Combinando Github Actions con CML
Github para Data Science Pt. 3

Siguiendo un poco con la racha de tutoriales dedicado al uso de Github, hoy quiero hablar de un tercer punto que creo que es importante que es la automatización al momento de productivizar. Yo soy Data Scientist, pero me gustaría mucho en el futuro cercano trabajar como Machine Learning Engineer y creo que una de las cosas más importantes de aprender en el desarrollo de software es CI/CD.
CI/CD
Corresponde a la sigla para Continuous Integration / Continuous Delivery y en el desarrollo de software se usa para automatizar tareas que siempre deben de ejecutarse para asegurar que el producto a productivizar es infalible, ojalá libre de errores y que pasa todos los test de calidad que el mismo proyecto se ha impuesto. Normalmente el Proceso de CI/CD incluirá procesos de Unit Testing, Deploy, Dockerización y un largo etc.
Cuando pensamos en el desarrollo de Machine Learning es un poco distinto. Hoy no quiero hablar de cómo hacer el deploy y el proceso de MLOps que uno debería seguir, sino más bien de cómo poder automatizar el proceso de Experimentación y que pueda ser revisado de manera más amena.
Pongo el siguiente caso (porque lo he vivido):
- Tengo un proyecto.
- Tengo un Product Owner, que normalmente no entiende nada de código (esto me parece que no debiera ser así y deberían empezar a interiorizarse más en el tema. Siempre se habla de que el DS tiene que entender del negocio para poder explicar a los stakeholders, pero el negocio nunca hace un esfuerzo por entender lo técnico, en fin, pelea para otro día).
- El Product Owner quiere entender si tenemos alguna mejora, es decir, si el modelo está mejorando o no.
- Cita a una Reunión en la que hay mostrarle el Jupyter Notebook y llegamos a las métricas finales.
- Finalmente el interés del PO es: ¿Mejoramos el Accuracy/Recall/Valor para el negocio/etc. o no?
Y la reunión termina con un ¿y probaste X, probaste Y o probaste Z? ¿Mejora o no? Y uno rápidamente tiene que ponerse a corregir el notebook en vivo o citar a otra reunión para volver a tener la misma conversación y mostrar los nuevos resultados.
Bueno, creo que todo este proceso tedioso podría hacerse de manera asíncrona, sin perder tiempo en reuniones y tener la discusión en un Pull Request (que creo que es algo que un PO debería poder saber qué es, cómo hacerlo y cómo interactuar con él).
iterative.ai desarrolló una herramienta llamada CML una herramienta para Continuous Machine Learning.
Si bien creo que es una herramienta bastante básica y en pleno desarrollo, creo que aporta con varios elementos que nos permiten solucionar el problema que expongo anteriormente. Es fácil de usar y cumple su objetivo que es lo más importante de todo que es generar reportes, en medio del Pull Request para mostrar en simple los avances del código del modelo.
CML funciona con Github Actions. Github Actions es la herramienta que Github provee para hacer CI/CD. Github Actions básicamente crea una maquina virtual (VM) de manera automatizada donde se ejecutarán los comandos que uno le indique. Estos comandos pueden ejecutarse cada vez que se hace un commit, push, PR, etc. Dentro de esa VM nosotros ejecutaremos CML, el cual nos permitirá crear dicho reporte con lo que nosotros indiquemos.
Creo que CML se puede utilizar para bastantes cosas más, pero aún estoy aprendiendo y haciendo pruebas de en qué flujos podría ser una alternativa.
CML es compatible también con Gitlab CI, y tiene una imagen Docker prefabricada, por lo que en caso de tener Circle CI, Travis CI, Jenkins o cualquier otra alternativa de CI/CD también debería ser posible utilizarlo.
Github Actions
Bueno Github Actions está disponible en cualquier repositorio de Github. Basicamente una Action es un Script que permite crear un ambiente virtual en el que podemos tener cosas pre-instaladas, o podemos cargar una imagen Docker. Todo usuario de Github tiene gratis varios minutos al mes de Github Actions, luego de esa cuota se empieza a cobrar para tener acceso a minutos adicionales. Si les interesa pueden ver los precios acá.
Acabo de volverme Github Pro y eso aumenta la cuota de minutos mensuales de 2000 a 3000, que creo que para un usuario normal es suficiente. En el caso de empresas es recomendable que tenga un plan.
Entonces para utilizar Github Actions basta con que tu repo contenga una carpeta llamada .github/workflows. Dentro de esta carpeta crearemos un archivo yaml, el cual puede tener cualquier nombre.
Para mostrar esto con ejemplos concretos utilizaremos el Repo utilizado en el tutorial de DVC. Además para seguir un correcto uso de GIT crearé una Rama llamada CML:
$ git checkout -b CML
Dentro de esta rama crearé el siguiente archivo ´cml.yaml´:
name: train-my-model
on: [push]
jobs:
train-model:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: iterative/setup-cml@v1
- uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Train model
env:
repo_token: $
run: |
pip3 install -r requirements.txt
dvc repro
# Create CML report
echo "## Metrics" >> report.md
dvc metrics show --show-md >> report.md
cml publish conf_mat.png --md >> report.md
cml send-comment report.md
Este archivo puede verse muy complejo de entender, pero paso a explicar parte por parte en detalle:
- name: No es nada más que el nombre que yo le doy a mi proceso, no afecta a mi proceso de CI/CD.
- on: Esto indica cuando se va a ejecutar la Action. En este caso esto se va a ejecutar siempre y cuando haga un push. Pero existen distintas opciones que se pueden ver acá. Github actions es tán flexible que se pueden ejecutar en distintos eventos, en ramas específicas, etc.
- Luego jobs especificará qué hará el proceso:
- runs-on: Indica en qué ambiente correrá. En este caso se indica una maquina virtual con ubuntu-latest. Lo más común es usar ubuntu ya que es lo más barato y fácil, otras opciones incluyen Windows y MacOs que son más caras. En mi opinión Ubuntu es suficiente a menos que tengas dependencia de OS, por ejemplo, si estás desarrollando un app para Mac y tiene que probarse en dicho OS.
- steps: Indica qué se va a instalar en la VM. Hay que entender la VM es una maquina creada de cero, no tiene nada.
- uses: Son las Actions predefinidas que se van a cargar, esto normalmente sirven como preparación del ambiente:
- actions/checkout@v2: Esto lo que hace es cargar toda la Info del commit para que esté disponible en la maquina. Si no hacemos esto, nuestros scripts no pueden ser vistos por la VM.
- iterative/setup-cml@v1: Esta instala CML, y está indicado en la Documentación de CML como una línea obligatoria.
- actions/setup-python@v2: Instala Python. Tengo dudas si este paso es realmente necesario porque en la Doc dice que la Action de CML ya tiene Python incluido, pero igual en su ejemplo usan este paso.
- name: Este otro name ahora indica el nombre de una etapa. Uno eventualmente puede dividir su Action en varias etapas.
- env: Declara variables de entorno.
- repo_token: $ Esta es una variable de entorno propia del Repo de Github. La razón de agregarla es que para que CML pueda comentar dentro del PR que vamos a generar.
- run: Finalmente este comando permite ejecutar cualquier tipo de comando válido en la VM.
Modificaciones en esta Rama
Aparte de que nuestra rama agrega cml.yaml para configurar Github Actions, hicimos las siguientes modificaciones:
- Creamos un archivo
requirements.txtpara definir las dependencias de nuestro proyecto. Esto es importante ya que, como dijimos anteriormente, nuestra VM de Github Actions no tiene nada instalado.
gdown
pandas
dvc
scikit-learn
matplotlib
- Modificamos nuestro script
src/04-evaluate_model.pyde la siguiente forma:
import json
import joblib
import pandas as pd
from sklearn.metrics import accuracy_score, recall_score, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
from config import Config
X_test = pd.read_csv(Config.FEATURES_PATH / 'test_features.csv')
y_test = pd.read_csv(Config.FEATURES_PATH / 'test_labels.csv')
model = joblib.load(Config.MODELS_PATH / 'model.joblib')
y_pred = model.predict(X_test)
output = dict( test_accuracy = accuracy_score(y_test, y_pred),
test_recall = recall_score(y_test, y_pred, average='macro'))
with open(Config.METRICS_PATH, 'w') as outfile:
json.dump(output, outfile)
ConfusionMatrixDisplay.from_predictions(y_test, y_pred)
plt.title("Confusion Matrix for NBA Positions.")
plt.xlabel("Posiciones Predichas")
plt.ylabel("Posiciones Reales")
plt.savefig('conf_mat.png')
Básicamente sólo importamos matplotlib y agregamos una Matriz de Confusión la cual guardamos como conf_mat.png. Ojo, Scikit-Learn cambió su API gráfica de curvas desde la versión 1.0. Personalmente me gustó mucho la nueva API, ya que permite crear curvas from_prediction, from_model y como clase. Para entender más como funciona la nueva interfaz pueden ir acá.
Entonces teniendo estos cambios nuestro run, que quizas es la única parte que nos corresponde modificar al momento de setear Github Actions, queda así:
- Instalamos las dependencias de nuestro proyecto con
pip install -r requirements.txt. - Luego hacemos
dvc repropara ejecutar nuestro experimento. - Luego tenemos los siguientes comandos:
- echo “## Metrics” » report.md: Esto escribe Metrics como Título dos y lo guarda en un archivo llamado report.md
- dvc metrics show –show-md » report.md: Esto toma las métricas de nuestro modelo las convierte en formato markdown y le hace un append al mismo archivo report.md.
- cml publish conf_mat.png –md » report.md:
cml publishcorresponde a uno de los comandos de CML, tomará en este caso el archivo.pngy lo inserta en el archivo report.md. Publish se utiliza sólo con imágenes. cml send-comment report.mdtomará nuestro archivo y lo publica como un comentario en nuestro Pull Request.
Al hacer los cambios mandamos todo a Github:
$ git add .
$ git commit -m 'Adding CI/CD'
$ git push --set-upstream origin CML
Al ejecutar esto, creamos el Pull Request. Si ahora vamos a Github en la pestaña Actions veremos algo así:

En este caso el workflow posee el Mensaje del Commit, la Rama y un color que puede ser Rojo si falla, Amarillo cuando se está ejecutando y verde cuando se ejecutó sin problemas.
Al clickear en el Workflow encuentran esto:
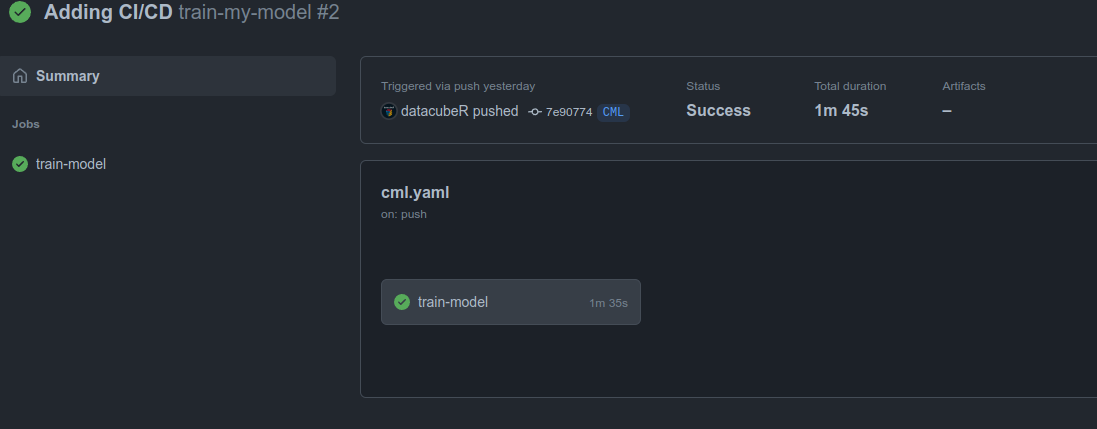
En este caso vemos, el nombre de la etapa Train Model se transforma en train-model y nos dice que el proceso fue exitoso y duró 1m 45s. Esto es importante porque acá Github va llevando registro de nuestra cuota mensual. Si clickeamos nuevamente en train-model vemos lo siguiente:
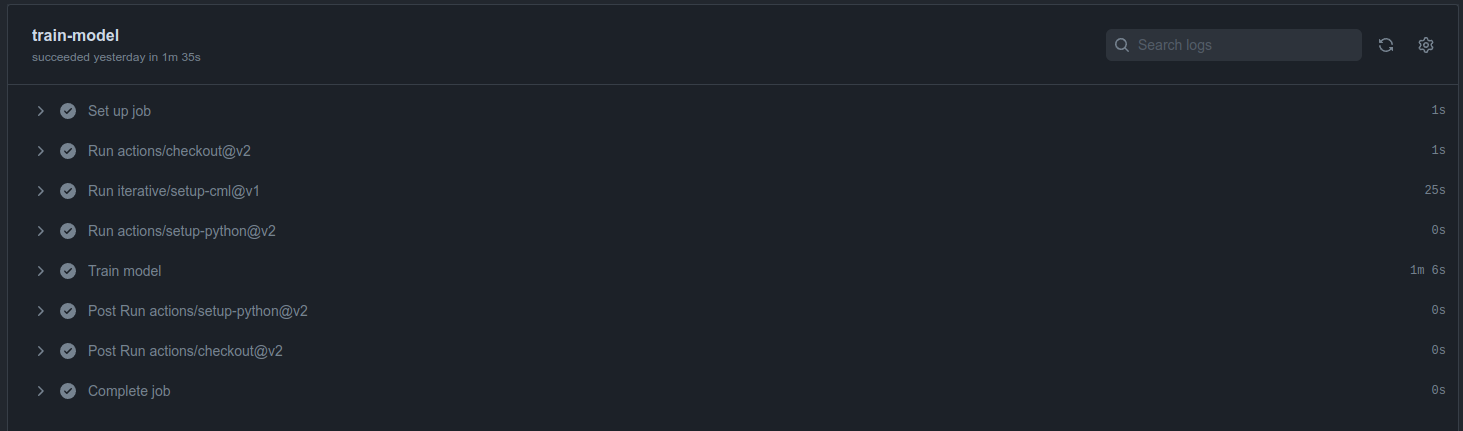
Acá podemos ver un desglose de todo. Podemos notar que nuestro proceso de entrenamiento es el que más tiempo toma con 1m 6s debido a la instalación de las librerías más la ejecución de nuestro Pipeline. Luego lo que más demora es la instalación de CML con 25s. Ante la duda de si utilizar o no la Action con Python es indistinto ya que tomó 0 segundos.
Finalmente si volvemos al Pull Request veremos el resultado:
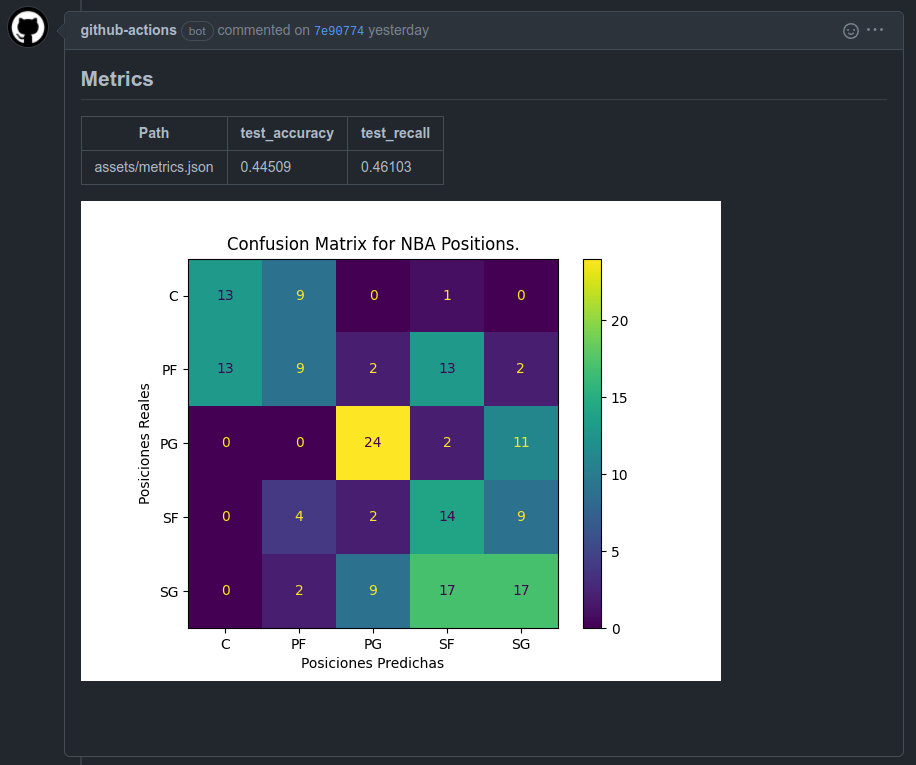
Podemos ver las métricas obtenidas en nuestro tutorial anterior. Y además tenemos una Matriz de Confusión, la cual podría ser útil para nuestro PO para poder evaluar si el nuevo modelo cumple con sus expectativas o no. Obviamente, esto es un ejemplo, y dependiendo del proyecto podremos definir cuales son las gráficas y métricas de interés para medir si nuestro proyecto está avanzando o no. En el caso de que este modelo cumpla con las expectativas podemos hacer el merge con Master para pasarlo como nuestro modelo actual.
Como justo terminó la temporada regular de la NBA podríamos desviarnos un poquito a analizar los resultados del modelo. No tiene que ver con el tutorial pero es importante entender para qué serviría colocar una gráfica así en el Pull Request.
Dijimos que la intención del modelo es poder entender de acuerdo a las estadísticas del jugador, cuál podría ser una posición adecuada. Si miramos nuestras métricas, son pésimas, pero ¿quiere decir que nuestro modelo es realmente inservible?
Si analizamos la Matriz de Confusión que está hecha para el Test Set, podemos notar que nuestro modelo tiene grandes problemas para diferenciar, por ejemplo, un Centro (C) de un Power Forward (PF). Y tiene razón, hoy en día el Centro (C) es una pieza fundamental en el ataque no sólo como el reboteador del equipo y quien hace las pantallas, sino como anotador y pasador (algunos hasta anotando triples). En mi opinión, Anthony Davis (PF), Giannis Antetokounmpo (PF), Nikola Jokic (C) y Joel Embid (C) son el mismo monstruo. Tipos gigantes y atléticos (Jokic un poco menos) pero extremadamente completos, que sólo juegan en esas posiciones por su altura y poder, pero podrían jugar en cualquier posición. Se entiende que en la NBA actual el modelo tenga problemas diferenciando dichas posiciones.
Por otro lado, se ve una tremenda confusión entre los PF, SG y PG. Y en mi opinión la NBA actual ya no sigue para nada dichas posiciones. Los Point Guards (PG) solían ser tipos pequeñitos muy hábiles que destacaban por su habilidad para pasar (recordar John Stockton, Tony Parker, Steve Nash, Jason Kidd). Hoy son el show de cada partido: Steph Curry, Ja Morant, Chris Paul, Kyrie Irving. Si bien algunos siguen el esterotipo, podrían perfectamente jugar de SG o SF por su habilidad anotadora si tuvieran mayor corpulencia. Por el otro lado, los SG eran los anotadores con buen dominio de balón y los SF eran Anotdores, robustos que no tenían tanta habilidad en el dribble pero hoy: Lebron James (SF), Kevin Durant (SF), Kawhi Leonard (SF), James Harden (SG), Donovan Mitchell (SG) o Devin Booker (SG), son jugadores prácticamente intercambiables. Son tan completos que la única razón por la que no juegan de PF o C es su altura o robustez, pero en muchas ocasiones durante partidos se les ve ejerciendo el rol de armador (PG).
Con esto no quiero defender al modelo, efectivamente sus métricas están mal, pero analizando una simple Matriz de Confusión más un poquito de Conocimiento del Juego se pueden obtener muy buenos insights para mejorar el modelo (y obtener valor). Por ejemplo, incluir altura y peso para definir de mejor manera las posiciones dentro de la cancha, ya que diría que hoy ya no es un tema de habilidad, sino más bien de corpulencia.
Setear un Action la primera vez no es fácil, de hecho pueden ir a mi tab de Actions para ver todas los workflows fallidos que tuve antes de encontrar la combinación correcta. Lo bueno es que una vez que la configuración está correctamente hecha no hay que preocuparse más
¿Cómo Combinar CML con la Interfaz de Experimentación?
Uno de los flujos que consideré que podía ser bueno utilizar CML es para experimentar. Lamentablemente me encontré con un muro. Mi idea era utilizar el Workflow para ejecutar todas los experimentos y generar un reporte de todo lo obtenido con el fin de que todo se hiciera en la maquina virtual y no en mi maquina, cosa que yo pudiera seguir trabajando.
Github Actions permite utilizar self-hosted servers, es decir podríamos correr estos procesos en un servidor propio o incluso en máquinas Cloud (esto queda para una futura iteración)
Lamentablemente, CML no está pensado para experimentar y luego de muchas pruebas fallidas intentando correr experimentos me di cuenta de que no se podía. Aún así llegué al siguiente flujo el cual se puede ver en mi rama rama-experimental. la Documentación de DVC y CML no estaba preparada para esto. Intentando muchas pruebas no encontré solución, por lo que decidí abrir un issue en el repo de DVC que pueden ver acá.
La verdad es que tenía pensado sacar este tutorial la semana anterior, pero al encontrarme con esto decidí que no era buena idea. De hecho en un momento hasta pensé que no valía la pena aprender CML. Pero gracias a la ayuda de los mantenedores logramos sacar el tutorial adelante.
Por lo tanto, para poder generar una interfaz remota de experimentación crearemos una nueva rama:
$ git checkout -b rama-experimental
En esta rama considero los mismos cambios de la Rama CML pero agrego los siguientes:
Cree el archivo exp_file.sh en el cual setié experimentos:
dvc exp run --queue -S train.C=5
dvc exp run --queue -S train.C=30
dvc exp run --queue -S train.C=60
dvc exp run --queue -S train.C=120
dvc exp run --run-all
Como se puede ver, generé 4 experimentos en el cual pruebo los valores C=5,30,60,120. El flag --queue permite generar una cola de experimentos los cuales se correrán con dvc exp run --run-all lo cual puede ser súper útil para dejar ejecutando e irse a descansar.
Luego para poder hacer correr la interfaz de experimentación en Github Actions tuve que modificar el cml.yaml de la siguiente manera:
name: experiments
on: [push]
jobs:
train-model:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
fetch-depth: 0
- uses: fregante/setup-git-user@v1
- uses: iterative/setup-cml@v1
- uses: iterative/setup-dvc@v1
- uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Experiment
env:
repo_token: $
run: |
pip3 install -r requirements.txt
bash exp_file.sh
echo "## Resultados del Experimento" >> report.md
dvc exp show --only-changed --drop 'assets|src' --no-pager --md >> report.md
cml send-comment report.md
De acuerdo a los comentarios en el issue, dvc exp run requiere la historia de GIT completa y no sólo un shallow-clone. Por defecto actions/checkout@v3 hace un checkout sólo del commit actual, lo que no es suficiente. Agregando el fetch-depth: 0 tenemos la historia completa que permite a DVC funcionar correctamente.
Durante esta semana salió actions/checkout@v3 que tiene unas mejoras de performance respecto actions/checkout@v2. Yo probé todos los workflows probando ambas y cualquiera que quieras utilizar funciona bien siempre y cuando se agregue el fetch_depth: 0.
Al intentar esto, me dí cuenta de que DVC necesita conectarse con tu cuenta de GIT. Y lamentablemente dentro de la maquina virtual DVC no tiene tus credenciales de GIT. Para solucionar esto, encontré otra action que lo hace, con lo que basta agregar la línea uses: fregante/setup-git-user@v1 y asunto solucionado.
Finalmente indagando dentro de la documentación de DVC encontré que desarrollaron un Action para instalar DVC de manera más rápida que el pip install. Aplicamos dicho paso utilizando la línea uses: iterative/setup-dvc@v1.
Aún así tuve que dejar DVC como dependencia ya que pip install dvc instala el paquete yaml, el cual es dependencia para usar parámetros. Lo dejé mencionado en el issue y espero pronto se solucione eso.
Subiendo los cambios a Github y siguiendo el mismo procedimiento anterior obtuve lo siguiente en mi Pull Request:
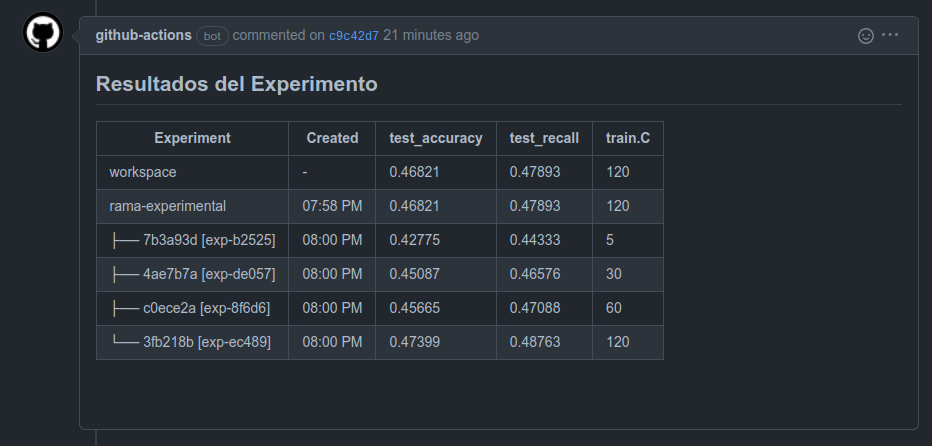
Creo que este puede ser un buen flujo para poder dejar documentado cuales fueron los avances que he ido teniendo junto con visualizaciones y métricas que me interesan para poder medir el impacto del modelo. En el caso de que algún set de hiperparámetros me guste los dejo fijos en el siguiente commit y ejecuto dvc repro para generar el primer reporte que mostramos en el tutorial.
Investigando para solucionar el flujo de experimentación me encontré que Github Actions es una herramienta muy poderosa. Hay muchas ideas que encontré para poder dejar un flujo automatizado completamente en la interfaz de Github por lo que a medida que vaya implementando más cosas las iré compartiendo. CML por su parte nos ayudará a generar el reporte y agregar nuestras imágenes de manera sencilla como comentario.
Como siempre, pueden ir a mi Github y en especial a este Repo. En este caso dejé todas las ramas y los Pull Requests para que puedan seguir todo el flujo que seguí al construir este tutorial. También decidí no eliminar todos los intentos fallidos de Actions por lo que pueden ir revisando lo que les interese.
Espero que este tutorial les haya gustado y nos vemos a la próxima.