TICS-579-Deep Learning
Clase 8: Redes Recurrentes
Datos Secuenciales
Hasta ahora, hemos asumido que los datos con los que trabajamos son independientes e idénticamente distribuidos (i.i.d). Sin embargo, en muchos casos, los datos tienen una estructura secuencial que debe ser considerada al momento de modelarlos. Algunos ejemplos comunes de datos secuenciales incluyen:
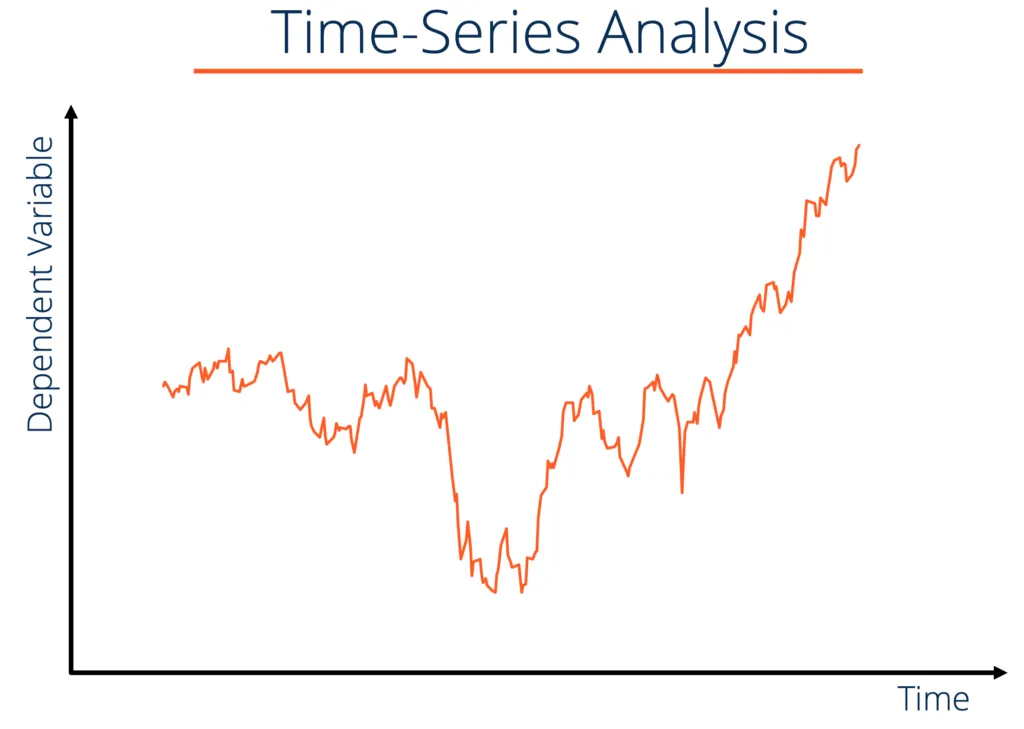
Time Series (precios de acciones, datos meteorológicos, etc)
Audio (grabaciones de voz, música, etc)

Texto (oraciones, documentos, etc)

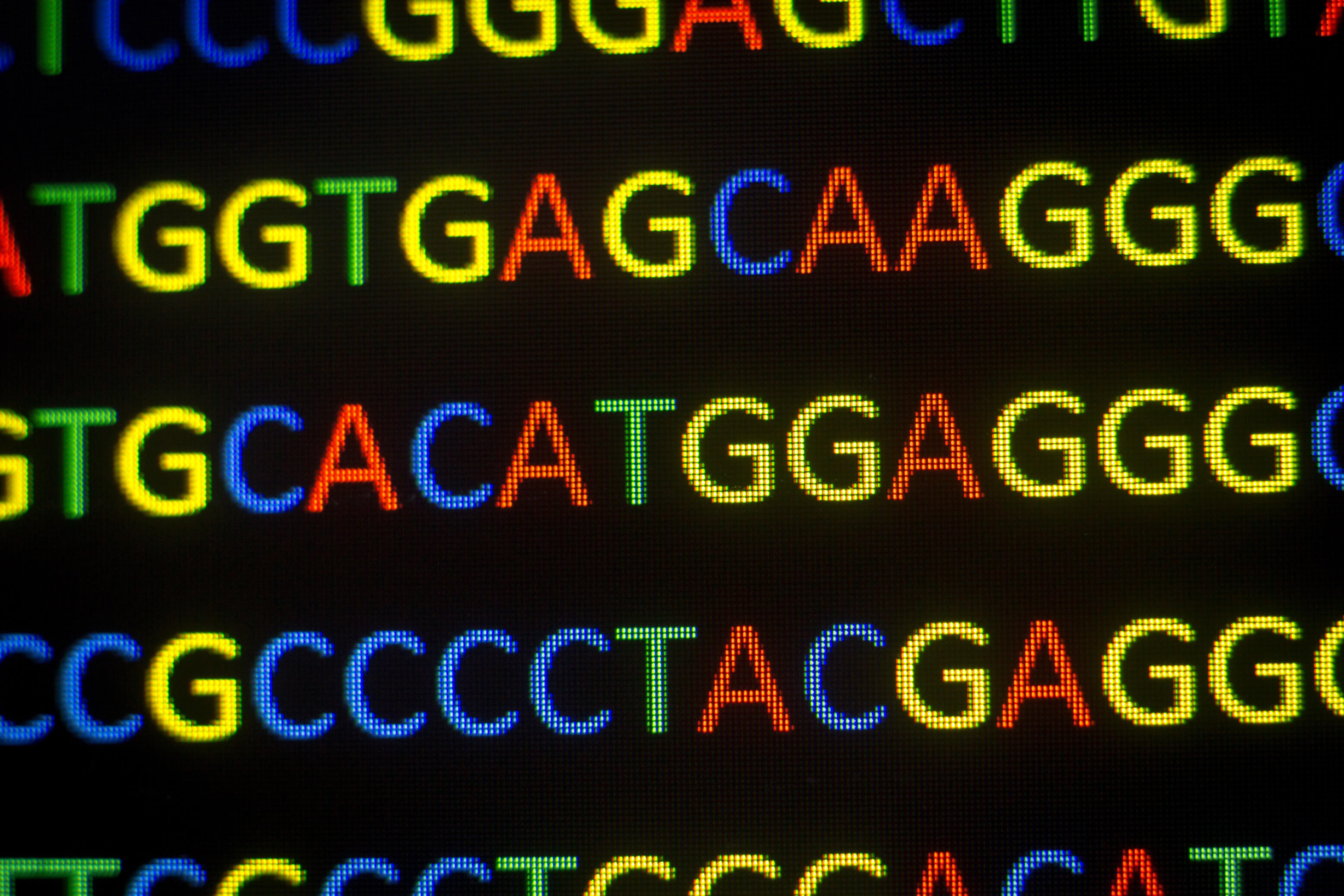
Genoma (secuencias de ADN, etc.)
Datos Secuenciales
También pudiesen existir datos “multimodales”, donde por ejemplo, se combinan secuencias con imágenes.
Image Time Series
Video

¿Cómo se ven datos secuenciales reales?
Redes Neuronales Recurrentes (RNNs)
- RNN
- Corresponden a un tipo de red neuronal diseñada para procesar secuencias de datos manteniendo en memoria los inputs previos. A diferencia de los otros tipos de redes que procesan datos de manera independiente, acá existen conexiones cíclicas que permiten retener información en el tiempo.
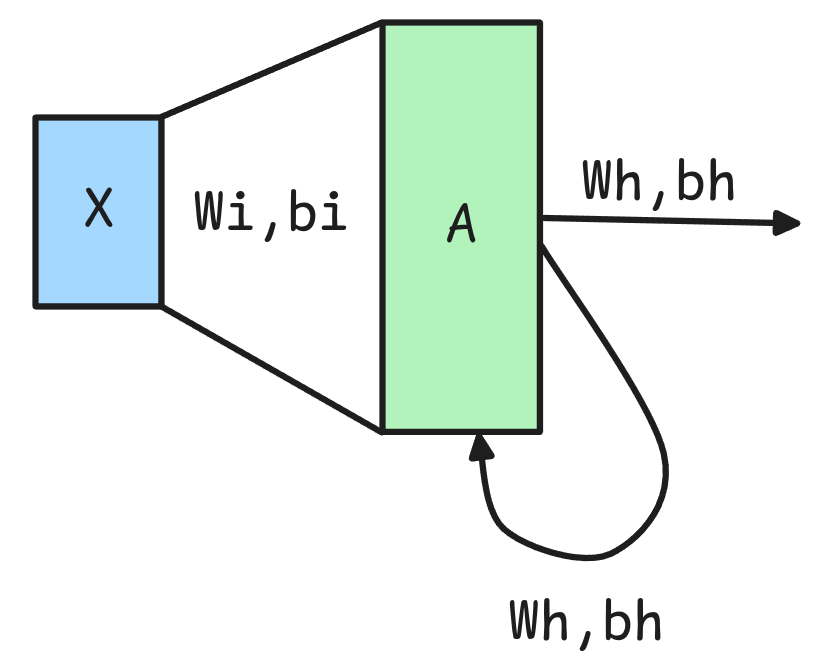
\[h_t = f(x_t \cdot W_{ih}^T + b_{ih} + h_{t-1} \cdot W_{hh}^T + b_{hh})\]
En la implementación original \(f\) corresponde a la \(tanh(\cdot)\).
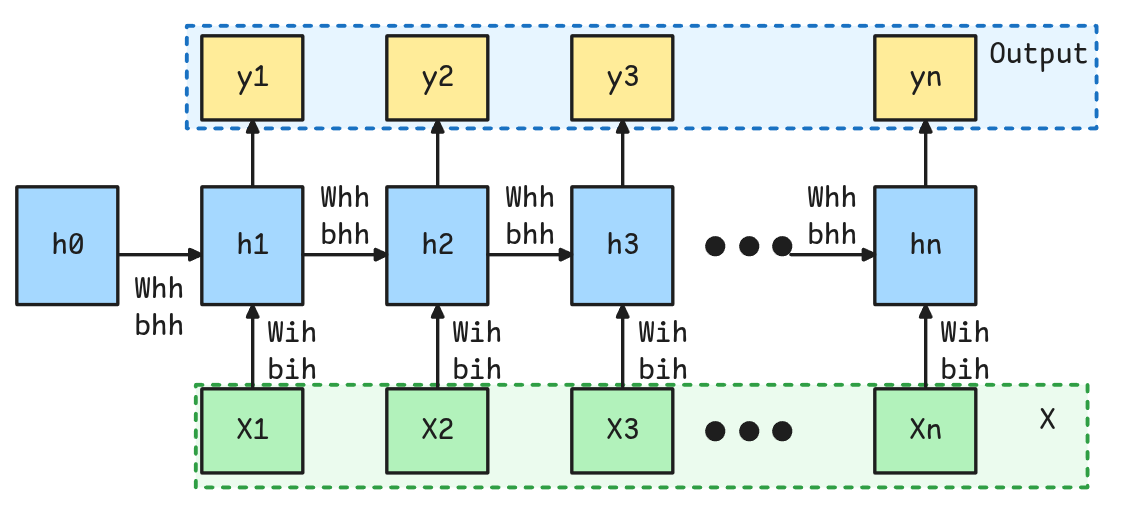
Unrolling RNN
Vanishing/Exploding Gradients
- Entre más larga se la secuencia (más unrolls se realicen), más difícil es entrenar la red debido a dos posibles problemas: el
vanishing gradient problemy elexploding gradient problem.
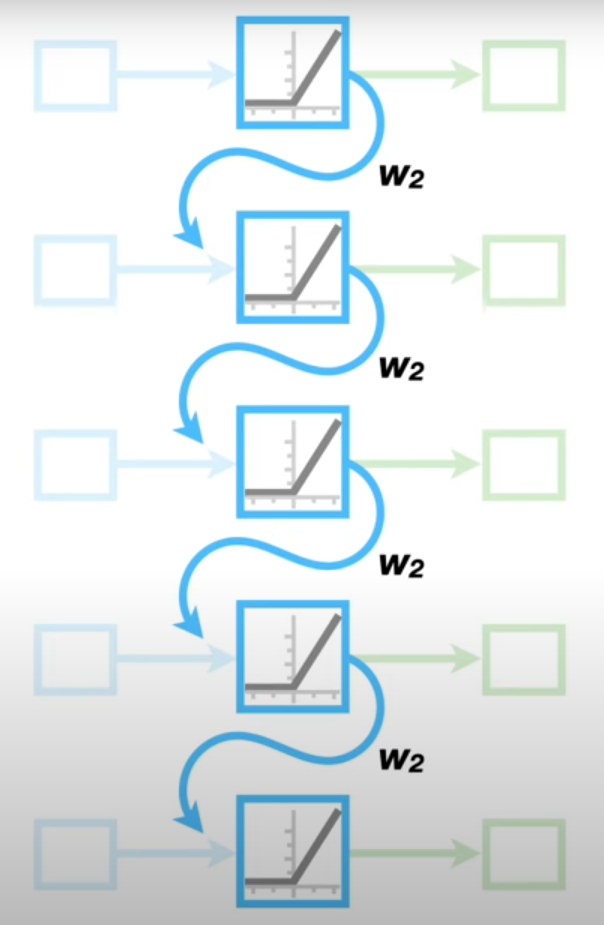
\[Gradiente = f(Input \times W_2^{N_{Unroll}})\]
Cuando los valores de \(W_2\) son muy pequeños (menores que 1), el gradiente tiende a desvanecerse (vanishing gradient).
En cambio, si los valores de \(W_2\) son muy grandes (mayores que 1), el gradiente tiende a explotar (exploding gradient).
$W_2^{N_unroll} aparece en la ecuación al momento de comenzar a derivar de manera recursiva.
Las Vanilla RNNs se utilizan muy poco en la práctica; sin embargo, tienen una relevancia histórica significativa, ya que sentaron las bases para el desarrollo de arquitecturas más avanzadas, como las LSTMs y los Transformers.
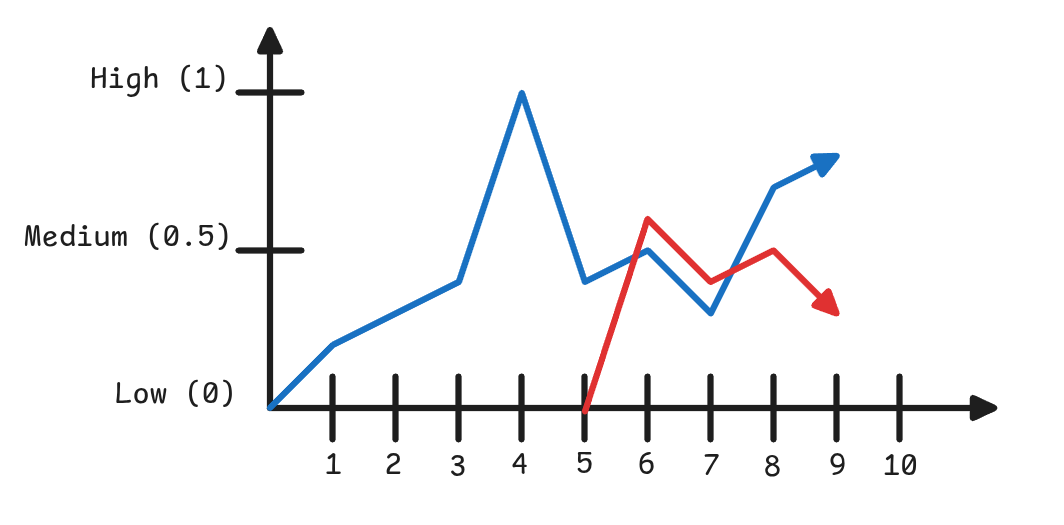
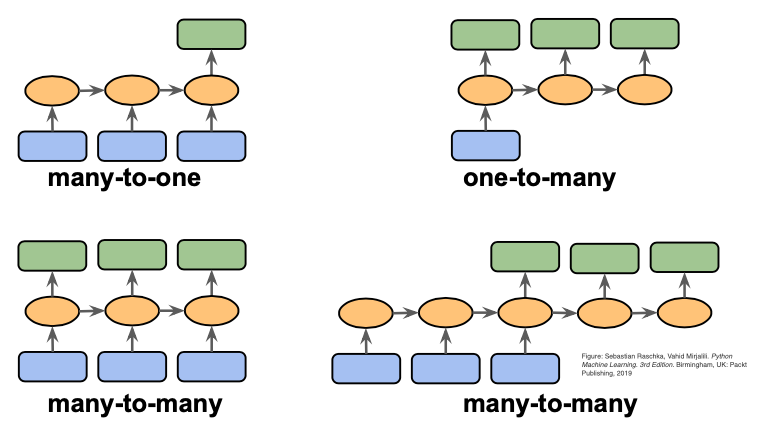
Tipos de Tareas a Resolver en Datos Secuenciales
Stacking RNNs
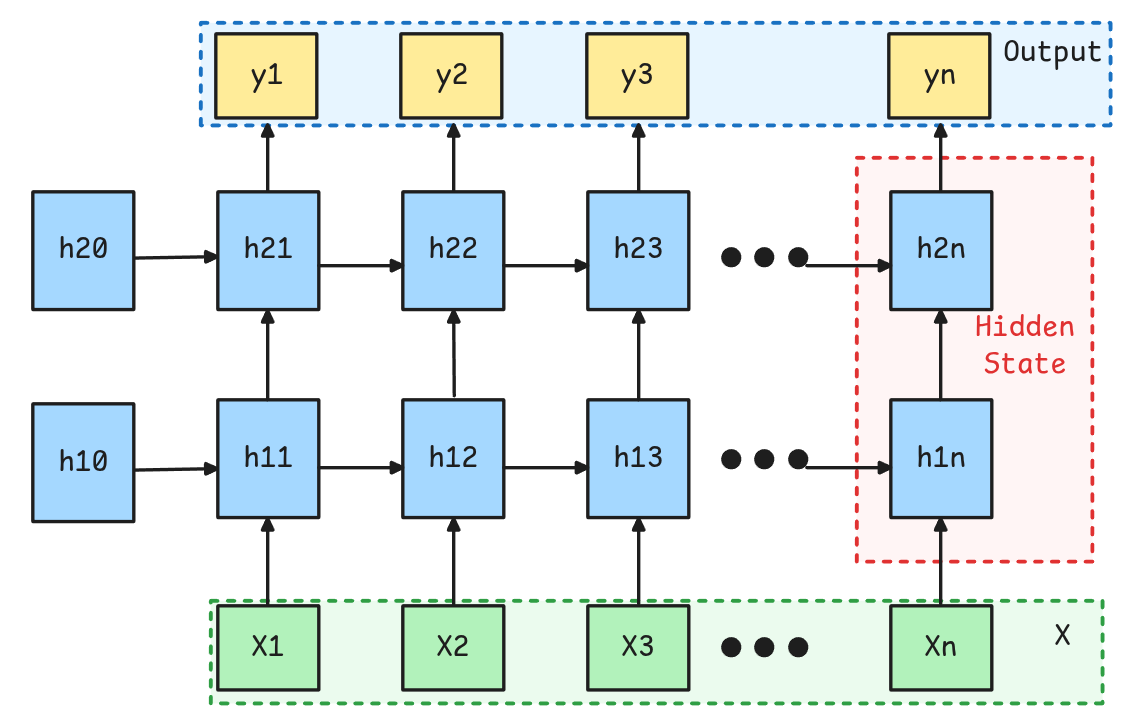
Es posible juntar varias capas recurrentes, para que las salidas de una alimenten un siguiente Hidden State, y que luego de algunas capas efectivamente se llegue a las salidas de interés.
Debido a que hacer esto es complicado esto viene integrado en la implementación en Pytorch mediante el parámetro num_layers.
OJO
No existen salidas intermedias, sino que los Hidden States de capas anteriores son utilizados directamente como inputs de los hidden states posteriores.
En Pytorch los Hidden States se devuelven concatenados. Es común utilizar el último Hidden State, es decir, la última salida de la última capa como Input Features para una capa Fully Connected.
A diferencia de otro tipos de Redes como las Convolucionales o FFN, la profundidad en este tipo de redes es de bastante menos impacto.
Variantes de RNNs: LSTM (1997)
- LSTM (Long Short-Term Memory)
-
Es un tipo de Red Neuronal Recurrente que está diseñada para capturar dependencias de largo plazo abordando algunas de las limitaciones de las RNNs tradicionales, tales como el
vanishing gradient problem.
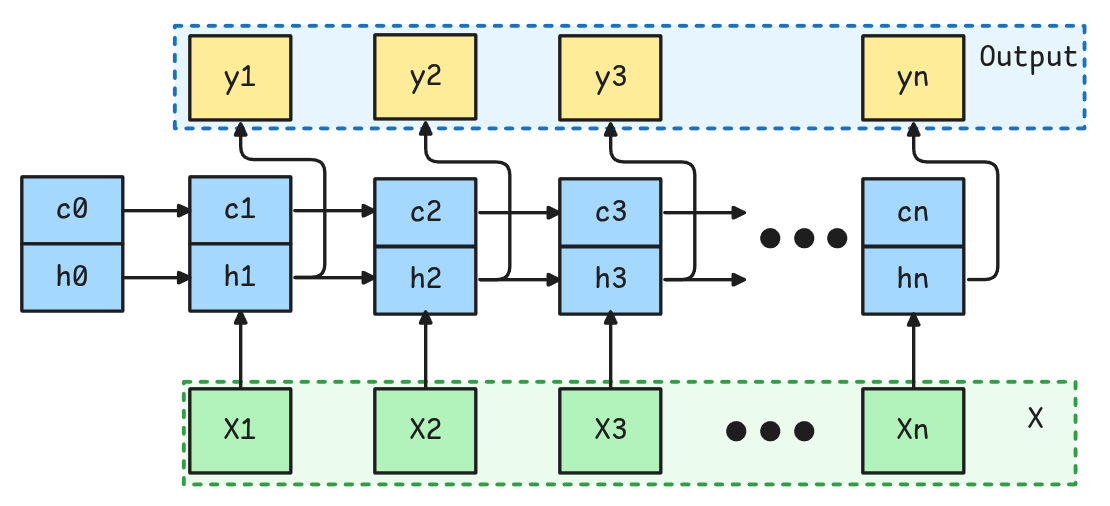
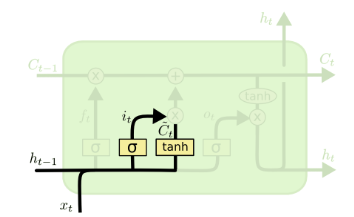
Posee un funcionamiento similar a la RNN, sólo que el “hidden state” se divide en dos partes: \(h_t\) y \(C_t\), llamados hidden state (corto plazo) y cell state (largo plazo) respectivamente.
Spoiler: El Hidden y Cell State está compuesto por multiples set de parámetros a los cuales se les dan los nombres de forget gate, input gate, cell gate y output gate. Su interpretabilidad nunca ha logrado ser completamente explicada.
Variantes de RNNs: LSTM (1997)
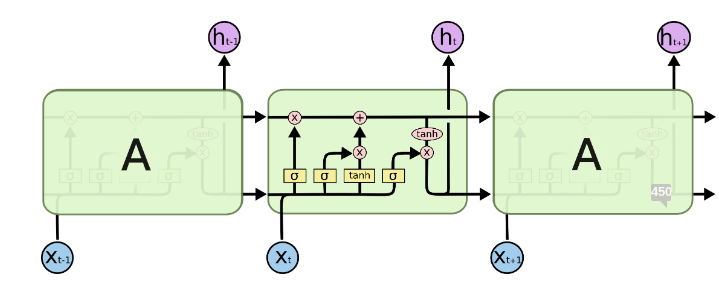
La LSTM está regida por las siguientes ecuaciones:
\[i_t = \sigma(W_{ii}x_t + b_{ii} + W_{hi}h_{t-1} + b_{hi})\]
\[f_t = \sigma(W_{if}x_t + b_{if} + W_{hf}h_{t-1} + b_{hf})\]
\[g_t = tanh(W_{ig}x_t + b_{ig} + W_{hg}h_{t-1} + b_{hg})\]
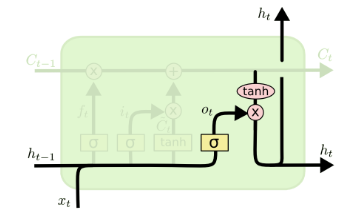
\[o_t = \sigma(W_{io}x_t + b_{io} + W_{ho}h_{t-1} + b_{ho})\]
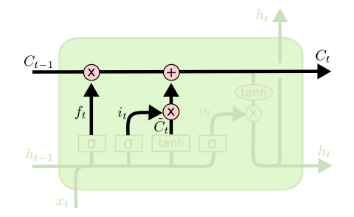
\[c_t = f_t \odot c_{t-1} + i_t \odot g_t\]
\[h_t = o_t \odot tanh(c_t)\]
Todas estos elementos \(i_t,f_t, g_t,o_t, c_t,h_t \in \mathbb{R}^d\), donde \(d\) es el “hidden_size”.
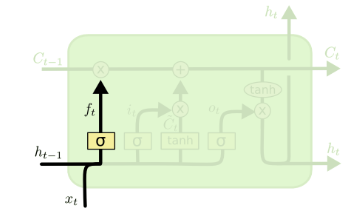
LSTM: Forget Gate
LSTM: Input y Cell Gate
Cell State
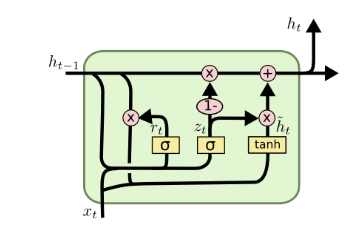
Variantes de RNNs: GRU (2014)
- GRU (Gated Recurrent Unit)
- Corresponde a otro tipo de Arquitectura Recurrente, similar a la LSTM, pero con una estructura más simplificada en la cuál se mantiene sólo un “Hidden State” y se tienen menos gates.
Bidirectional RNNs
Existen ocasiones en las que se requiere no sólo el contexto de los tiempos anteriores, sino también de los posteriores. Por ejemplo, problemas de traducción.
Para ello existen las redes bidireccionales, en la cual se agrega una segunda capa pero que mueve los hidden state en el otro sentido.
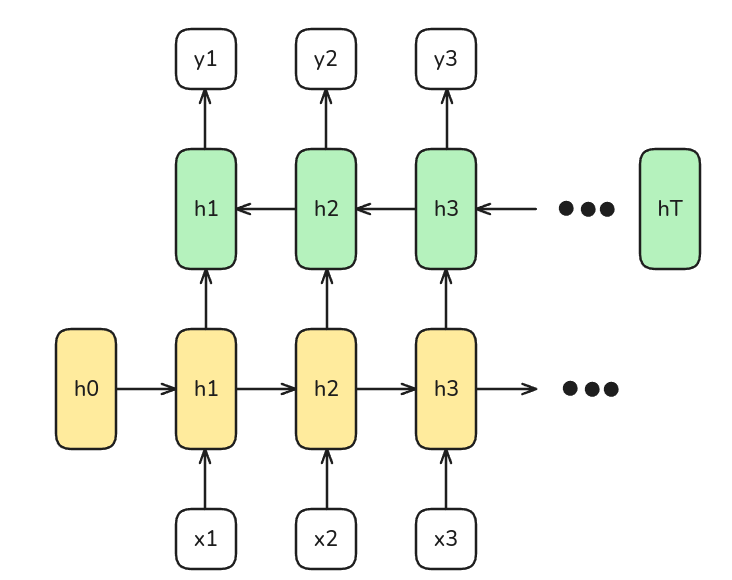
- En este caso la capa amarilla será la encargada de detectar dependencias del pasado.
- Mientras que la capa verde será la encargada de traer dependencias desde el futuro.
Los hidden states pueden ser capas Vanilla RNN, LSTM o GRUs.