Github Basics y un poco más.
Github para Data Science

Si eres Data Scientist es muy probable que nunca hayas usado GIT/Github. No te culpo, no somos completamente desarrolladores y quizás muchos de ustedes (al igual que yo) ni siquiera tenemos un background en Ciencias de la Computación. Entonces la pregunta es, ¿Por qué deberíamos usarlo?
Github es una plataforma que permite almacenar código en la nube de manera que se pueda contribuir de manera colaborativa llevando un control de versiones. Es decir siempre puedes volver a distintos checkpoints de tu código en caso de introducir un bug y este deje de funcionar como se espera. De esta manera se puede llevar un orden de todos los progresos que se llevan pero sin miedo de romper algo que no se pueda deshacer.
Github está basado en GIT que es el software creado para llevar un control de versiones de un documento. Si bien es cierto GIT se puede utilizar para llevar registro de cualquier tipo de archivo, éste se ha popularizado para el desarrollo de software libre. Hoy en día no se puede ser desarrollador de software sin saber GIT/Github. Es por eso que para la ciencia de datos, que es un campo que cada vez más tiene que ver con el desarrollo de software se hace esencial saber lo básico y yo diría que un poquito más.

Lamentablemente, son pocos las personas que entienden a cabalidad como funciona GIT. Y como al final tiene tantos comandos (que muchas veces hay que correr en terminal), mucha gente le tiene mucho miedo y conoce los comandos básicos sin entenderlos. Incluso desarrolladores con mucha experiencia no llegan a entenderlo bien.

Con esto no quiero decir que haré una clase magistral de cómo usarlo, pero al menos tener la intuición más avanzada. No soy experto en GIT pero ya lo entiendo a un nivel que no me da miedo pensar que dejaré la embarrada y no podré solucionarlo.
Bueno, entonces ¿cómo usamos GIT? Yo creo que está lleno de tutoriales de cómo aprender a usarlo. Pero creo que lo mejor es entender cómo funciona con un ejemplo. Para ello voy a crear un Repositorio desde cero y mostrar cómo se trabaja con él.
Puedes seguir este Repo en el cual llevé a cabo todos los pasos mostrados.
Creando un Repo en Github.
Primero que todo tenemos que ir a nuestro perfil de Github y tenemos la opción de crear un Nuevo Repositorio:
En este caso este es mi página de inicio, y si se escoge la pestaña Repositories y clickeas en New, se llega a algo como esto:
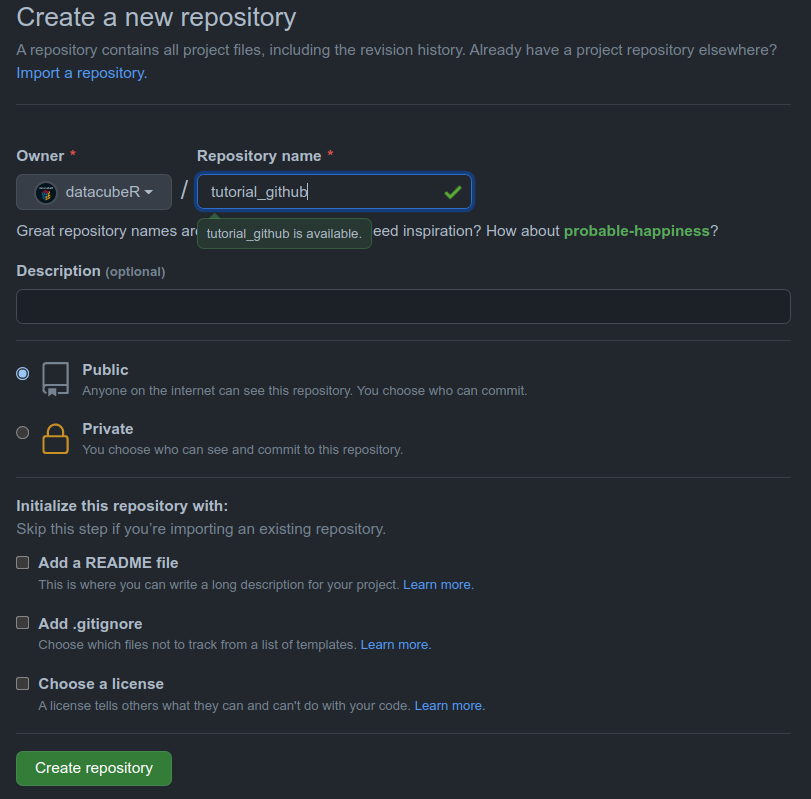
Cuando se es primera vez que se trabaja con Github, mi recomendación es sólo colocar el nombre (en este caso tutorial_github, dejarlo como un Repo Público y clickear en Create repository). La razón por la cual hacer esto es porque si se no se escoge nada para comenzar el repositorio el propio Github te entrega instrucciones de cómo continuar con el proceso.
Cuando un Repositorio es público implica que cualquier persona puede verlo. En caso de que haya código que no quieres que sea compartido con alguien más, entonces mi recomendación es dejarlo privado.
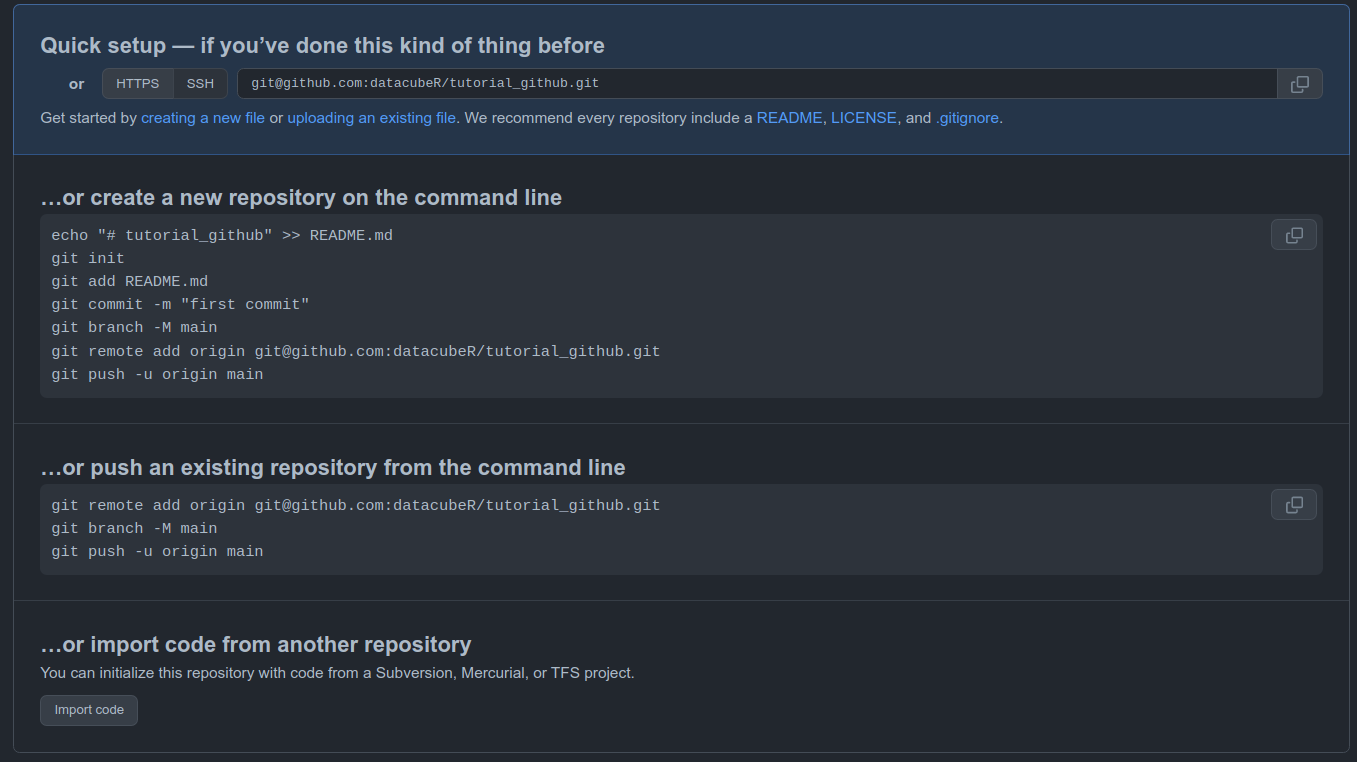
Al terminar la construcción del Repo nos entrega instrucciones a seguir para continuar con el proceso. Lo que acabamos de hacer es crear nuestro Repo Remoto, lo cual normalmente Github llama origin. Nuestro Repo remoto va a ser el backup que va a vivir en la Nube, específicamente en Github. Este remoto por sí solo no es útil, este debe ser sincronizado con nuestro Repo Local. Y un Repo Local no es más que una manera fancy de denominar una carpeta de nuestro computador. La diferencia es que esta carpeta va a ir siendo trackeada, y se guardaran todas las distintas versiones que nosotros queramos de nuestros documentos.
El control de versiones nos permitirá evitar carpetas llenas de múltiples copias de nuestro trabajo como esto:
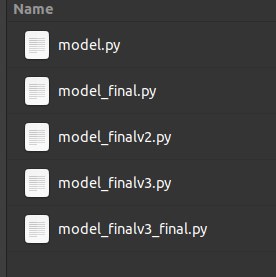
A continuación voy a ir mostrando el paso a paso en mi maquina con Ubuntu. Seguir estos pasos es exactamente igual en los distintos sistemas operativos. La ventaja de usar Ubuntu y en mi caso el Shell ZSH es que tiene algunos elementos que me ayudarán a entender mejor el estado de mi Repo.
Creando Nuestro Repo Local
Crear nuestro Repo Local es muy sencillo, sólo tienes que asegurarte de tener instalado GIT desde acá. Y en la carpeta de interés abre la línea de comandos y ejecuta:
$ git init
El comando git init lo único que hace es crear una carpeta oculta llamada .git que lo que hará es ir almacenando automáticamente distintas versiones de tus documentos.
Ahora nuestro Repo Local es la carpeta de trabajo que utilizaremos y se crea automáticamente la Rama Master que es como la versión oficial en la que trabajaremos:

Para seguir los comandos en Windows mi recomendación es usar Git Bash. Este es un shell que se instalará junto con GIT.
Pero para que este repo local, se sincronice con el Repo Remoto que tenemos en Github tenemos que ejecutar lo siguiente:
$ git remote add origin git@github.com:datacubeR/tutorial_github.git
donde git@github.com:datacubeR/tutorial_github.git corresponde a la localización de nuestro Repo Remoto. Github ofrece dos versiones para la localización del Repo: HTTPS y SSH. Mi recomendación es ir por la SSH ya que poco a poco Github está quitando soporte a la HTTPS. Además la versión SSH permite que cada vez que hagas commit y push no tengas que colocar tu clave de acceso, lo cual lo hace muy cómodo y de hecho es más seguro.
Si te interesa configurar Github con SSH te recomiendo el siguiente tutorial:
Esquema de trabajo en Github
Es tan popular el uso de Github que se han desarrollado distintas estrategias de trabajo para trabajar en él. Yo tuve la suerte de trabajar en Jooycar, que seguía bastantes buenas prácticas de desarrollo de software y pude aprender (siento que) bastante bien cómo trabajar con Github.
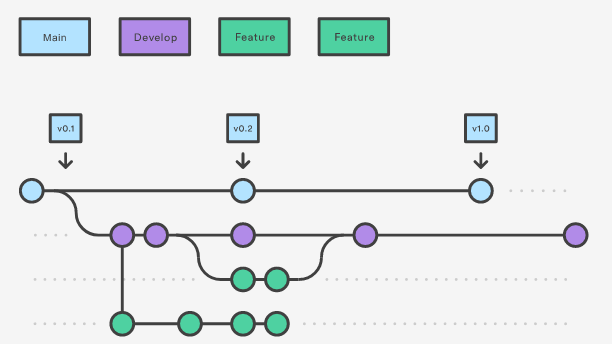
Básicamente la idea es seguir una lógica de Ramas, donde la Rama Master (recientemente renombrada main, pero yo y la mayoría sigue llamandola Master, porque suena más cool) es la versión principal de tu código. La idea que el código que vive en Master sea el código funcional, libre de bugs. Y cualquier trabajo se haga en ramas paralelas que no rompan Master. Una vez que las ramas paralelas (o de features) estén probadas y se sabe que funcionan como se esperan, se unirán a Master. En Github hay harta terminología que es importante entender antes de usarlo:
- Ramas: Son las distintas versiones del trabajo realizado. La rama principal es Master o Main.
- Ramas Secundarias: Versiones donde se realizan las pruebas y desarrollo nuevo para evitar romper Master.
- Commits: Corresponden a cada uno de los puntitos. Cada punto es un Save. Es decir por cada commits hay cambios en el código, pueden ser adiciones, sustracciones o modificaciones del código.
- Push: Se refiere a guardar nuestros commits locales en Github (en remoto).
Es importante que el tener una versión remota no es sólo para tener un respaldo en caso de que algo pase con tu maquina local, sino que para que todos tus compañeros puedan tener acceso al código. De esa manera se evitan esas malas prácticas de enviar un Notebook/Script por Slack o de copiar y pegar una línea de código.
Nuestro Primer Commit
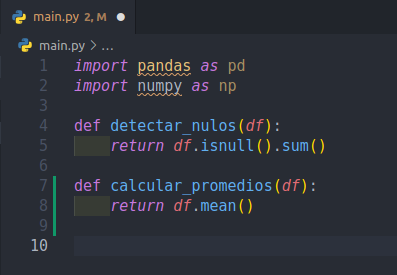
Para realizar el commit entonces es necesario hacer nuestros primeros cambios: Creemos entonces un archivo llamado main.py y creemos lo siguiente:
import pandas as pd
import numpy as np
def detectar_nulos(df):
return df.isnull().sum()
Luego entonces debemos utilizar los siguientes comandos:
$ git add .
Este comando agregará todos los archivos (punto equivale a todos los archivos en la carpeta actual) al Stage Area. Esta área se utiliza para indicarle a git cuáles son los archivos que van a ser parte del commit. Obviamente no es necesario juntarlos todos, pero es lo más común. También se puede usar git add para ir agregándo sólo los necesarios (pero normalmente todos los archivos modificados son parte del commit).
$ git status
git status nos dirá cuales son los archivos que están actualmente siendo trackeados.
$ git commit -m 'Mi primer Commit'
Finalmente git commit será el encargado de guardar una versión en GIT. Esta versión va a acompañada de un mensaje, el que indica en qué se trabajó durante dicho commit. De esta manera en caso de tener errores en el futuro y se quiera volver a versiones anteriores se tiene el comentario como referencia para encontrar el commit indicado.
Nuestro Primer Push
Para llevar el código a Github es necesario hacer un push:
$ git push
Es importante entender que este comando fallará la primera vez que se ejecute ya que GIT inicialmente no entiende con qué ramas remotas está sincronizado. Mi recomendación es que usar git push. Al fallar, Github indicará que no es el comando indicado (normalmente se agregan el nombre de la rama y unos flags) y te dirá cuál es el apropiado. Esto se debe hacer en el primer commit de cada rama. Luego de eso git push es suficiente.
Todos nuestros cambios se ven en Github de la siguiente forma:
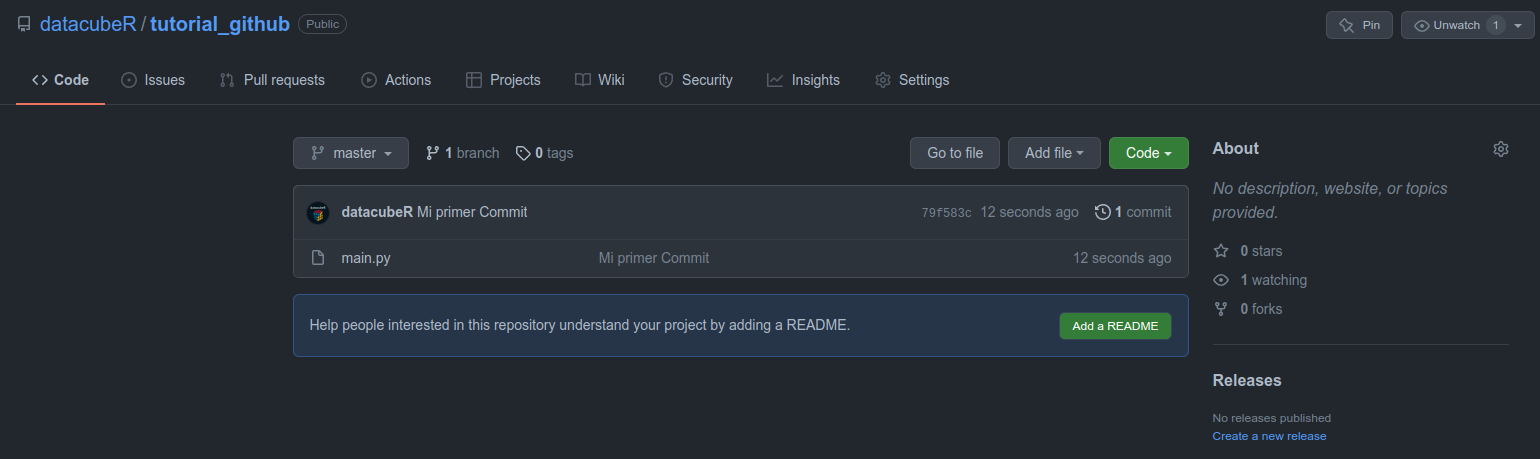
Normalmente esto es casi todo lo que cualquier persona que dice saber GIT efectivamente sabe. Quizás algunos dicen conocer git pull. Pero la verdad es que eso no es del todo cierto y voy a explicar git pull en detalle más adelante.
Trabajo en Ramas
Si bien es cierto siempre se puede ir trabajando en Master, esto constituye una muy mala práctica. Como hemos dicho anteriormente, se considera Master como la versión productiva del código. Por lo tanto, no puede ser alterado por nada que no sea por código debidamente probado. En el caso de trabajar en cualquier cosa que pudiera romper el código productivo (esto significa básicamente todo lo que no sea el código final), es necesario trabajar en Ramas.
$ git checkout -b nueva-rama
Este comando creará una nueva rama e inmediatamente se cambiará a ella. El flag -b es para indicar que la rama creada se llamará nueva-rama. Existen varias convenciones para el nombramiento de las nuevas ramas, normalmente se antepone un feature cuando se está trabajando en una nueva funcionalidad del código o hot-fix cuando se quiere solucionar rápidamente un bug encontrado en producción. Pero la verdad la convención de nombres va a depender del equipo. Lo importante es que el nombre de la rama sea representativo del trabajo realizado.
La rama corresponde a una versión paralela del código. Las buenas prácticas dicen que las nuevas ramas debieran salir principalmente de Master, pero siempre se pueden crear subramas que partan del trabajo realizado de un compañero. Entre más anidadas estén las ramas más complicado es volver a unirla en Master, por lo que si bien, es posible, se desaconseja en la medida de lo posible.
Al crear una rama, todo funciona igual, salvo que los commits se irán haciendo en la nueva rama, creando una historia alternativa a Master. En este caso cuando queramos hacer un push tendremos que definir la primera vez cuales es la rama correspondiente en Github.
Por ejemplo, supongamos una rama en la cual ahora creamos una segunda función:
Podemos actualizar nuestro Repo utilizando los comandos vistos anteriormente:
$ git add .
$ git commit -m 'Mi primer Commit en otra Rama'
$ git push --set-upstream origin nueva-rama
El resultado se verá en Github así:
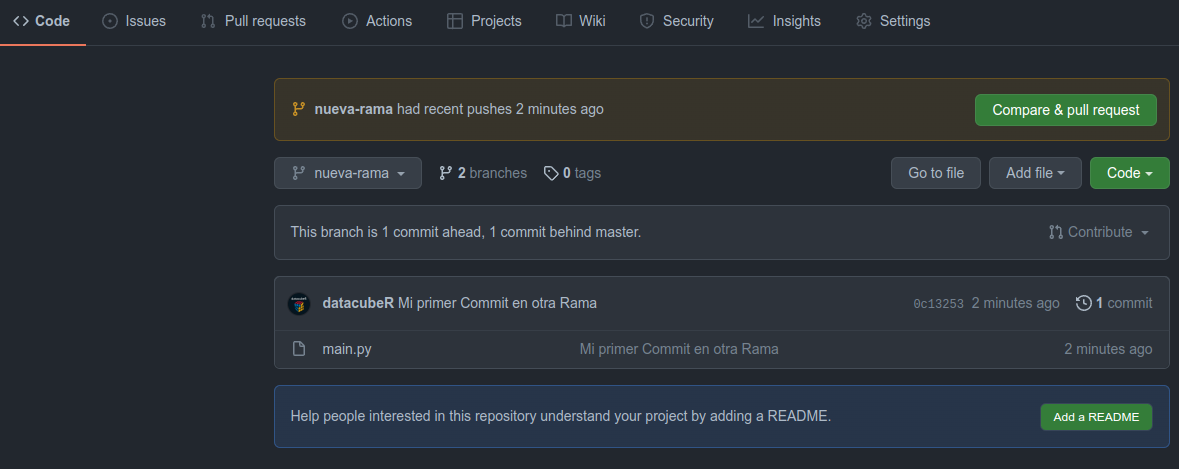
Apenas creemos un nuevo commit en una rama no Master, Github nos sugerirá que realicemos un Pull Request (PR para los amigos). Entender un Pull Request y todas las funcionalidades que tiene da para un artículo entero, pero en sencillo, un Pull Request es una instancia de revisión, en la que normalmente un Programador/Data Scientist con más experiencia, revisará el código (aunque también puede ser un par). De esta manera varios pares de ojos revisan que:
- No se introduzcan bugs a la rama productiva.
- Pueden sugerir mejores manera de abordar una solución.
- Pueden corregir y dar feedback del trabajo realizado.
Al crear el PR se debe colocar un título adhoc al trabajo realizado más una descripción. El PR tiene la posibilidad de ser comentado (para sugerir feedback), aprobado directamente en caso de no tener problemas, o se pueden solicitar cambios que deben ser realizados antes de la aprobación. En caso de que el PR no sea aprobado no podrá fusionarse con Master (en estricto rigor los settings por defecto de Github te dejan hacer el merge, pero no se debería).
En cualquier caso Github permite bloquear los push a Master permitiéndolos sólo mediante PRs aprobados, esta funcionalidad está disponible en todos los Repos Públicos, o en Repos Privados que sean Cuenta Pro o Enterprise
Realizando un Pull Request
Un Pull Request es una instancia iterativa de revisión. No es necesario abrir el PR cuando el trabajo está listo. De hecho, es mejor abrirlo apenas se comience con el trabajo. De esa manera los DS con más experiencia pueden ir mirando tu código sin necesidad de tener que agendar una reunión. De hecho, puedes pedir feedback, sugerencias, opiniones, etc.
Una vez abierto un Pull Request puedes seguir añadiendo commits con cada uno de los avances que vayas haciendo. Si seguimos el ejemplo, lo primero que debemos hacer es abrir el Pull Request. Se puede clickear directamente en el Compare & pull request o ir a la pestaña Pull Request y clickear en New Pull Request.
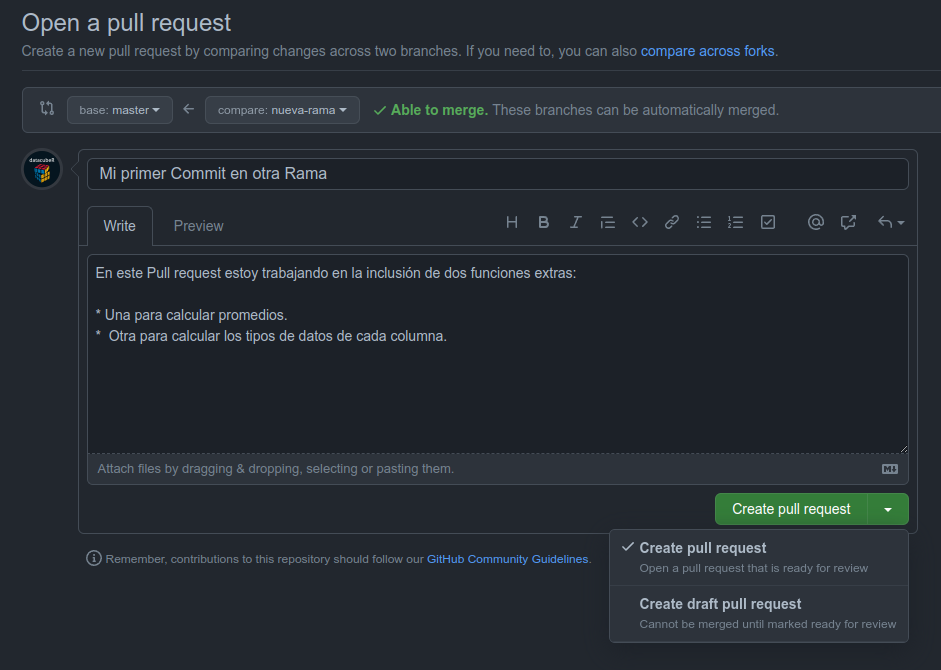
Como se puede ver, el PR se puede crear al clickear abajo. Esto significa que está listo para ser revisado. Pero además para Repos Públicos o Empresa, se tiene la opción Draft. Esto quiere decir que está en progreso. Y si bien se puede mirar el código y el progreso, no está listo para ser aprobado.
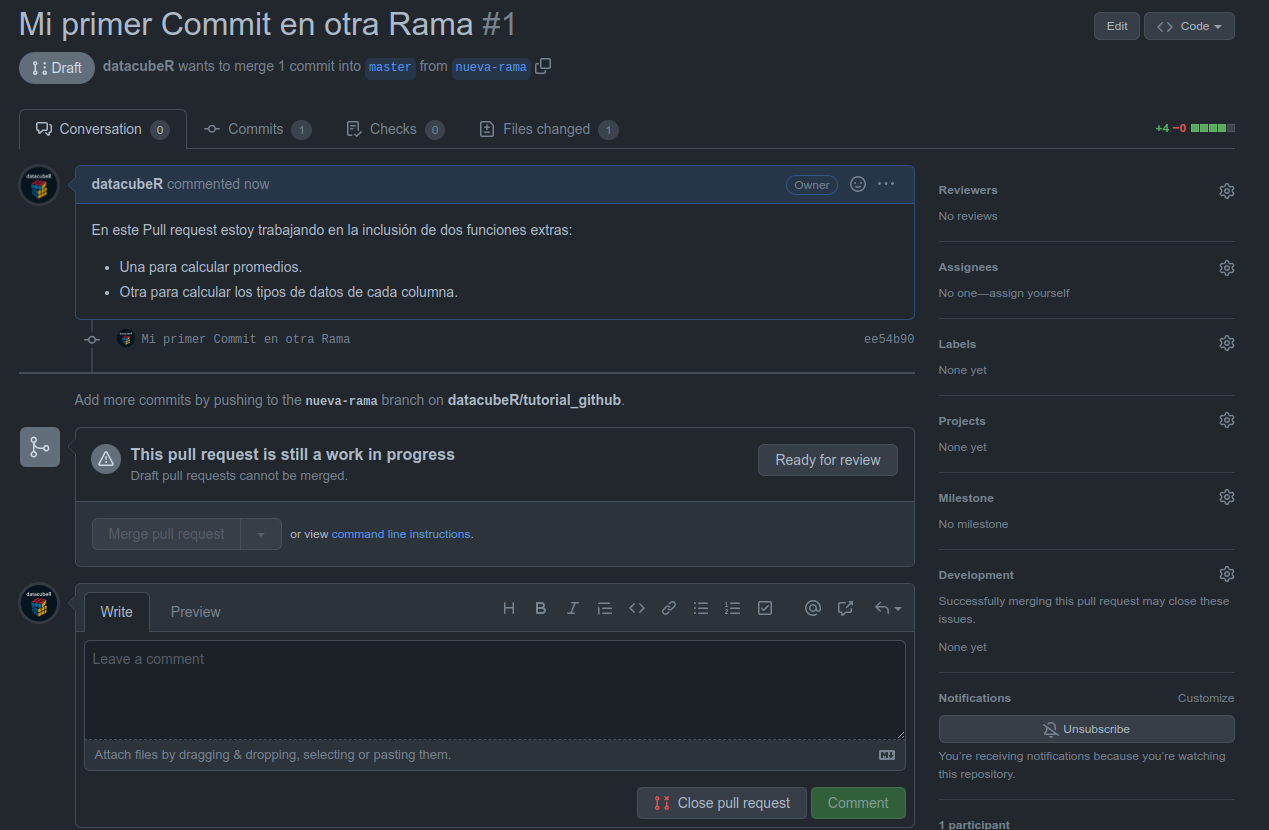
En este caso hice el PR como Draft, lo cual quiere decir que aún no está listo para ser revisado como se indica abajo. Adicionalmente Github permite colocar Reviewers, Labels, Proyectos e incluso Issues que permiten llevar mejor control del trabajo a realizar.
Entonces, siguiendo con el ejemplo el PR dice que haremos dos funciones. Nos falta una, la cual crearemos:
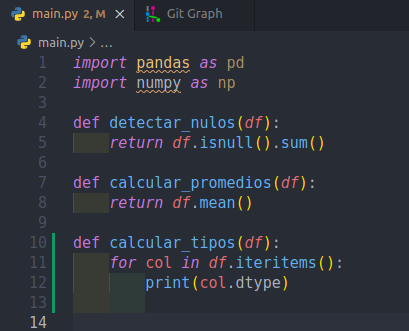
$ git add .
$ git commit -m 'Agrego la segunda función del PR'
$ git push
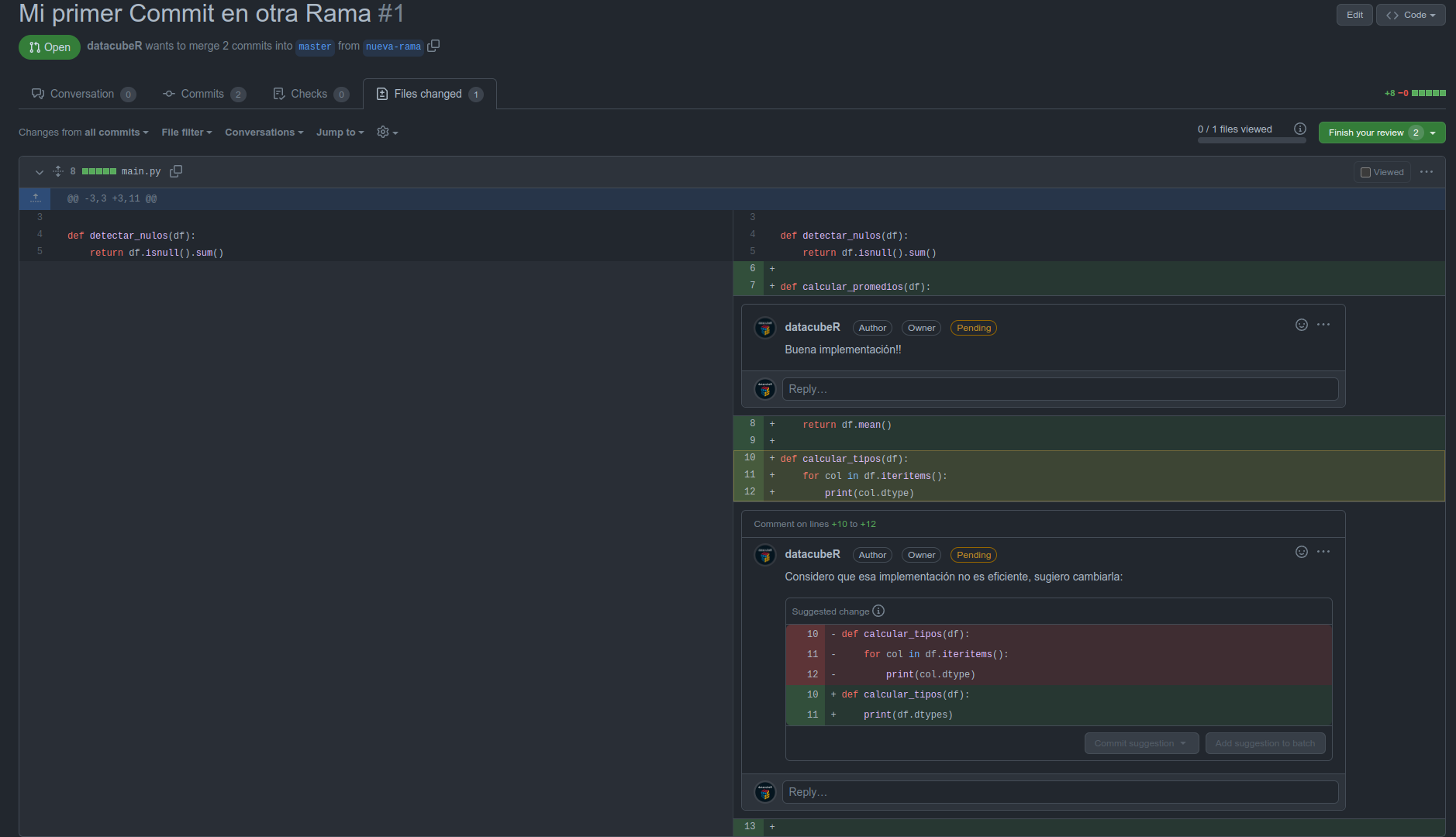
Suponiendo que ahora está listo el trabajo a realizar, pidamos entonces que el PR pase a revisión. Para ello clickeamos en Ready for Review y podemos asignar a alguien para revisión o pedirle de manera particular. Para ello el revisor debe ir a la pestaña Files Changed y se encontrará con algo así:
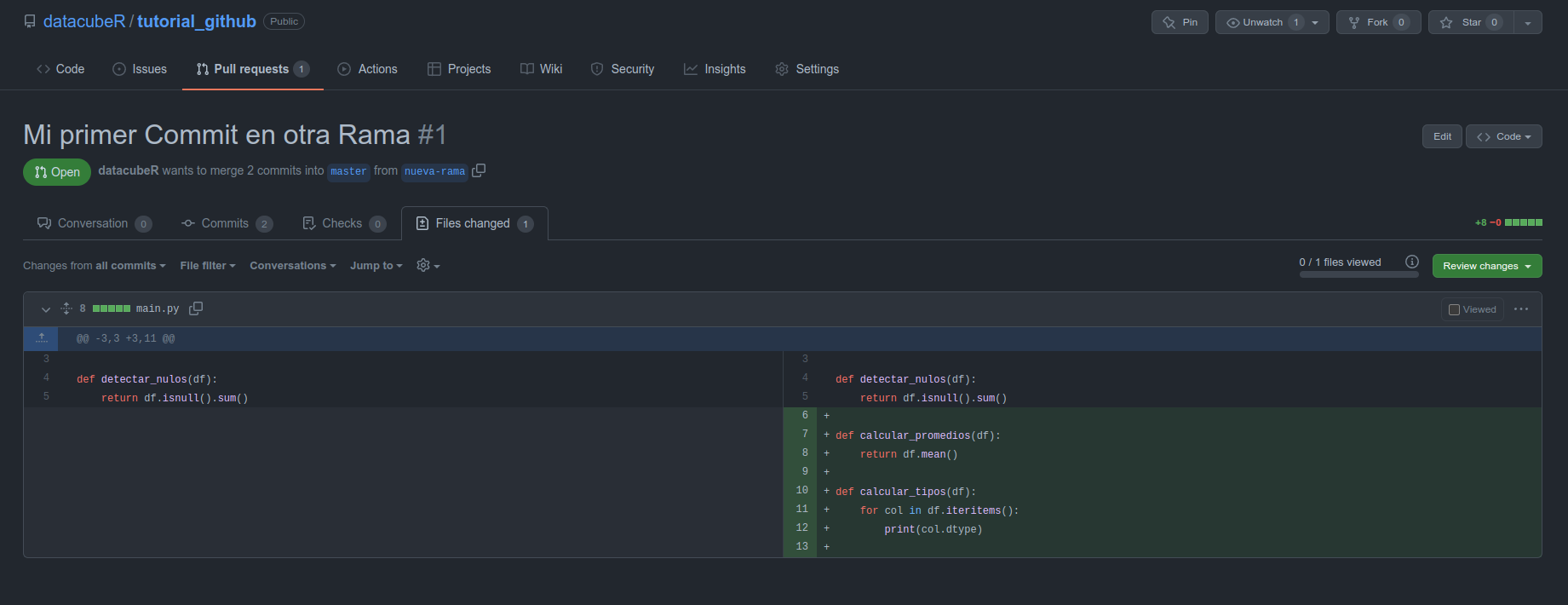
Al revisar podemos ir linea por línea agregando comentarios, o podemos agregar sugerencias como se ve en la línea 10-12. De esa manera, la persona puede sólo aceptar la sugerencia y hacer commit directamente, en vez de tener que realizar todo el cambio y volver a agregar el commit desde su Repo Local.
Al terminar la revisión se puede hacer click en Finish your review, y se tienen 3 opciones:
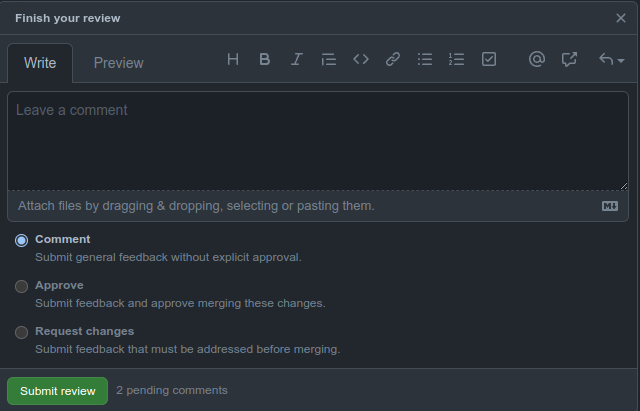
- Comment: Permite dar feedback.
- Approve: Indica que el código está correcto y listo para hacer merge.
- Request Changes: Implica que el código está incorrecto y no se va a aprobar hasta que se solucionen los comentarios dejados.
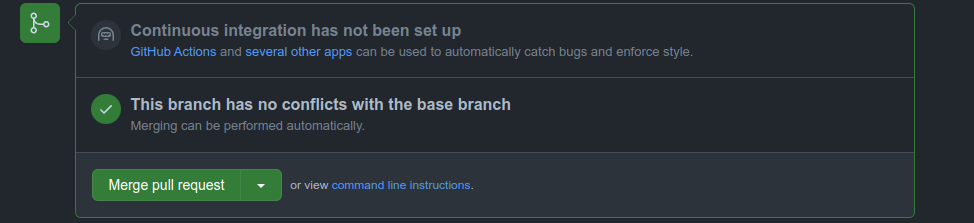
Una vez que el PR esté listo basta con cerrarlo haciendo Merge con Master:
Como se puede ver, acepté una de las sugerencias hechas en el PR, por lo tanto mi origin/master final queda de la siguiente manera:
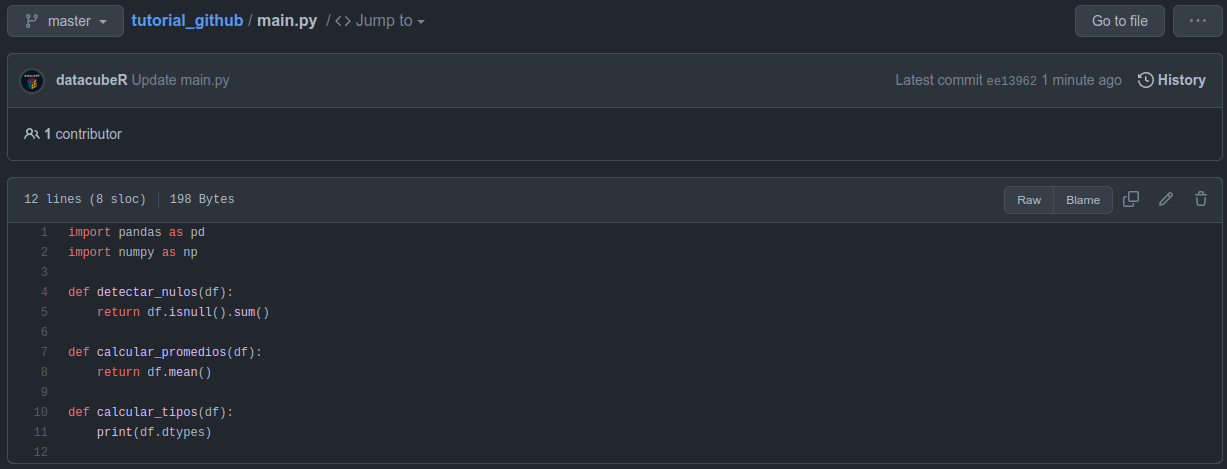
Tenemos las 3 funciones que nos interesan.
Sincronización del Repo Remoto con el Repo Local
Es común que varias personas trabajen en paralelo en un mismo proyecto. Por lo tanto puede pasar que distintos Data Scientist trabajen en distintos aspectos de dicho proyecto. Además como dijimos, todos los cambios tienen que ir haciéndose siempre en origin/master (la versión remota de master). Pero eso no necesariamente va a estar en nuestro computador local. Por lo tanto, debemos asegurarnos que tengamos nuestro master local al día. La mayoría utiliza git pull para hacer esto. Y no hay nada de malo, pero…
¿Sabías que hay dos estrategias de Pull, y es muy probable que la estrategia por defecto no sea la mejor para ti?
Si no quieres pensar nada, y no te interesa entender qué pasa en GIT usa git pull y no te cuestiones nada. Pero existe una segunda estrategia que se llama Rebase, que diferencia un usuario común de uno que entiende un poquito más de GIT.
git pull es un comando compuesto, es la mezcla entre un git fetch + git merge o git rebase dependiendo de cómo lo uses. git fetch básicamente le dice a Github dime qué tan diferente eres a lo que to tengo en mi Repo Local. Y en caso de que existan diferencias descarga esas diferencias y únelas en mi repo local. Ahora, para descargar esas diferencias hay dos posibilidades: una es usar git merge, que básicamente crea un commit extra (lo cual ensucia un poco Master ya que cada vez que exista un pull, voy a crear un commit más que la mayoría de las veces solo estorba en la historia del código). Existe una segunda alternativa que es git rebase. El cual se le conoce como ser un comando malvado que puede destruir tu código, pero la verdad es que si se entiende bien no hay nada que temer.

Básicamente lo que hace un Rebase es: toma tu rama y hace que comience al final de Master (o de la rama que tú desees), es decir, cambia la base (el punto de partida) al final de la rama especificada. Esto es útil no sólo para actualizar el Repo pero también para poder utilizar los cambios realizados en tu nueva rama.
En nuestro caso entonces, alguien hizo cambios en la rama nueva-rama y además aceptó la sugerencia de uno de los revisores durante el PR. Esto quiere decir que ninguno de estos cambios está actualizado en en nuestro repo local. Para ello entonces haremos:
$ git pull --rebase
El comando anterior debe hacerse en la rama base donde se pegaran los cambios, es decir, en nuestro caso primero hay que moverse a Master (git checkout master) y luego el git pull –rebase
Notar que se genera lo siguiente:
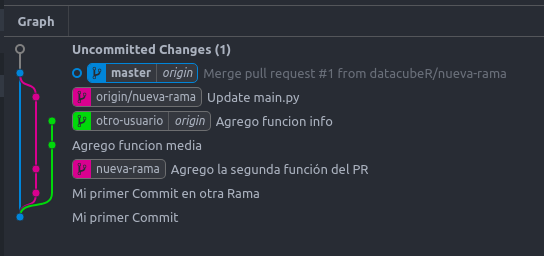
- origin/master que es la rama nueva se crea a continuación de Master, sin crear un commit extra.
- origin/master considera el merge de origin-nueva-rama que es la versión remota resultado del PR.
Podemos ver que ahora en nuestro Master Local tenemos lo mismo que en Github:
El temido conflicto
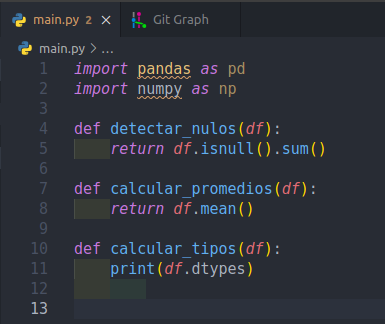
Supongamos ahora que hay otra rama llamada otro-usuario, que es el trabajo que otro DS está haciendo y que como se pudo ver anteriormente no incluye los cambios de origin/master (por ejemplo la sugerencia de código) ya que nace antes del merge.
El avance de este DS es el siguiente:
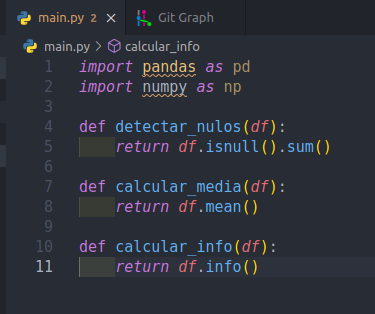
En un error de comunicación el nuevo DS modificó la segunda función y la llamó calcular_media. Además creó una tercera función llamada calcular_info que al parecer es más completa que calcular_tipos.
Entonces pasa de que quiero incluir esos cambios en mi rama. Es decir, quiero que mi rama (otro-usuario) comience luego de origin/master. En este caso haremos uso del rebase, pero no de git fetch (por lo tanto no usamos git pull --rebase). Por lo tanto haremos lo siguiente:
$ git checkout otro-usuario
$ git rebase origin/master
Lo que acabamos de hacer es cambiarnos a otro-usuario y decirle quiero que esta rama parta luego de origin/master. Si hacemos esto nos aparece el temido conflicto de GIT:
First, rewinding head to replay your work on top of it...
Applying: Agrego funcion media
Using index info to reconstruct a base tree...
M main.py
Falling back to patching base and 3-way merge...
Auto-merging main.py
CONFLICT (content): Merge conflict in main.py
error: Failed to merge in the changes.
Patch failed at 0001 Agrego funcion media
hint: Use 'git am --show-current-patch' to see the failed patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".

Tranquilo, porque un conflicto no es más que un malentendido. Ocurre cuando GIT no sabe qué hacer, y decide preguntarte a ti como programador qué código dejar y qué código no. Existen muchos add-ons para trabajar con conflictos. En mi opinión lo más sencillo es usar VSCode (espero que como Data Scientist lo uses ya que permite usar git, notebooks, scripts y montones de add-ins super útiles para programar mejor).
Si es que abres el archivo en cuestion (en nuestro caso el archivo en conflicto es main.py) en VSCode, o en su defecto hiciste el git rebase en la consola integrada de VSCode, verás algo así:
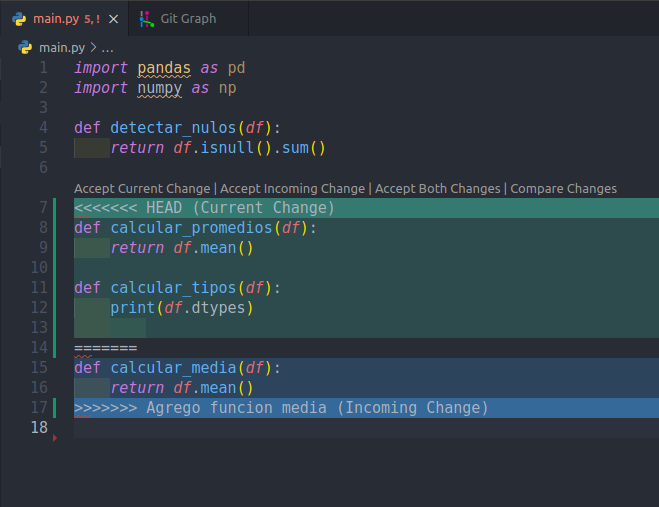
VSCode te deja solucionar el conflicto con un click. Basta con aceptar el Current Change en verde, o el Incoming Change en Azul.
Rebase generará a lo más N conflictos, donde N es el número de commits que tiene la rama a cambiar de base. Luego de solucionar cada conflicto se debe continuar el rebase usando git rebase --continue
Usando git status es posible ver lo siguiente:
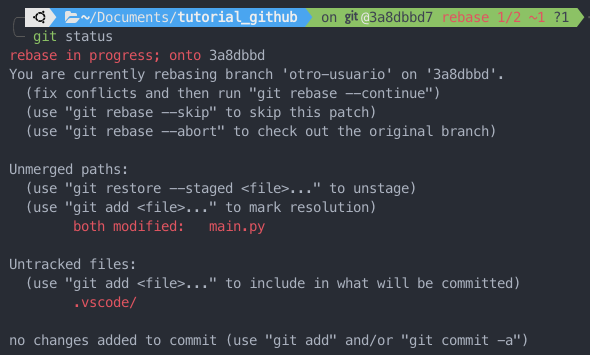
Nos indica que estamos en medio de un rebase. Y en mi caso, debido a que tengo ZSH, me dice que estoy en el primero de dos pasos de un Conflicto. Por lo tanto, en mi caso voy a aceptar el Incoming Change y guardar. Esto porque es el nombre nuevo que me gustaría que prevaleciera. Para guardar los cambios en GIT hacemos:
$ git add .
$ git rebase --continue
Al hacer este cambio, el segundo commit de otro-usuario nos dice, quizás se debería agregar la función calcular_info. Por lo tanto, nuevamente voy a aceptar el Incoming Change.
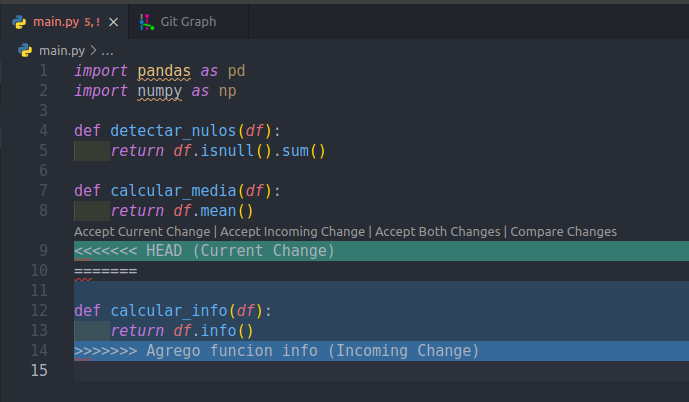
Repetimos el procedimiento anterior, guardando los cambios, y usando los comandos mostrados para obtener lo siguiente:
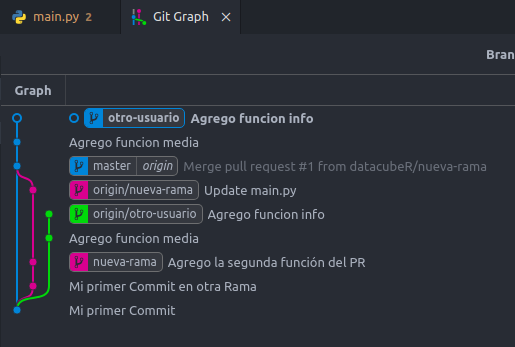
Entonces nuestra rama comienza al final de origin/master. Es importante recalcar, que en este caso desechamos los cambios producidos en el caso anterior, pero eventualmente uno podría querer dejar algunos elementos de la rama. Para eso VSCode permite alterar el archivo de manera manual (como un archivo de texto) sin utilizar los botones. De esa manera almacenamos todos los elementos que nos interesan independiente si vienen de Incoming o Current, de tal manera de hacer commits mixtos rescatando lo mejor de cada rama.
Otros aspectos importantes de GIT
README.md
Este es un archivo que puede ir en la raíz o en cada carpeta de tu Repo. Es un archivo markdown que normalmente se usa para especificar el contenido del repo. Debido a que utilizar Markdown, el contenido queda bien bonito. En este caso el README.md se ve así:
El archivo .gitignore
Este archivo es una configuración de GIT que nos permitirá no llevar registro de elementos que no nos interesan. Algunos de esos elementos son:
- data: GIT no está hecho para eso y va a reclamar si se intentan commitear archivos muy grandes. Para llevar registro de data es mejor usar herramientas como DVC.
- ambientes virtuales: No es buena idea porque las librerías de Python pueden ser pesadas (Por ejemplo Pytorch es 0.5GB+). Si se sugiere un requierements.txt.
- __pycache__ o .ipynbcheckpoints: Estos son archivos que se generan al ejecutar scripts o notebooks y no vale la pena trackearlos.
En caso de querer una lista exhaustiva de archivos que no vale la pena trackear en proyectos de Python pueden ir acá.
Notebooks
GIT está hecho para tracker archivos de texto, y si bien un notebook es un JSON, que sigue siendo texto, tiene mucha basura que impide chequear bien el código. Es más, si dos usuarios ejecutan celdas de manera distinta se puede incluso inducir conflictos. Mi recomendación es trackearlo, pero sólo como respaldo, el contenido del código debiera ser revisado en scripts.
¿Cuándo Commitear y Pushear?
Esto es medio polémico, porque GIT nació como una herramienta de desarrollo, y la programación de un Developer y de un Data Scientist no es igual. Mi Rule of Thumb 👍 diría:
- Commit cada vez que termines código funcional (al menos que corra, aunque no está la funcionalidad completamente terminada).
- Push al menos una vez al día.
- PR inmediatamente al abrir una rama para que pueda ser revisado. Y esto lo digo no como una estrategia de micro-management, sino para recibir feedback y poder dar hacer preguntas más fáciles.
Por ejemplo Github permite hacer algo así:
Acá comparto la definición de la función detectar_nulos compartiendo el permalink. De esta manera pueden compartir código, preguntar por algo en específico, pedir revisión, sugerencias, etc.
Espero entonces este tutorial sea de ayuda para poder trabajar como corresponde, usando mejores prácticas y llevando un mejor orden y control de su código.

Nos vemos a la otra,