Resolviendo el Problema de Perros vs Gatos
Transfer Learning + RTX 3090
En Junio del 2012, Andrew Ng era optimista acerca de los promisorios resultados que estaban entregando en ese tiempo las redes Neuronales. En un trabajo llamado ¿Cuántos computadores para identificar un gato? 16000 Se demostraba el tremendo logro de que una red neuronal pudiera diferenciar una imagen de un gato, eso sí a un tremendo costo computacional. En el mismo año 2012, pero en Septiembre se la Arquitectura AlexNet ganó el ImageNet Large Scale Visual Recognition Challenge. Un consurso que hace un tiempo se dejó de hacer pero que fue el impulsor de grandes Arquitecturas de Redes Convolucionales como Inception (GoogleNet), ResNets, ResNexts entre otras.

En el artículo de hoy quiero demostrar que es posible resolver el problema de Gatos vs Perros. Este es un problema que ya está resuelto, pero quiero atacarlo con datos reales, de buena calidad, color y buen tamaño. Para ello se disponibilizaron 24994 entre perros y gatos para entrenar una red Neuronal que sea capaz de diferenciarlos. Generaremos una implementación de una Red en Pytorch y lo compararemos con una implementación de AlexNet pre-entrenado utilizando Transfer Learning.
Además me interesa probar como rinde la RTX 3090 en un set de datos considerable. Vamos con la implementación:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torchvision.utils import make_grid
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from PIL import Image
from IPython.display import display
import glob
Además si te interesa recrear este problema disponibilicé las imágenes de este tutorial en el siguiente link
Nota: Este es un problema de verdad y las imágenes pesan cerca de 800Mb por lo que asegúrate de tener espacio para almacenarlas y una cantidad de RAM suficiente para manipular esta cantidad de datos.
Una vez descargadas las imágenes podemos notar que vienen de la siguiente forma: 
Dos carpetas, una de train y test. Cada una contiene dos subcarpetas que separan las imágenes de Perros y/o Gatos. Si utilizamos la librería PIL, librería por defecto para manipular imágenes en Python, podemos importar la imágen de un Gato de la siguiente manera:
with Image.open('CATS_DOGS/test/CAT/10107.jpg') as im:
display(im)

En este caso tenemos una imágen pequeñita de un gato. Pero no todas las imágenes son así. Antes que cualquier cosa chequeemos la integridad de los datos. Muchas veces, las imágenes pueden venir corruptas y no es posible importarlas. Por lo tanto, chequeemos el número de elementos en las carpetas:
img_names = glob.glob('*/*/*/*.jpg')
len(img_names)
24994
%time
img_sizes = []
rejected = []
for item in img_names:
try:
with Image.open(item) as img:
img_sizes.append(img.size)
except:
rejected.append(item)
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 3.58 µs
print('Imágenes correctamente importadas: ', len(img_sizes))
print('Imágenes no importadas: ',len(rejected))
Imágenes correctamente importadas: 24994
Imágenes no importadas: 0
Además como se mencionó anteriormente se puede chequear que existen imágenes de distintos tamaños. Si mostramos las 10 primeras imágenes notamos acá los distintos tamaños presentes:
img_sizes[:10]
[(500, 248),
(500, 332),
(500, 375),
(350, 374),
(500, 375),
(500, 375),
(243, 346),
(353, 467),
(500, 375),
(458, 415)]
Es más, podemos importar las imágenes dentro de un DataFrame y chequear algunos estadísticos:
df = pd.DataFrame(img_sizes, columns = ['width','height'])
df.describe()
| width | height | |
|---|---|---|
| count | 24994.000000 | 24994.000000 |
| mean | 404.493518 | 361.037129 |
| std | 108.941802 | 96.936811 |
| min | 42.000000 | 33.000000 |
| 25% | 323.000000 | 302.000000 |
| 50% | 448.000000 | 375.000000 |
| 75% | 500.000000 | 421.000000 |
| max | 500.000000 | 500.000000 |
Es posible observar que el tamaño máximo de las imágenes es de 500 x 500 (imágenes de tamaño razonable). Por otro lado, las dimensiones más pequeñas son del orden de 40 píxeles. En promedio las imágenes tienen un tamaño cercano a los 400x360. Cabe destacar también que las imágenes son a color por lo que tendrán 3 canales (RGB).
Importemos entonces una imagen de un perro. Es posible ver que la imagen es de alta calidad y se puede notar claramente su contenido a diferencia de los problemas de CIFAR-10 o MNIST que son los más básicos para partir explorando en cuanto a redes neuronales.
dog = Image.open('CATS_DOGS/train/DOG/14.jpg')
dog

Además, se puede apreciar, que cada imágen tiene 3 canales, que van de 0 a 255. Esta es la manera estándar de representar imágenes a color.
dog.getpixel((0,0))
(90, 95, 98)
Preprocesamiento
Dada la complejidad del problema se requiere establecer un Pipeline de preprocesamiento que ayude a la red Neuronal a aprender a identificar las clases Perro y Gato de mejor manera. Además este Pipeline debe garantizar que las imágenes que entran a la red son todas de las mismas dimensiones. Esto es un requerimiento de la red Convolucional, ya que sólo pueden recibir Tensores del mismo tamaño.
transform = transforms.Compose([
transforms.Resize((250)), # Resize a 250 Pixeles
transforms.CenterCrop(250), # Centra la imágen
transforms.ToTensor(), # Transforma a Tensor
])
im = transform(dog)
print(type(im))
print(im.shape)
<class 'torch.Tensor'>
torch.Size([3, 250, 250])
#matplotlib, height, width and channel
plt.imshow(np.transpose(im.numpy(), (1,2,0)));

Data Augmentation
Adicionalmente haremos modificaciones a la imagen, tales como pequeñas rotaciones, y flips tipo espejo, que funcionarán como Data Augmentation a modo de dar mayor capacidad de entendimiento a la red Neuronal.
Si bien en artículos anteriores utilizamos Albumentations para realizar este proceso, en este caso utilizaremos directamente torchvision. La razón de esto es que torchvision espera que la imágen sea importada en formato imagen, es decir, utilizando PIL, mientras que Albumentations espera un numpy array, lo que agregaría un paso de transformación adicional.
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p = 1),
transforms.RandomRotation(30),
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor()
])
im = transform(dog)
print(type(im))
print(im.shape)
#matplotlib, height, width and channel
plt.imshow(np.transpose(im.numpy(), (1,2,0)));
<class 'torch.Tensor'>
torch.Size([3, 224, 224])
Normalización
Adicionalmente, torchvision recomienda una normalización. Esto, alterará la distribución de los píxeles. La razón de esto es porque normalizar permitirá resaltar otros aspectos de la imagen que a simple vista no pueden verse. Adicionalmente, los modelos preentrenados fueron entrenados con una normalización particular (que es la que usaremos acá). Esta normalización permitirá un mejor desempeño del modelo.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = [0.485,0.456,0.406], std = [0.229,0.224,0.225])
])
im = transform(dog)
print(type(im))
print(im.shape)
#matplotlib, height, width and channel
plt.imshow(np.transpose(im.numpy(), (1,2,0)));
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255]
for integers).
<class 'torch.Tensor'>
torch.Size([3, 387, 500])

Red Convolucional Convencional
El primer modelo que intentaremos es una Red Convolucional común y corriente. Para ello crearemos un Pipeline de Transformaciones que incluirán rotaciones, flips y un tamaño estandar que en este caso será de 224 pixeles. La imágen será centrada y además se normalizará.
El augmentation se realiza sólo a los datos de entrenamiento. A los datos de test se aplica sólo el Centrado y el cambio de tamaño, además de la normalización.
train_transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomHorizontalFlip(),
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
#normalización sugerida por torchvision para modelos pre-entrenados.
])
test_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
Torchvision contiene un ImageFolder utility que es muy conveniente para la organización con el que se entregan las imágenes. Este .ImageFolder permitirá importar los datos de entrenamiento y Test. Además, mediante las subcarpetas podrá inmediatemente asignar la clase a la que pertence cada imagen. Las clases del problema serán entonces inferidas de los nombres CAT y DOG.
Además en este mismo paso se crearán los DataLoaders. Se utilizará un batch size de 100 imágenes y se mezclarán sólo las de entrenamiento. Una aspecto que va a ser primordial si se quiere acelerar el proceso de entrenamiento es el uso de pin_memory=True. Esto permitirá provisionar memoria en la GPU para un entrenamiento más rápido y num_workers=12, que permitirá hacer el proceso de augmentation (que hay que recordar que se hace en CPU) de manera paralelizada.
En mi experiencia es bueno dejar un par de núcleos libres. En mi caso estoy entrenando en J.A.R.V.I.S que tiene 16 núcleos. Si bien a los que les gusta el peligro pueden usar todos sus núcleos, yo prefiero dejar algunos libres, porque si mi proceso se demora, no quiero perder mi progreso porque el PC se quedó sin recursos.
# Utility para importar imágenes desde carpetas
train_data = datasets.ImageFolder('CATS_DOGS/train', transform = train_transform)
test_data = datasets.ImageFolder('CATS_DOGS/test', transform = test_transform)
torch.manual_seed(42)
train_loader = DataLoader(train_data, batch_size = 100, pin_memory = True,
num_workers = 12, shuffle = True)
test_loader = DataLoader(test_data, batch_size = 100, pin_memory = True,
num_workers = 12, shuffle = False)
class_names = train_data.classes #obtenido directamente de las carpetas
class_names
['CAT', 'DOG']
Por lo tanto del total de imágenes, se tiene la siguiente distribución:
print('Imágenes de Train: ', len(train_data))
print('Imágenes de Test: ', len(test_data))
Imágenes de Train: 18747
Imágenes de Test: 6251
for images, labels in train_loader:
break
images.shape
torch.Size([100, 3, 224, 224])
im = make_grid(images, nrow=5)
inv_normalize = transforms.Normalize(mean = [-0.485/0.229, -0.456/0.224, -0.406/0.225],
std = [1/0.229, 1/0.224, 1/0.225])
im_inv = inv_normalize(im)
plt.figure(figsize = (20,40))
plt.imshow(np.transpose(im_inv.numpy(),(1,2,0)))
plt.axis('off');

Arquitectura de la Red
La Red que utilizaremos tendrá 2 capas convolucionales. Entre cada capa convolucional se aplicará una activación ReLU y un MaxPool2D para reducir de tamaño. Luego de las capas convolucionales se aplicarán 3 capas Lineales, una que recibe el tensor proveniente de las capas Convolucionales de tamaño (54x54, que es el tamaño de la imagen resultante x16 (número de filtros de la capa anterior)) que tendrá 120 neuronas, luego pasará a una capa de 84 para terminar en las dos clases (Perros y Gatos).
class ConvolutionalNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 3, 1)
self.conv2 = nn.Conv2d(6, 16, 3,1)
self.fc1 = nn.Linear(54*54*16, 120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,2)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x,2,2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x,2,2)
x = x.view(-1, 54*54*16)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
El modelo será entrenado con CrossEntropy Loss como Loss Function y Adam como optimizador.
torch.manual_seed(101)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Dispositivo: ',torch.cuda.get_device_name(0))
CNNmodel = ConvolutionalNetwork().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(CNNmodel.parameters(), lr = 0.001)
CNNmodel
Dispositivo: GeForce RTX 3090
ConvolutionalNetwork(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=46656, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=2, bias=True)
)
La arquitectura construida tendrá el siguiente número de Parámetros:
con = 0
for p in CNNmodel.parameters():
con += p.numel()
con
5610222
Entrenamiento
import time
start_time = time.time()
epochs = 3
max_trn_batch = 800
max_tst_batch = 300
train_losses = []
test_losses = []
train_correct = []
test_correct = []
for e in range(epochs):
trn_corr = 0
tst_corr = 0
for b, (X_train, y_train) in enumerate(train_loader):
b += 1
x,y = X_train.to(device), y_train.to(device)
y_pred = CNNmodel(x)
loss = criterion(y_pred, y)
#arg max
predicted = torch.max(y_pred.data,1)[1]
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(loss)
train_correct.append(trn_corr)
with torch.no_grad():
for b, (X_test, y_test) in enumerate(test_loader):
x_t, y_t = X_test.to(device), y_test.to(device)
y_val = CNNmodel(x_t)
predicted = torch.max(y_pred.data,1)[1]
loss = criterion(y_val, y_t)
test_losses.append(loss)
test_correct.append(tst_corr)
#print(f'Epoch {e} Loss: {loss.item()}')
print(f'Epoch {e + 1}/{epochs}, Train Loss : {train_losses[e]}, Test Loss: {test_losses[e]}')
total_time = time.time()-start_time
print(f'Total Time: {total_time/60} minutes')
Epoch 1/3, Train Loss : 0.6994757056236267, Test Loss: 0.41201767325401306
Epoch 2/3, Train Loss : 0.3059247136116028, Test Loss: 0.37493208050727844
Epoch 3/3, Train Loss : 0.3059287965297699, Test Loss: 0.5692620277404785
Total Time: 0.6383750836054484 minutes
La red neuronal fue entrenada utilizando la RTX 3090. Como pueden ver, el entrenamiento es muy rapido, toma cerca de 40 segundos. Hice pruebas con num_workers=1 y toma cerca de 4 minutos. Realmente influye mucho paralelizar las transformaciones. Es muy probable que si utilizaramos Albumentations se podría reducir esto aún más.
Con respecto a los resultados se ve que hay sobreajuste a pesar de sólo entrenar por 3 Epochs. Esto va a tener un impacto negativo en el desemepeño del modelo.
Calculando el Accuracy obtenido llegamos a tan sólo un 79%.
test_load_all = DataLoader(test_data, batch_size = len(test_data), shuffle = False)
with torch.no_grad():
correct = 0
for X_test, y_test in test_load_all:
x_t, y_t = X_test.to(device), y_test.to(device)
y_val = CNNmodel(x_t)
predicted = torch.max(y_val, 1)[1]
correct += (predicted == y_t).sum()
correct.item()/len(test_data)
0.7859542473204287
Ahora, para medir el resultado en la práctica del modelo, agregué fotos de mis Mascotas: Cocó (la gatita negra), Nala (la gatita Romana) y la Kira (la favorita, se nota cierto?). Al predecir sobre estas fotos se obtienen los siguientes resultados:
from mpl_toolkits.axes_grid1 import ImageGrid
def predict(model,image):
pic = test_transform(Image.open(image))
model.eval()
with torch.no_grad():
new_prediction = model(pic.view(1,3,224,224).to(device))
return class_names[new_prediction.argmax().item()]
def prediction_grid(model, image):
fig = plt.figure(1, (20., 20.))
grid = ImageGrid(fig, 111,
nrows_ncols=(4, 2),
axes_pad=0.4,
)
for img, axes in zip(im_list,grid):
axes.set_title(f'{img} is a {predict(model,img)}', fontdict=None,
loc='center', color = "k")
axes.axis('off')
axes.imshow(Image.open(img))
return plt.show()
im_list = ['kira.jpg','kira2.jpg','kira3.jpg',
'kira4.jpg','kira5.jpg','kira6.jpg',
'coqui.jpg','nalita.jpg']
prediction_grid(CNNmodel, im_list)

Si bien la mayoría de los resultados están correctos, me molesta demasiado que la primera foto, que se nota claramente que es un perro sea predicho como un gato. Algunas de las teorías que tengo, es que cuando se hace el resize, se cortan un poco las orejas, y por el ángulo no se puede apreciar el largo de la nariz, dos aspectos claves para predecir la diferencia entre ambos animales. Veamos qué tal nos va a ahora con Transfer Learning.
Transfer Learning
Transfer Learning se refiere al uso de Redes Preentrenadas, es decir, ya tienen pesos. Esto normalemente se traduce en que ya saben ver. Por lo tanto, no tienen que aprender a ver y además aprender a diferenciar mi data. Al usar redes entrenadas, de lo único que se debe preocupar la red es en aprender mis datos. Entonces, la habilidad para ver la aprendió en su pre-entrenamiento y el ver mis datos lo aprende en el fine-tuning que daremos ahora. En este caso usaremos AlexNet, la cual fue preentrenada en ImageNet, que creo que tiene categorías de Perros y Gatos.
Por lo tanto desde torchvision.models podemos importar AlexNet pre-entrenado. Como se puede ver es un modelo bastante más complejo.
AlexNetmodel = models.alexnet(pretrained=True)
AlexNetmodel
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(i(4): LogSoftmax(dim=1)lace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Además, vamos a congelar sus pesos. Esto nos permitirá no modificarlos. Es decir sólo entrenaremos los pesos asociados a la cabeza de la red, que son los que aprenden los datos. La capacidad de ver de la red quedará intacta:
for param in AlexNetmodel.parameters():
param.requires_grad = False
torch.manual_seed(42)
AlexNetmodel.classifier = nn.Sequential(nn.Linear(9216, 1024),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(1024, 2))
AlexNetmodel
Como se puede ver originalmente la cabeza de la red (la parte llamada classifier) estaba configurada de 4096 neuronas a 1000 (que son las 1000 categorías de ImageNet). Probablemente esto sea demasiado para nuestro problema y nos puede llevar al overfitting, por lo tanto generamos algo bastante más simple. Además, esta modificación debe ser consistente con los tamaños de imágenes que estamos utilizando. En nuestro caso recibimos 9216 parámetros (una imagen de 36x36 con 256 filtros), se pasa por una ReLu como activación y un Dropout a modo de regularización para luego llegar a una capa de 1024 y la capa final.
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Linear(in_features=9216, out_features=1024, bias=True)
(1): ReLU()
(2): Dropout(p=0.4, inplace=False)
(3): Linear(in_features=1024, out_features=2, bias=True)
)
)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
AlexNetmodel = AlexNetmodel.to(device)
Como se puede ver, este modelo tiene varios más parámetros, alrededor de 9.5 millones, pero sólo entrenaremos aquellos de la capa densa.
cont = 0
for param in AlexNetmodel.classifier.parameters():
print(param.numel())
cont += param.numel()
cont
9437184
1024
2048
2
9440258
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(AlexNetmodel.classifier.parameters(), lr = 0.001)
train_loader = DataLoader(train_data, batch_size = 10, pin_memory = True, shuffle = True)
test_loader = DataLoader(test_data, batch_size = 10, pin_memory = True, shuffle = False)
import time
start_time = time.time()
epochs = 3
max_trn_batch = 800
max_tst_batch = 300
train_losses = []
test_losses = []
train_correct = []
test_correct = []
for i in range(epochs):
trn_corr = 0
tst_corr = 0
# Run the training batches
for b, (X_train, y_train) in enumerate(train_loader):
# if b == max_trn_batch:
# break
b+=1
# Apply the model
x,y = X_train.to(device), y_train.to(device)
y_pred = AlexNetmodel(x)
loss = criterion(y_pred, y)
# Tally the number of correct predictions
predicted = torch.max(y_pred.data, 1)[1]
batch_corr = (predicted == y).sum()
trn_corr += batch_corr
# Update parameters
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Print interim results
if b%200 == 0:
print(f'epoch: {i:2} batch: {b:4} [{10*b:6}/8000] loss: {loss.item():10.8f} \
accuracy: {trn_corr.item()*100/(10*b):7.3f}%')
train_losses.append(loss)
train_correct.append(trn_corr)
# Run the testing batches
with torch.no_grad():
for b, (X_test, y_test) in enumerate(test_loader):
# if b == max_tst_batch:
# break
x_t, y_t = X_test.to(device), y_test.to(device)
# Apply the model
y_val = AlexNetmodel(x_t)
# Tally the number of correct predictions
predicted = torch.max(y_val.data, 1)[1]
tst_corr += (predicted == y_t).sum()
loss = criterion(y_val, y_t)
test_losses.append(loss)
test_correct.append(tst_corr)
print(f'\nDuration: {time.time() - start_time:.0f} seconds') # print the time elapsed
epoch: 0 batch: 200 [ 2000/8000] loss: 0.12588477 accuracy: 89.500%
epoch: 0 batch: 400 [ 4000/8000] loss: 0.09032388 accuracy: 91.250%
epoch: 0 batch: 600 [ 6000/8000] loss: 0.26316878 accuracy: 91.900%
epoch: 0 batch: 800 [ 8000/8000] loss: 0.14361647 accuracy: 92.325%
epoch: 0 batch: 1000 [ 10000/8000] loss: 0.10198053 accuracy: 92.640%
epoch: 0 batch: 1200 [ 12000/8000] loss: 0.46762228 accuracy: 92.900%
epoch: 0 batch: 1400 [ 14000/8000] loss: 0.00291114 accuracy: 93.207%
epoch: 0 batch: 1600 [ 16000/8000] loss: 0.12340410 accuracy: 93.400%
epoch: 0 batch: 1800 [ 18000/8000] loss: 0.00000925 accuracy: 93.533%
epoch: 1 batch: 200 [ 2000/8000] loss: 0.38755649 accuracy: 94.750%
epoch: 1 batch: 400 [ 4000/8000] loss: 0.00076796 accuracy: 94.700%
epoch: 1 batch: 600 [ 6000/8000] loss: 0.06538789 accuracy: 94.417%
epoch: 1 batch: 800 [ 8000/8000] loss: 0.00010027 accuracy: 94.450%
epoch: 1 batch: 1000 [ 10000/8000] loss: 0.00033302 accuracy: 94.610%
epoch: 1 batch: 1200 [ 12000/8000] loss: 0.23096445 accuracy: 94.558%
epoch: 1 batch: 1400 [ 14000/8000] loss: 0.53282773 accuracy: 94.457%
epoch: 1 batch: 1600 [ 16000/8000] loss: 0.16338238 accuracy: 94.631%
epoch: 1 batch: 1800 [ 18000/8000] loss: 0.05234673 accuracy: 94.611%
epoch: 2 batch: 200 [ 2000/8000] loss: 0.05994357 accuracy: 95.400%
epoch: 2 batch: 400 [ 4000/8000] loss: 0.00032028 accuracy: 95.175%
epoch: 2 batch: 600 [ 6000/8000] loss: 0.00776298 accuracy: 95.050%
epoch: 2 batch: 800 [ 8000/8000] loss: 0.20413604 accuracy: 95.200%
epoch: 2 batch: 1000 [ 10000/8000] loss: 0.01127659 accuracy: 95.110%
epoch: 2 batch: 1200 [ 12000/8000] loss: 0.71031255 accuracy: 95.200%
epoch: 2 batch: 1400 [ 14000/8000] loss: 0.06394389 accuracy: 95.214%
epoch: 2 batch: 1600 [ 16000/8000] loss: 0.06476951 accuracy: 95.112%
epoch: 2 batch: 1800 [ 18000/8000] loss: 0.09471183 accuracy: 95.100%
Duration: 198 seconds
Como podemos ver acá se puede ver el poder de la RTX 3090. Estamos pasando casi 20 mil imágenes en batches de 10, y aún así tomá cerca de 200 segundos, poco más de 3 minutos. Realmente quedé bien sorprendido con el proceso de augmentation paralelizado en 12 cores y el traspaso a la GPU que por el uso de pin memory se hace bastante más rápido.
test_load_all = DataLoader(test_data, batch_size = len(test_data), shuffle = False)
with torch.no_grad():
correct = 0
for X_test, y_test in test_load_all:
x_t, y_t = X_test.to(device), y_test.to(device)
y_val = AlexNetmodel(x_t)
predicted = torch.max(y_val, 1)[1]
correct += (predicted == y_t).sum()
correct.item()/len(test_data)
0.9580867061270196
Como se puede ver el cambio es brutal, la mejora es clara. Análogamente, chequearemos como responde el modelo en Datos no vistos anteriormente (a.k.a mis mascotas). Además agregué algunos perros que dejaron en mi Linkedin que tendían a fallar y un Gato relativamente difícil de ver.
from mpl_toolkits.axes_grid1 import ImageGrid
def predict(model,image):
pic = test_transform(Image.open(image))
model.eval()
with torch.no_grad():
new_prediction = model(pic.view(1,3,224,224).to(device))
return class_names[new_prediction.argmax().item()]
def prediction_grid(model, image, r, c):
fig = plt.figure(1, (20., 20.))
grid = ImageGrid(fig, 111,
nrows_ncols=(r, c),
axes_pad=0.4,
)
for img, axes in zip(im_list,grid):
axes.set_title(f'{img} is a {predict(AlexNetmodel,img)}', fontdict=None, loc='center', color = "k")
axes.axis('off')
axes.imshow(Image.open(img))
return plt.show()
im_list = ['kira.jpg','kira2.jpg','kira3.jpg','kira4.jpg','kira5.jpg','kira6.jpg',
'coqui.jpg','nalita.jpg','stefanni.jpg','pitbull.jpg','another-cat.png','white_cat.jpg']
prediction_grid(AlexNetmodel, im_list,2,6)
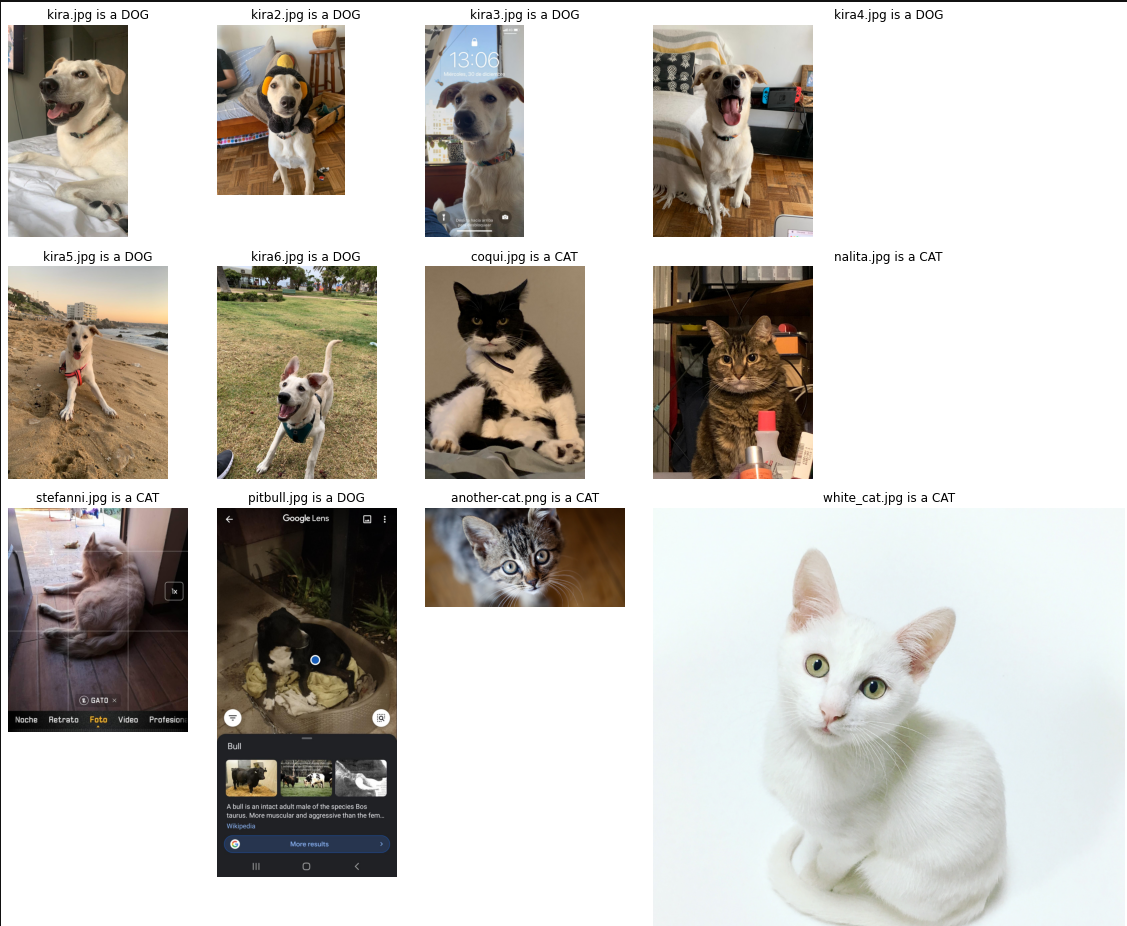
La verdad es que los resultados obtenidos con este modelo me dejan mucho más conforme. Pudimos mejorar la imagen en la que el modelo anterior fallaba. Mejoramos una imagen que me dieron que de hecho predecía como un toro. El gato blanco que es bien complejo de ver también funcionó bastante bien. El único caso que no funcionó tan bien fue el Perro de Stefanni. Tiendo a pensar que la razón es porque se está tapando gran parte de los rasgos de su cara que siento que deben ser claves para que el modelo prediga de manera correcta.
Ese fue el tutorial de hoy. Espero que hayan podido aprender harto. Yo al menos aprendí harto y me voy sintiendo cada vez más cómodo con Pytorch. Además, me voy muy conforme con la RTX 3090. A pesar de estar lidiando con imágenes muy pesadas no tuvo problemas para entrenar el modelo rápidamente.
Nos vemos a la próxima!!!