Modelo de Estimación de RUL
¿Hagamos un Proyecto desde cero? Parte 3
Esta es la tercera patita de cómo hacer un proyecto desde cero. Puedes ver la parte 1 acá y la parte 2 acá. La idea es que, como ya implementamos un modelo baseline y un clipping, ahora podamos ir implementando elementos que permitan poder mejorar el puntaje obtenido. .
Si es que hiciste la tarea, habrás notado que algo raro pasa. En la vida real nosotros no podemos ver nuestro Test Set, eso irá ocurriendo a medida de que el Motor vaya funcionando. Por lo tanto, nosotros deberíamos confiar que nuestro esquema de validación es suficientemente robusto para decirnos que el modelo va a generalizar como corresponde en Test-Time. Pero acá no ocurre.

Los resultados que debieron haber obtenido muestran que el mejor puntaje de Validación se obtiene con Clipping de 150 pero no es el que generaliza mejor en Test. En test nuestro modelo actúa mejor con Clipping de 120. Lo que acaba de pasar es algo muy dificil de detectar (no sabría como hacerlo en tiempo real), nuestro modelo no está generalizando de manera apropiada. Y esto puede ser por varias razones:
- Nuestro esquema de Validación no es confiable.
- Tenemos algún error en nuestro código.
- No estamos capturando apropiadamente el error.
Detectar este tipo de Problemas es quizás de las Skills más complicadas de desarrollar, y para los que dicen que la Modelación Competitiva (Kaggle principalmente) no sirve, déjenme decirles que esto es precisamente la skill principal a desarrollar en competencias. Poder descubrir a ciegas si el modelo está generalizando de manera apropiada o no.
Me gustaría pensar que este problema se da por lo siguiente:
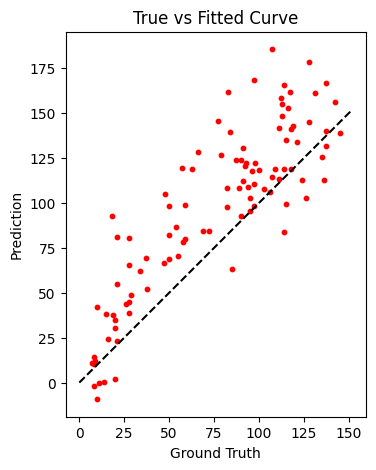
Nuestro modelo tiene predicciones bajo cero para RUL reales muy pequeños. Lo cual no refleja la realidad. Debemos pensar que el objetivo final del modelo es poder predecir de manera anticipada que nuestro motor fallará. Por lo tanto, no nos interesan valores negativos diciéndonos que la falla ya ocurrió. Para corregir realizaremos un Post-Procesamiento. Es decir, evitaremos que nuestro modelo prediga RUL menores a uno, de esa manera cuando hayan predicciones con 1 indicará que el motor está pronto a fallar. Quiero pensar que esto solucionará nuestro problema 😕.
Adicionalmente, intetaremos otro approach. Debido a la naturaleza temporal del problema generaremos variables que nos permitan modelar el problema en el tiempo. Para ello generaremos lags, variables con un desfase en el tiempo. Para ello trataremos de descubrir cuál es el mejor set de lags, dejando en este caso un RUL_CLIP fijo de 125.
Vamos a implementar esos cambios.
Archivo de Configuración params.yaml
base:
random_seed: 42
import:
train_name: train_FD001.txt
test_name: test_FD001.txt
rul_name: RUL_FD001.txt
featurize:
index_names: [unit_nr, time_cycles]
setting_names: [setting_1, setting_2, setting_3]
sensor_names: [s_1, s_2, s_3, s_4, s_5, s_6, s_7, s_8, s_9, s_10, s_11, s_12, s_13,
s_14, s_15, s_16, s_17, s_18, s_19, s_20, s_21]
to_keep: [s_2, s_3, s_4, s_6, s_7, s_8, s_9, s_11, s_12, s_13, s_14, s_15, s_17,
s_20, s_21]
lags:
- 1
- 2
- 3
- 4
- 5
- 10
- 20
- 30
train:
model_name: model.joblib
n_split: 5
rul_clip: 125
pred_clip: 1
standardize: true
En este nuevo archivo de configuración tenemos lo siguiente:
- En la etapa featurize mantenemos el parámetro
to_keep, que nos perrmitirá determinar con qué sensores queremos quedarnos. - Además agregamos los posibles lags que nos gustaría calcular. (La razón en utilizar - como separador es que cuando probamos listas como hiperparámetros DVC al sobreescribir el óptimo lo deja en ese formato).
- En la etapa agregamos dos parámetros nuevos:
standardizeque permitirá activar o no el StandardScaler, que es buena práctica para modelos lineales y que no veníamos realizando. Además fijamos elrul_clipa 125 y elpred_clipa 1.
Featurize
En esta etapa utilizaremos ahora la función create_features() cambiará de la siguiente forma:
def create_features(df_train, df_test, params):
to_keep = params['to_keep']
lag_features = []
for lag in params['lags']:
cols = [col + f'_lag_{lag}' for col in to_keep]
lag_features.extend(cols)
df_train[cols] = df_train.groupby('unit_nr')[to_keep].shift(lag)
df_test[cols] = df_test.groupby('unit_nr')[to_keep].shift(lag)
df_train.dropna(inplace = True)
df_test.dropna(inplace = True)
# selecting last instance to predict
df_test = df_test.groupby('unit_nr').last()
return df_train[to_keep + lag_features], df_test[to_keep + lag_features], df_train.rul
Esta función aceptará un set de train y test y creará los lags sólo para los sensores que vamos a dejar (los que entregan info de acuerdo a to_keep). Luego debido a la naturaleza del lag, quedarán observaciones con nulos, los cual simplemente los eliminaremos. También eliminaremos etiquetas, por lo que devolveremos el Train set y el Test set con las nuevas variables y las etiquetas de entrenamiento que sobrevivan a la eliminación de nulos.
La definición de features se ve mucho más sencilla ahora:
df_train = add_rul(df_train)
train_features, test_features, train_labels = create_features(df_train,
df_test,
params = params)
Notar que los set ingresados a create_features() son el train luego de crear el RUL y el test sin agrupar.
Train
Cuando entrenamos nuestro modelo ahora tendremos los siguientes cambios:
if params['standardize']:
model = Pipeline([('scaler', StandardScaler()),
('model', LinearRegression())])
else:
model = LinearRegression()
#======================================================
# Validation Metrics
#======================================================
folds = KFold(n_splits=params['n_split'],
shuffle=True,
random_state=Config.RANDOM_SEED)
mae = np.zeros(params['n_split'])
rmse = np.zeros(params['n_split'])
r2 = np.zeros(params['n_split'])
for fold_, (train_idx, val_idx) in enumerate(folds.split(X = train_features, y = train_labels)):
log.info(f'Training Fold: {fold_}')
X_train, X_val = train_features.iloc[train_idx], train_features.iloc[val_idx]
y_train, y_val = train_labels.iloc[train_idx], train_labels.iloc[val_idx]
# Training Clipping
model.fit(X_train, y_train.clip(upper = params['rul_clip']))
# Adding Prediction Clipping (Numpy)
val_preds = model.predict(X_val).clip(min = params['pred_clip'])
val_mae = mean_absolute_error(y_val, val_preds)
val_rmse = mean_squared_error(y_val, val_preds, squared=False)
val_r2 = r2_score(y_val, val_preds)
mae[fold_] = val_mae
rmse[fold_] = val_rmse
r2[fold_] = val_r2
log.info(f'Validation MAE for Fold {fold_}: {val_mae}')
log.info(f'Validation RMSE for Fold {fold_}: {val_rmse}')
log.info(f'Validation R2 for Fold {fold_}: {val_r2}')
Agregaremos la opción de un Pipeline de Estandarización y además al momento de Predecir aplicaremos Clipping mínimo (para evitar los RUL negativos).
El resultado de la predicción es un Numpy Array y el clipping en Numpy utiliza min, max en vez de lower, upper. Fue un dolor de cabeza inicialmente, porque no entendía por qué me arrojaba error.
Evaluate
En el caso de nuestro Evaluate, también debemos aplicar clipping.
model = joblib.load(Config.MODELS_PATH / 'model.joblib')
# Adding Prediction Clipping (Numpy)
y_pred = model.predict(X_test).clip(min = params['pred_clip'])
Proceso de Experimentación
DVC es sumamente inteligente, y podemos utilizarlo para hacer nuestra búsqueda de Hiperparámetros. DVC automáticamente detecta qué etapas se deben reejecutar y cuáles se pueden reutilizar dependiendo de nuestras dependencias definidas en dvc.yaml (ejecutando dvc_config.sh).
Para definir nuestra búsqueda de Hiperparámetros utilizarmos exp_config.sh para probar con distintos lags.
dvc exp run -S featurize.lags=[1,2,3,4,5]
dvc exp run -S featurize.lags=[1,2,3,4,5,6,7,8,9]
dvc exp run -S featurize.lags=[1,2,3,4,5,10,20,30]
dvc exp run -S featurize.lags=[1,2,3,4,5,10,20]
dvc exp run -S featurize.lags=[1,3,6,9,12,15]
Estudiaremos el efecto de los distintos niveles de Lag:
Ahora les toca poder ejecutar todo este proceso en Colab. ¿Mejoramos nuestros resultados? ¿Fue posible solucionar el problema de Generalización? ¿Y si quiero probar otro modelo? Cambia el tipo de Modelo a un Random Forest o a un XGBoost y cuéntame cómo te dan los resultados.
Habiendo entendido esta parte la verdad es que podrías utilizar cualquier modelo de Machine Learning Shallow (los clásicos, RF, XGB, LGBM, Catboost, incluso un Multilayer Perceptron) y no habrían grandes cambios. Variables extras pueden ir en featurize y el resto del Pipeline sigue igual.
Por eso es tan importante la parte de programación en Ciencia de Datos. Mucho del gran esfuerzo se hace al principio en el cual tenemos que dedicar mucho tiempo a un Pipeline robusto que nos permita experimentar de manera rápida y sencilla.
Consejo/Opinión muy personal:
- Utiliza Jupyter Notebooks cuanto quieras para explorar, visualizar, incluso cómo instrucciones de Reproducibilidad como estoy utilizandolo yo ahora.
- Vamos de a poco dejando de usar los Jupyter Notebooks. Lamentablemente este tipo de estructura para el core del código te fuerza a hacer códigos eternos y poco modulares. Uno se olvida de utilizar abstreaer en Clases o Funciones y copia y pega a veces incluso ejecutando en órdenes diferentes.
- Utiliza alguna herramienta de Automatización de Pipelines, yo uso DVC, pero está MAKE (que estoy empezando a revisar y posiblemente se vuelva un tutorial luego), Airflow (también viene luego), y un largo etc.
¿Y habrá parte 4?