Predecir el comportamiento del BitCoin
Bitcoin Price Prediction

Las criptomonedas son un tema apasionante. En el último tiempo se han convertido en el dolor de cabezas de los gamers (también de los modeladores de Deep Learning y de Nvidia que no sabe como producir más GPUs), ya que han provocado una escasez en el stock de GPUs, pero también han ayudado a ganar (y también a perder) dinero a mucha gente. Una de las catacterísticas más llamativas de este mercado es lo impredecibles que son y cómo comentarios de gente importante (tío Elon) pueden generar variaciones muy importantes de manera súbita. Hoy intentaremos predecir el comportamiento del precio del Bitcoin utilizando Pytorch Lightning, aplicando una de las que fueron las redes Neuronales más famosas antes de la era de los Transformers, las LSTM (Long Short-Term Memory).
Las LSTM son más que un tipo de red, se podría decir que es una configuración de varias redes neuronales cada una con un propósito en particular. Podríamos casi
llamarla una arquitectura. La principal característica que tienen es que poseen memoria, una característica que las hace ideal para trabajar con datos secuenciales, ya que puede utilizar datos del pasado para poder predecir el futuro
. Las LSTM Son la evolución de las RNN convencionales ya que introduciendo un cell state son capaces de solucionar el problema del vanishing gradient que éstas suelen sufrir.
Entender las redes recurrentes puede ser complicado y no es mi intención explicar en detalle la matemática de fondo de este tipo de redes. Pero para quienes les interese, pueden visitar el Colah’s Blog que es el lugar donde mejor se explica esta arquitectura (y de donde robé las siguientes imágenes).
Básicamente, una LSTM tiene distintas etapas (cada una una red neuronal) que se encargan de aprender o desaprender (espero que esta palabra exista) distintas partes. La primera es la forget gate. Esta red neuronal se encarga de olvidar, a medida que se entrena decide qué cosas ya no vale la pena recordar en futuras iteraciones.
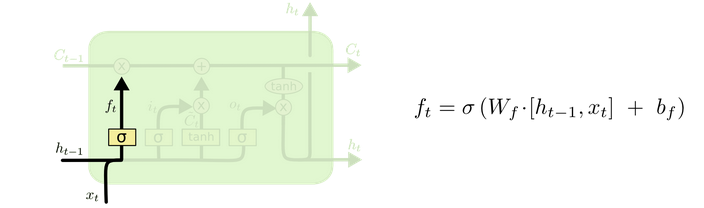
La input gate es la información que llega. El propósito de esta red neuronal es aprender qué aspectos son importantes de los nuevos datos de la secuencia
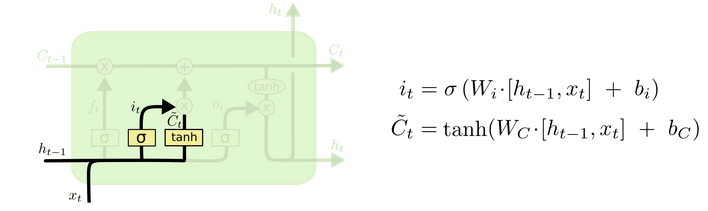
Esta información nueva debe combinarse con el output del forget gate dando paso al cell state. El cell state será la memoria y es la información nueva menos lo que tiene que olvidarse, es decir, toda la información que debe ser pasada a la siguiente iteración.
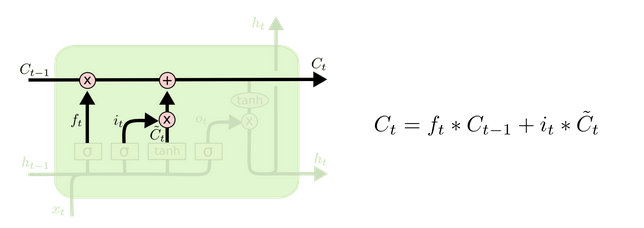
Finalmente el output será una red que decide la salida de la red considerando tanto la entrada (input gate) como la memoria (cell state). La gracia de una LSTM es que cada capa asociada (neurona LSTM) tendrá un output, pero además ese output pasará a la siguiente iteración como el hidden state.
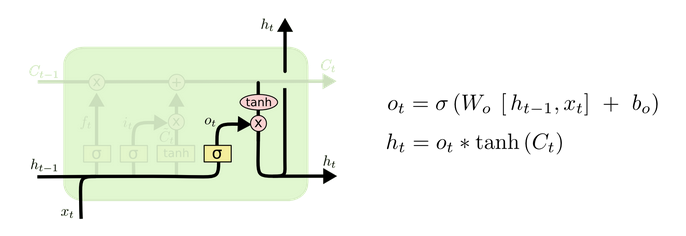
Para poder resolver este problema predictivo se ha utilizado data descargada desde Binance que corresponde a la información por minuto del precio del Bitcoin, la cual se puede descargar del siguiente sitio.
Al menos en mi caso descargué datos que van desde el 2019 hasta el 5 de Agosto de 2021 (sí, me demoré en poder generar un modelo decente para mostrar).
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
import matplotlib
import pandas as pd
import numpy as np
from tqdm.notebook import tqdm
from multiprocessing import cpu_count
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
import torchmetrics
%config InlineBackend.figure_format = 'retina'
sns.set(style = 'whitegrid', palette = 'muted', font_scale = 1.2)
HAPPY_COLORS_PALETTE = ['#01BEFE', '#FFDD00','#FF7D00','#FF006D','#ADFF02','#8F00FF']
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 6,4
tqdm.pandas()
RANDOM_SEED = 42
pl.seed_everything(RANDOM_SEED)
Global seed set to 42
Lo primero que haremos será entonces importar la data de Binance. Sólo destacar que se hace un parseo de la fecha y se ordena la data por fecha dado su caracter secuencial. Luego se reinicia el índice para evitar cualquier inconveniente posterior.
df = pd.read_csv('Binance_BTCUSDT_minute.csv', parse_dates = ['date']).sort_values(by = 'date').reset_index(drop = True)
df.shape
(997650, 10)
La cantidad de data extraída es bastante. Las redes recurrentes en general son redes lentas de entrenar debido precisamente a su caracter presencial. Para ayudar en el proceso de entrenamiento, evitar ruidos del pasado (aunque podría impactar en la estacionalidad) y permitir que otras personas sin GPU puedan reproducirlo, decidí entrenar sólo con la información de este año.
Debido a que la información está detallada al minuto, la estacionalidad debiera también revisarse a ese nivel. La LSTM debiera fijarse en minutos anteriores para predecir el minuto siguiente.
df.query('date > "2021-01-01"', inplace = True)
print(df.shape)
df
(306437, 10)
| unix | date | symbol | open | high | low | close | Volume BTC | Volume USDT | tradecount | |
|---|---|---|---|---|---|---|---|---|---|---|
| 691213 | 1609459260000 | 2021-01-01 00:01:00 | BTC/USDT | 28961.67 | 29017.50 | 28961.01 | 29009.91 | 58.477501 | 1.695803e+06 | 1651 |
| 691214 | 1609459320000 | 2021-01-01 00:02:00 | BTC/USDT | 29009.54 | 29016.71 | 28973.58 | 28989.30 | 42.470329 | 1.231359e+06 | 986 |
| 691215 | 1609459380000 | 2021-01-01 00:03:00 | BTC/USDT | 28989.68 | 28999.85 | 28972.33 | 28982.69 | 30.360677 | 8.800168e+05 | 959 |
| 691216 | 1609459440000 | 2021-01-01 00:04:00 | BTC/USDT | 28982.67 | 28995.93 | 28971.80 | 28975.65 | 24.124339 | 6.992262e+05 | 726 |
| 691217 | 1609459500000 | 2021-01-01 00:05:00 | BTC/USDT | 28975.65 | 28979.53 | 28933.16 | 28937.11 | 22.396014 | 6.483227e+05 | 952 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 997645 | 1628125260000 | 2021-08-05 01:01:00 | BTC/USDT | 39592.99 | 39600.00 | 39559.77 | 39570.02 | 33.148678 | 1.312017e+06 | 1462 |
| 997646 | 1628125320000 | 2021-08-05 01:02:00 | BTC/USDT | 39570.01 | 39570.01 | 39388.00 | 39396.36 | 207.697394 | 8.198434e+06 | 4960 |
| 997647 | 1628125380000 | 2021-08-05 01:03:00 | BTC/USDT | 39396.36 | 39440.69 | 39363.55 | 39434.95 | 121.355510 | 4.780575e+06 | 3329 |
| 997648 | 1628125440000 | 2021-08-05 01:04:00 | BTC/USDT | 39434.95 | 39436.77 | 39364.06 | 39369.67 | 46.405522 | 1.827913e+06 | 1604 |
| 997649 | 1628125500000 | 2021-08-05 01:05:00 | BTC/USDT | 39369.67 | 39394.00 | 39338.53 | 39361.02 | 38.950155 | 1.533056e+06 | 2341 |
306437 rows × 10 columns
Como se puede apreciar hay 16 variables. Se escogeran las que que ami parecer son más relevantes y crearemos algunas que nos permitan captar información temporal:
No soy para nada experto en temas de Trading. Mi única intención con este post es mostrar las capacidades que puede tener una red Neuronal para predecir el comportamiento del Bitcoin. Si este tema le interesa desde el punto de vista financiero o de trading le recomiendo seguir a Lautaro Parada, este cabro sabe y ha desarrollado algunas herramientas en Python para facilitar el tema financiero (ver más detalles acá)
Creación del Close Change
Esta es una variable que creo que puede ser significativa. Corresponde a cuánto cambió el precio del Bitcoin respecto al periodo anterior (en este caso al minuto anterior).
%%time
df['prev_close'] = df.shift(1)['close']
df['close_change'] = (df.close-df.prev_close).fillna(0)
df.head()
| unix | date | symbol | open | high | low | close | Volume BTC | Volume USDT | tradecount | prev_close | close_change | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 691213 | 1609459260000 | 2021-01-01 00:01:00 | BTC/USDT | 28961.67 | 29017.50 | 28961.01 | 29009.91 | 58.477501 | 1.695803e+06 | 1651 | NaN | 0.00 |
| 691214 | 1609459320000 | 2021-01-01 00:02:00 | BTC/USDT | 29009.54 | 29016.71 | 28973.58 | 28989.30 | 42.470329 | 1.231359e+06 | 986 | 29009.91 | -20.61 |
| 691215 | 1609459380000 | 2021-01-01 00:03:00 | BTC/USDT | 28989.68 | 28999.85 | 28972.33 | 28982.69 | 30.360677 | 8.800168e+05 | 959 | 28989.30 | -6.61 |
| 691216 | 1609459440000 | 2021-01-01 00:04:00 | BTC/USDT | 28982.67 | 28995.93 | 28971.80 | 28975.65 | 24.124339 | 6.992262e+05 | 726 | 28982.69 | -7.04 |
| 691217 | 1609459500000 | 2021-01-01 00:05:00 | BTC/USDT | 28975.65 | 28979.53 | 28933.16 | 28937.11 | 22.396014 | 6.483227e+05 | 952 | 28975.65 | -38.54 |
Creación de Variables temporales.
Estas variables son las que nos permitirán poder determinar posibles estacionalidades. Si bien es posible determinar muchísimas subdivisiones de tiempo, decidí que el día de la semana, el día del mes, la semana del año y el mes serían suficiente.
df = df.assign(
day_of_week = lambda x: x.date.dt.dayofweek,
day_of_month = lambda x: x.date.dt.day,
week_of_year = lambda x: x.date.dt.isocalendar().week,
month = lambda x: x.date.dt.month
)
df.head()
Es muy probable que aquí esté cometiendo un error, ya que estoy entrenando con menos de un año y puede que esté desaprovechando algunas de estas variables temporales. Inicialmente entrené con toda la data pero se demoraba demasiado (aunque sólo probé en el notebook). Es importante destacar que este proceso de entrenamiento es largo a pesar de que la data es muy poquita.
| unix | date | symbol | open | high | low | close | Volume BTC | Volume USDT | tradecount | prev_close | close_change | day_of_week | day_of_month | week_of_year | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 691213 | 1609459260000 | 2021-01-01 00:01:00 | BTC/USDT | 28961.67 | 29017.50 | 28961.01 | 29009.91 | 58.477501 | 1.695803e+06 | 1651 | NaN | 0.00 | 4 | 1 | 53 | 1 |
| 691214 | 1609459320000 | 2021-01-01 00:02:00 | BTC/USDT | 29009.54 | 29016.71 | 28973.58 | 28989.30 | 42.470329 | 1.231359e+06 | 986 | 29009.91 | -20.61 | 4 | 1 | 53 | 1 |
| 691215 | 1609459380000 | 2021-01-01 00:03:00 | BTC/USDT | 28989.68 | 28999.85 | 28972.33 | 28982.69 | 30.360677 | 8.800168e+05 | 959 | 28989.30 | -6.61 | 4 | 1 | 53 | 1 |
| 691216 | 1609459440000 | 2021-01-01 00:04:00 | BTC/USDT | 28982.67 | 28995.93 | 28971.80 | 28975.65 | 24.124339 | 6.992262e+05 | 726 | 28982.69 | -7.04 | 4 | 1 | 53 | 1 |
| 691217 | 1609459500000 | 2021-01-01 00:05:00 | BTC/USDT | 28975.65 | 28979.53 | 28933.16 | 28937.11 | 22.396014 | 6.483227e+05 | 952 | 28975.65 | -38.54 | 4 | 1 | 53 | 1 |
Finalmente me quedé con las siguientes variables. La única lógica que utilicé para escoger estas variables es mi sentido común y mi vago conocimiento de finanzas. Si alguien considera que algo más debió ser considerado (o que de frentón me qequivoqué) por favor no dude en notificarlo en mi github.
features_df = df[['day_of_week','day_of_month','week_of_year','month', 'open','high','low','close_change','close']].copy()
features_df
| day_of_week | day_of_month | week_of_year | month | open | high | low | close_change | close | |
|---|---|---|---|---|---|---|---|---|---|
| 691213 | 4 | 1 | 53 | 1 | 28961.67 | 29017.50 | 28961.01 | 0.00 | 29009.91 |
| 691214 | 4 | 1 | 53 | 1 | 29009.54 | 29016.71 | 28973.58 | -20.61 | 28989.30 |
| 691215 | 4 | 1 | 53 | 1 | 28989.68 | 28999.85 | 28972.33 | -6.61 | 28982.69 |
| 691216 | 4 | 1 | 53 | 1 | 28982.67 | 28995.93 | 28971.80 | -7.04 | 28975.65 |
| 691217 | 4 | 1 | 53 | 1 | 28975.65 | 28979.53 | 28933.16 | -38.54 | 28937.11 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 997645 | 3 | 5 | 31 | 8 | 39592.99 | 39600.00 | 39559.77 | -22.97 | 39570.02 |
| 997646 | 3 | 5 | 31 | 8 | 39570.01 | 39570.01 | 39388.00 | -173.66 | 39396.36 |
| 997647 | 3 | 5 | 31 | 8 | 39396.36 | 39440.69 | 39363.55 | 38.59 | 39434.95 |
| 997648 | 3 | 5 | 31 | 8 | 39434.95 | 39436.77 | 39364.06 | -65.28 | 39369.67 |
| 997649 | 3 | 5 | 31 | 8 | 39369.67 | 39394.00 | 39338.53 | -8.65 | 39361.02 |
306437 rows × 9 columns
Data Split
Como se trata de data secuencial el split de datos de validación no se puede (ni se debe) realizar de manera aleatoria. Si no más bien, toda la data, que llamaremos test, tiene que ser data posterior al proceso de entrenamiento siguiendo la secuencia lógica temporal.
Es por eso que decidí entrenar con el 90% de la data disponible y validar con el 10% restante:
train_size = int(len(features_df)* 0.9)
print('Number of Train Sequences: ', train_size)
train_df, test_df = features_df[:train_size], features_df[train_size + 1:] # + 1 is not necessary
train_df.shape, test_df.shape
Number of Train Sequences: 275793
((275793, 9), (30643, 9))
Estandarización
Finalmente para lograr una mejor convergencia de los datos generaremos una estadarización. Llevando todos los datos al rango -1, 1.
scaler = MinMaxScaler(feature_range=(-1,1))
train_df = pd.DataFrame(
scaler.fit_transform(train_df),
index = train_df.index,
columns = train_df.columns
)
test_df = pd.DataFrame(
scaler.transform(test_df),
index = test_df.index,
columns = test_df.columns
)
Creación de Secuencias
El formato inicial de la data no viene listo para ser usado en redes recurrentes. Como dije anteriormente, la aplicación de este tipo de Redes Neuronales se justifica siempre y cuando tengamos data secuencial. Esta data se construirá de la siguiente manera:
def create_sequences(input_data: pd.DataFrame, target_column, sequence_length):
sequences = []
data_size = len(input_data)
for i in tqdm(range(data_size - sequence_length)):
sequence = input_data[i: i+sequence_length] # No considero el último valor
label_position = i + sequence_length # Este es el último valor, usado de Label
label = input_data.iloc[label_position][target_column]
sequences.append((sequence, label))
return sequences
Esta función puede ser un poco dificil de explicar por lo que lo haré mediante un ejemplo. Supongamos el siguiente DataFrame:
sample_data = pd.DataFrame(dict(
feature_1 = [1,2,3,4,5],
label = [6,7,8,9,10]
))
sample_data
| feature_1 | label | |
|---|---|---|
| 0 | 1 | 6 |
| 1 | 2 | 7 |
| 2 | 3 | 8 |
| 3 | 4 | 9 |
| 4 | 5 | 10 |
Ejecutaremos la función de manera de crear secuencias de largo 3:
sample_sequences = create_sequences(sample_data, 'label', sequence_length=3)
Como se puede ver, esta función dejará 3 filas (largo de secuencia 3) para cada una de las variables contenidas en el DataFrame. Esos 3 registros tendrán como objetivo predecir el valor siguiente como se muestra en los siguientes ejemplos:
print()
print(f'label: {sample_sequences[0][1]}')
sample_sequences[0][0]
label: 9
| feature_1 | label | |
|---|---|---|
| 0 | 1 | 6 |
| 1 | 2 | 7 |
| 2 | 3 | 8 |
Debido a la definición de nuestra función sólo se pueden crear secuencias hasta que el último registro del dataframe exista. Por ejemplo la secuencia para los registros 2, 3, 4 no existe porque no es posible asociarle un label.
print()
print(f'label: {sample_sequences[1][1]}')
sample_sequences[1][0]
label: 10
| feature_1 | label | |
|---|---|---|
| 1 | 2 | 7 |
| 2 | 3 | 8 |
| 3 | 4 | 9 |
El modelo que queremos plantear acá es un modelo de Serie de Tiempo Multivariada. Una de las ventajas que poseen las redes neuronales es que es posible utilizar más de una variable (o lo que se llama también usar variables exógenas) para predecir el comportamiento de mi objetivo en el tiempo.
Por lo tanto para poder crear este modelo predictivo usaremos secuencias de largo 120, es decir, dos horas.
SEQUENCE_LENGTH = 120
train_sequences = create_sequences(train_df, 'close', SEQUENCE_LENGTH)
test_sequences = create_sequences(test_df, 'close', SEQUENCE_LENGTH)
print('Secuencias de Entrenamiento', len(train_sequences))
print('Diferencia entre Registros y Secuencias creadas: ', len(train_df) - len(train_sequences))
Secuencias de Entrenamiento 275673
Diferencia entre Registros y Secuencias creadas: 120
La diferencia entre el número de registros de un dataset y el número de secuencias creadas debe ser igual al largo de la secuencia. Estos valores corresponderán a la secuencia que no se puede crear debido a no poder crear el target.
Modelo
El modelo será construido en Pytorch Lightning debido a la facilidad de uso. Ya hemos vistos en post anteriores que cualquier modelo puede ser transformado en Lightning. La ventaja de Lightning es que el código quedará mucho más organizado y es posible configurar opciones avanzadas de manera mucho más sencilla.
Si quieres aprender la equivalencia entre un modelo en Pytorch Nativo y uno en Pytorch Lightning puedes ver este post.
Pytorch Dataset y Pytorch Data Module
A continuación crearemos el Pytorch Dataset, que se encargará de generar las secuencias, las cuales serán el DataFrame como se explicó anteriormente y el label que será el valor a predecir. Adicionalmente se crearán los Dataloaders en el Lightning Data Module. Los 3 dataloaders creados serán el de entrenamiento, el de validación y el de predicción. El dataloader de predicción se utilizará con la data de testeo que es con la que verificaremos si nuestro modelo responde como esperamos.
class BTCDataset(Dataset):
def __init__(self, sequences):
self.sequences = sequences
def __len__(self):
return len(self.sequences)
def __getitem__(self, idx):
sequence, label = self.sequences[idx]
return dict(
sequence = torch.tensor(sequence.to_numpy(), dtype = torch.float32),
label = torch.tensor(label, dtype = torch.float32)
)
class BTCPriceDataModule(pl.LightningDataModule):
def __init__(self, train_sequences, test_sequences, batch_size = 8):
super().__init__()
self.train_sequences = train_sequences
self.test_sequences = test_sequences
self.batch_size = batch_size
def setup(self, stage = None):
self.train_dataset = BTCDataset(self.train_sequences)
self.test_dataset = BTCDataset(self.test_sequences)
def train_dataloader(self):
return DataLoader(
self.train_dataset,
batch_size=self.batch_size,
pin_memory=True,
num_workers=cpu_count(),
shuffle = False
)
def val_dataloader(self):
return DataLoader(
self.test_dataset,
batch_size=1,
pin_memory=True,
num_workers=cpu_count(),
shuffle = False
)
def predict_dataloader(self):
return DataLoader(
self.test_dataset,
batch_size=1,
pin_memory=True,
num_workers=cpu_count(),
shuffle = False
)
Es importante destacar que todos los dataloader están paralelizados utilizando todos los cores disponibles y haciendo un pin_memory para aprovechar mejor la GPU. El modelo fue entrenado en Jarvis por lo que utilizó una RTX 3090 como GPU, la cual redujo el tiempo de entrenamiento casi 4 veces (de 8 minutos a menos de 2) y se paralelizó en 16 hilos.
Pytorch Model y Lightning Module
El modelo utilizado para este problema es una red neuronal LSTM que tendrá 9 neuronas (una para cada variable a utilizar). Contará con 128 celdas LSTM y 2 capas. Además a modo de regularización usarmos un dropout de un 20%.
class PricePredictionModel(nn.Module):
def __init__(self, n_features, n_hidden = 128, n_layers = 2):
super().__init__()
self.n_hidden = n_hidden
self.lstm = nn.LSTM(
input_size = n_features,
hidden_size = n_hidden,
batch_first = True,
num_layers = n_layers,
dropout = 0.2
)
self.regressor = nn.Linear(n_hidden, 1)
def forward(self, x):
#self.lstm.flatten_parameters() # for distributed training
_, (hidden, _) = self.lstm(x)
#print("Shape of LSTM output: ", hidden.shape)
out = hidden[-1]
#print('Shape of out: ', out.shape)
x = self.regressor(out)
#print(x.shape)
return x
class BTCPricePredictor(pl.LightningModule):
def __init__(self, n_features: int):
super().__init__()
self.model = PricePredictionModel(n_features)
self.criterion = nn.MSELoss()
def forward(self, x, labels = None):
output = self.model(x)
loss = 0
if labels is not None:
loss = self.criterion(output, labels.unsqueeze(dim = 1))
return loss, output
return output
def training_step(self, batch, batch_idx):
sequences = batch['sequence']
labels = batch['label']
loss, output = self(sequences, labels)
self.log('train_loss', loss, prog_bar = True, logger = True)
return loss
def validation_step(self, batch, batch_idx):
sequences = batch['sequence']
labels = batch['label']
loss, output = self(sequences, labels)
self.log('val_loss', loss, prog_bar = True, logger = True)
def predict_step(self, batch, batch_idx):
sequences = batch['sequence']
labels = batch['label']
loss, output = self(sequences, labels)
return labels, output
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr = 1e-4)
Para entrenar definimos training_step, validation_step y predict_step para ser consistente con los dataloaders creados anteriormente. El modelo está siendo optimizado mediante Adam, con un learning rate de 1e-4 usando el MSELoss como función de costo.
Cabe destacar que para efectos de la gráfica que queremos construir al final del artículo, el predict_step() devolverá tanto la etiqueta real como la etiqueta predicha (esta es una de las flexibilidades que entrega Lightning para evitar duplicación de loops).
Entrenamiento del Modelo
Finalmente para el entrenamiento del modelo se utilizará:
- 8 Epochs con EarlyStopping, eso quiere decir que si en 2 epochs no hay mejora en el score de validación el entrenamiento se termina.
- Usaremos un Batch Size de 64 secuencias que se irán pasando por la red a la vez.
- Se utilizará un Model Checkpoint, almacenando el mejor modelo de las epochs ejecutadas.
- Se forzará a que el modelo entrene al menos por 3 epochs antes de poder activar el Early Stopping.
N_EPOCHS = 8
BATCH_SIZE = 64
model = BTCPricePredictor(n_features = 9)
dm = BTCPriceDataModule(train_sequences, test_sequences, batch_size=BATCH_SIZE)
#model(item['sequence']).shape
mc = ModelCheckpoint(
dirpath='checkpoints',
filename = 'best-checkpoint',
save_top_k=1,
verbose = True,
monitor='val_loss',
mode = 'min'
)
early_stop = EarlyStopping(monitor = 'val_loss', patience = 2)
trainer = pl.Trainer(
deterministic = True
min_epochs = 3,
callbacks = [mc, early_stop],
max_epochs = N_EPOCHS,
gpus = 1,
progress_bar_refresh_rate = 30
)
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
trainer.fit(model, dm)
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
---------------------------------------------------
0 | model | PricePredictionModel | 203 K
1 | criterion | MSELoss | 0
---------------------------------------------------
203 K Trainable params
0 Non-trainable params
203 K Total params
0.814 Total estimated model params size (MB)
Global seed set to 42
Epoch 0, global step 4307: val_loss reached 0.01444 (best 0.01444), saving model to "/home/alfonso/Documents/binance/checkpoints/best-checkpoint-v1.ckpt" as top 1
Epoch 1, global step 8615: val_loss was not in top 1
Epoch 2, global step 12923: val_loss was not in top 1
El modelo se entrenó por 3 epochs, en las cuales tuvo dos casos sin mejoría por lo que se detuvo.
trained_model = BTCPricePredictor.load_from_checkpoint(
'checkpoints/best-checkpoint-v1.ckpt',
n_features = 9
)
trained_model
BTCPricePredictor(
(model): PricePredictionModel(
(lstm): LSTM(9, 128, num_layers=2, batch_first=True, dropout=0.2)
(regressor): Linear(in_features=128, out_features=1, bias=True)
)
(criterion): MSELoss()
)
trained_model.freeze()
trainer.validate(model = model)
--------------------------------------------------------------------------------
DATALOADER:0 VALIDATE RESULTS
{'val_loss': 0.014435895718634129}
--------------------------------------------------------------------------------
Verificación en datos de validación
preds = trainer.predict(model = trained_model, dataloaders = dm.val_dataloader())
labels = torch.tensor(preds)[:,0]
predictions = torch.tensor(preds)[:,1]
Es importante destacar acá que devolvimos etiquetas y labels. Transformando el output en tensor es posible obtener dos tensores independientes de cada set de etiquetas.
Creación de un Descaler
Es importante recordar que para el proceso de entrenamiento toda la data fue escalada. Por lo tanto para ver efectivamente nuestro resultado se necesita traerla a la escala real. Para ello se hace el siguiente truco para poder aprovechar el inverse_transform de Scikit-Learn.
descaler = MinMaxScaler()
descaler.min_, descaler.scale_ = scaler.min_[-1], scaler.scale_[-1]
scaler.min_ y scaler.scale_ son los parámetros aprendidos por MinMaxScaler. Basicamente acá estamos simulando un entrenamiento artificial utilizando sólo los parámetros de nuestro label.
def descale(values, descaler = descaler):
values_2d = np.array(values)[:, np.newaxis]
return descaler.inverse_transform(values_2d).flatten()
predictions_descaled = descale(predictions)
labels_descaled = descale(labels)
test_data = df[train_size + 1:]
len(test_data), len(test_df)
(30643, 30643)
Luego verificamos que los datos de test sean consistentes con lo que generamos, ambos deben entregarnos el mismo número de registros.
Finalmente, tenemos que notar que no es posible generar predicciones para las secuencias menores al largo de Secuencia ya que no cuentan con secuencias necesarias para predecir. Por lo tanto, generamos el siguiente set de secuencias para luego extraer la fecha:
test_sequences_data = test_data.iloc[SEQUENCE_LENGTH:]
len(test_sequences_data), len(test_sequences)
(30523, 30523)
test_sequences_data.head()
| unix | date | symbol | open | high | low | close | Volume BTC | Volume USDT | tradecount | prev_close | close_change | day_of_week | day_of_month | week_of_year | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 967127 | 1626294180000 | 2021-07-14 20:23:00 | BTC/USDT | 32794.15 | 32800.00 | 32772.74 | 32779.19 | 6.164449 | 202108.117635 | 278 | 32794.15 | -14.96 | 2 | 14 | 28 | 7 |
| 967128 | 1626294240000 | 2021-07-14 20:24:00 | BTC/USDT | 32780.65 | 32808.76 | 32780.64 | 32804.94 | 24.302589 | 797120.586022 | 388 | 32779.19 | 25.75 | 2 | 14 | 28 | 7 |
| 967129 | 1626294300000 | 2021-07-14 20:25:00 | BTC/USDT | 32804.93 | 32823.71 | 32804.93 | 32817.51 | 10.519932 | 345226.325132 | 359 | 32804.94 | 12.57 | 2 | 14 | 28 | 7 |
| 967130 | 1626294360000 | 2021-07-14 20:26:00 | BTC/USDT | 32814.92 | 32823.42 | 32812.00 | 32820.00 | 5.496652 | 180388.987189 | 284 | 32817.51 | 2.49 | 2 | 14 | 28 | 7 |
| 967131 | 1626294420000 | 2021-07-14 20:27:00 | BTC/USDT | 32819.99 | 32843.55 | 32819.96 | 32821.31 | 11.457531 | 376199.073946 | 351 | 32820.00 | 1.31 | 2 | 14 | 28 | 7 |
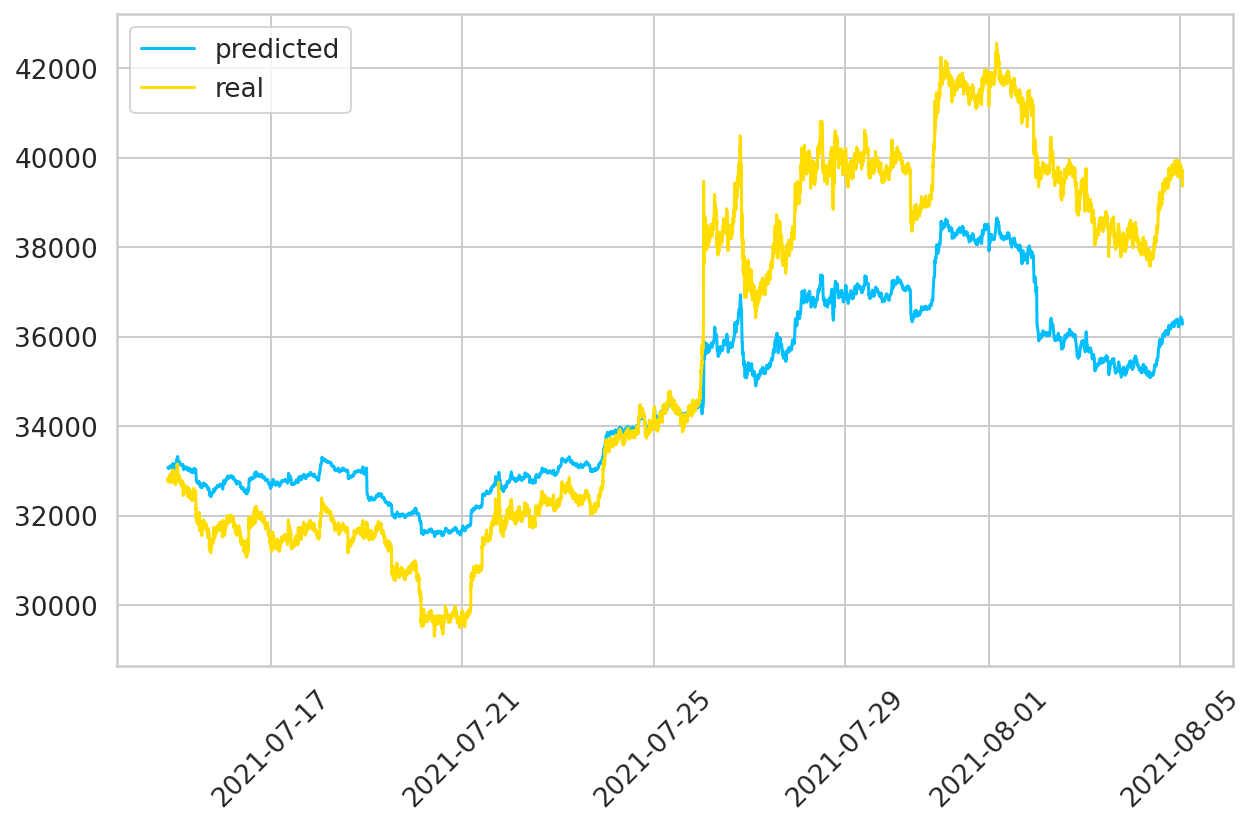
Finalmente graficamos los valores reales del periodo de Test y los obtenidos por nuestra predicción:
dates = matplotlib.dates.date2num(test_sequences_data.date.tolist())
plt.figure(figsize = (10,6))
plt.plot_date(dates, predictions_descaled, '-', label = 'predicted')
plt.plot_date(dates, labels_descaled, '-', label = 'real')
plt.xticks(rotation = 45)
plt.title('Predicción BitCoin 2021')
plt.legend();
Disclaimer
No soy experto en temas de Finanzas ni Criptomonedas por lo que si se quiere aplicar modelos como estos para sus inversiones asegúrese de asesorarse. No creo que sea un modelo malo, pero si tengo las siguientes consideraciones:
- Tanto el entrenamiento como la validación está medido en datos del pasado, y funciona bien. Pero este modelo no puede predecir que Elon Musk de algún comunicado y el precio se del BitCoin se caiga de un día para otro.
- Si bien logra predecir de muy buena manera las tendencias, no predice la magnitud correcta.
- Probablemente entrenando por más epochs y/o utilizando más data puede ayudar.
- Quizás una buena idea sea eliminar el Early Stopping y dejar que el modelo entrene las 8 epochs completas.
- Un mejor afinamiento de hiperparámetros puede ser de gran utilidad.
Espero que este tutorial haya sido de ayuda y se pueda entender el gran potencial que se tiene al utilizar redes neuronales.
UPDATE TL;DR
Luego de subir este post recibí algunos comentarios acerca de la metodología utilizada. Quiero agradecer particularmente a Mario Leni, quien me compartió el siguiente video en el cual se critican algunas de las prácticas utilizadas para la predicción de Stocks y me gustaría hacer algunos comentarios al respecto:
- Primero, el video está subido por un tipo que se denomina LazyProgrammer. He tenido la oportunidad algunos cursos de él en Udemy y la verdad es que explica super bien. En su sitio web menciona que tiene 2 Masters:
- Uno en Computer engineering con Especialización en Machine Learning y Reconocimiento de Patrones (largo el nombre)
- Y uno en estadísticas. Que el tipo tiene credenciales tiene…
Ahora, es muy extraño como parte su video porque no me gusta mucho su tono. Tiene un tono agradable de voz pero igual usa palabras que encuentro pesadas. Es raro porque siento que su video es medio pataleta (como un berrinche) porque la gente está equivocada y reclama varias cosas sin una estructura lógica (pero igual hace propaganda a sus cursos):
- Que nadie escribe su código.
- Que uno copia y pega arrastrando errores.
- Que está mal utilizar el
MinMaxScaler(algo que yo hice en mi implementación y se supone es su reclamo principal). - Que no se debe usar el precio, sino que los returns.
Que nadie escribe su código
Eso es cierto, una de las ventajas del código es poder reutilizarlo, y poder reproducir algo que alguien más hizo sin que tenga que demostrar cómo lo hizo. En mi caso yo sí tomé el código de varios otros posteos, pero no estaba en Pytorch Lightning. De hecho, yo lo adapté y sufrí harto para hacerlo funcionar, y entrenar el modelo costó, por eso la diferencia entre la data que saqué hasta que lo publiqué.
Que uno copia y pega arrastrando errores
Es posible, en mi caso, siempre me cuestiono lo que hago con mi código para entenderlo. No suelo comprar lo que todos dicen. De hecho, especialmente en el mundo Pytorch hay mucho código boilerplate que uno solamente copia y pega sin saber para qué sirve. Yo no puedo con eso, me quita el sueño colocar código que no entiendo y siempre trato de estar super conciente de por qué se aplica cada parte. Una crítica que él reclamaba en particular es el hecho de usar secuencia de largo 1. Es muy probable que sea un error, y que mucha gente no se lo cuestione (básicamente no es una secuencia). En mi caso usé secuencias de 120.
Es interesante que en un punto dice que no se puede predecir stocks como secuencias, porque son aleatorios (~2:40). Creo que esa es precisamente la idea de las redes recurrentes: ver si es que hay algún patrón difícil de encontrar al ojo humano y aprender de él. Pero aprender no significa repetir, el punto que él menciona me da la impresión que se refiere a redes que hacen overfitting, toman el patrón y lo repiten por que no saben generalizar. Si fuera porque nada realmente es una secuencia porque es aleatorio, no podríamos predecir nada.
Que está mal utilizar el MinMaxScaler
Es raro, reclama todo el rato que está mal hacerlo pero al final dice que no está tan mal (~10:00). Su punto es que a diferencia de las ondas, el stock price no está acotado por lo tanto no puedo asumir el máximo como 1 y el mínimo como -1. Yo personalmente creo que esto está mal. El MinMaxScaler sólo mueve la escala, en ningún momento obliga a la red neuronal a predecir en el rango -1 a 1. De hecho, la implementación tiene como capa de salida una red densamente conectada sin función de activación (esto por ser un problema de regresión). Por lo tanto, al no tener una función sigmoide no está forzada a predecir en este rango.
Entiendo que las redes neuronales no se caractarizan por su capacidad de extrapolar, y aquí puede ser que implícitamente estamos colocando un techo a la red. Pero de nuevo el objetivo de este tipo de post es mostrar cómo se entrena un modelo de serie de tiempos, no volverse rico invirtiendo en BitCoin.
Que no se debe usar el precio, sino que los returns
Este punto no lo entiendo. Si me interesa investigar el precio, tratar de entender hasta cuanto va a llegar el precio, ¿por qué debería usar el return? Su razón es que no tiene tendencia. Bueno si la tendencia es el problema de la serie de tiempo de Precios, se puede quitar la tendencia aplicando diferenciación. Es muy sencillo de aplicar y me permite no tener que cambiar la variable que quiero monitorear. Probablemente si quiero ganar plata el return es una mejor opción, pero aún así no me calza la crítica.
Yo creo que está bien criticar cuando uno ve un proceso incorrecto. Pero en particular en el uso de redes neuronales, donde ni los Kaggle GrandMasters están 100% seguros de lo que hacen, no me parece la manera. El inglés no es mi idioma nativo, pero estoy casi seguro que idiotic
(~3:00) no es una palabra buena onda. Y la conclusión que saco es que hace una crítica sólo para vender sus cursos.
Creo que una de las características que tienen que primar en este campo es la humildad. He visto código horriblemente malo de Phds, Kaggle Grandmasters, incluso he visto errores de concepto por parte de LazyProgrammer (tomé uno de sus cursos y aplicaba un Softmax a la salida de un problema multiclase utilizando como Loss Function CrossEntropy Loss, un concepto incorrecto y que se desaconseja/desaprueba en los foros de Pytorch), pero este es un campo en desarrollo, nadie sabe realmente cómo funcionan las Redes Neuronales. Y usando su mismo argumento, si él sí sabe como hacer Stock Prediction, por qué no es millonario invirtiendo en BitCoin (o quizás ya lo es 🤔).
Sorry por lo latero,
Nos vemos la próxima,