TICS-579-Deep Learning
Clase 7: Transfer Learning y Image Augmentation
Arquitecturas Famosas
Crear arquitecturas de CNN desde cero es una tarea compleja y que requiere de mucho conocimiento y experiencia. Afortunadamente, existen diversas arquitecturas famosas que han sido probadas y testeadas en el tiempo, las cuáles pueden ser utilizadas como backbones para distintas tareas de Visión por Computador.
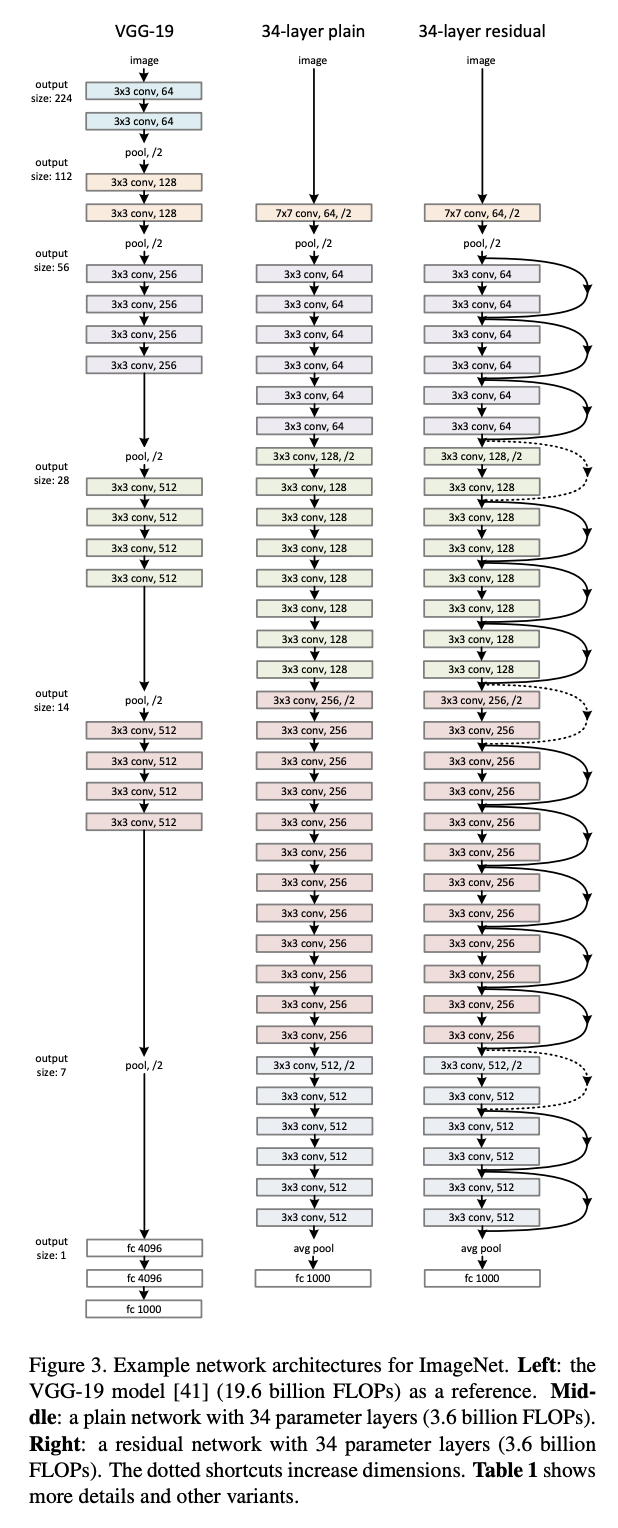
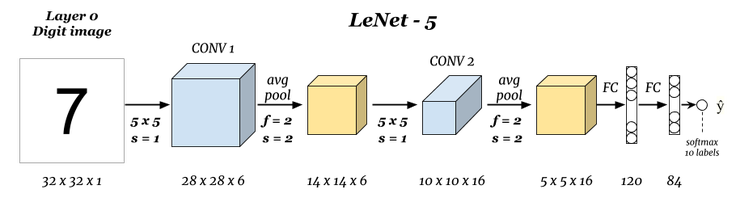
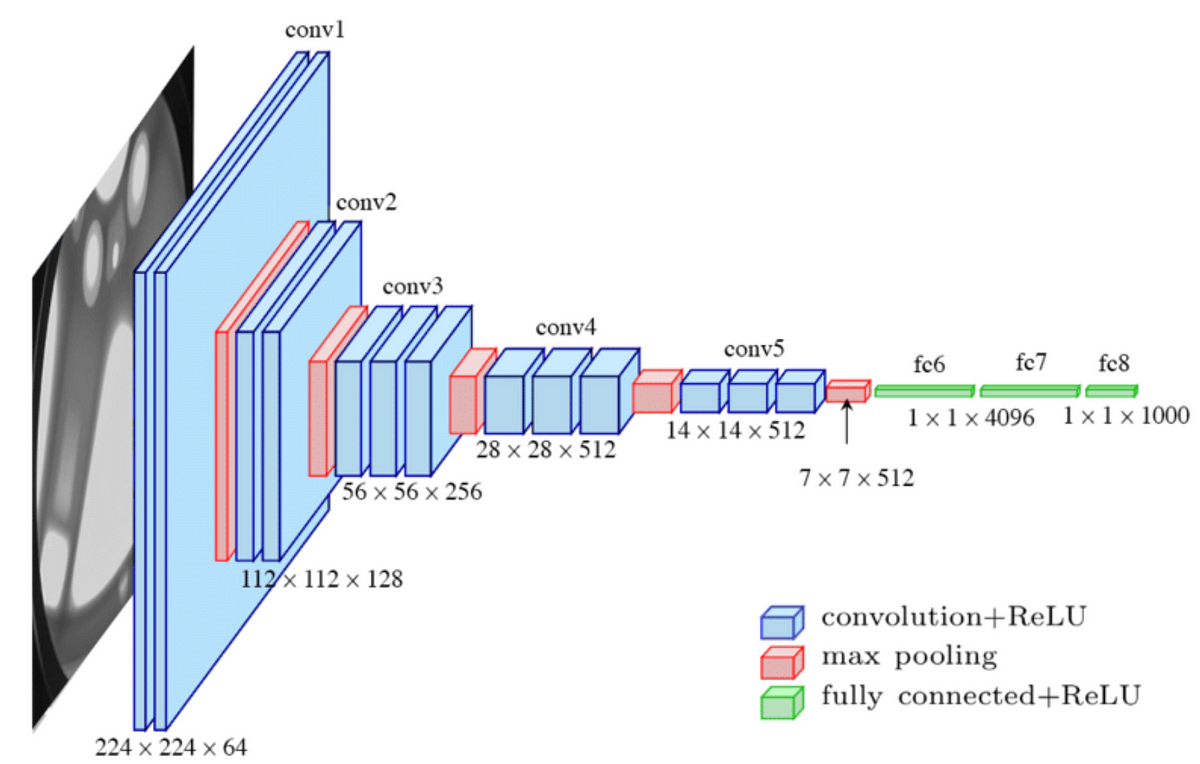
LeNet-5 (LeCun et al., 1998)
Probablemente la primera arquitectura famosa en poder realizar tareas importantes de reconocimiento de imagen. Diseñada especialmente para reconocimiento de dígitos, introduce los bloques de convolución más pooling para luego conectarse con FFN.
AlexNext (Krizhevsky, Sutskever y Hinton, 2012)
Ganó el concurso Imagenet (ILSVRC) en 2012 por un largo margen (algo impensado para ese tiempo). Introdujo los conceptos de ReLU, Dropout y Aceleración por GPU. Esta arquitectura está disponible en
torchvision.
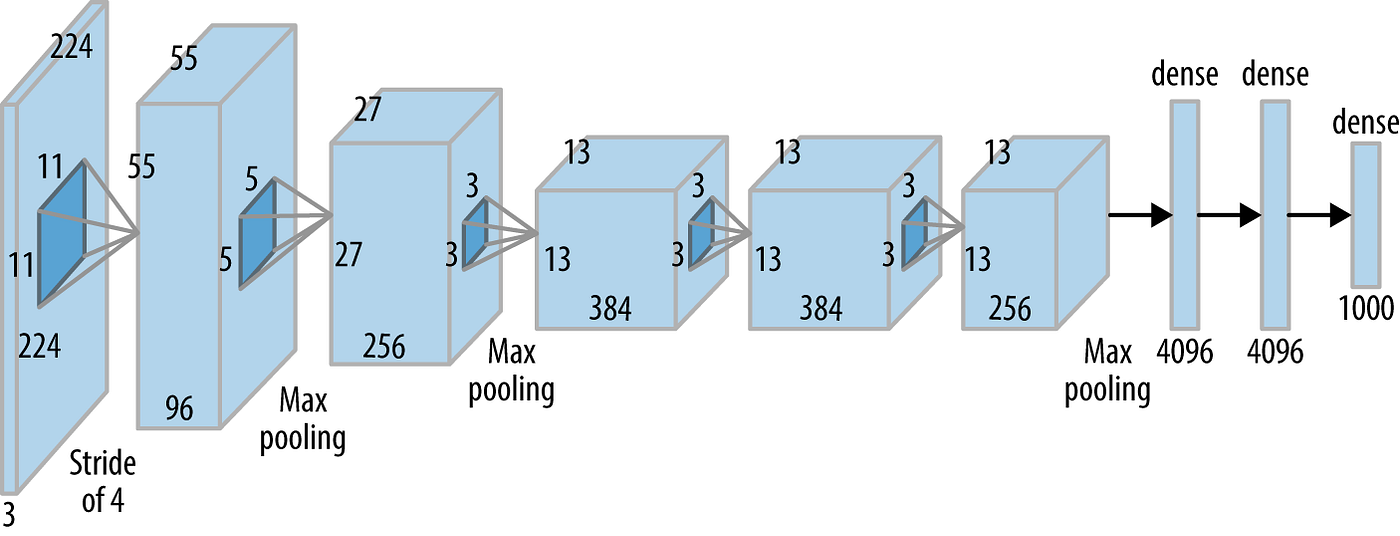
La arquitectura de Torchvision está inspirada en una versión alternativa de Alexnet. Esto probablemente no será corregido ya que no es una arquitectura que se utilice comunmente en la actualidad.
VGGNet (Simonyan, Zisserman, 2014)
Presentaron las primeras redes relativamente profundas con Kernels pequeños de \(3 \times 3\). Su propuesta incluye Redes de hasta 19 capas.
import torchvision
torchvision.models.vgg16(weights = "IMAGENET1K_V1")
## Versión con Batchnorm
torchvision.models.vgg16_bn(weights = "IMAGENET1K_V1")torchvision incluye las arquitecturas de 11, 13, 16 y 19 capas, además de variantes que incluyen Batchnorm (que en eltiempo del paper no existían aún).
GoogleNet/Inception (Szegedy et al., 2014)
Introduce las “Pointwise Convolutions” (Convoluciones de 1x1) que permiten reducir la complejidad de canales (mediante una combinación lineal) manteniendo las dimensiones de la imagen. Además introduce los Inception Modules, que combinan resultados de Kernels de distinto tamaño. Fue la Arquitectura ganadora de ILSVRC 2014.
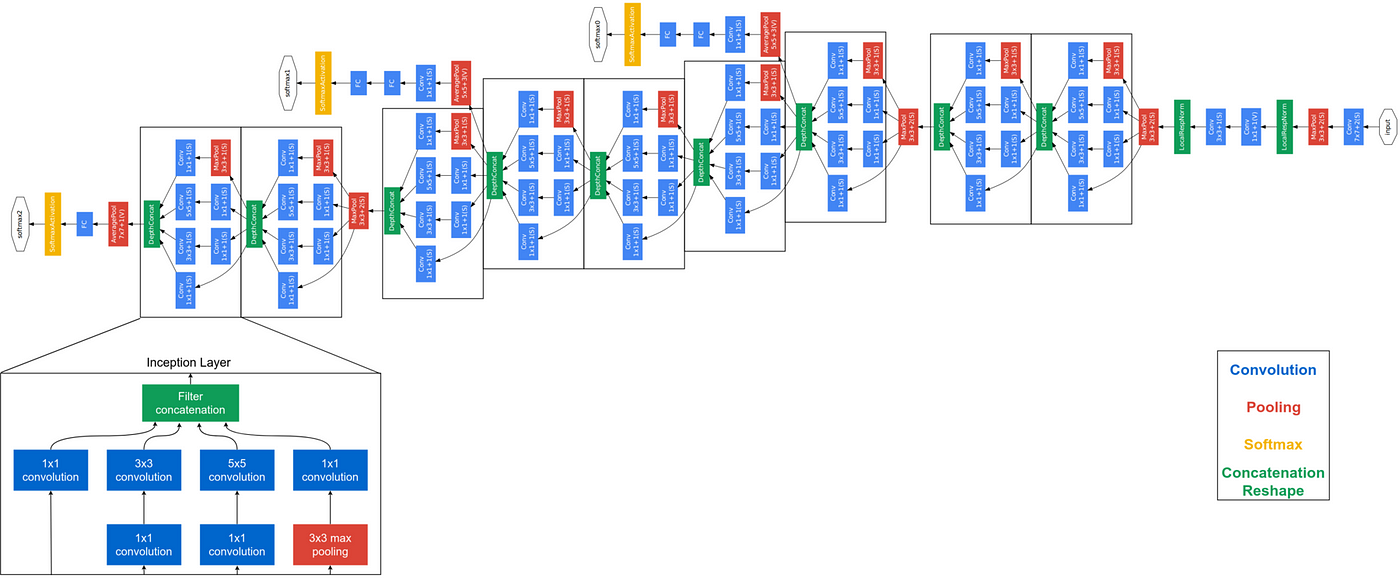
![]()
![]()
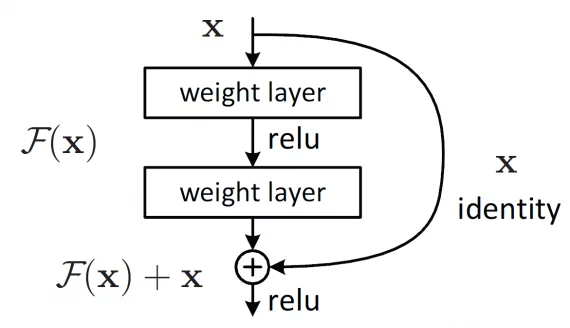
Resnet (He et al., 2015)
Introduce las conexiones residuales, lo cual permite evitar el problema del vanishing gradient para redes muy profundas. Es la Arquitectura ganadora de ILSVRC 2015.
Esta arquitectura se puede encontrar tanto en torchvision como timm. Recomiendo timm, ya que hay muchas más variantes, mejor mantención y procesos de entrenamiento actualizados.
import timm
model = timm.create_model("resnet50", pretrained = True)
## Listar todas las versiones de Resnet disponibles
timm.list_models("resnet*")Conexiones Residuales
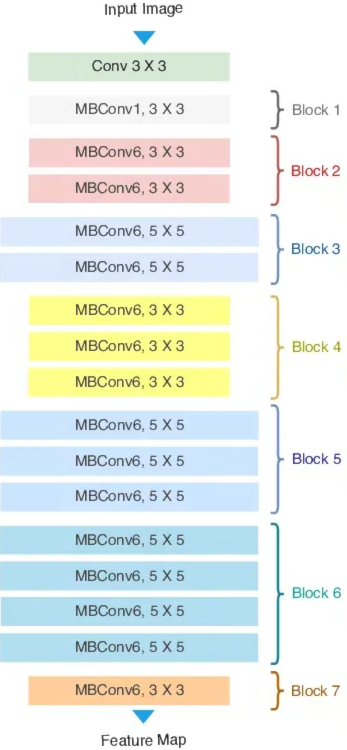
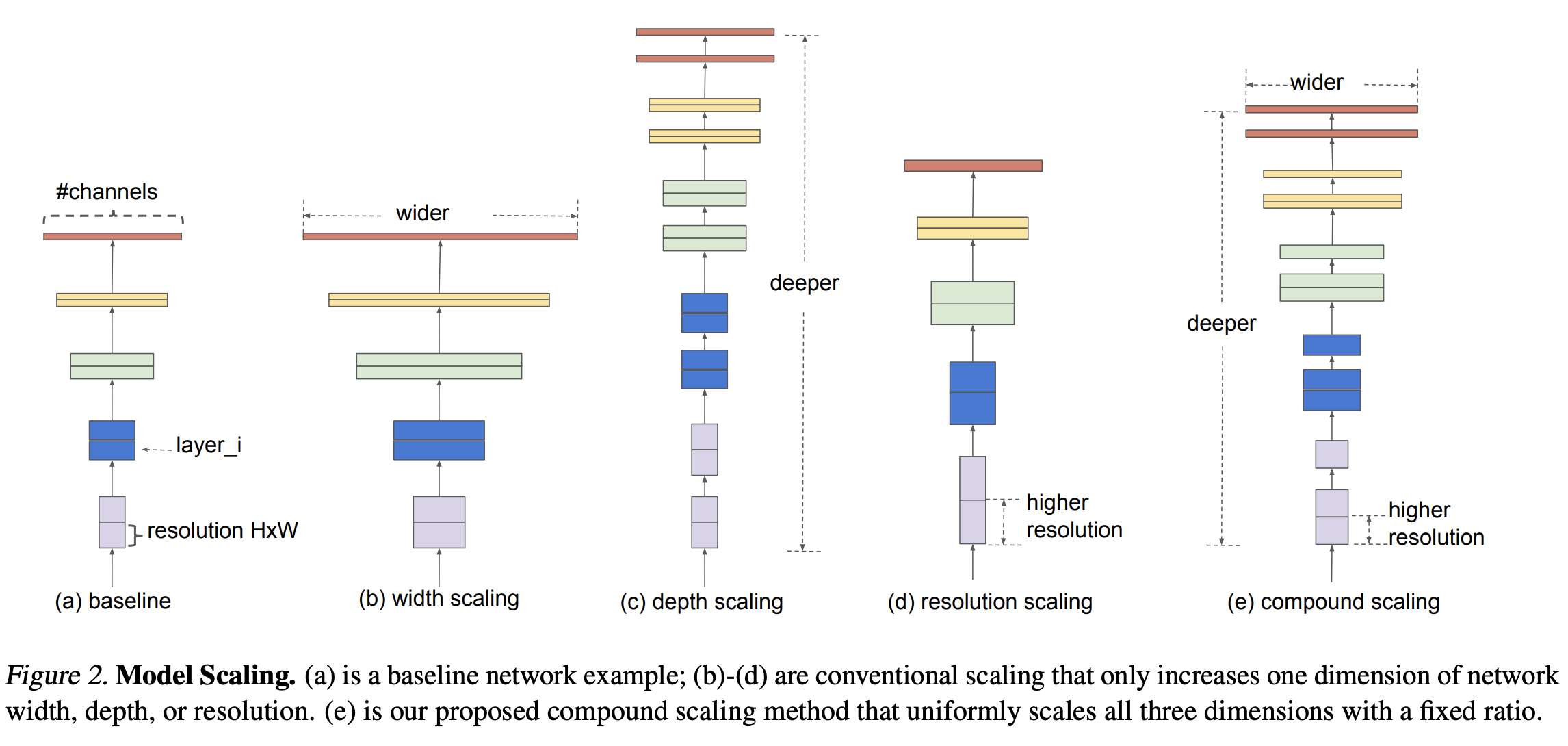
EfficientNet (Tan, Le, 2019)
Introducen el concepto de Compound Scaling que permite cambiar la escala de profundidad (número de capas en la red), ancho (número de canales en cada capa) y resolución (dimensiones de la imagen) para poder mejorar la performance. Permite crear resultados al nivel del estado del arte con muchísimos menos parámetros.
Transfer Learning
![]()
Data Augmentation
Corresponde a un proceso de generación de datos sintéticos. Este proceso se puede utilizar para:
- Permite la generación de datos adicionales debido a escasez por costo o disponibilidad de ellos. Ejemplo: Datos médicos.
- Genera variedad de datos, que entrega al modelo un mayor poder de generalización en datos no vistos.
- Al introducir mayor variabilidad en los datos entrega una mayor robustez ante el overfitting (Regularización).
- Simular condiciones adversas para el modelo en la cuál se quiera generar robustez.
- Ej: Se tiene un modelo de reconocimiento de vehículos, pero que tiene que funcionar en condiciones de niebla.

Normalmente este tipo de transformaciones entrega mejores resultados cuando se generan de manera aleatoria y on-the-fly. Es decir, se genera el aumento de datos en la carga de datos durante el entrenamiento.