TICS-579-Deep Learning
Clase 9: Manipulación de Datos de Texto
Natural Language Processing (NLP)



![]()

Speech Recognition
Dada la naturaleza secuencial del lenguaje, el contexto ayuda a interpretar cuál es la manera correcta de interpretar el sonido emitido.
Proceso de Tokenización y Embedding

Embeddings
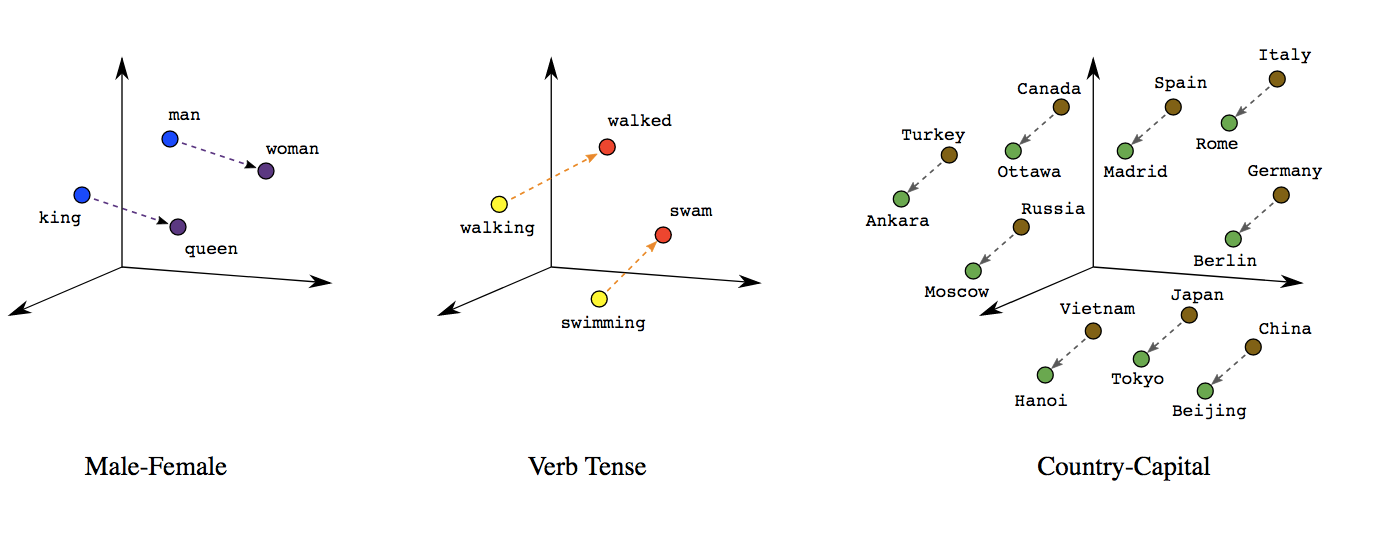
¿Por qué es tan importante el uso de Embeddings?
- Primero porque son entrenables. Es decir la red puede aprender cuál es la mejor manera de representar palabras.
- Existen embeddings pre-entrenados, es decir, se puede hacer transfer learning de embeddings.
- La red puede aprender relaciones semánticas entre palabras, algo imposible utilizando otras representaciones.
Problema de las RNN comunes
A pesar de las habilidades de las RNN, estas no son suficientes para distintas tareas de NLP.
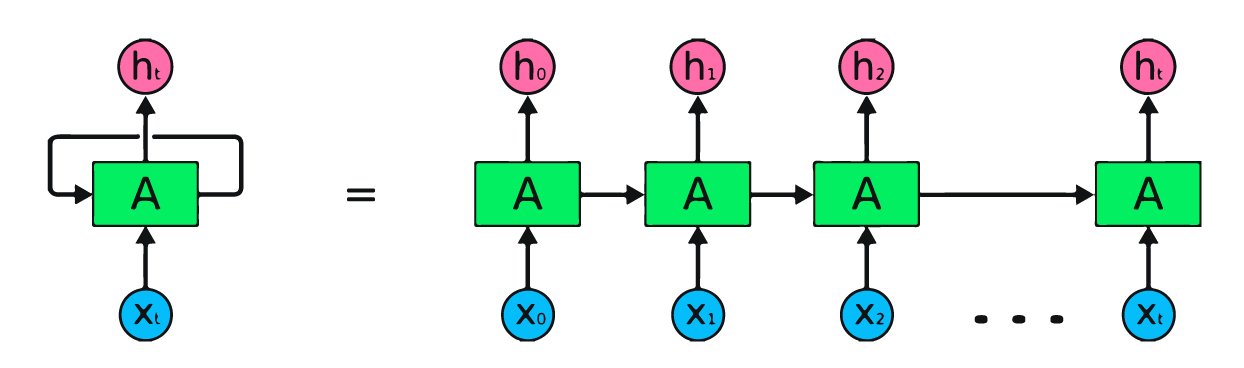
Las RNN inicialmente toman cada elemento de una secuencia y generan un output para cada entrada. Esto genera ciertas limitantes en tareas como Machine Translation, donde por ejemplo, el modelo asume que la traducción es uno a uno, lo cuál no es necesariamente cierto.
Soluciones: Redes Convolucionales
Una potencial solución se puede dar por medio de Redes Convolucionales de 1D. En este caso las redes convolucionales tienen la ventaja de poder mirar tanto al pasado como al futuro de manera móvil.
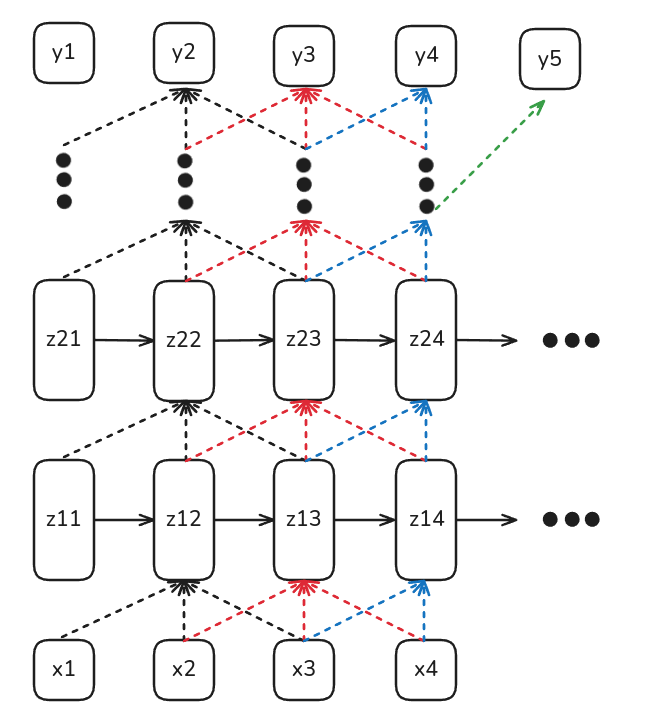
Ventajas
- Pueden tomar contexto desde el inicio y desde el final.
Desventajas
- Su campo receptivo es mucho más acotado y depende del número de capas y el largo del Kernel lo cual repercute directamente en el número de parámetros del modelo.
- No tienen estado latente (o memoria) que almacena contexto.
- No es útil para modelos de generación (ya que ve contexto desde el futuro).
Soluciones: Arquitecturas Encoder-Decoder
- Encoder
- Corresponde a una arquitectura que permitirá tomar datos de entrada y codificarlos en una representación numérica (normalmente como hidden states, embeddings o logits).
- Decoder
- Corresponde a una arquitectura que toma una representación codificada de datos (normalmente generado por un encoder) y la transforma nuevamente en una salida con un formato comprensible y no solamente una “simple etiqueta”.
Este tipo de arquitecturas son quizás las más populares hoy en día y tienen aplicaciones en distintos dominios.
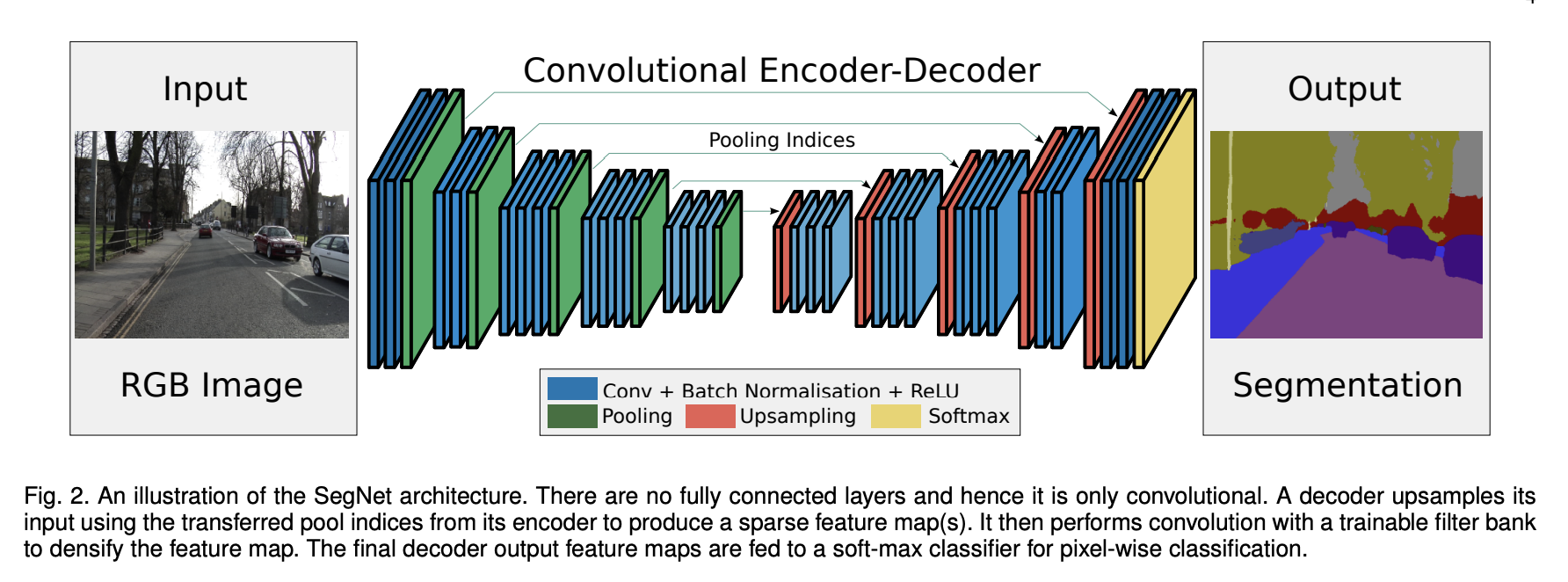
Soluciones: Arquitecturas Encoder-Decoder
Una arquitectura Encoder-Decoder convolucional permite devolver una imagen como salida. Este ejemplo se conoce como Segmentación Semántica.
Soluciones: Arquitecturas Encoder-Decoder
Una arquitectura recurrente permite devolver una secuencia como salida. La cual puede utilizarse para generación o traducción de texto.
![]()
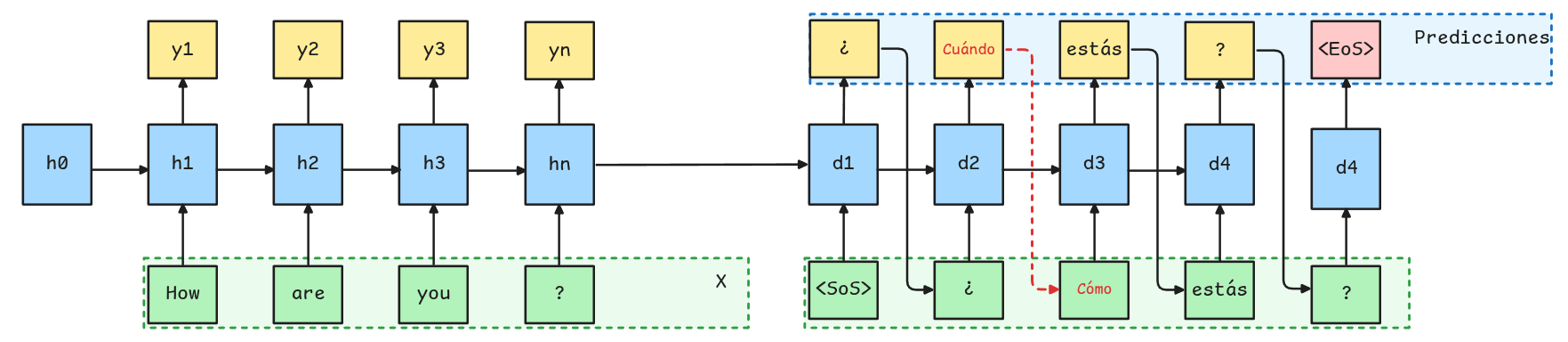
Ejemplo: Traducción de Texto
Supongamos que queremos traducir la frase How are you? al español.
![]()
![]()
![]()
Trucos de Entrenamiento
El entrenamiento de una RNN puede ser muy ineficiente y “trabado” si es que no se utilizan ciertos trucos. Algunos de estos trucos son:
Teacher Forcing
Trucos de Inferencia: Greedy Search
Estrategias para escoger el siguiente token
Al momento de generar texto, la salida de cada step del Decoder tendrá una distribución de probabilidad sobre el vocabulario. Existen distintas estrategias para escoger el siguiente token a utilizar:
Greedy Search
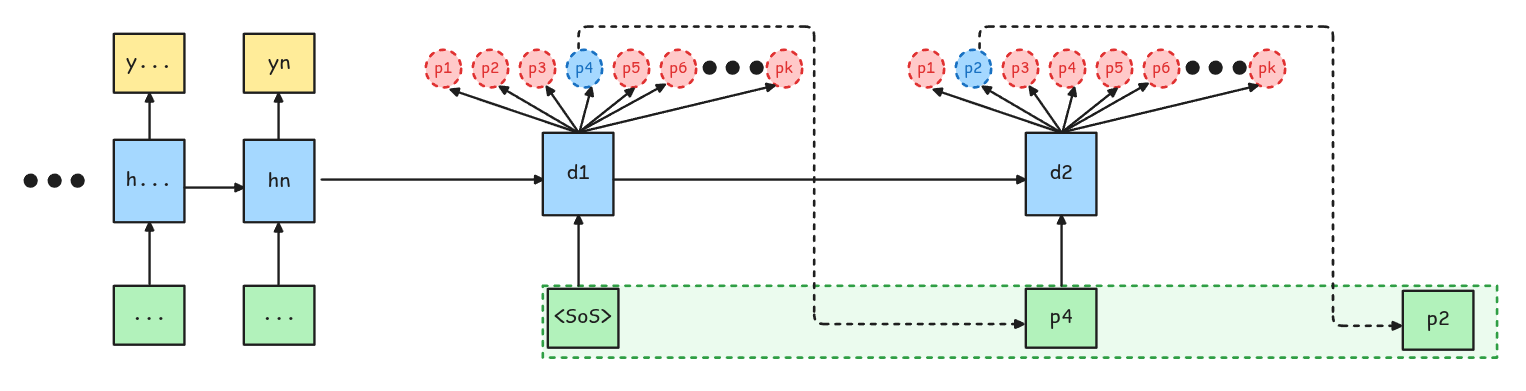
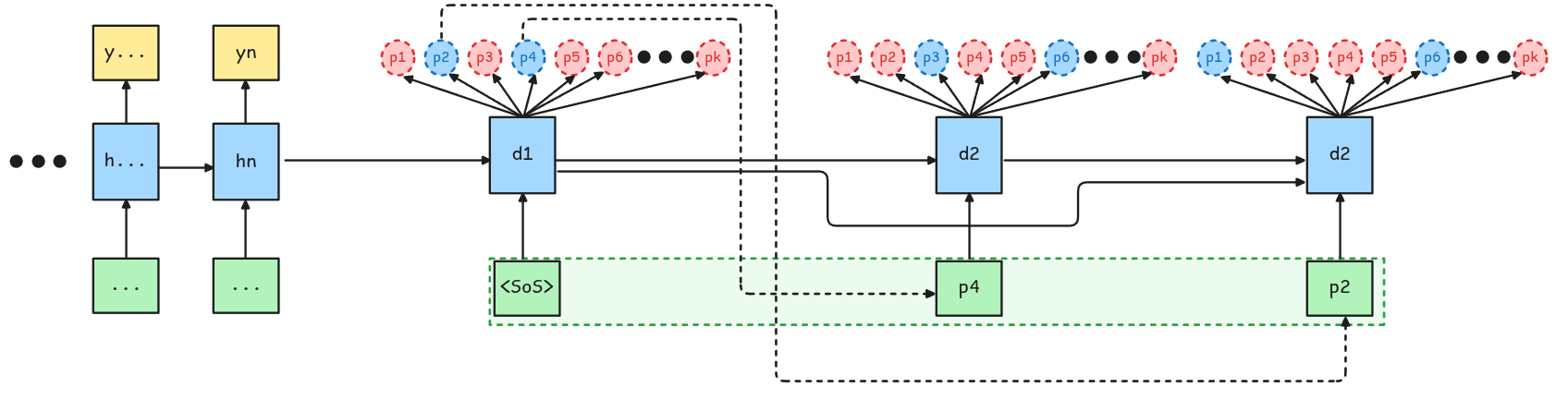
Trucos de Inferencia: Beam Search
Beam Search
En este caso se pueden escoger múltiples caminos en vez de solamente el de mayor probabilidad. Por ejemplo, si se escogen 2 caminos (beam width = 2), en el primer step se escogen los tokens con probabilidad p4 y p3. Luego en el segundo step, se generan las siguientes probabilidades para los distintos caminos. Acá se escoge el camino con la mayor probabilidad conjunta.