Las visualizaciones no me gustan, así que a reciclar.
Crear Funciones reutilizables para plotear
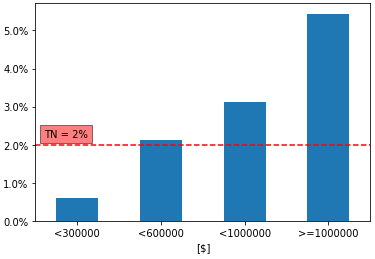
En mi nuevo trabajo me dí cuenta que utilizan un cierto tipo de gráfico para mostrar el impacto de una variable en particular sobre el target. Me carga hacer visualizaciones, así que decidí crear automatizar la creación de estos gráficos.
Normalmente tenemos una tasa natural de ocurencia de un evento, que se muestra como la línea segmentada TN. Y normalmente se tiene una variable dividida en categorías/segmentos/tramos que es la tasa de que ocurra ese evento por el bin utilizado.
Dado que este gráfico gusta bastante y se utiliza mucho es que decidí crear una función simple que permita evitar el ajetreo de graficar esto cada vez. Para esto voy a utilzar nuevamente el dataset del Titanic el cual también pueden descargar por Terminal si tienen la API de Kaggle.
$ kaggle competitions download -c titanic
import pandas as pd
df = pd.read_csv('train.csv')
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Signing_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1911-05-17 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1911-07-23 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1911-09-08 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1911-06-26 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1911-10-25 |
Este data set se utiliza normalmente para predecir la tasa de supervivencia de los pasajeros del Titanic. En este caso la variable target es Survived.
df.Survived.value_counts(normalize = True)
0 0.616162
1 0.383838
Name: Survived, dtype: float64
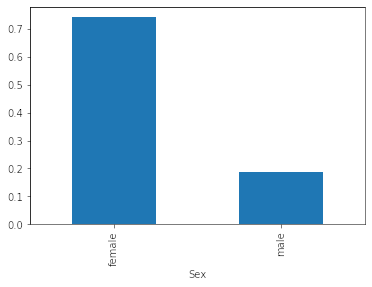
Se puede notar que el 61% de los pasajeros no sobrevivió el desastre del Titanic, pero ¿hay alguna diferencia si tomamos subconjuntos de los datos? Por ejemplo si analizamos la supervivencia por Sexo el resultdo que esperaría sería otro:
df.groupby(['Sex']).Survived.value_counts(normalize = True)
Sex Survived
female 1 0.742038
0 0.257962
male 0 0.811092
1 0.188908
Name: Survived, dtype: float64
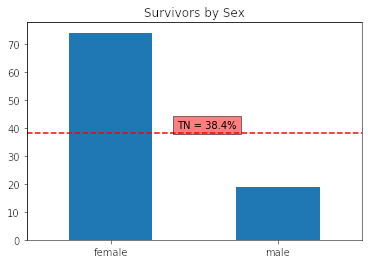
En realidad, al hacer el split por Sexo notamos que el 74% de las mujeres sobrevevivieron, mientras que sólo el 18% de los hombre sobrevivió. Entonces, ¿existe alguna buena manera de graficar esto? Nuestro objetivo es mostrar sólo la tasa de supervivencia (porque la tasa de muertes no es más que el complemento) y mostrar como se compara en contra de la tasa natural.
Un truco
Para datos que son binarios (como en el caso de nuestra variable Survived) es posible calcular la tasa de supervivencia de la siguiente forma:
df.groupby('Sex').Survived.mean()
Sex
female 0.742038
male 0.188908
Name: Survived, dtype: float64
import matplotlib.pyplot as plt
df.groupby('Sex').Survived.mean().plot(kind = 'bar')
plt.show()
Entonces vamos a crear la función plot_rate_by(). Esto dará flexibilidad a nuestra implementación permitiendo agregar funcionalidades como agregar título, o dejar que funcione para cualquier dataframe.
def plot_rate_by(data,by,Target, TN, title, x, y, x_label = None, rot = 0):
TN *=100 # converts to percentage
# plots ading title, and optional label rotation
ax = (data.groupby(by)[Target].mean()*100).plot(kind = 'bar', title = title, rot = rot)
plt.axhline(TN, color = 'r', linestyle = '--') # adds dashed line
# adds the red text box, in coordinates x and y to avoid overlapping
plt.text(x,y,f'TN = {TN}%',bbox=dict(facecolor='red', alpha=0.5))
ax.set_xlabel(x_label) # optional Label for the x Axis
return plt.show()
import numpy as np
# Natural Rate for survivors
tn = np.round(df.Survived.value_counts(normalize = True).loc[1],3)
plot_rate_by(df, by = 'Sex', Target = 'Survived', TN = tn,
title = 'Survivors by Sex', x = 0.4, y = 40, x_label = None)
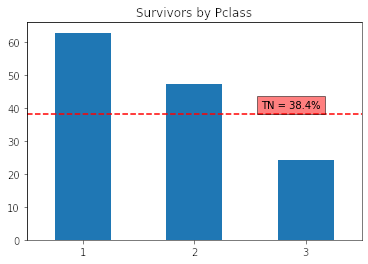
Esto se puede aplicar a cualquier variable categórica, por ejemplo, Pclass:
plot_rate_by(df, by = 'Pclass', Target = 'Survived', TN = tn, title = 'Survivors by Pclass', x = 1.6, y = 40, x_label = None)
Otra cosa que normalmente pasa en mi trabajo es que quien aplicar una lógica similar pero utilizando variables continuas. EL tema es que esto no lo hacen de manera directa sino que utilizando un binning previo. Esto puede ser realizado relativamente sencillo combinando numpy y pandas. Por lo tanto tratemos de gráficar la tasa de supervivencia por rango de tarifa Fare, para ello crearemos bins para tarifas <10, <100, <300 y >=300.
Para ello haré uso de una función llamada np.select. El nombre puedo ser poco informativo, pero básicamente devuelve un valor dependiendo de una condición. (sí, muy parecido a if/elif, pero bastante más eficiente).
# lista de condiciones
condlist = [df.Fare < 10, df.Fare < 100, df.Fare < 300, df.Fare >= 300]
# lista de elecciones.
choicelist = ['<10','<100','<300','>=300']
df['Fare_binning'] = np.select(condlist, choicelist)
df[['Fare','Fare_binning']]
| Fare | Fare_binning | |
|---|---|---|
| 0 | 7.2500 | <10 |
| 1 | 71.2833 | <100 |
| 2 | 7.9250 | <10 |
| 3 | 53.1000 | <100 |
| 4 | 8.0500 | <10 |
| ... | ... | ... |
| 886 | 13.0000 | <100 |
| 887 | 30.0000 | <100 |
| 888 | 23.4500 | <100 |
| 889 | 30.0000 | <100 |
| 890 | 7.7500 | <10 |
891 rows × 2 columns
Normalmente uno no sabe qué binnings mostrarán de mejor manera los datos previamente, por lo que es necesario que este tipo de operaciones sea sumamente flexible.¿Cómo transformar esto en una función?
vals_l = [10,100,300]
LUego podemos usar un for loop para crear las condiciones.
En pandas es posible intercambiar los operadores $<$ y $\geqslant$ por los métodos .lt() y .ge() lo cual entrega un poco más de flexibilidad al código.
condlist = []
choicelist = []
for v in vals_l:
condlist.append(df['Fare'].lt(v))
choicelist.append('<'+str(v))
condlist.append(df['Fare'].ge(vals_l[-1]))
choicelist.append('>='+str(vals_l[-1]))
choicelist
['<10', '<100', '<300', '>=300']
Una vez que hemos creado todas las categorías de manera correcta, se puede combinar todo dentro de una función:
def convert_to_range(data, field, vals_l):
vals_l = vals_l
condlist = []
choicelist = []
for v in vals_l:
condlist.append(data[field].lt(v))
choicelist.append('<'+str(v))
condlist.append(data[field].ge(vals_l[-1]))
choicelist.append('>='+str(vals_l[-1]))
return pd.Categorical(np.select(condlist, choicelist),
categories=choicelist, ordered = True)
Para asegurar que los tramos salgan en el orden correcto dentro del gráfico, es super importante que los bins creados sean de tipo Categórico y que estén ordenados. (Ver return)
df['binning_function'] = convert_to_range(df,'Fare',vals_l)
df[['Fare_binning','binning_function']]
| Fare_binning | binning_function | |
|---|---|---|
| 0 | <10 | <10 |
| 1 | <100 | <100 |
| 2 | <10 | <10 |
| 3 | <100 | <100 |
| 4 | <10 | <10 |
| ... | ... | ... |
| 886 | <100 | <100 |
| 887 | <100 | <100 |
| 888 | <100 | <100 |
| 889 | <100 | <100 |
| 890 | <10 | <10 |
891 rows × 2 columns
Podemos usar nuestra función anterior plot_rate_by() para graficar:
plot_rate_by(df, by = 'binning_function', Target = 'Survived', TN = tn, title = 'Survivors by Fare Categories', x = -0.3, y = 42, x_label = None)
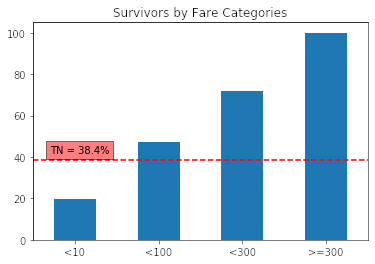
Podemos notar que se obtienen resultados equivalente que al usar variables categóricas y con la misma flexibilidad.
Espero que esto demuestre que el no gustarte algo puede transformarse en algo entretenido, que es automatizar, y no tener que prestarles tanta atención en el futuro.