Derivadas
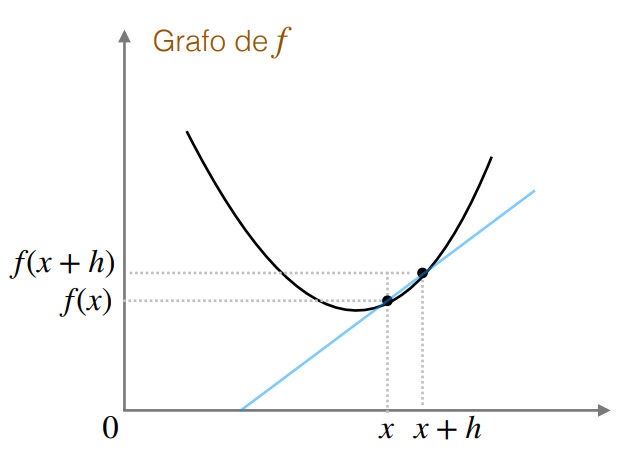
La derivada corresponde a la razón de cambio de una función con respecto a una variable de entrada \(x\). Es decir, cuánto cambia el valor de la función \(f(x)\) cuando cambiamos el valor de \(x\) en una cantidad infinitesimal \(h\).
La definición formal de la derivada
Para una función \(f: \mathbb{R} \rightarrow \mathbb{R}\), la derivada se define como: \[\frac{df(x)}{dx} = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}\]
- \(f(x + h) \approx f(x) + f'(x) \cdot h\), cuando \(h \to 0\).
- Si la derivada existe en \(x\), decimos que la función es derivable o diferenciable en \(x\).
- Si las derivadas laterales no existen o no son iguales, entonces \(f\) no es derivable en \(x\).
- Si \(f\) es derivable, entonces \(f\) es continua.
Esto se puede interpretar como la pendiente de la recta tangente a la curva de \(f(x)\) en el punto \(x\).
Derivadas: Ejemplos
- \((c)'= 0\)
- \((cx)' = c\)
- \((x^n)' = n x^{n-1}\)
- \((\sqrt{x})' = \frac{1}{2\sqrt{x}}\)
- \((\frac{1}{x})' = -\frac{1}{x^2}\)
- \((e^x)' = e^x\)
- \((ln(x))' = \frac{1}{x}\)
- \((log_a(x))' = \frac{1}{x ln(a)}\)
Reglas de Cálculo
- \((f+g)' = f' + g'\)
- \((fg)' = f'g + fg'\)
- \((\frac{f}{g})' = \frac{f'g - fg'}{g^2}\)
- \((\alpha f)' = \alpha f'\)
- \(f(x) = h(g(x)) \Rightarrow f'(x) = h'(g(x)) g'(x)\), conocida como la regla de la cadena.
Caso Multivariado
Si tenemos una función \(f: \mathbb{R}^n \rightarrow \mathbb{R}\). ¿Cómo se define la derivada?
- Se requiere una dirección para derivar. Dado por un vector \(\bar{v} \in \mathbb{R}^n\) y la recta que define.
La definición formal de la derivada direccional
Para una función \(f: \mathbb{R} \rightarrow \mathbb{R}\), la derivada en torno a \(\bar{x}\) en dirección \(\bar{v}\) (\(\bar{v}\) es un vector unitario) se define como: \[\nabla_{\bar{v}}f(x) = \lim_{h \to 0} \frac{f(\bar{x}+h\bar{v}) - f(\bar{x})}{h}\]
Este cálculo en general es poco práctico debido a que existen infinitas direcciones posibles. Por lo tanto, ¿cuál debería tomar?
Derivadas Parciales
Si \(f: \mathbb{R}^n \rightarrow \mathbb{R}\), se define la derivada parcial de \(f\) en torno a \(\bar{x}=(x_1,...,x_n)\) con respecto a la variable \(x_i\) como como la derivada direccional en la dirección del vector unitario \(\bar{e_i}\).
\[\frac{\partial f(x)}{\partial_{x_i}} = \lim_{h \to 0} \frac{f(x_1, ..., x_i + h, ..., x_n) - f(x_1, ..., x_i, ...x_n)}{h}\]
Gradiente: Función Escalar
Definimos el gradiente de \(f\) como:
\[
\begin{align}
\nabla f: \mathbb{R}^n &\rightarrow \mathbb{R}^{1 \times n} \\
\bar{x} &\rightarrow \nabla f(\bar{x}) = \begin{bmatrix}\frac{\partial f}{\partial x_1} & \dots & \frac{\partial f}{\partial x_n}\end{bmatrix}
\end{align}
\]
El gradiente podríamos considerarlo como un vector fila o columna según conveniencia. Por simplicidad lo dejaremos como un vector fila.
Derivada Direccional en función del Gradiente. ¿Cuál es la dirección en la que la Derivada Direccional es máxima?
\[\nabla_{\bar{v}}f(x) = \nabla f(x) \cdot \bar{v}\]
Gradiente: Ejemplo
\[f(x,y) = 3x^2 + 2xy + y^2 + 5x + 4\]
Consideremos entonces que \(\bar{x} = (x,y)\). Es decir, va de \(\mathbb{R}^2\) a \(\mathbb{R}\).
\[\nabla f(\bar{x}) = \nabla f(x,y) = \begin{bmatrix}\partial f_x & \partial f_y\end{bmatrix} = \begin{bmatrix} 6x + 2y + 5 & 2x + 2y\end{bmatrix}\]
Jacobiano: Función Vectorial
Sea \(f: \mathbb{R}^n \rightarrow \mathbb{R}^k\), el Jacobiano de \(f\) es la generalización del Gradiente y corresponderá a la matriz que contiene las derivadas parciales de una \(f\) multivariada respecto a cada una de sus variables de entrada.
Es decir, si \(f=(f_1(\bar{x}),...,f_k(\bar{x}))^T\)
Entonces,
\[
J = \begin{bmatrix}
- \nabla f_1(\bar{x}) -\\
\vdots \\
- \nabla f_k(\bar{x}) -\\
\end{bmatrix}
\]
Podemos pensar el Jacobiano como el “vector de Gradientes” stackeados hacia abajo para cada componente de la función multivariada. Como cada componente es un vector de \(1 \times n\), el Jacobiano tendrá dimensiones \(k \times n\).
Hessiano
Si la función a derivar es el Gradiente, entonces el Jacobiano pasa a llamarse Hessiano. Es decir, el Hessiano es el Jacobiano del Gradiente y es equivalente a la segunda derivada de una función vectorial/multivariada.
- El Hessiano es una matriz cuadrada de dimensiones \(n \times n\).
- Siempre es simétrica.
- Si el Hessiano es PSD (Positive Semi-Definite), entonces la función es convexa. Demostrando que \(\bar{x}^T H_f(\bar{x}) \bar{x} \geq 0\) para todo \(\bar{x}\).
\(\nabla f_i(\bar{x})\) corresponde a la componente \(i\) del Gradiente de \(f\) evaluada en \(\bar{x}\).
\[
H_f(\bar{x}) = \begin{bmatrix}
\frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \\
\frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \\
\vdots & \vdots & \ddots & \vdots \\
\frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2}
\end{bmatrix} = \begin{bmatrix}
- \nabla (\nabla f_1(\bar{x})) -\\
- \nabla (\nabla f_2(\bar{x})) -\\
\vdots \\
- \nabla (\nabla f_n(\bar{x})) -
\end{bmatrix}
\]
Hessiano: Ejemplo
\[f(x,y) = 3x^2 + 2xy + y^2 + 5x + 4\]
Consideremos entonces que \(\bar{x} = (x,y)\). Es decir, va de \(\mathbb{R}^2\) a \(\mathbb{R}\).
\[\nabla f(\bar{x}) = \nabla f(x,y) = \begin{bmatrix}\partial f_x & \partial f_y\end{bmatrix} = \begin{bmatrix} 6x + 2y + 5 & 2x + 2y\end{bmatrix}\]
\[ H_f(\bar{x}) = \begin{bmatrix}
- \nabla (\nabla f_1(\bar{x})) - \\
- \nabla (\nabla f_2(\bar{x})) - \\
\end{bmatrix} =
\begin{bmatrix}
6 & 2 \\
2 & 2
\end{bmatrix}\]
Automatic Differentiation
Supongamos que tenemos que calcular la derivada de \(f(1)\) de la siguiente función:
\[f(x) = \sqrt{x^2 + exp(x^2)} + cos((x^2 + exp(x^2))\]
- Su derivada analítica, luego de bastante esfuerzo es:
\[f'(x) = 2x \left(\frac{1}{2\sqrt{x^2+exp(x^2)}} - sen(x^2 + exp(x^2))\right)\left(1+exp(x^2)\right)\] \[f'(1) = 5.983\]
Calcular la derivada de manera analítica es muy engorroso y propenso a errores. Además, si la función tiene muchas variables, el cálculo se vuelve inviable y difícil de programar. Por ello se utiliza la diferenciación automática, un proceso algorítmico que permite calcular derivadas de funciones complejas de manera eficiente y precisa.
Automatic Differentiation: Ejemplo
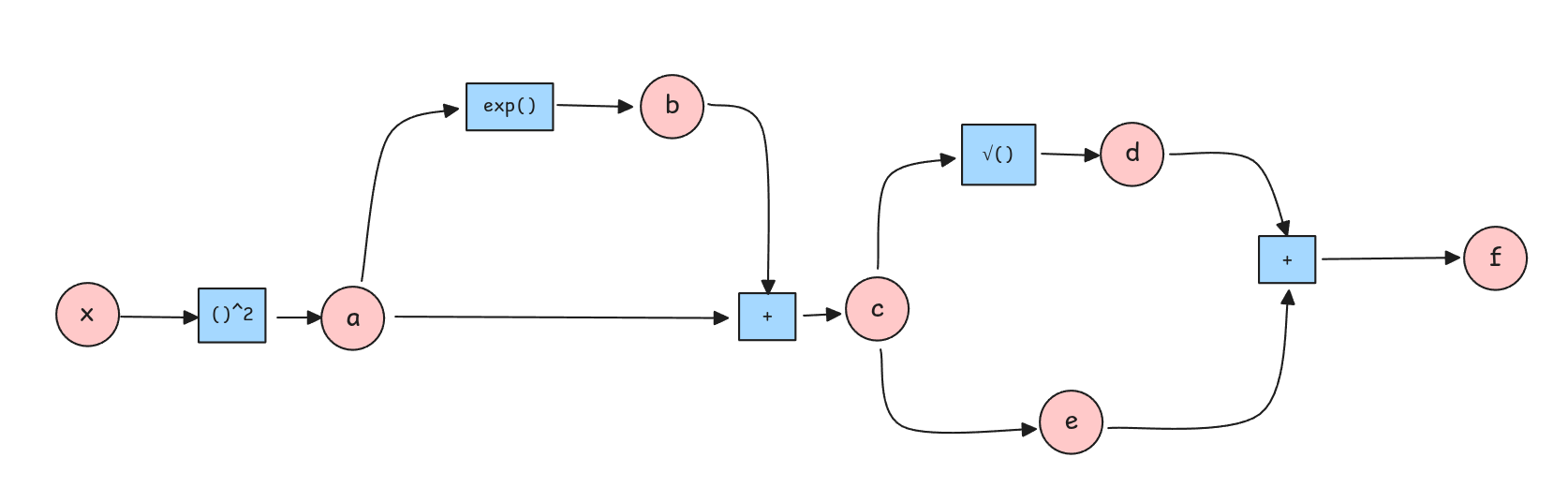
Podemos reescribir la función \(f\) como una secuencia de operaciones elementales y asignar variables intermedias:
- \(a = x^2\)
- \(b = exp(a)\)
- \(c = a + b\)
- \(d = \sqrt{c}\)
- \(e = Cos(c)\)
- \(f = d + e\)
La idea es que el camino entre dos nodos rojos son una derivada entre ambos nodos. Es decir, el camino entre \(f\) y \(d\) es \(\frac{\partial f}{\partial d}\).
Las derivadas se van acumulando y deben considerar todos los caminos. Por ejemplo, para calcular \(\frac{\partial f}{\partial c}\), debemos considerar los caminos \(f \to d \to c\) y \(f \to e \to c\).
Todas las variables definidas permiten calcular sus derivadas respecto a su input.
Si comenzamos a derivar de atrás hacia adelante podemos reutilizar cálculos anteriores.
Automatic Differentiation: Ejemplo
\[\frac{\partial f}{\partial d} = \frac{\partial f}{\partial e} = 1\] \[\frac{\partial f}{\partial c} = \frac{\partial f}{\partial d} \cdot \frac{\partial d}{\partial c} + \frac{\partial f}{\partial e} \cdot \frac{\partial e}{\partial c} = 1 \cdot 0.259 + 1 \cdot 0.545 = 0.8045\] \[
\begin{align}
\frac{\partial f}{\partial b} &= \frac{\partial f}{\partial d} \cdot \frac{\partial d}{\partial c} \cdot \frac{\partial c}{\partial b} + \frac{\partial f}{\partial e} \cdot \frac{\partial e}{\partial c} \cdot \frac{\partial c}{\partial b} \\
&= \frac{\partial f}{\partial c} \cdot \frac{\partial c}{\partial b} = 0.8045 \cdot 1 = 0.8045
\end{align}
\]
Notar que \(\frac{\partial f}{\partial c}\) ya la habíamos calculado.
\[\frac{\partial f}{\partial a} = \frac{\partial f}{\partial b} \cdot \frac{\partial b}{\partial a} + \frac{\partial f}{\partial c} \cdot \frac{\partial c}{\partial a} = 0.8045 \cdot 2.7183 + 0.8045 \cdot 1 = 2.9913\]
\[\frac{\partial f}{\partial x} = \frac{\partial f}{\partial a} \cdot \frac{\partial a}{\partial x} = 2.9913 \cdot 2 = 5.983\]
Si \(x = 1\), entonces:
\(a = x^2 = 1\)
\(b = exp(a) = 2.7183\)
\(c = a + b = 3.7183\)
\(d = \sqrt{c} = 1.9283\)
\(e = Cos(c) = -0.8383\)
\(f = d + e = 1.09\)
\(\frac{\partial d}{\partial c} = \frac{1}{2\sqrt{c}} = 0.259\)
\(\frac{\partial e}{\partial c} = -sen(c) = 0.545\)
\(\frac{\partial c}{\partial b} = 1\)
\(\frac{\partial b}{\partial a} = exp(a) = 2.7183\)
\(\frac{\partial a}{\partial x} = 2x = 2\)