Utilizar el Tidyverse para imputar NAs en una tabla.
Imputar valores Perdidos
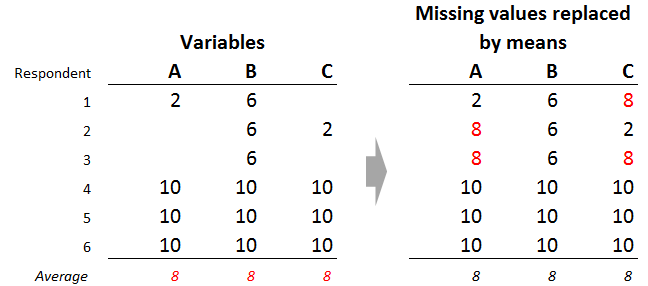
Navegando a través de stackoverflow me encontré un problema que encontré interesante de resolver. EL problema utilizaba la siguiente data:
El problema
sample <-
structure(
list(
`Country Name` = c(
"Aruba","Afghanistan","Angola","Albania","Andorra","Arab World","United Arab Emirates",
"Argentina","Armenia","American Samoa","Antigua and Barbuda","Australia"
),
`Country Code` = c(
"ABW","AFG","AGO","ALB","AND","ARB","ARE","ARG","ARM","ASM","ATG","AUS"),
`2007` = c(
5.39162036843645,8.68057078513406,12.2514974459487,2.93268248162318,NA,4.74356585295154,
NA,NA,NA,NA,1.41605259409743,NA),
`2008` = c(
8.95722105296535,26.4186641547444,12.4758291326398,3.36313757366391,NA,NA,12.2504202448139,
NA,8.94995335353386, NA, 5.33380639820232, NA),
`2009` = c(
-2.13630037272305,-6.81116108898995,13.7302839288409,2.23139683475865,NA,2.92089711805365,
1.55980098148558,NA,3.40676682683799,NA,-0.550159995508869,NA),
`2010` = c(
2.07773902027782,2.1785375238942,14.4696564932574,3.61538461538463,NA,3.91106195534027,
0.879216764156813,NA,8.17636138473956,NA,3.3700254022015,2.91834002677376),
`2011` = c(
4.31633194082721,11.8041858089129,13.4824679218511,3.44283593170005,NA,4.75316388885632,
NA,NA,7.6500080785929,NA,3.45674967234599,3.30385015608744),
`2012` = c(
0.627927921638161,6.44121280934118,10.2779049218839,2.03642235579081,NA,4.61184432206646,
0.662268900269082,NA,2.55802007757907,NA,3.37688044338879,1.76278015613193),
`2013` = c(
-2.37226328015073,7.38577178397857,8.77781429332619,1.92544399507649,NA,3.23423783752364,
1.10111836375706,NA,5.78966778544654,NA,1.05949782356168,2.44988864142539),
`2014` = c(
0.421637771012246,4.67399603536339,7.28038730361125,1.61304235314414,NA,2.77261158414198,
2.34626865671643,NA,2.98130868933673,NA,1.08944157435363,2.48792270531403
)
),
class = c("tbl_df", "tbl", "data.frame"),
row.names = c(NA,-12L)
)
sample
La idea del problema es poder inputar los valores perdidos siguiendo las siguientes reglas:
Algunos países tienen NAs para los 8 años de datos (columnas de la 3 a la 10) En ese caso se requiere remmplazar todos los NAs con el promedio de la columna.
Otros países sólo tienen NAs en alguns columnas in ese caso se quiere reemplazar los NAs con valor del año previo.
La última condición es que si el NA está en el primer año (2007) se quiere reemplazar con la media del año 2007 solamente (el 2008 fue la crisis financiera así que la inflación se fue a las nubes y ensucia el problema.
Por supuesto este problema puede ser resuelto fácilmente utilizando reglas de programación regular utilizando for loops y sentencias if. Pero la idea sería utilizar un approach Tidy utilizando librerías del Tidyverse.
library(dplyr, warn.conflicts = FALSE)
library(tidyr)
library(janitor)
# Obtener la medGetting the Column Means to Replace according to Condition 1 and 3.
(replacement <- sample %>%
select_if(is.numeric) %>%
summarize_all( ~ mean(., na.rm = TRUE)) %>%
#Transformando alista ya que es un requerimiento para
#tidyr::replace_na()
as.list())
La solución final
sample %>%
pivot_longer(`2007`:`2014`, names_to = "year", values_to = "int_rate") %>%
group_by(`Country Name`) %>%
summarize(na_num = is.na(int_rate) %>% sum) %>%
#Join con el número de NAs na-num con la nueva columna
left_join(sample, by = "Country Name") %>%
#Reemplazar los valores de 2007. Condición 3.
mutate(`2007` = if_else(between(na_num, 1, 7) &
is.na(`2007`), replacement[[1]] , `2007`)) %>%
#Haciendo un dataset long
pivot_longer(`2007`:`2014`, names_to = "year", values_to = "int_rate") %>%
group_by(`Country Name`) %>%
#imputar valores con año previo. Condición 2.
fill(int_rate) %>%
#Haciendo un dataset wide
pivot_wider(names_from = year, values_from = int_rate) %>%
#Reemplazar cuando todos los calores son NAs. Condición 1.
replace_na(replace = replacement)