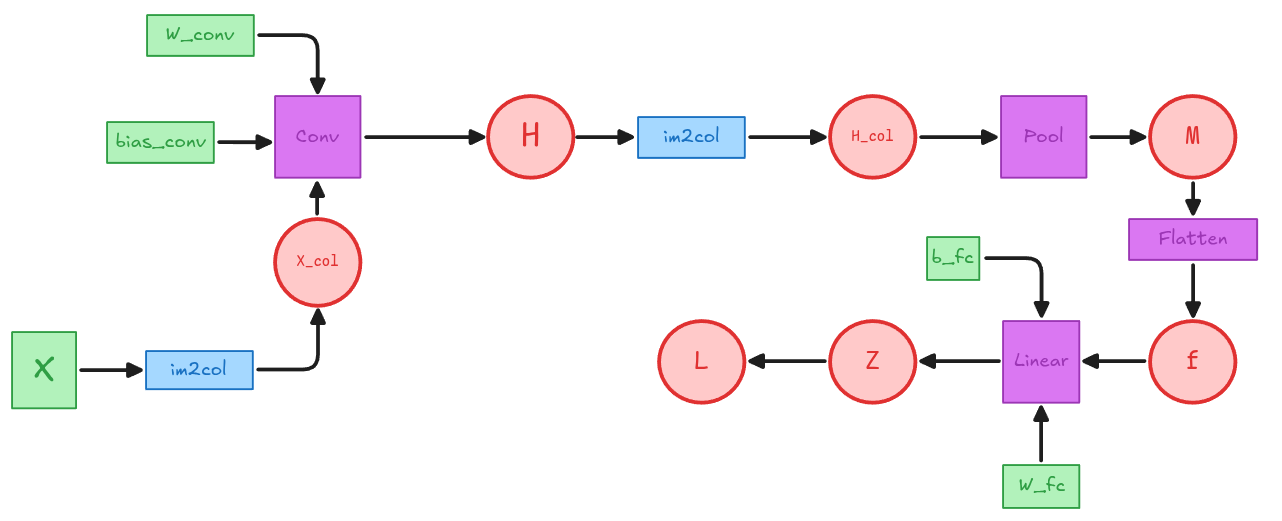
Grafo CNN sencilla
## Una Imagen de 1 Canal de Tamaño 6x6
X = torch.tensor([
[[[7., 6., 8., 5., 1., 3.],
[8., 6., 5., 3., 5., 5.],
[9., 1., 1., 5., 3., 5.],
[4., 5., 5., 9., 2., 6.],
[9., 5., 3., 1., 2., 2.],
[4., 4., 8., 8., 9., 8.]]]
])
X.shape(1,1,6,6)## 2 filtros de un Canal de tamaño 3x3
given_w = torch.tensor([
[[[1., 1., 0.],
[ -1., 1., -1.],
[ 0., -1., -1.]]],
[[[1., 1., 0.],
[-1., 1., -1.],
[ -1., 0., -1.]]]])
given_w.shape(2,1,3,3)Grafo CNN sencilla: Convolución
def calculate_out(X, k_size=(3,3), stride=1, dilation=1, padding=0):
kH, kW = k_size
N, in_channels, H_in, W_in = X.shape
out_H = np.floor((H_in +2*padding-dilation*(kH-1)-1)/stride + 1)
out_W = np.floor((W_in +2*padding-dilation*(kW-1)-1)/stride + 1)
return int(out_H), int(out_W)
H_out, W_out = calculate_out(X, k_size = (kH,kW))
H_out, W_out(4,4)O = torch.zeros((N, C_out, H_out, W_out))
for n in range(N):
for co in range(C_out):
for i in range(H_out):
for j in range(W_out):
# submatriz de tamaño kH x kW
patch = X[n, :, i:i+kH, j:j+kW]
O[n, co, i, j] = (patch * given_w[co]).sum() + given_bias[co]
Otensor([[[[ 5., 5., -1., -4.],
[ -4., -7., -1., -6.],
[ -1., -10., 6., -8.],
[ -9., -8., -6., -6.]],
[[ -3., 5., 3., -6.],
[ -3., -7., 3., -13.],
[ -5., -12., 4., -7.],
[ -9., -4., -6., -5.]]]])Este proceso es extremadamente ineficiente computacionalmente hablando. Por lo que se utiliza un proceso equivalente llamado im2col.
im2col
im2col es un algoritmo que permite transformar la operación de convolución en una operación de multiplicación de matrices, lo cual es computacionalmente más eficiente. En este caso los parches que requieren la convolución se aplanan y se organizan en columnas de una nueva matriz.

El procedimiento en Pytorch se realiza de la siguiente manera:
## Cada columna es un patche aplanado de 3x3. 16 patches en total.
X_col = F.unfold(X, kernel_size=(kH, kW)) # (1, 9, 16) (N,kH*kW,n_patches)
print(f"X_col shape: {X_col.shape}")
X_colX_col shape: torch.Size([1, 9, 16])
tensor([[[7., 6., 8., 5., 8., 6., 5., 3., 9., 1., 1., 5., 4., 5., 5., 9.],
[6., 8., 5., 1., 6., 5., 3., 5., 1., 1., 5., 3., 5., 5., 9., 2.],
[8., 5., 1., 3., 5., 3., 5., 5., 1., 5., 3., 5., 5., 9., 2., 6.],
[8., 6., 5., 3., 9., 1., 1., 5., 4., 5., 5., 9., 9., 5., 3., 1.],
[6., 5., 3., 5., 1., 1., 5., 3., 5., 5., 9., 2., 5., 3., 1., 2.],
[5., 3., 5., 5., 1., 5., 3., 5., 5., 9., 2., 6., 3., 1., 2., 2.],
[9., 1., 1., 5., 4., 5., 5., 9., 9., 5., 3., 1., 4., 4., 8., 8.],
[1., 1., 5., 3., 5., 5., 9., 2., 5., 3., 1., 2., 4., 8., 8., 9.],
[1., 5., 3., 5., 5., 9., 2., 6., 3., 1., 2., 2., 8., 8., 9., 8.]]])Variante en 1d
- Conv1d
- Corresponde a la variante de una dimensión, en la cual la entrada corresponden a secuencias de elementos como podrían ser series de tiempo, audio o hasta cadenas de texto.
Variante en 3d
- Conv3d
- Corresponde a la variante de tres dimensiones, en la cual la entrada corresponde a secuencias de imágenes, es decir, videos.
