¿Cómo implementar Naive Bayes en Scikit-Learn?
Naive Bayes como modelo Baseline
Hace unos días tuve que preparar una clase mostrando los beneficios de utilizar un modelo como el de Naive Bayes.
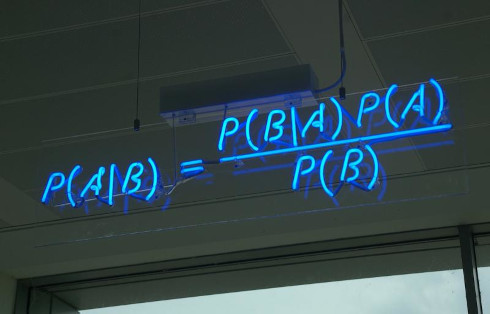
Tengo que decir que no es un modelo tremendamente poderoso, principalmente porque realiza algunos supuestos que la mayoría de las veces no son ciertos. Sin embargo, noté que a pesar de ello puede ser bastante útil para como un modelo base. Las ventajas es que no es un modelo muy dificil de implementar y la verdad es que es súper rápido.
Bueno la teoría detrás de este modelo, corresponde a un modelo de clasificación que está basado en el teorema de Bayes en la que se puede calcular la probabilidad a posteriori $P[y | X]$, es decir, la probabilidad de que ocurra un evento (en este caso nuestro target) siendo que se conocen previamente nuestras variables predictoras $X$.
Naive Bayes es un modelo generativo que se define de la siguiente manera: \[P[y|X] = \frac{P[X | y] \cdot P[y]}{P[X]}\]
y el proceso de Predicción del modelo se realiza de la siguiente manera: \[y = k = argmax\, P[y = k] \cdot \prod{}_{i = 1}^p P[X_i/y = k]\]
Es decir la clase predicha es aquella que tiene la máxima probabilidad de ocurrencia dado las variables predictoras.
A modo de ejemplo, se realizará una implementación de este modelo utilizando un dataset de Letras de Canciones el cual puede encontrarse en el siguiente link.
Agradecimientos a Hitesh Yalamanchili por disponibilizar este dataset.
Implementación en Python
Utilizando Scikit-Learn trateremos de predecir el género de las canciones por medio de su letra.
Importación de los datos
Al intentar importar los datos, noté que éstos tenían la siguiente forma:
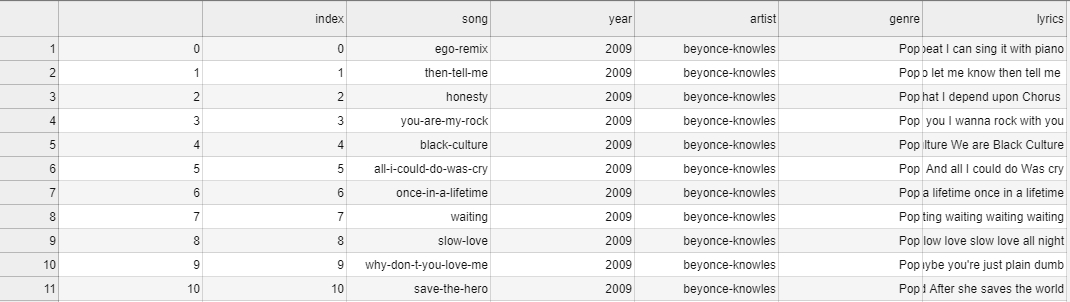
Por alguna razón hay un índice duplicado, uno sin nombre y otro llamado index. Para evitar problemas de importación y una columna muy molesta que suele aparecer llamada Unnamed: 0 es que utilice el argumento names de pd.read_csv. Aún así el índice duplicado aparecía por lo que se hizo el siguiente workaround:
Nota: Para hacer el dataset más manejable decidí sólo utilizar 4 de los géneros disponibles: Rock, Pop, Hip-Hop y Metal
%%time
import pandas as pd
df = pd.read_csv('english_cleaned_lyrics.csv',
header = 0,
names = ['song','year','artist','genre', 'lyrics'],
index_col = None).reset_index(level = 1, drop = True)
df.query('genre in ["Rock","Pop","Hip-Hop","Metal"]', inplace = True)
df
Wall time: 3.32 s
| song | year | artist | genre | lyrics | |
|---|---|---|---|---|---|
| 0 | ego-remix | 2009 | beyonce-knowles | Pop | Oh baby how you doing You know I'm gonna cut r... |
| 1 | then-tell-me | 2009 | beyonce-knowles | Pop | playin everything so easy it's like you seem s... |
| 2 | honesty | 2009 | beyonce-knowles | Pop | If you search For tenderness It isn't hard to ... |
| 3 | you-are-my-rock | 2009 | beyonce-knowles | Pop | Oh oh oh I oh oh oh I If I wrote a book about ... |
| 4 | black-culture | 2009 | beyonce-knowles | Pop | Party the people the people the party it's pop... |
| ... | ... | ... | ... | ... | ... |
| 362210 | photographs-you-are-taking-now | 2014 | damon-albarn | Pop | When the photographs you're taking now Are tak... |
| 362211 | you-and-me | 2014 | damon-albarn | Pop | I met Moko jumbie He walks on stilts through a... |
| 362212 | hollow-ponds | 2014 | damon-albarn | Pop | Chill on the hollow ponds Set sail by a kid In... |
| 362213 | the-selfish-giant | 2014 | damon-albarn | Pop | Celebrate the passing drugs Put them on the ba... |
| 362214 | hostiles | 2014 | damon-albarn | Pop | When the serve is done And the parish shuffled... |
178054 rows × 5 columns
Feature Extraction
Esta corresponde a la etapa en la que las letras de las canciones deben ser transformadas en algo que el modelo pueda efectivamente entender. Para ello se utilizará CountVectorizer() de scikit-learn el cual permitirá crear una matriz de ocurrencias, es decir, creará una matriz de dimensiones Número de Canciones $\times$ Número de Palabras con el conteo de palabras en cada canción. Se realizará un pequeño preprocesamiento al set de datos en el cual sólo se eliminarán las “Stopwords”.
Cada conteo de palabras se utilizará entonces como una variable predictora para determinar el género de cada canción.
%%time
from sklearn.feature_extraction.text import CountVectorizer
## Se eliminan las stopwords y solo dejan las 20000 palabras más frecuentes
c_vec = CountVectorizer(stop_words = 'english', max_features = 20000)
vectorizer = c_vec.fit_transform(df['lyrics'])
Wall time: 35.6 s
pd.DataFrame(vectorizer.toarray(), columns = c_vec.get_feature_names())
| 00 | 000 | 02 | 03 | 05 | 06 | 07 | 09 | 10 | 100 | ... | zones | zonin | zoo | zoom | zoomin | zoovie | zoovier | zoowap | zu | zulu | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 178049 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 178050 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 178051 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 178052 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 178053 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
178054 rows × 20000 columns
Warning: El número de palabras a utilizar va influir directamente en el desempeño final del modelo. En general los modelos de Machine Learning suelen funcionar mejor entre más datos tienen, pero ojo el RAM disponible para no matar el PC.
Setup del Modelo
El modelo es super fácil de setear. En este caso se utilizará un MultiomialNB debido a que se trata de un modelo de Clasificación Multiclase. Adicionalmente, se generará un split de datos apropiados para evitar problemas de “data leakage” y finalmente la construcción de un Pipeline con todos los procesos. Las métricas para medir el desempeño del modelo se mostrarán a través de classification_report.
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import confusion_matrix, classification_report
X_train, X_test, y_train, y_test = train_test_split(df['lyrics'],
df['genre'],
test_size = 0.4,
random_state = 123)
$X$ corresponde a la matriz de palabras, mientras que $y$ corresponde al vector de géneros
%%time
text_clf = Pipeline(steps = [
('cv', CountVectorizer(stop_words = 'english', max_features = 20000)),
('nb', MultinomialNB(alpha = 0.1))
])
#Entrenamiento del modelo
text_clf.fit(X_train, y_train)
#Predicción en el Test set para medir desempeño
y_pred = text_clf.predict(X_test)
Wall time: 26.4 s
Lo primero positivo a notar es que a pesar de ser un modelo con 178K filas y 20K columnas se entrenó sumamente rápido, esa es definitivamente una de las ventajas de Naive Bayes.
En términos de resultados, no es un tremendo modelo, 63% de Accuracy y un 62% de Macro F1.
print(classification_report(y_test,y_pred))
precision recall f1-score support
Hip-Hop 0.72 0.77 0.74 9062
Metal 0.48 0.75 0.59 8551
Pop 0.42 0.53 0.47 13582
Rock 0.78 0.60 0.68 40027
accuracy 0.63 71222
macro avg 0.60 0.66 0.62 71222
weighted avg 0.66 0.63 0.63 71222
{: title="Métricas del modelo"}
Cómo mejorar el Modelo
Evidentemente no estamos trabajando con el mejor modelo existente, pero sí es posible realizar algunos pequeños ajustes que logren ciertas mejorías. En este caso utilizaremos GridSearch para variar el valor del hiperparámetro $\alpha$ correspondiente a un parámetro de suavización que evita que la probabilidad a posteriori sea cero con eventos no vistos, además aplicaremos un 5-Fold Cross Validation para una mayor robustez al evaluar su desempeño.
%%time
from sklearn.model_selection import GridSearchCV
parameters = {'nb__alpha': [0, 0.001, 0.01, 0.1, 0.5, 1] }
text_clf = Pipeline(steps = [
('cv', CountVectorizer(stop_words = 'english')),
('nb', MultinomialNB())
])
searchCV = GridSearchCV(text_clf, parameters, n_jobs = -1, scoring = 'f1_macro', cv = 5)
searchCV.fit(X_train, y_train)
Wall time: 3min 27s
GridSearchCV(cv=5,
estimator=Pipeline(steps=[('cv',
CountVectorizer(stop_words='english')),
('nb', MultinomialNB())]),
n_jobs=-1, param_grid={'nb__alpha': [0, 0.001, 0.01, 0.1, 0.5, 1]},
scoring='f1_macro')
El GridSearch toma alrededor de 3 minutos para correr 6 modelos utilizando 5-Fold CV (osea 30 modelos). Los resultados se muestran a continuación:
best_nb = searchCV.best_estimator_ # Extracting Best Model
y_pred = best_nb.predict(X_test) # Predicting the Test Set
print(classification_report(y_test,y_pred))
precision recall f1-score support
Hip-Hop 0.73 0.77 0.75 9062
Metal 0.56 0.70 0.62 8551
Pop 0.45 0.49 0.47 13582
Rock 0.76 0.69 0.73 40027
accuracy 0.66 71222
macro avg 0.63 0.66 0.64 71222
weighted avg 0.67 0.66 0.67 71222
Se pudo notar que aplicar las técnicas anteriores generaron las siguientes mejoras:
- Accuracy mejora 3%.
- Macro F1 mejoró 2%.
- La categoría Rock es la que mejoró más con un salto de f1 de 68 a 73%.
- Igual hay que notar un trade-off, mientras algunas clases mejoran hay otras que bajan su desempeño como por ejemplo el Metal. Es por eso que siempre el mejor modelo debe ser siempre definido dependiendo del objetivo final y no porque tenga “todas las métricas buenas”.
Como dice el dicho:
“…Todos los modelos están incorrectos, pero algunos son útiles” George E.P. Box
Para terminar se puede ver que el parámetro óptimo en este caso es $\alpha=1$
best_nb.named_steps.nb.get_params()
{'alpha': 1, 'class_prior': None, 'fit_prior': True}
Espero que con este pequeño ejemplo se pueda apreciar que con pocas líneas de código es posible crear un modelo relativamente sencillo con un desempeño decente.
Nos vemos!!