Tabular Playground Enero 2022
Mi primera incursión en Kaggle

Como algunos sabrán me cambié de pega. En mi nuevo trabajo hay una fuerte componente temporal involucrada en los problemas que resolvemos y justo este mes en Kaggle el Tabular Playground abordó un problema de series de tiempo. ¿Qué mejor manera de introducirse en el mundo de Kaggle? .
La verdad es que hace rato que quería empezar a competir en Kaggle, pero me daba como miedito. Como que es jugar en las grandes ligas donde hay mucha gente que sabe lo que está haciendo. Decidí entrar en estas competencias de un mes, que no son con premio (pensando que eran más sencillas) y en verdad aprendí muchísimo y no son más fáciles. Una de las cosas más importante que me llevo es que los modelos líneales son poderosos y útiles.
SPOILER: El ganador de esta competencia ganó con un Modelo Lineal, y harto feature engineering con data externa.
Sobre Kaggle
Yo creo (es sólo mi opinion) que Kaggle no es para alguien recién empezando. Si bien se puede encontrar gente de todos los niveles, siento que participar en Kaggle es abrumante. Todos los días hay Kernels nuevos, con nuevas opiniones, consejos, tips, que uno no sabe por donde partir, lo cual creo que para alguien que está partiendo es demasiada información por todas partes (Para mí fue terrible, de hecho, luego de dos semanas como que no quería seguir entrando, es muy desgastante).
Otra cosa que me dí cuenta, es que las personas que realmente saben en Kaggle son pocas, y hay que tener un ojo crítico para encontrarlos. En el caso de esta competencia un tipo de nick AmbrosoM siempre destacó con sus kernels, todas las soluciones se basaban en sus hallazgos y terminó ganando la competencia, porque efectivamente tenía un entendimiento bastante superior al resto de nosotros.
Hay muchos que colocan Kernels muy bonitos, con EDA espectacular, con modelos espectaculares y que reciben muchos votos, pero que terminan dando la hora en el Private Leaderboard. Hay un chico en el cuál tomé las ideas de Hybrid Models que terminó más abajo que yo, supongo que por abusar del Public Leaderboard y otro que implementó un transformer desde cero. Como que quise copiar su Transformer pero no logré entenderlo, y lo que no entiendo no lo implemento.
La semana pasada tuve la oportunidad de escuchar una entrevista de
Weights & Biasesa un Kaggler llamado Mark Tenenholtz, y me gustó mucho, porque él decía que la verdadera habilidad que da Kaggle es aprender a tener un buen esquema de validación y evitar el Overfitting. El mejor consejo que entregaba es no preocuparse del Score Público y confiar en el CV local. Siempre dan ese consejo pero pocas veces se sigue. Y en esta competencia, el que salió 1ero en el Public LeaderBoard terminó 322 en el Private LeaderBoard. De verdad la competencia fue una oda al Overfitting.
Más adelante les cuento como me fue a mí!!.
Entonces quiero mostrarles cuál fue una de las soluciones que plantée con lo aprendido que usa una técnica llamada Hybrid Models, o Boosted Linear Models, el cual combina modelos lineales con modelos Boosting (que siguen siendo mis favoritos).
Presentación del Problema
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import holidays
Quizás, la única librería que hay que destacar acá es Holidays. Es una librería bien sencilla pero que tiene todos los feriados de los países.
df_train = pd.read_csv('../inputs/train.csv', index_col=0, parse_dates=['date'])
df_test = pd.read_csv('../inputs/test.csv', index_col=0, parse_dates=['date'])
df_train.shape, df_test.shape
((26298, 5), (6570, 4))
Como se puede ver, el número de variables predictoras es muy limitado, sólo 4. Y el número de registros permite poder realizar una gran cantidad de experimentos sin un costo computacional tan alto. Los registros del dataset se ven así:
df_train.head()
| date | country | store | product | num_sold | |
|---|---|---|---|---|---|
| row_id | |||||
| 0 | 2015-01-01 | Finland | KaggleMart | Kaggle Mug | 329 |
| 1 | 2015-01-01 | Finland | KaggleMart | Kaggle Hat | 520 |
| 2 | 2015-01-01 | Finland | KaggleMart | Kaggle Sticker | 146 |
| 3 | 2015-01-01 | Finland | KaggleRama | Kaggle Mug | 572 |
| 4 | 2015-01-01 | Finland | KaggleRama | Kaggle Hat | 911 |
| 5 | 2015-01-01 | Finland | KaggleRama | Kaggle Sticker | 283 |
| 6 | 2015-01-01 | Norway | KaggleMart | Kaggle Mug | 526 |
| 7 | 2015-01-01 | Norway | KaggleMart | Kaggle Hat | 906 |
| 8 | 2015-01-01 | Norway | KaggleMart | Kaggle Sticker | 250 |
| 9 | 2015-01-01 | Norway | KaggleRama | Kaggle Mug | 1005 |
| 10 | 2015-01-01 | Norway | KaggleRama | Kaggle Hat | 1461 |
| 11 | 2015-01-01 | Norway | KaggleRama | Kaggle Sticker | 395 |
| 12 | 2015-01-01 | Sweden | KaggleMart | Kaggle Mug | 440 |
| 13 | 2015-01-01 | Sweden | KaggleMart | Kaggle Hat | 624 |
| 14 | 2015-01-01 | Sweden | KaggleMart | Kaggle Sticker | 175 |
- Como pueden notar hay pocas variables, lo cual quiere decir que esta competencia se va a ganar principalmente por quien desarrolle las mejores features.
- Dado que hay una fuerte componente temporal una muy buena idea es poder descomponer las fechas en varias variables adicionales.
- El esquema de validación es algo que no se puede dejar al azar. Dado que hay una componente temporal (secuencial) es que no se pueden hacer splits aleatorios, se debe respetar el orden.
Sigo sin comprender por qué es necesario utilizar splits ordenados en el tiempo. Creo personalmente que hay una diferencia entre un problema de Forecasting de Series de Tiempo y otro de Regresión de Series de Tiempo. La documentación de sktime explica que un Forecasting es cuando el target t-1 es input necesario para predecir el target t. Y es en este caso donde se requiere una validación secuencial.
En el caso de esta competencia, se propuso utilizar GroupKFold donde cada grupo era un año y terminó dando buenos resultados a pesar de que uno a veces terminaba validando en el pasado.
Si alguien tiene alguna propuesta/respuesta/explicación a este fenómeno que me contacte.
Variables Temporales
Algunas de las variables creadas descomponiendo la fecha fueron las siguientes (todas construidas con Pandas).
def create_date_features(df):
df['day_of_year'] = df.date.dt.day_of_year
df['day_of_month'] = df.date.dt.day
df['day_of_week'] = df.date.dt.weekday
df['month'] = df.date.dt.month
df['quarter'] = df.date.dt.quarter
df['year'] = df.date.dt.year
df['period'] = df.date.dt.to_period('M')
return df
df_train = create_date_features(df_train)
df_test = create_date_features(df_test)
df_train.shape, df_test.shape
((26298, 12), (6570, 11))
EDA
El Análisis exploratorio es definitivamente algo que no me gusta hacer, pero que pucha que ayuda para entender la data. Una de las cosas que más aprendí en esta competencia es la importancia de siempre volver al análisis. El análisis exploratorio para ir descubriendo que features nuevos ir construyendo pero también al Error Analysis para ir chequeando donde tu modelo está fallando y trabajar en dichas falencias.
Yo aún no tengo un framework definido de error analysis. Es algo que recién descubrí su importancia. (A pesar de que escuché la clase Andrew Ng hace tiempo en este tema). Siento que ahora recién empiezo a tomarle el peso a tener este tipo de información para elegir el mejor modelo
df_train.date.agg({np.min, np.max})
amin 2015-01-01
amax 2018-12-31
Name: date, dtype: datetime64[ns]
df_test.date.agg({np.min, np.max})
amin 2019-01-01
amax 2019-12-31
Name: date, dtype: datetime64[ns]
df_train.period.value_counts().sort_index().plot(figsize = (12,8));
df_test.period.value_counts().sort_index().plot(figsize = (12,8));
def cat_per_column(df):
cat_cols = [col for col in df.columns if df[col].dtype == 'object']
for col in cat_cols:
print(df[col].value_counts(), '\n')
cat_per_column(df_train)
Finland 8766
Norway 8766
Sweden 8766
Name: country, dtype: int64
KaggleMart 13149
KaggleRama 13149
Name: store, dtype: int64
Kaggle Mug 8766
Kaggle Hat 8766
Kaggle Sticker 8766
Name: product, dtype: int64
cat_per_column(df_test)
Finland 2190
Norway 2190
Sweden 2190
Name: country, dtype: int64
KaggleMart 3285
KaggleRama 3285
Name: store, dtype: int64
Kaggle Mug 2190
Kaggle Hat 2190
Kaggle Sticker 2190
Name: product, dtype: int64
df_train.set_index('period').num_sold.plot(figsize = (16,8));
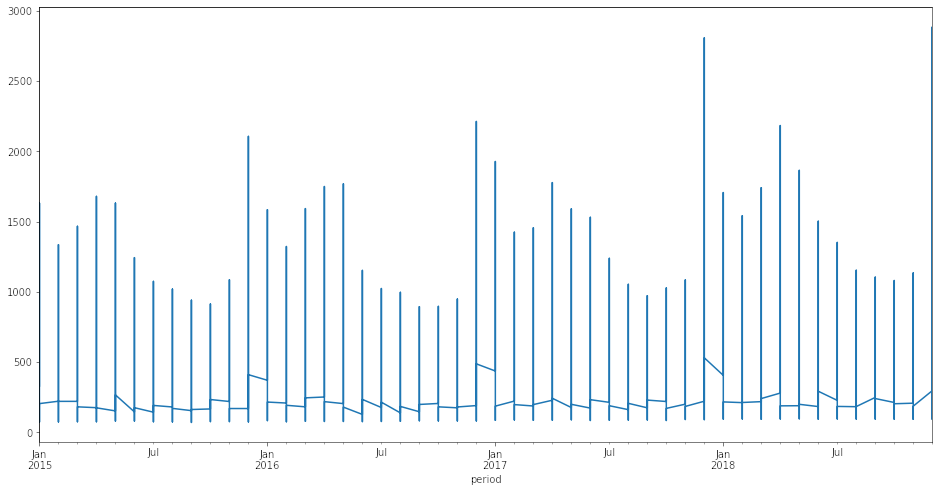
df_train.groupby(['country', 'store','product']).num_sold.agg(['min','max','mean'])
| min | max | mean | |||
|---|---|---|---|---|---|
| country | store | product | |||
| Finland | KaggleMart | Kaggle Hat | 210 | 1113 | 362.479808 |
| Kaggle Mug | 126 | 774 | 204.200548 | ||
| Kaggle Sticker | 70 | 326 | 103.044490 | ||
| KaggleRama | Kaggle Hat | 354 | 1895 | 628.926762 | |
| Kaggle Mug | 220 | 1398 | 356.110883 | ||
| Kaggle Sticker | 128 | 559 | 180.232033 | ||
| Norway | KaggleMart | Kaggle Hat | 335 | 1809 | 594.645448 |
| Kaggle Mug | 201 | 1113 | 334.370294 | ||
| Kaggle Sticker | 114 | 518 | 169.577687 | ||
| KaggleRama | Kaggle Hat | 596 | 2884 | 1036.357974 | |
| Kaggle Mug | 366 | 1935 | 584.297741 | ||
| Kaggle Sticker | 214 | 874 | 295.607803 | ||
| Sweden | KaggleMart | Kaggle Hat | 248 | 1207 | 419.214237 |
| Kaggle Mug | 149 | 730 | 235.885010 | ||
| Kaggle Sticker | 86 | 356 | 119.613279 | ||
| KaggleRama | Kaggle Hat | 428 | 2169 | 731.452430 | |
| Kaggle Mug | 253 | 1438 | 411.273101 | ||
| Kaggle Sticker | 148 | 637 | 208.314853 |
df_train.groupby(['country', 'store','product']).num_sold.mean().unstack(level = 'store').assign(ratio = lambda x: x.KaggleRama/x.KaggleMart)
| store | KaggleMart | KaggleRama | ratio | |
|---|---|---|---|---|
| country | product | |||
| Finland | Kaggle Hat | 362.479808 | 628.926762 | 1.735067 |
| Kaggle Mug | 204.200548 | 356.110883 | 1.743927 | |
| Kaggle Sticker | 103.044490 | 180.232033 | 1.749070 | |
| Norway | Kaggle Hat | 594.645448 | 1036.357974 | 1.742817 |
| Kaggle Mug | 334.370294 | 584.297741 | 1.747457 | |
| Kaggle Sticker | 169.577687 | 295.607803 | 1.743200 | |
| Sweden | Kaggle Hat | 419.214237 | 731.452430 | 1.744818 |
| Kaggle Mug | 235.885010 | 411.273101 | 1.743532 | |
| Kaggle Sticker | 119.613279 | 208.314853 | 1.741570 |
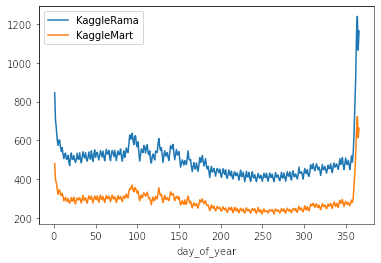
Gracias al Análisis Exploratorio se pudo notar que básicamente Kaggle Rama siempre vende alrededor de 1.73x más que KaggleMart. Yo particularmente no lo utilicé en el proceso de modelamiento, pero creo que los primeros lugares sí lo utilizaron para que el modelo entendiera mejor la diferencia entre una y otra tienda.
Gráficos comparativos
A continuación presento una serie de gráficos para poder entender las distintas tendencias entre las categorías del dataset y distintas ventanas de tiempo.
df_train.query('store == "KaggleRama"').groupby(["day_of_week"]).num_sold.mean().plot(label = 'KaggleRama')
df_train.query('store == "KaggleMart"').groupby(["day_of_week"]).num_sold.mean().plot(label = 'KaggleMart')
plt.legend()
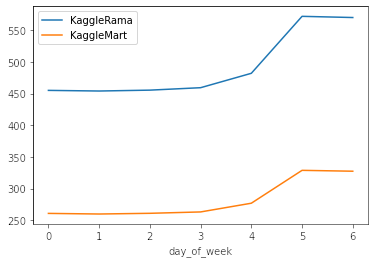
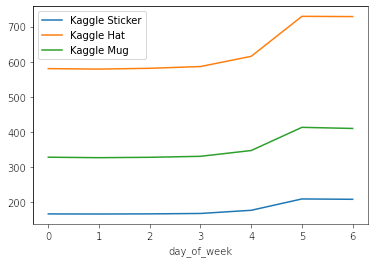
df_train.query('product == "Kaggle Sticker"').groupby(["day_of_week"]).num_sold.mean().plot(label = "Kaggle Sticker")
df_train.query('product == "Kaggle Hat"').groupby(["day_of_week"]).num_sold.mean().plot(label = "Kaggle Hat")
df_train.query('product == "Kaggle Mug"').groupby(["day_of_week"]).num_sold.mean().plot(label = "Kaggle Mug")
plt.legend();
0: Es Lunes. 6: Es Domingo.
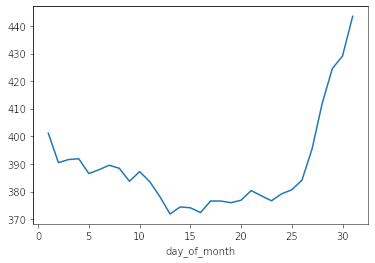
df_train.groupby("day_of_month").num_sold.mean().plot();
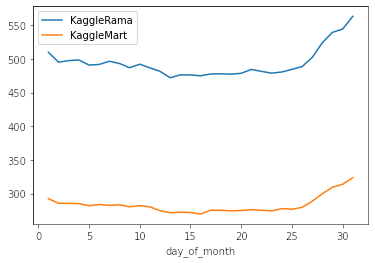
df_train.query('store == "KaggleRama"').groupby(["day_of_month"]).num_sold.mean().plot(label = 'KaggleRama')
df_train.query('store == "KaggleMart"').groupby(["day_of_month"]).num_sold.mean().plot(label = 'KaggleMart')
plt.legend();
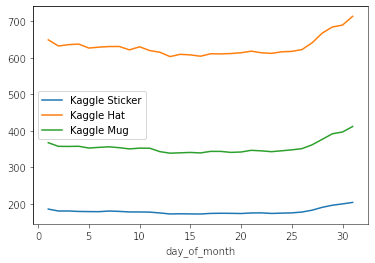
df_train.query('product == "Kaggle Sticker"').groupby(["day_of_month"]).num_sold.mean().plot(label = "Kaggle Sticker")
df_train.query('product == "Kaggle Hat"').groupby(["day_of_month"]).num_sold.mean().plot(label = "Kaggle Hat")
df_train.query('product == "Kaggle Mug"').groupby(["day_of_month"]).num_sold.mean().plot(label = "Kaggle Mug")
plt.legend();
df_train.groupby("day_of_year").num_sold.mean().plot();
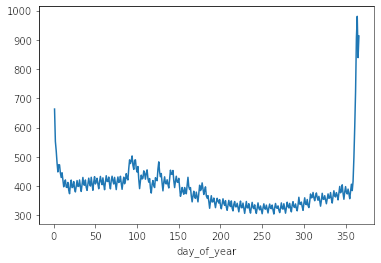
df_train.query('store == "KaggleRama"').groupby(["day_of_year"]).num_sold.mean().plot(label = 'KaggleRama')
df_train.query('store == "KaggleMart"').groupby(["day_of_year"]).num_sold.mean().plot(label = 'KaggleMart')
plt.legend();
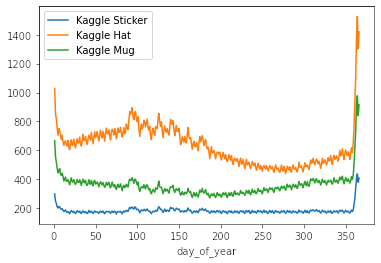
df_train.query('product == "Kaggle Sticker"').groupby(["day_of_year"]).num_sold.mean().plot(label = 'Kaggle Sticker')
df_train.query('product == "Kaggle Hat"').groupby(["day_of_year"]).num_sold.mean().plot(label = 'Kaggle Hat')
df_train.query('product == "Kaggle Mug"').groupby(["day_of_year"]).num_sold.mean().plot(label = 'Kaggle Mug')
plt.legend();
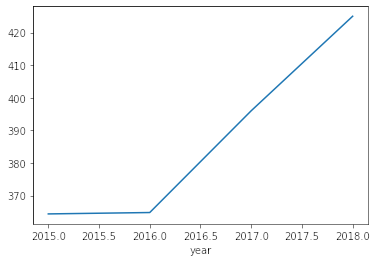
df_train.groupby("year").num_sold.mean().plot();
df_train.query('store == "KaggleRama"').groupby(["year"]).num_sold.mean().plot(label = 'KaggleRama')
df_train.query('store == "KaggleMart"').groupby(["year"]).num_sold.mean().plot(label = 'KaggleMart')
plt.legend();
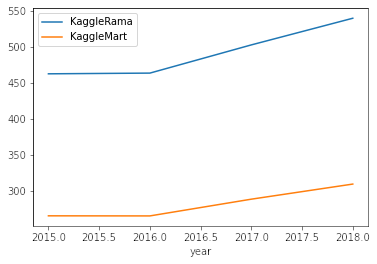
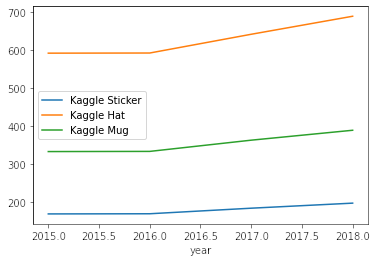
df_train.query('product == "Kaggle Sticker"').groupby(["year"]).num_sold.mean().plot(label = 'Kaggle Sticker')
df_train.query('product == "Kaggle Hat"').groupby(["year"]).num_sold.mean().plot(label = 'Kaggle Hat')
df_train.query('product == "Kaggle Mug"').groupby(["year"]).num_sold.mean().plot(label = 'Kaggle Mug')
plt.legend();
plt.figure(figsize = (18,12))
df_train.set_index('date').num_sold.plot(label = 'daily')
df_train.set_index('date').num_sold.resample('W').mean().plot(label = 'weekly')
df_train.set_index('date').num_sold.resample('M').mean().plot(label = 'monthly')
plt.legend();
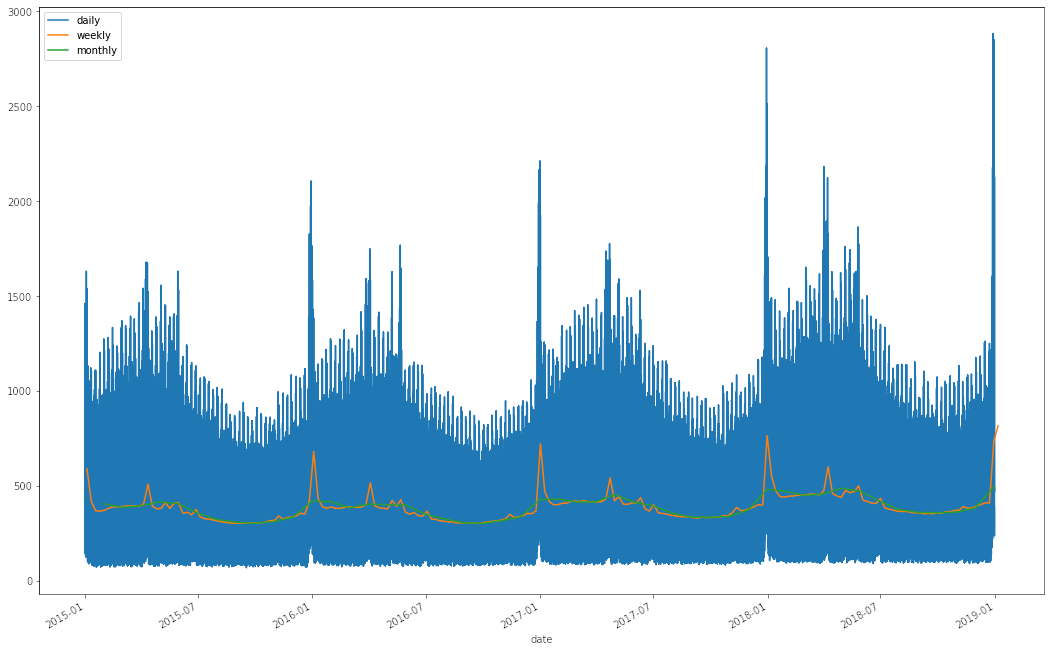
Conclusiones del EDA
- Es posible ver que el viernes hay un leve aumento en las ventas y ya el sábado y el domingo se vende bastante más.
- Hay un incremento en las ventas al final del mes.
- También existen incrementos en los finales de año.
- Hay un efecto relacionado a los festivos. Se pueden ver peaks recurrentes año a año que están asociados a festividades propias de cada país. (De ahí la importancia de la librería holidays.)
- Se puede ver que desde el 2016 en adelante hay un incremento lineal en las ventas. Esto muy probablemente indica que en el año a predecir (2019) la tendencia continúa, y por lo tanto nuestro modelo debe ser capaz de extrapolar.
- Se pueden ver periodos de estacionalidad cuando suavizamos la curva al nivel de semana.
Feature Engineering
A partir de las conclusiones del EDA se intentarán modelar variables para abordar los distintos efectos:
Holiday Effect
Para poder entonces modelar los efectos de los festivos utilizamos la librería Holiday. Esta librería permite extraer los feriados por País y por Año.
finland = pd.DataFrame([dict(date = date,
finland_holiday = event,
country= 'Finland') for date, event in holidays.Finland(years=[2015, 2016, 2017, 2018, 2019]).items()])
finland['date'] = finland['date'].astype("datetime64")
norway = pd.DataFrame([dict(date = date,
norway_holiday = event,
country= 'Norway') for date, event in holidays.Norway(years=[2015, 2016, 2017, 2018, 2019]).items()])
norway['date'] = norway['date'].astype("datetime64")
sweden = pd.DataFrame([dict(date = date,
sweden_holiday = event.replace(", Söndag", ""),
country= 'Sweden') for date, event in holidays.Sweden(years=[2015, 2016, 2017, 2018, 2019]).items() if event != 'Söndag'])
sweden['date'] = sweden['date'].astype("datetime64")
df_train = df_train.merge(finland, on = ['date', 'country'], how = 'left').merge(norway, on = ['date', 'country'], how = 'left').merge(sweden, on = ['date', 'country'], how = 'left')
df_test = df_test.merge(finland, on = ['date', 'country'], how = 'left').merge(norway, on = ['date', 'country'], how = 'left').merge(sweden, on = ['date', 'country'], how = 'left')
df_train
| date | country | store | product | num_sold | day_of_year | day_of_month | day_of_week | month | quarter | year | period | finland_holiday | norway_holiday | sweden_holiday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2015-01-01 | Finland | KaggleMart | Kaggle Mug | 329 | 1 | 1 | 3 | 1 | 1 | 2015 | 2015-01 | Uudenvuodenpäivä | NaN | NaN |
| 1 | 2015-01-01 | Finland | KaggleMart | Kaggle Hat | 520 | 1 | 1 | 3 | 1 | 1 | 2015 | 2015-01 | Uudenvuodenpäivä | NaN | NaN |
| 2 | 2015-01-01 | Finland | KaggleMart | Kaggle Sticker | 146 | 1 | 1 | 3 | 1 | 1 | 2015 | 2015-01 | Uudenvuodenpäivä | NaN | NaN |
| 3 | 2015-01-01 | Finland | KaggleRama | Kaggle Mug | 572 | 1 | 1 | 3 | 1 | 1 | 2015 | 2015-01 | Uudenvuodenpäivä | NaN | NaN |
| 4 | 2015-01-01 | Finland | KaggleRama | Kaggle Hat | 911 | 1 | 1 | 3 | 1 | 1 | 2015 | 2015-01 | Uudenvuodenpäivä | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 26293 | 2018-12-31 | Sweden | KaggleMart | Kaggle Hat | 823 | 365 | 31 | 0 | 12 | 4 | 2018 | 2018-12 | NaN | NaN | Nyårsafton |
| 26294 | 2018-12-31 | Sweden | KaggleMart | Kaggle Sticker | 250 | 365 | 31 | 0 | 12 | 4 | 2018 | 2018-12 | NaN | NaN | Nyårsafton |
| 26295 | 2018-12-31 | Sweden | KaggleRama | Kaggle Mug | 1004 | 365 | 31 | 0 | 12 | 4 | 2018 | 2018-12 | NaN | NaN | Nyårsafton |
| 26296 | 2018-12-31 | Sweden | KaggleRama | Kaggle Hat | 1441 | 365 | 31 | 0 | 12 | 4 | 2018 | 2018-12 | NaN | NaN | Nyårsafton |
| 26297 | 2018-12-31 | Sweden | KaggleRama | Kaggle Sticker | 388 | 365 | 31 | 0 | 12 | 4 | 2018 | 2018-12 | NaN | NaN | Nyårsafton |
26298 rows × 15 columns
Fourier Effect
Para modelar los periodos estacionales también es posible utilizar las propiedades de las series de Fourier. Sabemos (o deberíamos saber) que una serie de Fourier es una aproximación de infinitos combinaciones lineales de senos y cosenos a una función periodica. El tema es que para poder evitar considerar el ruido propio de una serie de tiempo podríamos sólo utilizar un número de componentes finitos que nos permitan deshacernos del ruido y encontrar sólo la señal de interés:
from numpy.fft import rfft, irfft, rfftfreq
def low_pass(s, threshold=2e4, d = None):
if d is None:
d = 2e-3 / s.size
fourier = rfft(s)
frequencies = rfftfreq(s.size, d=d)
fourier[frequencies > threshold] = 0
return irfft(fourier)
plt.figure(figsize = (18,12))
s = df_train.num_sold
for i, d in enumerate([1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6, 1e-7, 1e-8, 1e-9], start=1):
ax = plt.subplot(3,3, i)
ax.plot(low_pass(s, threshold=2e4, d = d))
ax.set_title(f'd = {d}')
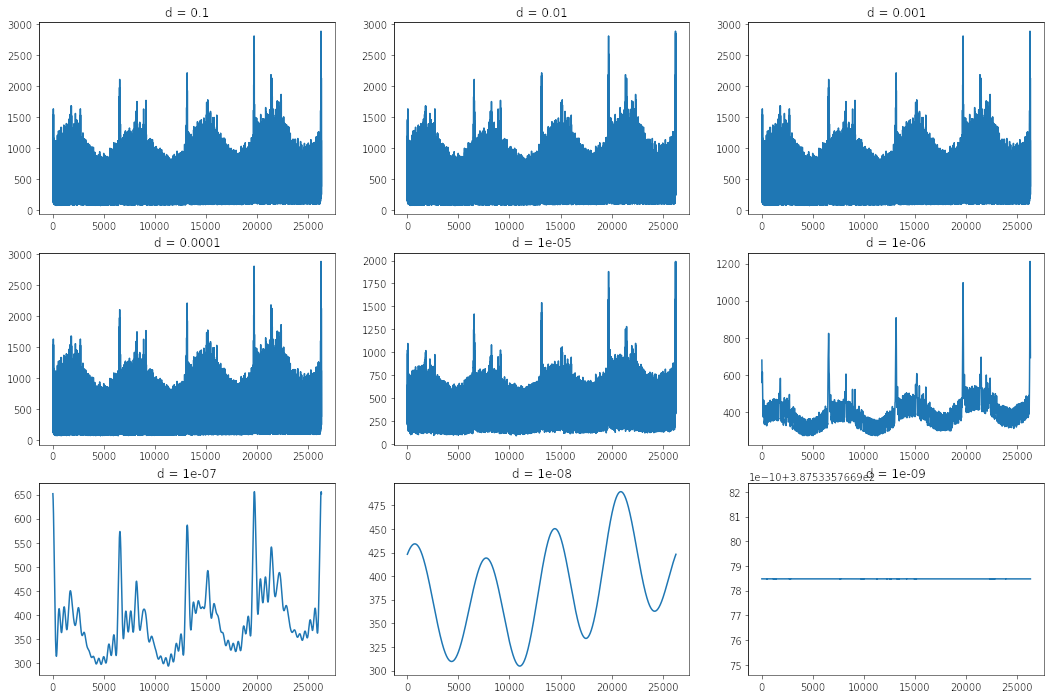
Luego una serie de Fourier se define formalmente como: \[f(t) \sim \frac{a_o}{2} + \sum{}_{n=1}^{\infty}\left[a_n cos\left(\frac{2n\pi}{T}t\right) + b_n sin\left(\frac{2n\pi}{T}t\right)\right]\]
Afortunadamente la librería feature-engine contiene una clase dedicada a componentes cíclicos (aka Fourier). Utilizando sus propiedades de manera apropiada, es posible replicar cada componente de la Serie de Fourier.

\(var\_sin = sin\left(\frac{2\pi}{max\_value}t\right)\) \(var\_cos = cos\left(\frac{2\pi}{max\_value}t\right)\)
\(var\_sin = sin\left(\frac{2n\pi}{max\_value}t\right) = sin\left(\frac{2\pi}{\frac{max\_value}{n}}t\right)\) \(var\_cos = cos\left(\frac{2n\pi}{max\_value}t\right) = cos\left(\frac{2\pi}{\frac{max\_value}{n}}t\right)\)
El Transformer creado por Feature-Engine tiene el inconveniente de que siempre nombra su resultado como var_sin o var_cos. Esto genera que cuando creo más de una componente de Fourier, estas se sobreescriben. Para mitigar eso creé mi propia versión del Transformer
class CyclicalTransformerV2(CyclicalTransformer):
def __init__(self, suffix = None, **kwargs):
super().__init__(**kwargs)
self.suffix = suffix
def transform(self, X):
X = super().transform(X)
if self.suffix is not None:
transformed_names = X.filter(regex = r'sin$|cos$').columns
new_names = {name: name + self.suffix for name in transformed_names}
X.rename(columns=new_names, inplace=True)
return X
Para ello heredé del CyclicalTransformer de Feature Engine y sólo modifiqué su transform.
Interacciones
Adicionalmente, es posible crear interacciones entre las variables categóricas y distintas componentes de Fourier para captar la estacionalidad propia de cada una de ella multiplicando la versión Dummy (One Hot Encoded) de cada categoría con una componente de Fourier.
products = pd.get_dummies(df_train['product'])
products.index = df_train.date
fourier_variables = pd.DataFrame({'sin': np.sin(2*np.pi*1*df_train['day_of_week']/7),
'cos': np.cos(2*np.pi*1*df_train['day_of_week']/7),
'sin2': np.sin(2*np.pi*2*df_train['day_of_week']/7),
'cos2': np.cos(2*np.pi*2*df_train['day_of_week']/7),
'sin3': np.sin(2*np.pi*3*df_train['day_of_week']/7),
'cos3': np.cos(2*np.pi*3*df_train['day_of_week']/7)})
fourier_variables.index = df_train.date
fourier_variables[['sin','cos']].plot(figsize = (16,12));
ax = fourier_variables.plot.scatter('sin', 'cos', figsize = (16,12)).set_aspect('equal')
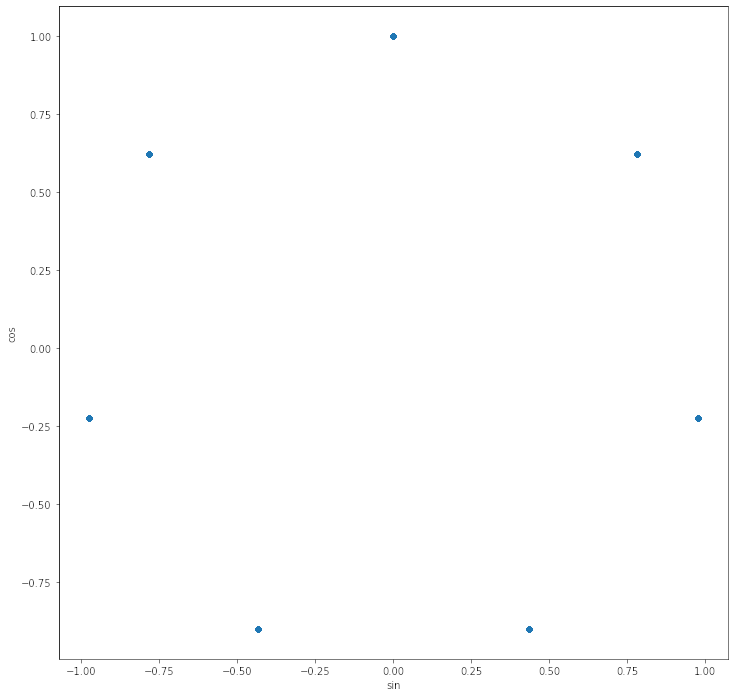
La gracia de la componente de Fourier es que permite que el modelo entienda que por ejemplo el Lunes (0) y el Domingo (6), están a la misma distancia a pesar de que numéricamente están a 6 unidades de distancia. Es como llevarlo a coordenadas polares.
El modelo
Como dijimos una de las gracias que tiene este problema es que es muy ruidoso, pero a la vez tiene una tendencia, en la cual nosotros tendremos que extrapolar.
Sé que muchos están esperando que diga que la regresión Lineal va a resolver todos los problemas, pero no. La extrapolación no es una ventaja de los modelos de árboles, pero sí de los modelos líneales (un punto para los modelos lineales). Por otro lado, ajustarse a alta variabilidad no es una ventaja de los modelos lineales, pero sí de los modelo de árbol (un punto para los modelos de árbol).
La pregunta es,
¿por qué no usar ambos de manera inteligente?
Aquí es donde aprendí de los modelos Híbridos.
El fundamento de los modelos híbridos es que el modelo líneal se encarga de captar la tendencia y extrapolarla. Y el modelo Boosting se encarga de aprender el ruido. Super interesante!
La idea acá es probar muchas combinaciones. Dentro de los modelos lineales que probé estuvo LR, HuberRegressor, PassiveAggresiveRegressor, entre otros. Y en los Boosting, probamos los 3 grandes, XGBoost, LightGBM y Catboost. Los resultados a mostrar ahora fueron los mejores para modelos antes de ensamblar.
Si ajustamos un modelo líneal a la data se ve algo así:
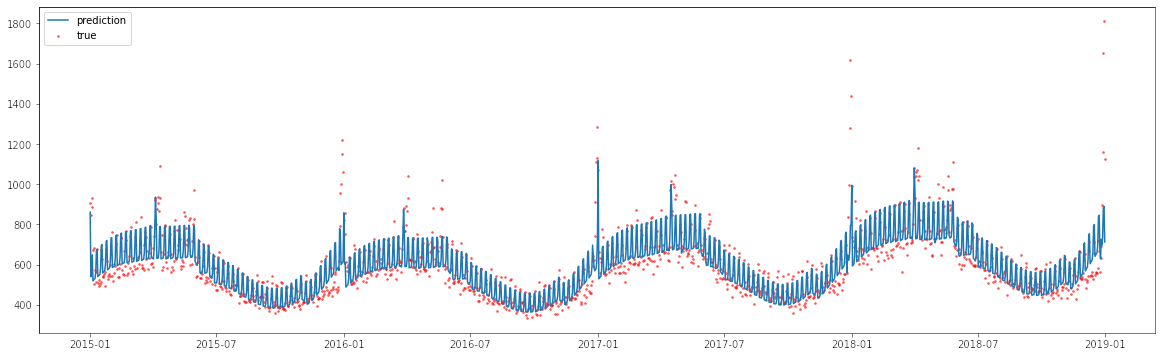
Como se ve un modelo lineal puede captar la tendencia de las ventas, e incluso la estacionalidad. Lo que no logra captar tan bien son los puntos extremos.
De hecho si hacemos una gráfica de los residuals (el valor real menos la predicción) notamos esto:
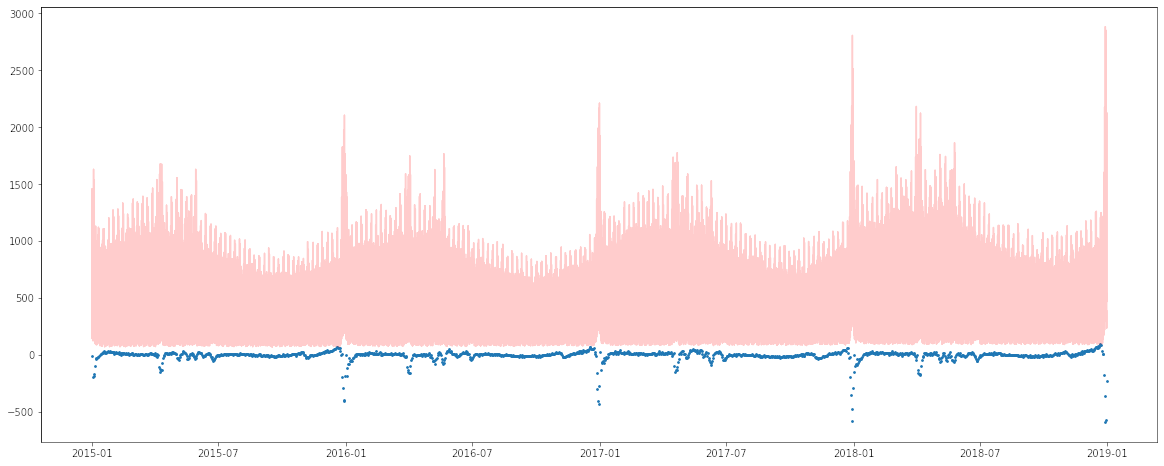
Los mayores errores (los puntitos azules más abajo) se dan en los peaks que se escapan de la tendencia. Luego la idea es poder utilizar el modelo Boosting para aprender los errores del modelo lineal y luego sumar las predicciones, obteniendo este ajuste:
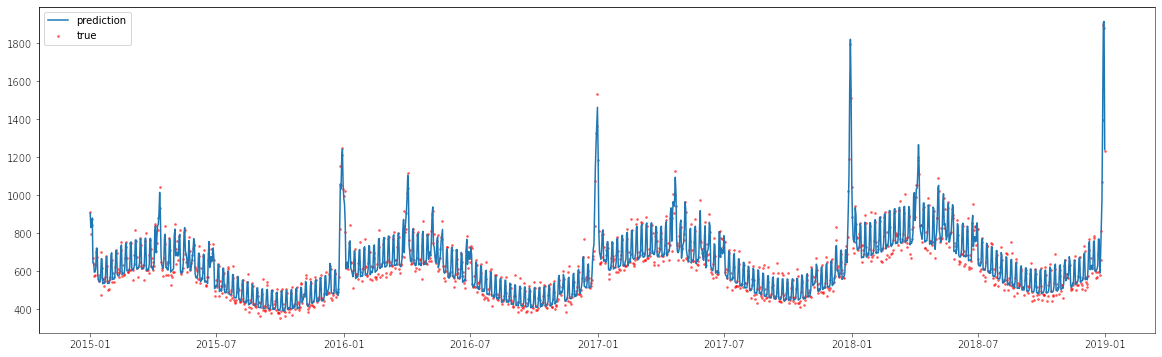
Este procedimiento podría ser muy propenso a Overfitting, por lo cual hay que asegurarse de una buena estrategia de validación.
Implementación de la Solución:
Generación de Features
Para generar mis features cree una clase que implementa todo de manera ordenada.
- Un detalle es que dentro de las discusiones de Kaggle se notó de que utilizar el GDP de cada país entregaba muy buenos resultados, por lo cual también lo agregué como feature.
- Además otros festivos como la pascua, el día de la mamá dieron buenos resultados. Además se dejaron indicadores de días previos y posteriores a fechas especiales que dieron buenos resultados.
- Se agreagaron indicadores para detectar viernes y fines de semana.
- Finalmente para el ajuste del modelo lineal se encontró que transformar el target a Log funcionaba de mejor manera. Esto debido a que el MAE de \(log(y)\) es muy parecido al error del SMAPE que era la métrica con la que se evaluaba este modelo.
El modelo que muestro acá es luego de varias ejecuciones afinando las variables finales y el respectivo preprocesamiento.
class Preprocess:
def __init__(self, gdp_path, easter, special_days, country_holidays):
self.gdp_path = gdp_path
self.easter = easter
self.special_days = special_days
self.country_holidays = country_holidays
def import_data(self, path):
self.df = pd.read_csv(path, parse_dates=['date'], index_col=0)
self.index = self.df.index
def get_gdp(self, path):
gdp = pd.read_csv(path)
gdp.columns = gdp.columns.str.title().str.replace('Gdp_','')
gdp = gdp.set_index('Year').stack(0).reset_index()
gdp.columns = ['year','country','gdp']
return gdp
def create_date_features(self, df):
# A
df['day_of_year'] = df.date.dt.day_of_year
df['day_of_month'] = df.date.dt.day
df['day_of_week'] = df.date.dt.weekday
df['week_of_year'] = df.date.dt.isocalendar().week.astype('int64')
df['year'] = df.date.dt.year
return df
def add_country_holidays(self, df):
years = [2015, 2016, 2017, 2018, 2019]
finland = self.country_holidays['finland']
norway = self.country_holidays['norway']
sweden = self.country_holidays['sweden']
return (df.merge(finland, on = ['date', 'country'], how = 'left')
.merge(norway, on = ['date', 'country'], how = 'left')
.merge(sweden, on = ['date', 'country'], how = 'left'))
def get_specific_dates_features(self, df):
return (df.assign(easter = lambda x: x.year.map(self.easter).astype('datetime64'),
moms_day = lambda x: x.year.map(self.special_days['moms_day']).astype('datetime64'),
wed_jun = lambda x: x.year.map(self.special_days['wed_june']).astype('datetime64'),
sun_nov = lambda x: x.year.map(self.special_days['sun_nov']).astype('datetime64'),
days_from_easter = lambda x: (x.date - x.easter).dt.days.clip(-5, 65),
days_from_mom = lambda x: (x.date - x.moms_day).dt.days.clip(-1, 9),
days_from_wed = lambda x: (x.date - x.wed_jun).dt.days.clip(-5, 5),
days_from_sun = lambda x: (x.date - x.sun_nov).dt.days.clip(-1, 9),
)).drop(columns = ['easter','moms_day','wed_jun','sun_nov'])
def join_gdp(self, df):
return df.merge(self.gdp, on = ['country','year'], how = 'left')
def feature_engineering(self, df):
df['log_gdp'] = np.log(df.gdp)
days_cats = [df.day_of_week < 4, df.day_of_week == 4, df.day_of_week > 4]
days = ['week','friday','weekends']
df['week'] = np.select(days_cats, days)
return df
def __call__(self, path, name = 'Train'):
self.import_data(path)
self.gdp = self.get_gdp(self.gdp_path).set_index('year')
out = (self.df.pipe(self.create_date_features)
.pipe(self.join_gdp)
.pipe(self.feature_engineering)
.pipe(self.add_country_holidays)
.pipe(self.get_specific_dates_features))
out.index = self.index
print(f'{name} Set created with {out.shape[1]} features')
return out
Preprocesamiento
Dado que se utilizan dos modelos distintos, con distintas caractertísticas, los preprocesamientos se hacen de manera distinta. De hecho las variables de Fourier se utilizan en 4 componentes y dos en el Boosting. Además se utilizó OrdinalEncoder en el modelo Boosting, mientras que en el modelo Lineal se usa OneHotEncoding y StandardScaler.
from feature_engine.creation import CombineWithReferenceFeature
from feature_engine.encoding import OneHotEncoder, OrdinalEncoder
from feature_engine.imputation import CategoricalImputer
from feature_engine.selection import DropFeatures
from feature_engine.wrappers import SklearnTransformerWrapper
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from utils import CyclicalTransformerV2
preprocess_dict = {}
scaler = SklearnTransformerWrapper(StandardScaler())
cyc_1 = CyclicalTransformerV2(variables = ['day_of_year'],
max_values = {'day_of_year':365},
suffix = '_1')
cyc_2 = CyclicalTransformerV2(variables = ['day_of_year'],
max_values = {'day_of_year':365/2,},
suffix = '_2')
cyc_3 = CyclicalTransformerV2(variables = ['day_of_week'],
max_values = {'day_of_week':7,},
suffix = '_week')
cyc_4 = CyclicalTransformerV2(variables = ['day_of_week'],
max_values = {'day_of_week':7/2,},
suffix = '_semiweek')
prep = Pipeline(steps = [
('cat_imp', CategoricalImputer()),
('ohe', OneHotEncoder(drop_last=True)),
('cyc1', cyc_1),
('cyc2', cyc_2),
('cyc3', cyc_3),
('cyc4', cyc_4),
('combo', CombineWithReferenceFeature(
variables_to_combine=['day_of_year_sin_1', 'day_of_year_cos_1',
'day_of_year_sin_2', 'day_of_year_cos_2'],
reference_variables=['product_Kaggle Mug', 'product_Kaggle Hat'],
operations = ['mul'])),
('combo_week', CombineWithReferenceFeature(
variables_to_combine=['day_of_week_sin_week', 'day_of_week_cos_week',
'day_of_week_sin_semiweek', 'day_of_week_cos_semiweek'],
reference_variables=['product_Kaggle Mug', 'product_Kaggle Hat'],
operations = ['mul'])),
('drop', DropFeatures(features_to_drop=['year'],
)),
('sc', scaler)
])
preprocess_dict['linear_v1'] = prep
bcyc_1 = CyclicalTransformerV2(variables = ['day_of_year'],
max_values = {'day_of_year':365},
suffix = '_1')
bcyc_2 = CyclicalTransformerV2(variables = ['day_of_year'],
max_values = {'day_of_year':365/2,},
suffix = '_2')
prep = Pipeline(steps = [
('cat_imp', CategoricalImputer()),
('oe', OrdinalEncoder()),
('cyc1', bcyc_1),
('cyc2', bcyc_2),
('drop', DropFeatures(features_to_drop=['year']
)),
])
preprocess_dict['boosting_v1'] = prep
Proceso de Entrenamiento
Esta función de entrenamiento tomará X e y para ser entrenados en un modelo utilizando una estrategia de CV definida. Además esta función devolverá los valores de Entrenamiento, Validación y Test para ser usados eventualmente en un stacking.
Un detalle que puede llamar la atención en esta implementación es que nunca entrené el modelo en toda la data. La predicción en test se da como el promedio de las predicciones en test para cada fold.
Esta estrategia la aprendí en un modelo de Abishek Thakur y últimamente no me ha dado TAN buenos resultados por lo que para futuras competencias haré un refit en toda la data.
SPOILER: Todos los stacking terminaron super sobreajustados por lo que no los envié dentro de mi predicción final.
def cv_trainer(model, X,y, X_test = None, folds = None):
S_train = pd.DataFrame(np.nan, index = range(len(X)), columns = ['fold','num_sold'])
S_test = {}
scores = dict(train = [],
val = [])
for fold, (train_idx, val_idx) in enumerate(folds):
X_train, y_train = X.iloc[train_idx],y.iloc[train_idx]
X_val, y_val = X.iloc[val_idx],y.iloc[val_idx]
id_train = X_train.index
id_val = X_val.index
id_test = X_test.index
model.fit(X_train, y_train)
y_pred_train = pd.Series(model.predict(X_train), index = id_train, name = 'num_sold')
y_pred_val = pd.Series(model.predict(X_val), index = id_val, name = 'num_sold')
y_pred_test = pd.Series(model.predict(X_test), index = id_test, name = 'num_sold')
S_train.loc[val_idx, 'num_sold'] = y_pred_val
S_train.loc[val_idx, 'fold'] = fold
scores['train'].append(smape(y_train, y_pred_train))
scores['val'].append(smape(y_val, y_pred_val))
S_test[fold] = y_pred_test
S_test = pd.DataFrame(S_test).mean(axis = 1).to_frame()
S_test.columns = ['num_sold']
return scores, S_train, S_test
Modelo Híbrido
Para poder implementar el modelo Híbrido cree una clase de Scikit-Learn de la siguiente forma:
class HybridModel(BaseEstimator, RegressorMixin):
def __init__(self, l_model, b_model):
self.l_model = l_model
self.b_model = b_model
def fit(self, X, y):
log_y = np.log(y)
self.l_model.fit(X, log_y)
linear_pred = np.exp(self.l_model.predict(X))
y_resid = y - linear_pred
self.b_model.fit(X, y_resid)
self.is_fitted_ = True
return self
def predict(self, X):
check_is_fitted(self, 'is_fitted_')
l_predict = np.exp(self.l_model.predict(X))
b_predict = self.b_model.predict(X)
y_predict = l_predict + b_predict
return y_predict
Esta clase hereda de BaseEstimator y RegressorMixin y va a tomar X, lo va introducir al pipeline del modelo lineal y lo va entrenar con el \(log(y)\). Posteriormente va a calcular el residual (es decir, el valor real menos la predicción) y va a entrenar un modelo boosting en este residual.
Finalmente la predicción va a ser la suma de la predicción en el modelo lineal y el modelo Boosting.
Código Principal
import os
import numpy as np
import pandas as pd
from sklearn.linear_model import HuberRegressor, Ridge, LinearRegression
from sklearn.model_selection import GroupKFold
from sklearn.pipeline import Pipeline
from lightgbm import LGBMRegressor
import data as d
from models import HybridModel
from preprocessing import preprocess_dict
from utils import Preprocess, cv_trainer
GDP_PATH = '../inputs/GDP_data_2015_to_2019_Finland_Norway_Sweden.csv'
TRAIN_PATH = '../inputs/train.csv'
TEST_PATH = '../inputs/test.csv'
feature_engineer = Preprocess(GDP_PATH, d.EASTER_DICT, d.SPECIAL_DAYS_DICT, d.COUNTRY_HOLIDAYS_DICT)
train_df = feature_engineer(TRAIN_PATH)
test_df = feature_engineer(TEST_PATH, name = 'Test')
X = train_df.drop(columns = ['gdp','date','num_sold'])
y = train_df.num_sold
X_test = test_df.drop(columns = ['gdp','date'])
ridge = Pipeline(steps = [
('prep', preprocess_dict['linear_v1']),
('model', LinearRegression())
])
xgb = Pipeline(steps = [
('prep', preprocess_dict['boosting_v1']),
('model', LGBMRegressor())
])
model = HybridModel(ridge, xgb)
folds = GroupKFold(n_splits=4).split(X = train_df, groups=train_df.year) # not sure if it's ok
scores, S_train, S_test = cv_trainer(model, X,y, X_test, folds)
model_name = '_'.join([type(model).__name__, type(model.l_model.named_steps.model).__name__, type(model.b_model.named_steps.model).__name__])
print(f'Training results for {model_name}')
print(scores)
print('Mean Training Score: ', np.mean(scores['train']))
print('Mean Validaton Score: ', np.mean(scores['val']))
S_test.to_csv(f'../submissions/submission_{model_name}_v2.csv')
def save_predictions(preds, model_name, mode = 'train'):
path = f'../submissions/Stacking_{mode}.csv'
if os.path.exists(path):
input = pd.read_csv(path, index_col=0)
input[f'{model_name}'] = preds['num_sold'].sort_index()
input.to_csv(path)
else:
out = preds['num_sold']
out.name = model_name
out.to_csv(path)
save_predictions(S_train, model_name)
save_predictions(S_test, model_name, mode = 'test')
Lecciones Aprendidas
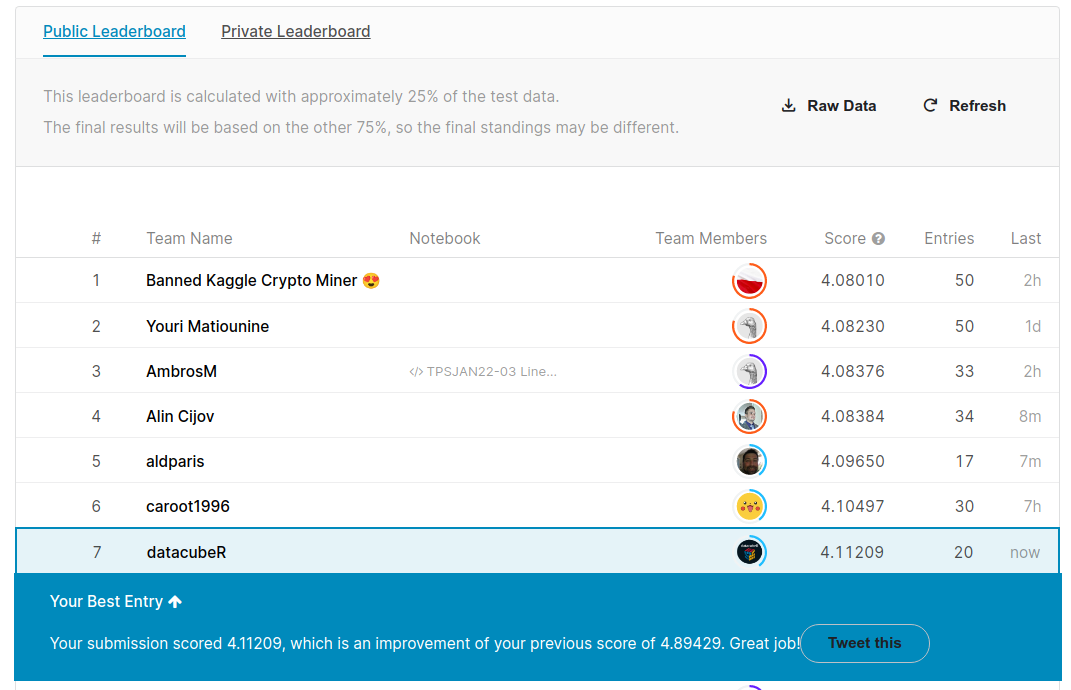
- Quien diga que Kaggle no sirve para la vida real no entiende nada. Creo que confirmo esto. Una de las grandes lecciones es que es muy fácil overfittear. Y Kaggle te invita a hacerlo. El Public Leaderboard es sólo una tentación a generar overfitting (una prueba de esto es que el número 1 en el Public Leaderboard terminó 322). Creo que todos los grandes Kagglers lo dicen, pero hay que confiar en tu estrategia de validación Local, y es dificil pero funciona.
En mi caso terminé 118 (Top 8%, lo cual hubiera sido bronce en una competencia real) y subí 184 puestos, lo cual me deja tranquilo de que no overfitié.
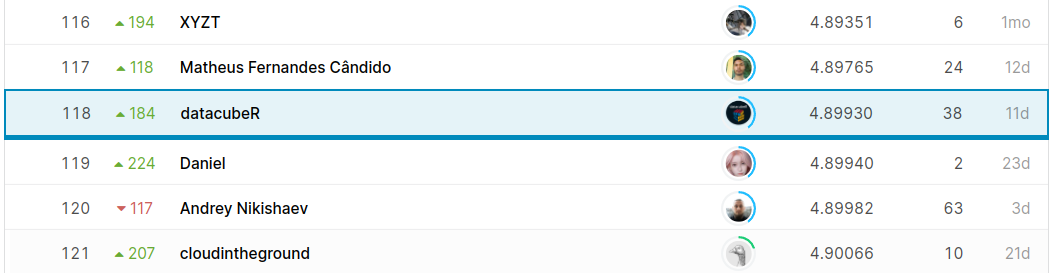
Mi modelo ganador no utilizó Stacking. Esto igual es interesante, porque hasta ahora el stacking sólo generó overfitting. Puede ser porque no lo implementé de manera correcta en series de tiempo, pero es algo en lo que tengo que trabajar.
No hay que creerle a un Kernel sólo porque tiene muchos votos. Varias veces me ví tentado a copiar algo en lo que no estaba de acuerdo, por ejemplo,
StandardScalerantes del split, o usandoKFoldcon fechas. Afortunadamente me quedo tranquilo que a pesar de que esos Kernels tenían buen puntaje público terminaron bien bajos en el privado 😈.Una cosa muy desmotivante en Kaggle es que uno se acuesta en un buen puesto y al otro día 500 personas te pasaron porque copiaron y pegaron un Kernel.
En un momento estuve en el top 10!!! 😱😱😱😱😱😱 Y luego llegó la triste realidad😞.
La fase de feature engineering fue clave. El dataset tal como estaba era casi inservible. De las variables finales que utilicé, el 95% fueron creadas. Por lo tanto sostengo que esta es por lejos la parte más importante al momento de modelar.
Los modelos lineales son bakanes. Son más complicados de manejar, requieren mucho más expertise y crear features muy customizadas, pero creo que obligan al modelador a dedicarle mucho tiempo. Quizás esa es la razón porque los modelos boosting son tan populares. No sólo son muy poderosos sino que también no es necesario dedicarle tanto tiempo.
Tengo que dedicar tiempo al HPO. Nuevamente no alcancé a optimizar hiperparámetros, y esto podría haber reducido un par de puestos adicionales. Como dije esta competencia era puro evitar el overfitting, y estoy seguro que varios de mis modelos no alcanzaron a llegar a su óptimo.
Después de competir con tanta gente “Novata” tan buena, creo que jamás tendría la desfachatez de autoproclamarme experto en Machine Learning. Una de las cosas que aprendí es que sé menos de lo que creo y tengo un largo camino de aprendizaje.
Hay que atreverse a la competencia real. Tenía la convicción de que para poder estar en Kaggle hay que dedicar demasiado tiempo. Pero creo que si uno es inteligente y genera buenos scripts ordenados que uno puede eventualmente entrenar durante la noche y analizar durante el día, competir es completamente manejable con la vida. Así que me voy a ir con todo a
Ubiquant. Otra competencia de Series de Tiempo, donde espero poder implementar harto de lo aprendido durante TPS (Y que ya les cuento que es un cacho porque la data es gigante).
Por implementar
Hay varias cosas que sin duda tengo que mejorar para las siguientes competencias, las cuales describo acá:
Sistemas automatizado de feature engineering y feature selection. Normalmente entre más y mejores features mejor, pero esto es difícil y super desgastante.
Ser ordenado y loguear con W&B. Me dio como latita esto, y creo que es super importante poder reproducir cada uno de los experimentos. Perdí varios experimentos que pudieron ser útiles para algún stacking por no ser ordenado. No sé por qué pero siento que tengo que seguir trabajando en esto.
Error Analysis. Actualmente no sé nada de esto, no lo tengo implementado y no sé como afrontarlo en mi framework de modelamiento. Tengo que ver qué hacer respecto a esto. Una librería que me gustó es
deepcheckla cual voy a estar revisando para ver cómo me ayuda.
Espero este artículo sea de ayuda. Tengo otros artículos en la puerta del horno que no he podido terminar porque no tengo mucho tiempo. Espero tener pronto el tiempo para terminarlos.
El código de todo el proceso se puede encontrar en mi Github acá.
Hasta la otra,