Creando un Framework de Experimentación
Como abordar una Competencia de ML

Estamos cerca de Navidad, así que me gustaría hacer un regalo mostrando cómo es que yo enfrento la resolución de un problema de Machine Learning. . Esto no es un proceso exhaustivo, y probablemente hay muchas otras manera de hacerlo, pero esta es mi experiencia (con muy poco tiempo) en una competencia. Para ejemplificar esto, voy a utilizar la data del reciente concurso organizado por BCI y Binnario. La verdad es que no me fue tan bien, saqué el puesto 22 no más. Y quiero mostrar cómo utilizando un par de scripts y sin hacer mucho (porque de verdad no tenía tiempo), se logró un puntaje decente.
En verdad creo que si hubiera dedicado suficiente tiempo a probar algo más podría haber logrado mejores puntajes. Pero el tiempo y la época del año no me dio.
No es mi intención quitar créditos ni desviar la atención de los ganadores de esta versión del concurso, sino que mostrar cómo se puede crear una metodología de trabajo para modelar y que pueda ser reutilizable en el futuro.
El concurso
En este caso, se presentaba un problema de Regresión, en el cual se solicitaba predecir las ventas de un cliente, o algo así. Lo importante de esto es poder entender que el target a predecir era un valor continuo. La ventaja de este concurso es que te entregaba un dataset plug & play, pero con un gran inconveniente: Tenía demasiados nulos. La verdad es que me puse a probar varios métodos de imputación avanzados: MICE, Datawig, IterativeImputer, KNN, y otros más, pero me cansé, tenía que dejar el computador corriendo demasiado tiempo y esta vez, no contaba con ese tiempo.
A continuación les presento mi propuesta con el que se lograba un puntaje no terrible y en que el entrenamiento toma muy poco tiempo.
Mi propuesta tiene casi nada de Preprocesamiento, cero feature engineering y nada de afinamiento de hiperparámetros. Tiene un par de truquillos eso sí… Esto me tomó alrededor de 1 hora en programar y 10-20 minutos máximo en entrenar y enviar la submisión.
Primero que todo la data:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pd.options.display.max_rows = 100
train_df = pd.read_csv('./data/train_data.csv').set_index('id')
test_df = pd.read_csv('./data/test_data.csv').set_index('id')
train_df['periodo_mes'] = pd.to_datetime(train_df.mes.astype('str') + '01').dt.to_period('M')
test_df['periodo_mes'] = pd.to_datetime(test_df.mes.astype('str') + '01').dt.to_period('M')
train_df['year'] = train_df.periodo_mes.dt.year
train_df['month'] = train_df.periodo_mes.dt.month
test_df['year'] = test_df.periodo_mes.dt.year
test_df['month'] = test_df.periodo_mes.dt.month
print(f'Train Set con {train_df.shape[0]} filas y {train_df.shape[1]} columnas')
print(f'Test Set con {test_df.shape[0]} filas y {test_df.shape[1]} columnas')
Train Set con 667691 filas y 72 columnas
Test Set con 292016 filas y 71 columnas
Al momento de importar cree también algunas columnas extras.
- periodo_mes: Es una variable que contiene un periodo mensual (mes-año). La utilizo sólo para que los gráficos queden sin espacios que alteran la visualización.
- year: Año extraído. Parece que en el modelo final no la utilizo. Aunque podría haberlo hecho.
- month: Mes Extraído. Igual que arriba.
EDA
Vamos a revisar qué tiene la data. La verdad es que dediqué muy poquito tiempo a revisar la data. Este paso es importante, pero para mi gusto es bien latero, entonces no le dediqué mucho tiempo. Eso también me llevó a una solución bien simplificada:
train_df.target_mes.agg({np.min, np.max})
amin 0.00
amax 69430.19
Name: target_mes, dtype: float64
Se puede ver que la data tiene una distribución bien asimétrica:
train_df.target_mes.plot(kind = 'hist', bins = 100, figsize = (10,8))
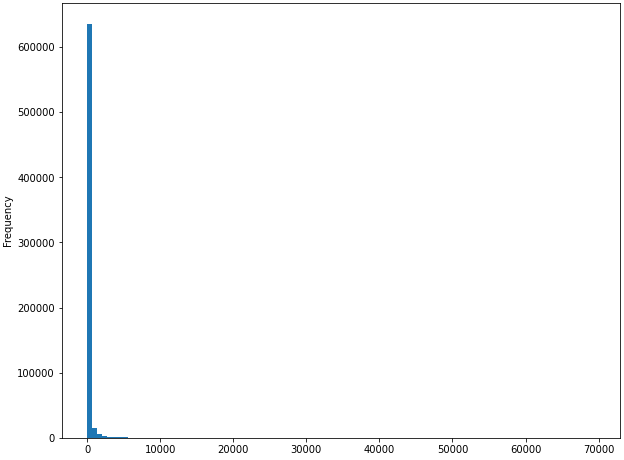
La verdad es que una estrategia que se puede hacer para no tener una distribución tan asimétrica es utilizar el Log para convertir la variable objetivo (pero me dió lata hacerlo, así que para la próxima).
Como se puede ver a continuación, es muy probable que el target seguía una distribución media log-normal:
plt.figure(figsize=(10,8))
plt.hist(np.log1p(train_df.target_mes))
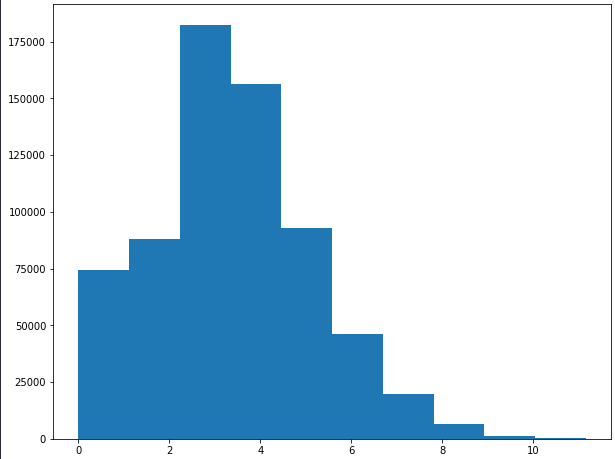
Además notamos que las variables tenían los siguientes tipos de datos:
train_df.dtypes
mes int64
tipo_ban object
tipo_seg object
categoria object
tipo_com object
tipo_cat object
tipo_cli object
VAR1_sum float64
VAR1_prom float64
VAR1_trx float64
VAR2_sum float64
VAR2_prom float64
VAR2_trx float64
VAR3_sum float64
VAR3_prom float64
VAR3_trx float64
VAR4_sum float64
VAR4_prom float64
VAR4_trx float64
VAR5_sum float64
VAR5_prom float64
VAR5_trx float64
VAR6_sum float64
VAR6_prom float64
VAR6_trx float64
VAR7_sum float64
VAR7_prom float64
VAR7_trx float64
VAR8_sum float64
VAR8_prom float64
VAR8_trx float64
VAR9_sum float64
VAR9_prom float64
VAR9_trx float64
VAR10_sum float64
VAR11_sum float64
VAR12_sum float64
VAR13_sum float64
VAR14_sum float64
VAR15_sum float64
VAR16_sum float64
VAR17_sum float64
VAR18_sum float64
VAR19_sum float64
VAR20_sum float64
VAR21_sum float64
VAR22_sum float64
VAR23_sum float64
VAR23_prom float64
VAR23_trx float64
VAR24_sum float64
VAR24_prom float64
VAR24_trx float64
VAR25_sum float64
VAR25_prom float64
VAR25_trx float64
VAR26_sum float64
VAR26_prom float64
VAR26_trx float64
VAR27_sum float64
VAR27_prom float64
VAR27_trx float64
VAR28_sum float64
VAR28_prom float64
VAR28_trx float64
VAR29_prom float64
VAR29_ratio float64
VAR30_sum float64
target_mes float64
periodo_mes period[M]
year int64
month int64
dtype: object
Además, es posible ver que de todas las variables entregadas, hay 6 que son categóricas y el resto todas numéricas y todas están anonimizadas. Por lo tanto eso entrega un grado de complejidad adicional.
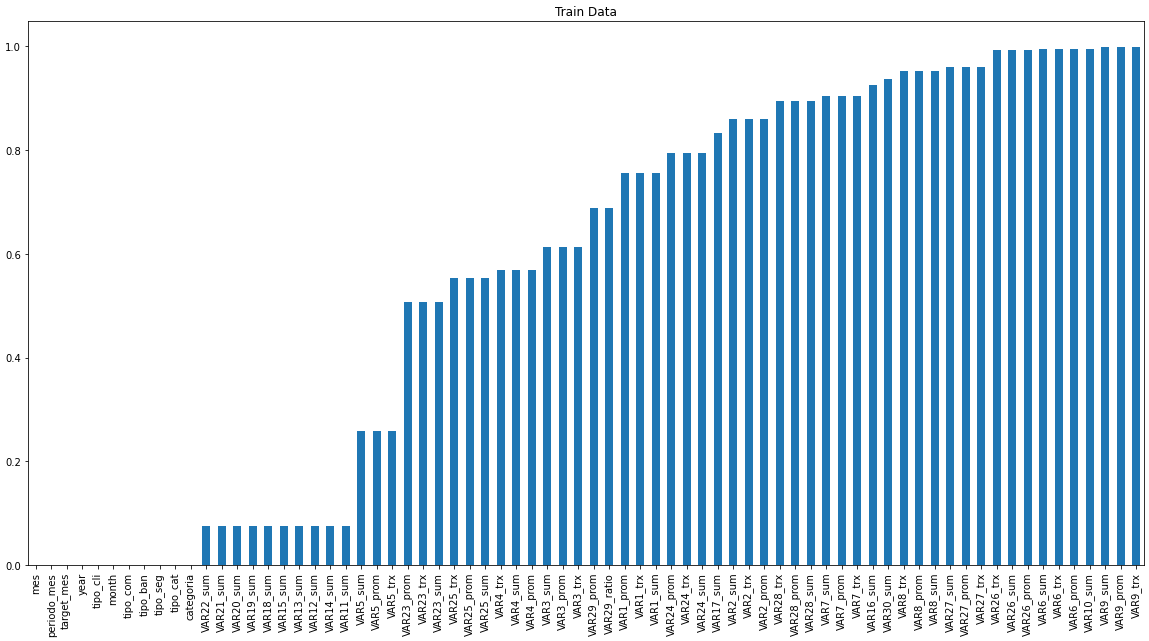
Finalmente, creo que el gran insight de este problema es que hay MUCHOS nulos:
def check_nulls(df, name):
data = (df.isnull().sum()/len(df)).sort_values()
data.plot(kind='bar', figsize = (20,10), title = name)
check_nulls(train_df, 'Train Data')
check_nulls(test_df, 'Test Data')
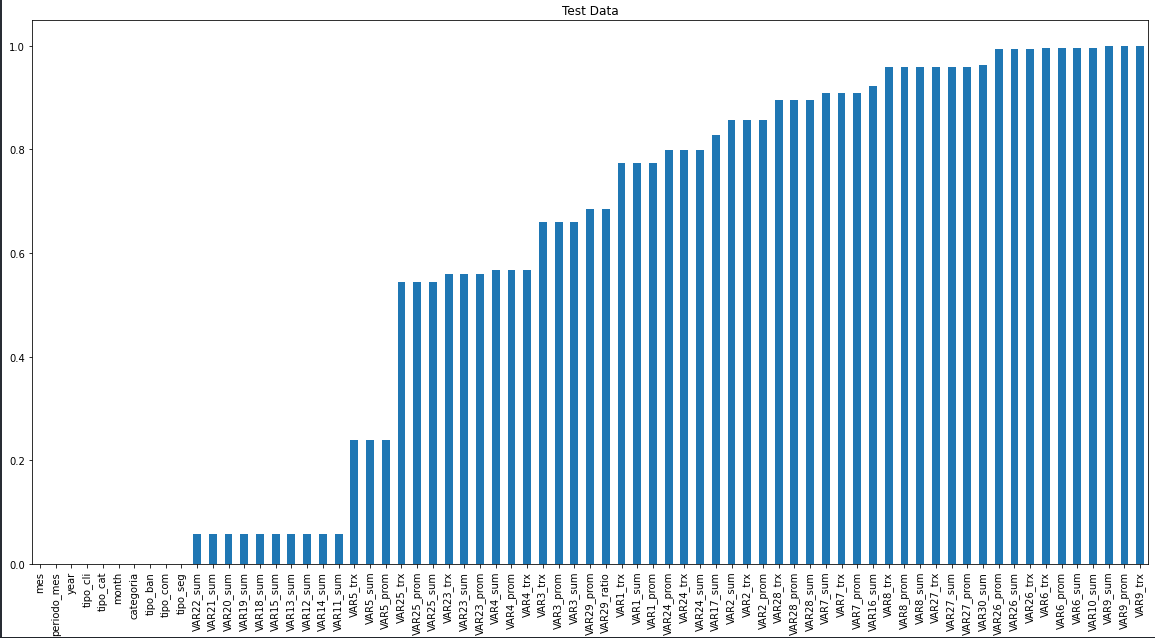
Además otra cosa extraña que había, es que en el split entregado al parecer la mayoría de los elementos a predecir estaban en el periodo Mayo en adelante del 2021. (Azul: Train, Naranja: Test)
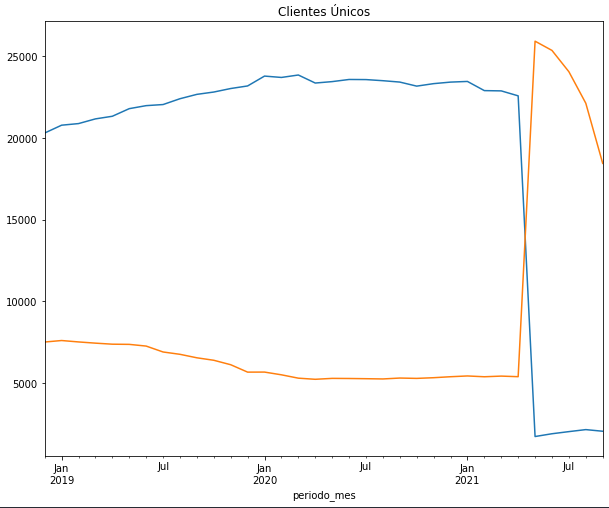
En mi opinión, ver esto me dio a entender que no era un problema tan difícil, que además la distribución del Train y el Test Set era similar. Pero que los datos de entrenamientos que están permiten aprender más de ciertos meses que de otros.
Además creo que la gran dificultad de este problema es cómo lidiar con los nulos.
Mi approach
Bueno, como viene siendo costumbre, generé varios scripts para ir descomponiendo las distintas etapas. A continuación el detalle del esquema de archivos que utilicé:

create_folds.py
Este archivo se encarga de crear el set de Validación. En mi caso particular utilicé un esquema para validar de 5-Folds. Muchos dirán, pero Scikit-Learn tiene la capacidad de usar CV con GridSearchCV o usando cross_val_score o cross_validate de manera mucho más sencilla. El problema de este tipo de estrategias es que son completamente compatibles con Estimadores de Scikit-Learn, pero impiden utilizar funcionalidades más avanzadas de otras librerías como lo es el Early Stopping.
import pandas as pd
import hydra
from omegaconf import DictConfig
from hydra.utils import to_absolute_path
from sklearn.model_selection import KFold
@hydra.main(config_path='conf', config_name='config')
def create_folds(cfg: DictConfig):
df = pd.read_csv(to_absolute_path('input/train_data.csv'))
df['kfold'] = -1
kf = KFold(n_splits=5, shuffle = True, random_state=123)
for fold , (train_idx, val_idx) in enumerate(kf.split(X = df, y = df.target_mes)):
df.loc[val_idx, 'kfold'] = fold
df.to_csv(to_absolute_path('input/train_folds.csv'), index=False)
if __name__ == '__main__':
create_folds()
create_folds.py entonces creará una columna que contendrá para cada registro a qué Fold de validación pertenecerá. Bajo esta lógica se asume que todo lo que no esté en el Fold de Validación debe usarse para entrenar. Y esto se repite para cada Fold. Si no queda claro como funciona de manera interna el K-Fold pueden mirar el siguiente link.
Finalmente este Script tiene por objetivo generar un archivo .csv con toda la data incluyendo los splits de Validación, permitiendo que todos los modelos se entrenen con el mismo esquema de validación y que los Folds se guarden en un archivo y no en memoria. La ventaja de esto que es que los modelos no se ejecutan en memoria permitiendo el entrenamiento de modelos más pesados sin que la memoria RAM o la GPU reclamen tan seguido.
train.py
Este será el script encargado de entrenar los modelos. El objetivo de este script es encontrar un proceso de entrenamiento común que pueda ser útil para distintos modelos.
from timeit import default_timer as timer
import hydra
import numpy as np
import pandas as pd
from hydra.utils import to_absolute_path
from omegaconf import DictConfig
from sklearn.metrics import mean_absolute_error
from src.dispatcher import *
import logging
import joblib
from box import Box
log = logging.getLogger("Training")
@hydra.main(config_path='conf',config_name='config')
def train(cfg: DictConfig):
df = pd.read_csv(to_absolute_path(cfg.training_data))
cat_vars = ['tipo_ban','tipo_seg','categoria','tipo_com','tipo_cat','tipo_cli']
df[cat_vars] = df[cat_vars].astype('category')
score = []
val_df = pd.DataFrame()
for fold in range(cfg.n_splits):
id_val = df.query('kfold == @fold')[['id','mes','kfold']]
log.info(f'Training for Fold {fold}')
X = Box({})
y = Box({})
X.train = df.query('kfold != @fold').drop(columns = ['id','mes','kfold','target_mes'])
X.val = df.query('kfold == @fold')[X.train.columns]
y.train = df.query('kfold != @fold').target_mes
y.val = df.query('kfold == @fold').target_mes
pipe, preds = hydra.utils.call(cfg.model.algo, X = X, y = y)
val_score = mean_absolute_error(y.val, preds)
score.append(val_score)
log.info(f'Exporting Results for Fold {fold}...')
joblib.dump(pipe, to_absolute_path(f'models/{cfg.model_name}_fold_{fold}.joblib'))
joblib.dump(X.train.columns, to_absolute_path(f'models/{cfg.model_name}_fold_{fold}_columns.joblib'))
id_val[f'{cfg.model_name}_pred'] = preds
val_df = val_df.append(id_val)
log.info(f'MAE for Fold {fold}: {val_score}')
val_df.to_csv(to_absolute_path(f'preds/{cfg.model_name}_preds.csv'), index=False)
log.info(f'Mean Score {np.mean(score)}')
if __name__ == '__main__':
tic = timer()
train()
toc = timer()
print(f'Training Time: {(toc- tic)/60} minutes')
Vamos descomponiendo el Script por partes:
- Imports varios.
logginges una manera de generar logs que queden almacenados en los .log que genera Hydra.joblibserá utilizado para serializar los modelos.Boxes un Diccionario más bkn en Python, que en vez de llamar de la formaKey['value'], permite utilizar simplementeKey.value(Una maña mía, me gusta la notación de punto, me ahorro tecleos.).Fuera del boilerplate mínimo de Hydra, el cuál pueden aprender acá.
Se importa la data con los folds y además se define qué variables son categóricas. Esto es necesario debido a que algunos de los modelos que usaremos tienen tratamiento automático de categorías (como CatBoost).
- Se valida el modelo usando una estrategia de 5-Fold Cross Validation. Si bien se ve un poco largo, no lo es tanto:
- Se definen con qué Folds se entrena y con cual se valida.
- Se entrena el modelo.
- Se mide la performance del Modelo, el cual por reglamento se mide con el Mean Absolute Error (MAE).
- Se guarda todo el proceso de entrenamiento, es decir, se guarda el modelo entrenado en los (k-1) Folds y las columnas utilizadas en ese modelo. Esto se realiza para evitar que hayan columnas que no se utilizaron al momento de entrenar.
Finalmente, las líneas finales exportan las predicciones del modelo, las cuales fueron almacenadas por Fold. Estas predicciones podrían utilizarse más tarde para un Stacking, el cuál por tiempo no implementé.
dispatcher.py
Este Script es el encargado de generar los modelos y sus preprocesamientos.
from catboost import CatBoostRegressor
from feature_engine.encoding import OneHotEncoder, OrdinalEncoder, MeanEncoder
from feature_engine.imputation import (AddMissingIndicator,
ArbitraryNumberImputer)
from feature_engine.wrappers import SklearnTransformerWrapper
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
import lightgbm as lgb
scaler = SklearnTransformerWrapper(StandardScaler())
def xgb_v1(X, y):
model = xgb.XGBRegressor(n_estimators=1500,
objective='reg:squarederror',
tree_method="gpu_hist",
verbosity = 2,
enable_categorical = True,
random_state = 123
)
model.fit(X.train, y.train,
early_stopping_rounds=50,
eval_metric='mae',
eval_set=[(X.val, y.val)])
preds = model.predict(X.val)
return model, preds
def xgb_v2(X, y):
prep = Pipeline(steps = [
('ord', OrdinalEncoder(encoding_method='ordered')),
('mi', AddMissingIndicator()),
('imp', ArbitraryNumberImputer(arbitrary_number = 0))
])
prep.fit(X.train, y.train)
X_val = prep.transform(X.val)
model = xgb.XGBRegressor(n_estimators=1500,
objective='reg:squarederror',
tree_method="gpu_hist",
verbosity = 2,
enable_categorical = True,
random_state = 123
)
pipe = Pipeline(steps = [
('prep', prep),
('model',model)
])
pipe.fit(X.train, y.train,
model__early_stopping_rounds=150,
model__eval_metric='mae',
model__eval_set=[(X_val, y.val)])
preds = pipe.predict(X.val)
return pipe, preds
def lgb_v1(X, y, cat_vars):
prep = Pipeline(steps = [
('ord', OrdinalEncoder(encoding_method='ordered')),
('mi', AddMissingIndicator()),
('imp', ArbitraryNumberImputer(arbitrary_number = 0))
])
prep.fit(X.train, y.train)
X_val = prep.transform(X.val)
model = lgb.LGBMRegressor(n_estimators=1000, device="gpu")
pipe = Pipeline(steps = [
('prep', prep),
('model',model)
])
pipe.fit(X.train, y.train,
model__categorical_feature = cat_vars,
model__eval_metric='mae',
model__eval_set=[(X_val, y.val)],
model__callbacks = [lgb.early_stopping(stopping_rounds=50)])
preds = pipe.predict(X.val)
return pipe, preds
def cb_v1(X, y, cat_vars):
prep = Pipeline(steps = [
('ohe', OneHotEncoder()),
('mi', AddMissingIndicator()),
('imp', ArbitraryNumberImputer(arbitrary_number = 0)),
('sc', scaler),])
prep.fit(X.train, y.train)
X_val = prep.transform(X.val)
model = CatBoostRegressor(iterations=1500,
learning_rate=0.9,
loss_function='MAE',
random_seed = 123,
task_type="GPU",
devices='0:1')
pipe = Pipeline(steps = [
('prep', prep),
('model', model)
])
pipe.fit(X.train, y.train,
model__eval_set = (X_val, y.val),
#model__cat_features = cat_vars,
model__early_stopping_rounds = 150)
preds = pipe.predict(X.val)
return pipe, preds
def cb_v2(X, y, cat_vars):
prep = Pipeline(steps = [
('ohe', MeanEncoder()),
('mi', AddMissingIndicator()),
#('imp', ArbitraryNumberImputer(arbitrary_number = 0)),
('sc', scaler),])
prep.fit(X.train, y.train)
X_val = prep.transform(X.val)
model = CatBoostRegressor(iterations=1500,
learning_rate=0.9,
loss_function='MAE',
random_seed = 123,
task_type="GPU",
devices='0:1')
pipe = Pipeline(steps = [
('prep', prep),
('model', model)
])
pipe.fit(X.train, y.train,
model__eval_set = (X_val, y.val),
#model__cat_features = cat_vars,
model__early_stopping_rounds = 300)
preds = pipe.predict(X.val)
return pipe, preds
El dispatcher.py basicamente tiene 5 modelos que fueron entrenados:
- xgb_v1: XGBoost entrenado con 1500 estimadores. Automáticamente trata variables categóricas con
dtype=categorye imputa valores perdidos automáticamente. Tiene un early stopping de 50 rondas. - xgb_v2: XGBoost entrenado con 1500 estimadores en el cual se crea un Ordinal Encoding para las variables categóricas, se crea un Missing Indicator para los nulos de las variables numéricas y se Imputan los nulos con un Cero. Tiene un early stopping de 150 rondas.
- lgb_v1: Un LightGBM con 1000 estimadores, Early Stopping de 50 rondas y el mismo preprocesamiento que xgb_v2.
- cb_v1: Catboost con el mismo preprocesamiento pero usando OneHotEncoder para variables categóricas. 150 rondas de early stopping. Este fue el modelo que por sí solo dio los mejores resultados.
- cb_v2: Catboost con el mismo preprocesamiento pero usando MeanEncoder para variables categóricas, Scaler para ver si tiene algún efecto y la imputación automática de Catboost. 150 rondas de early stopping.
Cabe destacar que:
- XGBoost y LightGBM usan como Loss Function el MSE (L2), mientras que Catboost permite optimizar directamente el MAE (L1).
- Todos los early stopping se hicieron monitoreando el MAE.
- Todos los modelos se entrenaron en GPU.
- Cada modelo se entrena en cerca de 1 minuto (GPU), 4 mins app en (CPU).
inference.py
Es el encargado de crear las predicciones y el archivo de envío de la competencia.
import pandas as pd
import hydra
from omegaconf import DictConfig
from hydra.utils import to_absolute_path
import joblib
@hydra.main(config_path='conf', config_name='config')
def predict(cfg: DictConfig):
df_test = pd.read_csv(to_absolute_path(cfg.test_data))
cat_vars = ['tipo_ban','tipo_seg','categoria','tipo_com','tipo_cat','tipo_cli']
df_test[cat_vars] = df_test[cat_vars].astype('category')
id = df_test[['id','mes']]
preds_dict = {}
for fold in range(cfg.n_splits):
pipe = joblib.load(to_absolute_path(f'models/{cfg.model_name}_fold_{fold}.joblib'))
columns = joblib.load(to_absolute_path(f'models/{cfg.model_name}_fold_{fold}_columns.joblib'))
df_test = df_test[columns]
preds = pipe.predict(df_test)
preds_dict[fold] = preds
final_preds = pd.DataFrame(preds_dict).mean(axis = 1)
if cfg.clip:
final_preds.where(final_preds > 0, 0)
pd.concat([id, final_preds],axis = 1).to_csv(to_absolute_path(f'submissions/{cfg.model_name}.csv'), index = False)
if __name__ == '__main__':
predict()
Básicamente este script hace lo siguiente:
- Importa la data de Test. Se convierte las variables categóricas en tipo
categoryy separa elidy elmesque es parte del formato de predicción. - Se genera una predicción en tipo K-Fold. Es decir, cada modelo entrenado con 4 partes de la data predice sobre toda la data. Y luego la predicción del modelo se da como el promedio de los Folds.
- Luego, aplico un truquito. Debido a que la data sólo puede puede tener ventas mayores o iguales a cero, con esta parte me aseguro que sea así. Y en el caso de que haya valores negativos, automáticamente los transformo en ceros. (Increíblemente este truquito disminuyó unos puntitos del MAE).
- Se genera el archivo
.csva enviar.
blending.py
Los modelos resultaron dispares, Catboost entregó resultados de MAE ~95-96, pero todo el resto dio sobre 100. Lo cual no es muy bueno. Por lo tanto, decidí aplicar un ensamble muy sencillo llamado Blending. Básicamente consiste en promediar las predicciones de cada modelo y ver si mejoró.
import pandas as pd
import glob
files = glob.glob('submissions/*.csv')
df_test = pd.read_csv("input/test_data.csv")
preds_test = df_test[['id','mes']]
for f in files:
data = pd.read_csv(f)
preds_test = preds_test.merge(data, on = ['id','mes'], how = 'left')
id = preds_test[['id','mes']]
preds = preds_test.drop(columns = ['id','mes']).mean(axis = 1)
sub = pd.concat([id, preds], axis = 1)
sub.columns = ['id','mes','target_mes']
sub.to_csv('submissions/blending.csv', index = False)
Básicamente este script transforma todas las predicciones en sólo un DataFrame y promedia las predicciones, lo cual llevó al mejor resultado que logré: 94.4992 en el ranking público y 96.5098 en el ranking privado.
Los archivos de configuración para estos Scripts son los siguientes:
training_data: input/train_folds.csv
test_data: input/test_data.csv
n_splits: 5
clip: true
model_name: ${model.model_name}
model_name: cb_v1
algo:
_target_: src.train.cb_v1
cat_vars: ['tipo_ban','tipo_seg','categoria','tipo_com','tipo_cat','tipo_cli']
model_name: cb_v2
algo:
_target_: src.train.cb_v2
cat_vars: ['tipo_ban','tipo_seg','categoria','tipo_com','tipo_cat','tipo_cli']
model_name: lgb_v1
algo:
_target_: src.train.lgb_v1
cat_vars: ['tipo_ban','tipo_seg','categoria','tipo_com','tipo_cat','tipo_cli']
model_name: xgb_v1
algo:
_target_: src.train.xgb_v1
model_name: xgb_v2
algo:
_target_: src.train.xgb_v2
Ejecución
Siguiendo sólo estos procedimientos claramente no se va a ganar una competencia. Pero es un buen punto de partida. De hecho, mucho de este código puede quedar como un framework establecido para hacer tus pruebas en el futuro.
Todo el código funcional quedará en mi Github y pueden utilizarlo para los fines que estimen convenientes.
Pueden entrenar los modelos en el repo de la siguiente manera:
python -m src.train -m +model=xgb_v1,xgb_v2,lgb_v1,cb_v1,cb_v2
Para enviar la submissión basta con usar:
python -m src.inference -m +model=xgb_v1,xgb_v2,lgb_v1,cb_v1,cb_v2
y para ejecutar el blending:
python -m src.blending
- NOTA: El primer -m es el flag para ejecutar scripts como módulos. El segundo -m es el flag de Hydra para ejecutar un multirun.
Dejas corriendo tus scripts y en 10-20 mins más tienes tu predicción.
Siguientes Pasos
Para mejorar es necesario invertir tiempo en el modelo y abarcar los siguientes puntos:
- Más Modelos
- Feature Engineering: Normalmente, encontrar una variable combinando conocimiento del negocio es lo que más va a aportar. Posiblemente es la parte más trabajosa del proceso.
- Preprocesamiento: En este caso probablemente un buena manera de imputar podría haber aportado mucho más. Yo sólo usé las imputaciones built-in en cada modelo y una imputación burda por cero.
- Afinamiento de Hiperparámetros: Probablemente jugar con Hiperparámetros permitiría exprimir un poquito más de rendimiento de los modelos.
Espero que les haya gustado y a los que no se atreven a entrar a una competencia se atrevan a hacerlo la próxima vez. La única consecuencia de entrar a una competencia es salir sabiendo más que cuando entraron.