Otro invento de Facebook
Hydra: Automatización y Flexibilidad en Ciencia de Datos.
Soy un fanático de la automatización. No hay nada más reconfortante que construir un código tan flexible que permita resolver muchos problemas a la vez. Hydra, es otro framework del grupo de Research de Facebook que viene a ayudar en este tipo de tareas. Si bien fue creado específicamente para configuraciones de Modelos de Machine Learning, puede ayudar en mucho más…
En este tutorial, la verdad no tan quick, me gustaría explicar las ventajas que tiene utilizar archivos de configuración.
Supongamos el siguiente problema (ficticio, porque no uso datos reales, pero real, porque esto suele pasar en cualquier equipo de Data Science):
- Tenemos un Reporte.
- La generación del reporte se hace conectándose a un base de datos por medio de
SQLAlchemya una base de datos. En mi caso, una AWS Aurora con backend Postgres. - En esta base tengo alojada una tabla (en este caso es el dataset Iris).
- Con
pandasejecuto una query. Posteriormente hago algunas transformaciones básicas (en este caso sólo filtraré por dos campos) y exportaré el resultado a un archivo csv.
Sé que podría hacer el filtrado directamente en la Query desde Aurora. Mi punto acá es mostrar que nos conectamos a una BD, hacemos modificaciones y generamos un reporte, típico caso de automatización.
Bueno, este problema se puede resolver de manera muy sencilla así:
# importamos librerías
from sqlalchemy import create_engine
import pandas as pd
name = 'aurora_user'
db = 'db_aurora'
host = 'this_is_my_aurora_cluster.rds.amazonaws.com'
port = 5432 #típico postgres
password = 'very_secure_password'
#conexión base de datos
engine = create_engine(f'postgres://{name}:{password}@{host}:{port}/{db}')
#generación del repore
def pull_report(query, value1, value2):
df = pd.read_sql(query, con = engine)
return df.query('petal_length > @value1 and `class` == @value2').to_csv('output.csv', index = False)
if __name__ == '__main__':
valor = 7
clase = 'Iris-virginica'
query = 'select * from iris;'
pull_report(query, valor, clase)
Solución eficiente, rápida y ordenada que lo único que hace es llamar la tabla iris, filtrar todos los elementos de clase Virginica con petal_length > 7. Pero, que si la miramos bien, tiene algunos problemas:
- No es una buena idea colocar las credenciales en el código, Información Confidencial.
- ¿Qué pasa si quiero cambiar los parámetros valor, clase o hasta la query? Voy a tener que entrar al archivo cambiarlos y ejecutar. No es una buena idea.
- ¿A quién no le ha pasado que corre un reporte y no se acuerda qué parámetros usó la última vez? Muchas veces no recordamos ni siquiera cuándo lo ejecutamos.
- Y, ¿A quién no le ha pasado de tener la carpeta del código plagado de outputs, en el mejor de los casos, con algún diferenciador como un
_v2o una fecha. Otras veces, sobreescribiendo archivos antiguos por el desorden de hacer las cosas rápido?
Si a ti no te ha pasado te felicito, porque probablemente sigues buenas prácticas. Pero creo que todo buen Data Scientist, ha cometido este tipo de errores. Y es porque en mi experiencia, he visto pocos equipos que usan herramientas como git para el control de versiones o que siguen buenas prácticas de automatización. Normalmente, los Data Scientists que conozco (que son hartos) venimos de cualquier trasfondo menos Informático/Computer Science.
Hay varias formas de solucionar esto. Una primera forma que se me ocurre es utilizar los salvadores sys.argv. El problema de esto es que uno nunca sabe qué parámetro está rellenado. Y además no soluciona varios de los problemas mencionados. Otra opción es crear alguna app de Línea de Comando (CLI) usando Typer (es una tremenda librería creada por tiangolo, creador de FastAPI. Si no la conocen échenle un vistazo). Pero quizás es mucho trabajo para algo que queremos solucionar relativamente rápido.
Ahí es donde entra Hydra. Este Framework está pensado especialmente para generar archivos de configuración en modelos de Machine Learning. El que haya modelado como Dios manda sabrá cuantas configuraciones distintas hay que probar antes de llegar con el mejor modelo. Y eso sí es un caos.
pip install hydra-core --upgrade
Archivos de Configuración
Hydra usa el paradigma de archivos de configuración. Primero que todo crearemos un directorio de trabajo de la siguiente manera:
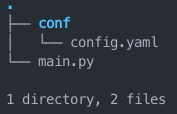
Hydra considera conf/config.yaml un archivo de configuración en formato yaml. Este es un formato jerárquico (que se aprende en 15 segundos, lo único que hay que saber es que la indentación es con dos espacios y ya!! Sabes yaml). En el cual se construye una configuración como esta:
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
La verdad es que no es necesario crear la carpeta conf. Pero más adelante se mostrarán los beneficios de tener los archivos de configuración en carpetas apartes.
Al utilizar Hydra hay que hacer pequeñas modificaciones a nuestro código para que ahora sea compatible con nuestro archivo de configuración:
import pandas as pd
import hydra
from omegaconf import DictConfig
from sqlalchemy import create_engine
@hydra.main(config_path='conf', config_name='config')
def pull_report(cnfg: DictConfig):
name = cnfg['name']
db = cnfg['db']
host = cnfg['host']
port = cnfg.port
password = cnfg.password
engine = create_engine(f'postgres://{name}:{password}@{host}:{port}/{db}')
value1 = 7
value2 = 'Iris-virginica'
query = 'select * from iris;'
df = pd.read_sql(query, con = engine)
df.query('petal_length > @value1 and `class` == @value2').to_csv('output.csv', index = False)
if __name__ == '__main__':
pull_report()
print('Reporte Terminado!!')
Hydra permite utilizar la notación [’’] o la de punto (que prefiero por requerir menos caracteres). Como se puede ver lo único que se necesita es:
- Importar hydra e incluir el decorador
@hydra.maindefiniendo la carpeta y el nombre del archivo (ojo, no se incluye el .yaml). - Desde
Omegaconf(que es una librería creada por el mismo creador deHydray que se instala en conjunto) se debe importar DictConfig, el cual se debe agregar como argumento a la función utilizando Type Hints. - Luego se pueden llamar todos los elementos del archivo de configuración desde dentro de la función decorada.
- La función decorada no contiene parámetros.
Jerarquías
Adicionalmente, Hydra permite crear jerarquías. De esta manera se pueden diferenciar usos para los parámetros. Por ejemplo:
aurora:
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
report:
query: 'select * from iris;'
value1: 7
value2: Iris-virginica
Con esta configuración se puede entender claramente que name, db, host, port y password son valores válidos para aurora, mientras que report contiene valores del reporte propiamente tal: los valores a filtrar y la query a ejecutar.
import pandas as pd
import hydra
from omegaconf import DictConfig
from sqlalchemy import create_engine
@hydra.main(config_path='conf', config_name='config')
def pull_report(cnfg: DictConfig):
name = cnfg.aurora.name
db = cnfg.aurora.db
host = cnfg.aurora.host
port = cnfg.aurora.port
password = cnfg.aurora.password
engine = create_engine(f'postgres://{name}:{password}@{host}:{port}/{db}')
value1 = cnfg.report.value1
value2 = cnfg.report.value2
query = cnfg.report.query
df = pd.read_sql(query, con = engine)
df.query('petal_length > @value1 and `class` == @value2').to_csv('output.csv', index = False)
if __name__ == '__main__':
pull_report()
print('Reporte Terminado!!')
Ejecución de un Script
Basta con ejecutar lo siguiente:
python main.py
Con esto Hydra ejecutará el archivo rescatando todos los valores desde conf/config.yaml. Pero además hará muchas otras cosas:
- Creará por defecto una carpeta llamada outputs con una una subcarpeta con la fecha de ejecución y otra subcarpeta con la hora.
Hydraes tan inteligente que irá almacenando las carpetas por día y por ejecución según corresponda (sin crear carpetas repetidas). - Agregará un
.logque en el caso de usar algún tipo de logging quedará registrado ahí. - En cada ejecución agregará una carpeta
.hydrala cual contendrá la configuración de Hydra (esto da para un tutorial entero), un archivo de overrides y la configuración utilizada que considerará los overrides (para dicha ejecución).
Ahora, qué es un override. Es un cambio que se hace a la configuración. Por ejemplo:
python main.py +report.value1=8
Esto generará un cambio en la configuración. value1 ahora será 8, por lo tanto fácilmente puedo crear un reporte con cambios adhoc sin tener que entrar a modificar nada a los archivos.
Y en caso que no te acuerdes de qué opciones existen se puede usar:
python main.py --help
python main.py --cfg jobs
Como dicen los gringos: Pretty Cool huh!!.
Pero esto es sólo el principio.
Interpolación
Hydra permite interpolar valores:
aurora:
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
report:
query: 'select * from iris;'
value1: 7
value2: Iris-virginica
file:
output_name: "output_by_${aurora.name}_${now:%d%m%y}.csv"
La notación \${} permitirá reemplazar por campos definidos dentro del mismo archivo de configuración. O usar algunos aspectos especiales como \${now:%d%m%y} que permite extraer la fecha utilizando strftime.
Invocar funciones.
Siento que Hydra te fuerza a seguir buenas prácticas de programación: como la modularización. No sé si se logra apreciar, pero siento que el código es poco entendible y hay partes que pueden abstraerse. Para ello, voy a generar un módulo llamado utils.py:
from sqlalchemy import create_engine
def connect(name, password, host, port, db):
return create_engine(f'postgres://{name}:{password}@{host}:{port}/{db}')
Una de las cosas más espectaculares de Hydra es que permite invocar funciones y darle parámetros desde la configuración. Para ello podemos hacer lo siguiente:
connect_f:
_target_: main.connect
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
report:
query: 'select * from iris;'
value1: 7
value2: Iris-virginica
file:
output_name: "output_by_${connect_f.name}_${now:%d%m%y}.csv"
Notar que ahora cambié la configuración de aurora por una que se llama connect_f. Esto invocará la función connect en el archivo main.py y la llenará con todos los parámetros dados. Ahora nuestro código puede ser optimizado de la siguiente manera:
from sqlalchemy import create_engine
def connect(name, password, host, port, db):
return create_engine(f'postgres://{name}:{password}@{host}:{port}/{db}')
import pandas as pd
import hydra
from omegaconf import DictConfig
from utils import connect
@hydra.main(config_path='conf', config_name='config')
def pull_report(cnfg: DictConfig):
# llamado a la funcion connect con
# todos los argumentos dados en la configuración
engine = hydra.utils.call(cnfg.connect_f)
value1 = cnfg.report.value1
value2 = cnfg.report.value2
query = cnfg.report.query
df = pd.read_sql(query, con = engine)
df.query('petal_length > @value1 and `class` == @value2').to_csv(cnfg.file.output_name, index = False)
if __name__ == '__main__':
pull_report()
print('Reporte Terminado!!')
Instanciar clases
Además, podría querer que el reporte detectara y avisara quien lo está ejecutando. Por ejemplo con el nombre utilizado en la conexión. Para ello voy a crear una clase de la siguiente manera:
from sqlalchemy import create_engine
class Connect:
def __init__(self, name, db, host, port, password):
self.name = name
self.db = db
self.host = host
self.port = port
self.password = password
def hola(self):
print(f'Hello {self.name}, Bienvenido a {self.db}!!')
def connect(self):
self.hola()
return create_engine(f'postgres://{self.name}:{self.password}@{self.host}:{self.port}/{self.db}')
Luego modifico mi archivo de configuración, llamando mi configuración connect_c (sólo para que se entienda que ahora es una clase):
connect_c:
_target_: main.Connect
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
report:
query: 'select * from iris;'
value1: 7
value2: Iris-virginica
file:
output_name: "output_by_${connect_c.name}_${now:%d%m%y}.csv"
Finalmente el código quedará así:
import pandas as pd
import hydra
from omegaconf import DictConfig
from utils import Connect
@hydra.main(config_path='conf', config_name='config')
def pull_report(cnfg: DictConfig):
connection = hydra.utils.instantiate(cnfg.connect_c)
engine = connection.connect()
value1 = cnfg.report.value1
value2 = cnfg.report.value2
query = cnfg.report.query
df = pd.read_sql(query, con = engine)
df.query('petal_length > @value1 and `class` == @value2').to_csv(cnfg.file.output_name, index = False)
if __name__ == '__main__':
pull_report()
print('Reporte Terminado!!')
Código Variable
Esta sí que es el Ultimate Feature de Hydra. Es tanta la flexibilidad que este framework permite, que incluso podemos crear reportes distintos que siguen un procedimiento similar creando configuraciones paralelas. Supongamos que cambiamos la estructura de nuestro proyecto a lo siguiente:

Ahora decidí que tengo dos configuraciones: una en mi base Aurora y otra en mi Data Warehouse Redshift. Ambos con distintos ejemplos de uso y como se puede ver son una subcarpeta de conf llamada db (notar la ventaja de haber organizado todo en una carpeta de configuración). El caso de Aurora es el reporte que estamos haciendo hasta ahora y que se exporta en formato csv. En el caso de Redshift, se utilizará otra query que llamará datos que se filtrarán en Redshift y se exportarán a un formato xlsx.
En este caso conf/config.yaml será la configuración en común que habrá para ambos reportes.
file:
output_name: "output_${db.name}_${now:%d%m%y}.${db.ext}"
- file contendrá la información referente al output del archivo, el cual incluirá en su nombre la base de datos que voy a utilizar, la fecha en la que lo voy a ejecutar y la extensión que tendrá el reporte. Hay que notar que la extensión se obtendrá desde la configuración db que utilice.
Por otra parte mi archivo conf/db/aurora.yaml contendrá las configuraciones que corresponden a Aurora:
name: aurora
ext: csv
connect:
_target_: main.ConnectAurora
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
query: 'select * from iris;'
value1: 7
value2: Iris-virginica
Como se puede ver agregué name que será el nombre de la configuración y ext que será la extensión del archivo de salida. Ambos elementos están siendo llamados desde la configuración inicial para construir el nombre del archivo de salida.
Luego connect, será la configuración de la clase ConnectAurora (la cual definiré más adelante). Esta clase corresponderá a los distintos pasos que necesito para llevar a cabo el reporte asociado a Aurora. Y los valores bajo ella serán todos los argumentos utilizados al momento de instanciar la clase.
De acuerdo a esta configuración generaré ConnectAurora en utils.py de la siguiente manera:
from sqlalchemy import create_engine
import pandas as pd
class ConnectAurora:
def __init__(self, name, db, host, port, password, query, value1 = None, value2 = None):
self.name = name
self.db = db
self.host = host
self.port = port
self.password = password
self.value1 = value1
self.value2 = value2
self.query = query
def hola(self):
print(f'Hello {self.name}, Bienvenido a {self.db}!!')
def connect(self):
self.engine = create_engine(f'postgres://{self.name}:{self.password}@{self.host}:{self.port}/{self.db}')
def report(self, output):
self.hola()
self.connect()
df = pd.read_sql(self.query, con = self.engine)
value1 = self.value1
value2 = self.value2
df.query('petal_length > @value1 and `class` == @value2').to_csv(output, index = False)
- __init__() será el constructor, en el que utilizaré todos los argumentos de configuración para instanciar la clase y además los dejaré como elementos internos de ella.
- hola() será un método que basicamente saluda a quién se está conectando. Sólo a modo de ejemplo para utilizar algunos de los valores de la configuración.
- connect() será un método que genera la conexión a la base de datos, en este caso Aurora.
- report(output) será la función que saluda, conecta y genera el reporte.
- Realizará una query en aurora según configuración.
- Filtrará por los valores dados.
- Exportará a CSV.
Ahora, ¿Tenemos que definir toda una clase para el reporte en Redshift? La verdad es que no. Dado que los reportes son similares podemos hacer uso de la propiedad de herencia para solo modificar los métodos que cambian y reutilizar código:
class ConnectRedshift(ConnectAurora):
def connect(self):
self.engine = create_engine(f'postgres+psycopg2://{self.name}:{self.password}@{self.host}:{self.port}/{self.db}')
def report(self,output):
self.hola()
self.connect()
df = pd.read_sql(self.query, con = self.engine)
df.to_excel(output, index = False)
Notar que en este caso al crear la clase ConnectRedshift, ésta hereda de ConnectAurora. Por lo tanto:
- __init__() y hola() serán igual a la clase madre.
- connect() es distinta ya que la conexión cambia debido a que se está conectando a otra Base de Datos.
- report(output) también cambia debido a que el reporte es distinto. En este caso:
- Leo una query directo de la base de datos.
- Exporto a Excel en vez de CSV.
Además, en este caso la configuración asociada también es distinta:
name: redshift
ext: xlsx
connect:
_target_: main.ConnectRedshift
name: redshift_user
db: db_redshift
host: this_is_my_redshift_cluster.rds.amazonaws.com
port: 5432
password: another_very_secure_password
query: "select firstname, lastname, email from users where ${db.connect.value1}=true;"
value1: likesports
En esta configuración también incluyop el nombre de la configuración y la extensión, pero la clase es ConnectRedshift. Y si bien, tiene parámetros de conexión iguales cuenta con la query y sólo value1 que de hecho es parte de la query y representa el campo a filtrar (en este caso si le gustan los deportes, pero hay otras opciones como si le gusta el jazz, el teatro, etc.).
Finalmente, main.py es único y funcionará para cualquiera de las dos configuraciones que se usen:
import hydra
from hydra.utils import instantiate
from omegaconf import DictConfig
from utils import ConnectAurora, ConnectRedshift
@hydra.main(config_path='conf', config_name='config')
def pull_report(cnfg: DictConfig):
connection = instantiate(cnfg.db.connect)
engine = connection.report(cnfg.file.output_name)
if __name__ == '__main__':
pull_report()
print('Reporte Terminado!!')
Como se puede ver ahora pull_report() sólo tiene dos líneas:
- Una que instancia la clase correspondiente según configuración.
- Y otra que ejecuta el reporte agregando el nombre que se le quiere dar el reporte también según configuración.
Finalmente si queremos ejecutar el reporte tendremos que hacer un override indicando que configuración ejecutar:
python main.py +db=aurora
Hello aurora_user
Reporte Terminado!!
O si nos interesa Redshift:
python main.py +db=redshift
Hello redshift_user
Reporte Terminado!!
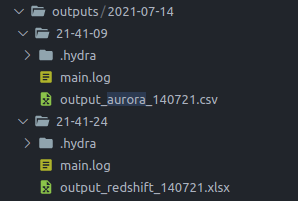
Como se puede ver se creó la carpeta outputs que en su interior la carpeta 2021-07-14 que es la fecha en la que hice las pruebas para esta ejecución. En el interior de esa carpeta hay dos subcarpetas:
- 21-49-09: Es la hora 21:49:09 (se utilizan
-porque creo que no se puede usar:en el nombre de una carpeta) y como se puede ver, tiene la carpeta de configuración, el log y además el output en csv, por lo tanto, se trata de una ejecución en aurora, lo cual también se puede comprobar en el archivo de configuración.
file:
output_name: output_${db.name}_${now:%d%m%y}.${db.ext}
db:
name: aurora
ext: csv
connect:
_target_: main.ConnectAurora
name: aurora_user
db: db_aurora
host: this_is_my_aurora_cluster.rds.amazonaws.com
port: 5432
password: very_secure_password
query: 'select * from iris;'
value1: 7
value2: Iris-virginica
- 21-41-24: Corresponde a la hora en la que ejecuté otro proceso pero con configuración redshift. Por eso en este caso el output es .xlsx y se puede chequear en la configuración utilizada.
file:
output_name: output_${db.name}_${now:%d%m%y}.${db.ext}
db:
name: redshift
ext: xlsx
connect:
_target_: main.ConnectRedshift
name: redshift_user
db: db_redshift
host: this_is_my_redshift_cluster.rds.amazonaws.com
port: 5432
password: another_very_secure_password
query: 'select firstname, lastname, email from users where ${db.connect.value1}=true;'
value1: likesports
Espero se pueda apreciar lo poderosa que es esta librería Hydra. Sin tener que aprender tanto, es posible dejar un código muy poderoso y flexible que puede ser ejecutado con las configuraciones que queramos y además llevando registro en el tiempo de nuestras ejecuciones.
Es es todo por hoy,
Nos vemos!!