Un algoritmo para detectar máximos y mínimos en Pandas
Cambios de Signo
En Jooycar nos dedicarmos a analizar comportamiento de manejo, y nos tuvimos que enfrentar a un problema muy pequeño en el que queríamos detectar si había una aceleración o un frenado, midiendo la curva de Fuerza G. En esta curva nosotros tenemos valores positivos, que representan que se está acelerando y valores negativos que representa que se está frenando. Para nosotros controlar estos valores es de extrema importancia ya que nos interesa velar por la seguridad del conductor y que un conductor se exponga a cambios extremos puede ser peligroso para su integridad física. Nuestro interés en específico era analizar el valor máximo de cada evento de Aceleración y de Frenado. Eso quiere decir que teníamos que encontrar los siguientes puntos:
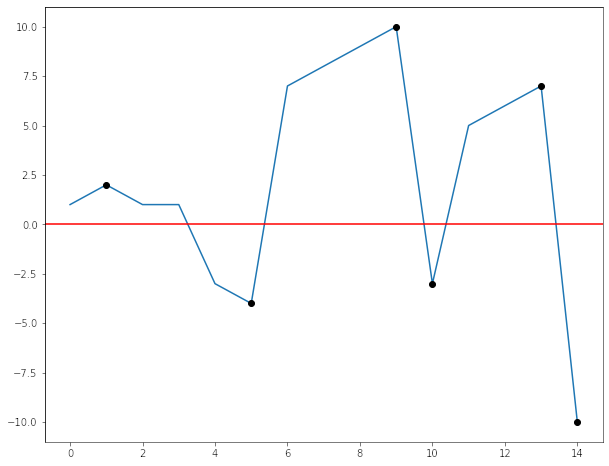
El gráfico muestra una curva de Fuerza G ficticia, pero de comportamiento similar, donde hay sectores sobre cero (positivos) y sectores bajo cero (negativos). El objetivo final es encontrar los puntos en negro que serán los valores máximos o mínimos, de cada uno de los peaks o valles que se vayan dando.
Para modelar esto se utilizarán los siguiente datos como un pandas DataFrame:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.DataFrame({"Eventos": [1,2,1,1,-3,-4,7,8,9,10,-3,5,6,7,-10]})
df.plot(figsize = (10,8))
plt.axhline(y = 0, c = 'r')
plt.show()
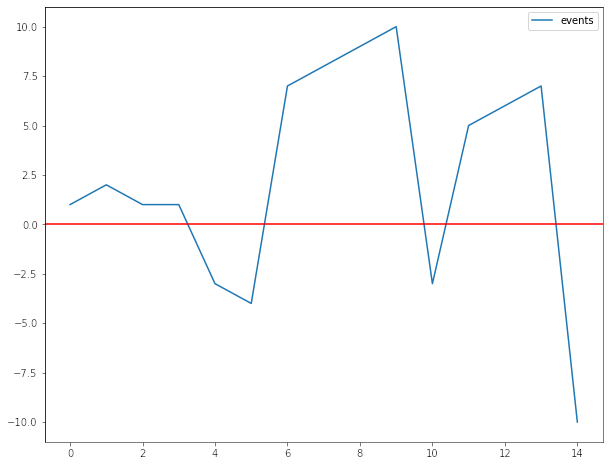
Teniendo los mismos datos, crear la lógica fue un poco compleja, pero muy similar al cálculo de la recencia. Iremos haciendo el cálculo columna por columna para que se entienda la lógica. Nuestra implemetación final no requiere la creación de columnas intermedias:
df["sign"]=np.sign(df.Eventos)
df['diff_sign'] = df.sign.diff()
df["change"]=np.cumsum(df.sign.diff() != 0)
df
| events | sign | diff_sign | change | |
|---|---|---|---|---|
| 0 | 1 | 1 | NaN | 1 |
| 1 | 2 | 1 | 0.0 | 1 |
| 2 | 1 | 1 | 0.0 | 1 |
| 3 | 1 | 1 | 0.0 | 1 |
| 4 | -3 | -1 | -2.0 | 2 |
| 5 | -4 | -1 | 0.0 | 2 |
| 6 | 7 | 1 | 2.0 | 3 |
| 7 | 8 | 1 | 0.0 | 3 |
| 8 | 9 | 1 | 0.0 | 3 |
| 9 | 10 | 1 | 0.0 | 3 |
| 10 | -3 | -1 | -2.0 | 4 |
| 11 | 5 | 1 | 2.0 | 5 |
| 12 | 6 | 1 | 0.0 | 5 |
| 13 | 7 | 1 | 0.0 | 5 |
| 14 | -10 | -1 | -2.0 | 6 |
Expliquemos un poco el algoritmo. Como se puede ver primero se aplica un np.sign. Esta función permite determinar el signo, positivo (1) o negativo (-1) del evento. Luego se aplico un .diff(). Esta función permite calcular la diferencia entre el valor siguiente y el anterior. Dado que la primera fila del Dataframe no tiene anterior es que se rellena con NaN.
Prestando atención a los resultados de la columna diff_sign es posible observar que los resultados son siempre cero, excepto en los lugares donde ocurre un cambio de signo.
Es a partir de ahí que nace la lógica de la columna change. Esta columna va a sumar de manera acumulativa todos los valores que no sean 0. Al hacer esto, vemos que cada sección, positiva o negativa, va a quedar asociada a un número. Es decir, pudimos crear un identificador de grupo, donde cada grupo es una sección que se va alternando entre el valor positivo y negativo.
Para poder calcular los valores máximos por grupo, basta con agrupar:
df["change"]=np.cumsum(df.sign.diff() != 0)
valores = df.groupby("change").events.transform(lambda x: x.abs().max())*df.sign
valores
0 2
1 2
2 2
3 2
4 -4
5 -4
6 10
7 10
8 10
9 10
10 -3
11 7
12 7
13 7
14 -10
dtype: int64
El resultado que se almacena en valores corresponderá al máximo para cada grupo. Este valor se encuentra repetido para cada instancia del grupo. Nótese que para evitar utilizar el mínimo o el máximo dependiendo si es peak o valle, se calcula sólo el máximo al valor absoluto de las instancias del grupo.
Finalmente para calcular los puntos y graficarlos se hace el siguiente truco: Si El evento es igual al valor máximo calculado entonces se deja como True, sino como NaN
mask = (df.Eventos == valores).mask(lambda x: x == 0, np.nan)
mask
0 NaN
1 2.0
2 NaN
3 NaN
4 NaN
5 -4.0
6 NaN
7 NaN
8 NaN
9 10.0
10 -3.0
11 NaN
12 NaN
13 7.0
14 -10.0
dtype: float64
Para terminar graficaremos nuestra curva inicial con la multiplicación del evento con mask lo que dejará visibles sólo los puntos máximos o mínimos según corresponda.
df.events.plot(figsize = (10,8))
plt.axhline(y = 0, c = 'r')
plt.plot(df.Eventos*mask, 'o', c = 'k')
plt.show()
Utilizando 3 funciones simples es posible resolver un problema de relativa complejidad para poder dar solución a una feature mediante análisis de Datos.
Nos vemos en la próxima,