ML-CLI
El problema
Normalmente cuando se intenta resolver un problema complejo de Machine Learning el proceso de Experimentación termina siendo tan engorroso y desordenado que uno perdiendo el hilo de qué cosas probó y qué cosas no. Obviamente existen aplicaciones como MlFlow, Neptune y Weights & Biases que permiten generar un proceso ordenado de almacenamiento de los resultados de la Experimentación, pero en mi opinión no permite ordenar la Experimentación misma.
Haciendo esta página en Jekyll, noté que el proceso de modularización ayuda bastante a mantenerse ordenado. Normalmente los Científicos de Datos no tenemos un background de diseño de Software y tener buenas prácticas en esta área son muchas veces muy necesarias al momento de embarcarse en un proyecto de Machine Learning.
Finalmente, descubrí Typer, una librería extremadamente fácil de usar y que permite crear CLI bonitas, eficientes y muy poderosas. Por lo que dije:
creo que podría ser una buena idea el poder crear un CLI, que permita revisar de manera sencilla el proceso d Experimentación que de cierta manera me fuerce a seguir las buenas prácticas del diseño de Software.
Esto todavía es un Trabajo en Desarrollo, probablemente iré agregando o quitando Features de lo que ya llevo
Un proyecto de Machine Learning
Un proyecto de Machine Lerning podría contener, sin estar limitado a, lo siguiente:
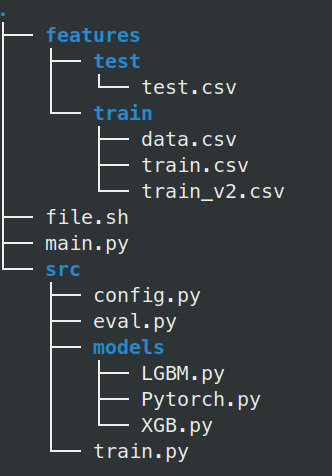
En este caso cuento con 2 carpetas principales, features y src. features corresponde a un set de datos trabajados que se encuentran listos para modelar. Como se puede apreciar éste ya está dividido en datos de train y de test. Normalmente en el train voy a contar con distintas versiones utilizando distintas transformaciones, selección de variables o feature engineering.
Por otra parte src contendrá todos los códigos que voy a utilizar para los distintos modelos: Actualmente tengo train.py que genera un entrenamiento genérico, y una subcarpeta models el cual dispondrá de código específico para cada uno de los distintos tipos de modelos. Esto es importante ya que las API de un modelo de Scikit-Learn, XGBoost, LightGBM o Pytorch pueden llegar a diferir sustancialmente.
Adicionalmente tendré eval.py con todo el proceso de Inferencia, y un config.py para poder definir hiperparámetros específicos de cada modelo cuando estoy en el proceso de Experimentación.
Actualmente tengo que pensar en la forma en la que voy a combinar todo esto con algún logger como podría ser Weights & Biases. (WIP)
Finalmente cuento con dos archivos: file.sh es un Bash que me permite agendar varios entrenamientos. Actualmente pienso en dedicar mucho tiempo a sólo desarrollar Scripts de modelos y luego dejarlos entrenando en la Noche con un file.sh que se encargue de correr todo, loguear, y luego apagar el PC (que podría ser J.A.R.V.I.S).
Para terminar está main.py, pero este main es distinto. Va a ser un orquestador de todo el proceso, pero en este caso decidí que fuera un CLI de Typer.
Funcionamiento
Typer permite crear un CLI que entregará ayuda de cómo ingresar los datos, además de pretty formatting que hace una interfaz más user-friendly. Además Typer genera una validación en el cual se permiten sólo valores válidos
.
Actualmente he implementado las siguientes funcionalidades:
check-train y check-test
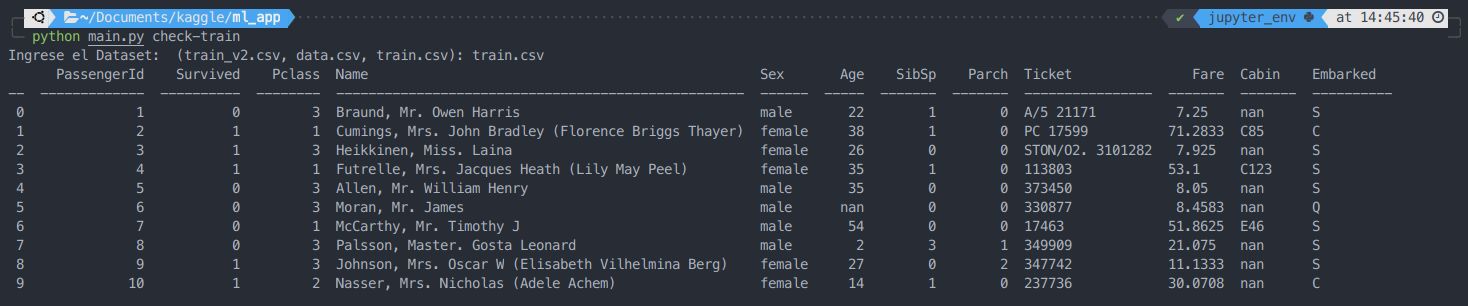
python main.py check-train
Generará un prompt interactivo para llenar el nombre de algún dataset contenido en features/train. En caso que se ingrese un valor que no es parte de los archivos generados entregará un error indicando que no es una opción válida y solicitará un nuevo valor desde la lista:
python main.py check-train
Choose a Dataset: (train_v2.csv, data.csv, train.csv): train
Error: invalid choice: train. (choose from train_v2.csv, data.csv, train.csv)
Ingrese el Dataset: (train_v2.csv, data.csv, train.csv):
En caso contrario, se entregará un output como sigue:
Análogamente está definida la opción check-test el cuál permitirá visualizar datasets contenidos en la carpeta features/test.
sch-train
Esta funcionalidad permite calendarizar (añadir a la cola) un proceso de entrenamiento para algún modelo contenido en src/models utilizando algún Dataset de entrenamiento disponible en features/train. En este caso también se obtiene validación de las opciones a ingresar:
Usage: main.py sch-train [OPTIONS] MODEL:[XGB|LGBM|Pytorch]
DATA:[train_v2.csv|data.csv|train.csv]
Arguments:
MODEL:[XGB|LGBM|Pytorch] [required]
DATA:[train_v2.csv|data.csv|train.csv] [required]
Options:
-r [default: False]
-v [default: False]
--help Show this message and exit.
Actualmente esta funcionalidad posee los argumentos MODEL (con opciones de todos los nombres de Scripts agregados a src/models) y DATA (con opciones de todos los dataset de entrenamiento agregados a features/train) y permite agregar un nuevo proceso de entrenamiento a los ya existentes.
Además posee dos flags: -r es por reset, eliminará los procesos existentes y -v por view que permitirá visualizar el archivo file.sh (por ahora por medio de nano).
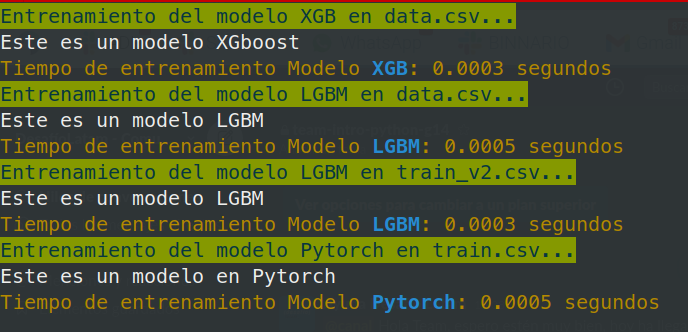
python main.py sch-train LGBM train_v2.csv -v
python src/train.py XGB data.csv
python src/train.py LGBM data.csv
python src/train.py LGBM train_v2.csv
python src/train.py Pytorch train.csv
python src/train.py LGBM train_v2.csv
python src/train.py LGBM train_v2.csv # valor añadido
train
Esta funcionalidad permitirá entonces poner en entrenamiento el proyecto.
python main.py train
Usage: main.py train [OPTIONS]
Options:
-hp [default: False]
-m [XGB|LGBM|Pytorch]
-d [train_v2.csv|data.csv|train.csv]
[default: train.csv]
--help Show this message and exit.
Actualmente si el procedimiento se lanza sin opciones éste ejecutará el file.sh con todos los modelos encolados.
Estoy pensando en agregar una opción para apagar el computador una vez finalizado. WIP
Esta funcionalidad posee 3 flags: -hp el cual permitirá un entrenamiento utilizando Hyperparameter tuning (WIP), -m y -d son opciones que trabajan en conjunto y permite entrenar u un modelo en un dataset específico. Cada uno de estas opciones tiene sus respectivos validadores.
TODO
Actualmente es un proyecto en desarrollo que salió como una idea al utilizar mucho jekyll. Me encantaría que esto pudiera transformarse en una librería de Python y que pudiera ser de mucha utilidad para Data Scientist luchando con el desorden y el caos del desarrollo de un modelo Predictivo. He decidido no compartir código por el momento, pero sí se aceptan sugerencias de funcionalidades que sería interesante incluir.