¿Por qué me cambié a Pytorch?
Tensorflow vs Pytorch
Los que me conocen saben que era un claro detractor de Python. Mi lenguaje favorito era R. Y debo decir que mucho de mi aprendizaje en Ciencia de Datos fue en R. Mis primeros modelos de Machine Learning fueron en dicho lenguaje y con lo contento que estaba nunca pensé que, hoy por hoy, el 95% de mi trabajo sería en Python. De hecho, perdí un trabajo y oportunidades importantes por estar cerrado en querer llegar a equipos que me permitieran trabajar sólo en R.

 Mi porfía se debía principalmente a que quería trabajar en lenguajes entretenidos, que tuvieran librerías que me permitieran implementar cosas entretenidas (créanme R tiene muchas, y aún sigo creyendo que, en reportería y automatización de Documentos, R es muy superior). Les voy a contar algo, pero no quiero que esto se vea como mi justificación para decir que R no es un buen lenguaje. Long story super short, una vez entrené un modelo chiquito de Random Forest en una maquina gigante en Azure y se caía (maté varias maquinas virtuales). Esto porque R estaba fallando por memory leakage. En palabras simples, una vez que R terminaba un proceso no estaba liberando la memoria RAM para ser ocupada en otro proceso. Y esto era particularmente caótico en procesos paralelizados. Lo cual en Modelos de Machine Learning era un real fiasco.
Mi porfía se debía principalmente a que quería trabajar en lenguajes entretenidos, que tuvieran librerías que me permitieran implementar cosas entretenidas (créanme R tiene muchas, y aún sigo creyendo que, en reportería y automatización de Documentos, R es muy superior). Les voy a contar algo, pero no quiero que esto se vea como mi justificación para decir que R no es un buen lenguaje. Long story super short, una vez entrené un modelo chiquito de Random Forest en una maquina gigante en Azure y se caía (maté varias maquinas virtuales). Esto porque R estaba fallando por memory leakage. En palabras simples, una vez que R terminaba un proceso no estaba liberando la memoria RAM para ser ocupada en otro proceso. Y esto era particularmente caótico en procesos paralelizados. Lo cual en Modelos de Machine Learning era un real fiasco.
 Esto me llevó a cuestionarme por qué Python era tan alabado cuando se trataba de ML, en ese tiempo por Scikit-Learn. Al probar Scikit-Learn (fue un poco abrumante al principio) pero encontré que era LA HERRAMIENTA para ML. Sentí que estaba demasiado bien pensado (entre otras cosas, creo que el approach orientado a objetos funciona mucho mejor que un approach funcional cuando se trata de entrenar modelos), era “rápido”, fácilmente paralelizable y la documentación era espectacular, lleno de ejemplos. Además en la web podías encontrar muchos tutoriales para aprender. Siento que moverme a Python me ayudó a aprender que hay herramientas específicas para tareas específicas (de hecho, todavía uso R para crear mis slides, porque siento que
Esto me llevó a cuestionarme por qué Python era tan alabado cuando se trataba de ML, en ese tiempo por Scikit-Learn. Al probar Scikit-Learn (fue un poco abrumante al principio) pero encontré que era LA HERRAMIENTA para ML. Sentí que estaba demasiado bien pensado (entre otras cosas, creo que el approach orientado a objetos funciona mucho mejor que un approach funcional cuando se trata de entrenar modelos), era “rápido”, fácilmente paralelizable y la documentación era espectacular, lleno de ejemplos. Además en la web podías encontrar muchos tutoriales para aprender. Siento que moverme a Python me ayudó a aprender que hay herramientas específicas para tareas específicas (de hecho, todavía uso R para crear mis slides, porque siento que Xaringan es la mejor librería para crear slides de manera programática, así como no hay símil para Bookdown, hice mi Tesis ahí).
Bueno, el tema es que mi Tesis está hecha en R, usé Keras para hacer Redes Convolucionales, y fue un parto. Probablemente porque no sabía usarlo bien. Además en R, Keras tiende a correr más lento, dado que hay que instalarlo en un ambiente Anaconda de Python. A eso sumar que Tensorflow 1 es %#-& malo. Al menos la documentación es como dispersa, hay muchas maneras de hacer lo mismo, nunca entendí bien la diferencia entre la API Secuencial y Funcional, debuggear es difícil y olvídense de hacerlo funcionar con GPU, es un parto. Al migrar a Python, pensé que utilizar Tensorflow (más bien Keras, conozco muy poca gente que use Tensorflow puro) directamente en Python iba a ser mejor. Pero no, instalarlo en Ubuntu, fue un cacho, tanto así que rompió los drivers de mi primera instalación y tuve que instalar Ubuntu from scratch (muy mala experiencia).
Ahí es cuando durante el 2019 partió el Boom de Pytorch, empezó a sonar harto, todos lo amaban. Yo recuerdo haber leído la documentación. Era sumamente clara, y como que inmediatamente me dieron ganas de apreneder a usarlo, pero no me dedicaba mucho al Deep Learning por lo que quedó en eso. Además me molestaba que requiriera el uso de clases. Yo estaba recién cambiandome de un lenguaje funcional a uno OOP por lo que no manejaba bien los conceptos. En el desafío Binnario intenté una red en Keras (que por cierto me dio malísima) y no pude encontrar implementaciones en Keras que siquiera pudiera entender. Y por otra parte encontré mucho material en Pytorch. De hecho si miran en Kaggle o Youtube, casi todo el mundo está implementando tutoriales en Pytorch, rara vez en Keras o Tensorflow.
MIS OPINIONES al respecto:
- Creo que el cambio de Tensorflow 1 a 2 es tremendo, la API y los docs son mucho más ordenados, pero el cambio rompió mucho código en producción y creo que mucha gente se enojó por eso.
- Dado que Pytorch tenía un enfoque más en Research, era mucho más fácil conseguir implementaciones de Problemas no tradicionales: Question Answering, Machine Translation, Object Detection, Semantic Segmentation, etc. No sé si yo no sé buscar, pero no tengo idea de cómo hacer eso en Tensorflow.
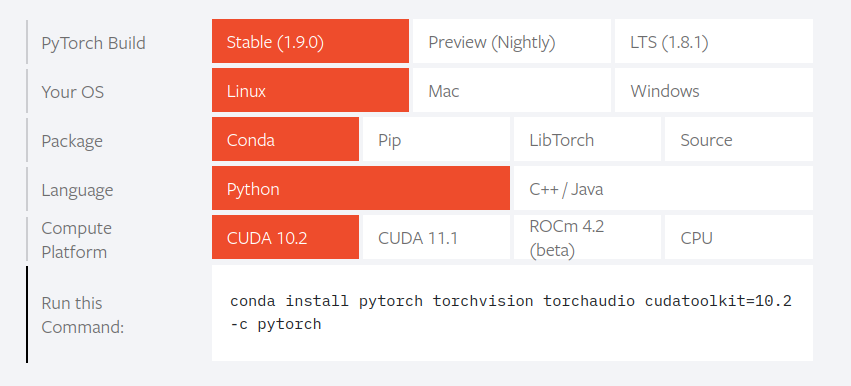
- La instalación de Pytorch es lo más simple que existe, vas a este link y escoges las características de tu sistema operativo y voilá, inmediatamente te dice como instalar en tu package manager, listo!!. Quienes han intentado ejecutar Tensorflow en GPU saben el parto que es.
Cudnn,Nvidia-Toolkit, algunas variables de entorno. Además de que no puedes usar los últimos drivers de Nvidia ni las últimas versiones de Python, porque Tensorflow siempre va varios pasos más atrás, por lo que si por algún error llegas a actualizar algo de manera automática Tensorflow dejará de funcionar. Y los errores son crípticos y difíciles de solucionar.
- Además, es raro, es como un lenguaje compilado (al menos TF 1, en la v2 eso se corrigió con grafos dinámicos), si falla algo, no sabes en qué falló, y hay que tener harta experiencia para debuggear.
- Tensorflow es rápido, pero siempre tienes miedo de que si falla no vas a saber qué hacer para solucionarlo.
Ahora, ¿Pytorch es perfecto? La verdad es que no. MIS OPINIONES al respecto:
- Hay una mentalidad o un flujo de trabajo en Pytorch que hay que entender. Siento que se requiere más conocimiento en programación en Pytorch que en Keras. Pero es más familiar. Si soy buen programador en Python, también lo soy en Pytorch. En Tensorflow no me pasaba eso.
- Es muuuuucho más verboso. Hay mucho código boilerplate. Partiendo porque debes crear las clases Datasets, crear los DataLoaders, crear la clase del modelo, crear un loop de entrenamiento (creo que es lo más tedioso, por qué no colocar un
.fit()y ya?), además de crear incluso loops para medir el accuracy. Pero no todo es malo, de hecho hay un beneficio en la verbosidad de Pytorch y es que uno puede entender todos los pasos (teóricos) de un entrenamiento:
for epoch in range(epochs):
model.train()
t0 = datetime.now()
train_loss = []
for batch in train_loader:
inputs, targets = batch['image'].to(device), batch['label'].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss.append(loss.item()) # for every batch
model.eval()
test_loss = []
for inputs, targets in test_loader:
inputs, targets = batch['image'].to(device), batch['label'].to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss.append(loss.item())
train_losses[epoch] = np.mean(train_loss)
test_losses[epoch] = np.mean(test_loss)
dt = datetime.now()-t0
print(f'Epoch {epoch + 1}/{epochs}, Train Loss : {train_losses[epoch]},
Test Loss: {test_losses[epoch]}, Duration: {dt}')
- Un
forque representa cada epoch. - Un
Dataloader(en otrofor) que representa cómo se cargan los datos Batch por Batch. - Un traspaso de los datos a la GPU, para que se realicen los cálculos tensoriales.
- La definición de que el modelo se encuentra en
trainoevalmode. Esto para mí fue aprender algo que nunca supe que ocurria en Tensorflow. Capas como el dropout o BatchNorm tienen comportamientos distintos en train o test. Por ejemplo, el dropout en train se desconcecta en la proporción dada para evitar sobre-entrenamiento (y así el sobreajuste), pero al momento de Inferencia hay que reconectarlos. optimizer.zero_grad()representa que los gradientes se van a acumular, partiendo en cero.- Se cargan los inputs al modelo representando el viaje de los datos a través de la red (Forward Propagation). Esto mientras se acumulan los gradientes para actualizar los pesos.
- Se calcula el loss para medir cuán incorrecto está el modelo epoch a epoch.
- Se lleva a cabo el proceso de backpropagation, definido específicamente por
loss.backward()mostrando el momento preciso donde se están calculando las derivadas del Loss Function respecto a cada parámetro de la red. optimizer.step()representa la actualización de los pesos utilizando el proceso de optimización elegido: SGD, Adam, RMSProp, etc.
Estoy seguro de que muchos Data Scientist no teníamos idea de todo lo que pasa en el entrenamiento de una Red Neuronal. Normalmente no vamos más allá de hacer un fit y entender cuáles son los pasos que se tienen que llevar a cabo para que un algoritmo efectivamente aprenda.
- Se hace un trade-off, la falta de abstracción y exceso de verbosidad a cambio de entender qué está pasando en el proceso de entrenamiento.
- Hay dos approaches también, usar módulos que heredan de nn.Module o la API funcional.
- E inicialmente hay que aprender de los errores. Es más fácil de debuggear que Keras/Tensorflow, pero igualmente tiene su curva de aprendizaje.
- Pytorch tiende a ser un pelo más lento que Tensorflow. Pero sorprendentemente ha entregado para un mismo modelo mejores resultados que su símil entrenado en Tensorflow. Y se puede ver que muchas competencias en Kaggle se ganan usando Pytorch. De hecho Pytorch multi-GPU, es medio competitivo con Tensorflow en TPU.
Todo esto, obviamente no es perfecto, pero es algo por lo que estoy dispuesto a pasar con el objetivo de entender mucho mejor qué es lo que hace una red neuronal mientras se entrena.
Ahora, ¿significa que codear en Pytorch es más lento? La verdad es que no, se han creado sub-frameworks como Pytorch Ignite, FastAI y, el que más me gusta a mí, Pytorch Lightning; que evitan el Boilerplate pero sin abstraer tanto como para no entender que pasa (como sí lo hace Keras).
Una cosa que quiero aclarar es que Tensorflow NO es peor que Pytorch. Es una herramienta mucho más madura en ambientes de producción y sigue siendo el framework más usado. Además tiene versiones en Javascript, que permiten correr en el navegador, versiones Lite para dispositivos móviles y versiones en C++. Pytorch viene de Torch programado creo que en Lua, tiene versión Mobile, y versiones elásticas para deployment en producción pero son más nuevas y no tan adoptados todavía. Pero si pensamos que Python es uno de los lenguajes más adoptados (en términos de programadores que usan el lenguaje) y, programar en Pytorch es muy similar sino igual que en Python, hace sentido que esté ganando popularidad rapidamente.
Espero no haberme metido en rollos tan técnicos como para que gente se sienta intimidada a leer, y para los que sí nos gusta la parte técnica, sea igual de interesante.