Combinando Git con DVC
Github para Data Science Pt. 2

Al parecer muchos encontraron que es una excelente idea aprender GIT para llevar un proceso ordenado de desarrollo en Ciencia de Datos. Pero también es cierto, que cuando se ideó GIT, la Ciencia de Datos como disciplina no estaba en el radar, y menos el proceso de entrenamiento de un Modelo. Hoy en día el MLOps está más de moda que nunca y todavía no es claro un framework único en el cuál se pueda llevar un verdadero control del proceso de modelamiento.
Para solucionar el problema de cómo logramos el control de un desarrollo de Machine Learning se creó DVC. DVC significa “Data Version Control” y no puede ser un peor nombre, porque si bien se diseñó como una alternativa para poder llevar control de versiones de la data en realidad es una aplicación que es mucho más que sólo eso.
DVC
DVC nace de la necesidad de solucionar uno de los grandes problemas de GIT/Github que es el almacenamiento de grandes archivos (que son pan de cada día en Ciencia de Datos). La idea es que DVC permita reproducir archivos generados sin la necesidad de tener que re-ejecutar un código (esto porque esto podría tomar mucho tiempo). Pero luego DVC comienza a evolucionar y creo que la gran ventaja que tiene es que permite generar Pipelines Reproducibles (de ML o cualquier otro proceso complejo de datos) y evitar ejecutar etapas cuando no es necesario.
Mientras realiza eso, DVC permite generar light-commits para experimentos, trackear parámetros, guardar métricas, incluso generar plots para poder monitorear el proceso de ML primeramente, pero es extendible para cualquier proceso de Datos.
DVC es un software agnóstico de Clouds, OS, ML frameworks, etc. Además es open source por lo que realmente vale la pena incorporarlo en los procesos de desarrollo de Ciencia de Datos porque casi no tiene boilerplate ni overhead asociado.
Además iterative.ai ha seguido desarrollando herramientas para Ciencia de Datos, entre ellas procesos de CI/CD (el cual ya estoy aprendiendo para traer en otro tutorial) de modo de permitir un desarrollo ágil (me refiero en el sentido de rápido, no haciendo tonteras como Scrum) y en el que pueda incluso estar involucrada gente no técnica.
Modelo de ML con Data de la NBA
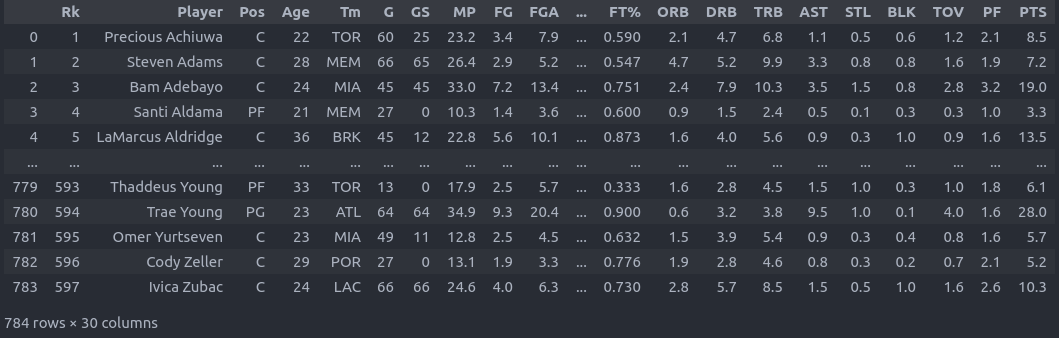
La NBA está muy buena estos días, y encontré un dataset del año pasado con todas las estadísticas de los jugadores. Propongo utilizar este dataset para utilizar las estadísticas para predecir la posición en la que juega un jugador. Este es un modelo muy sencillo multiclase, y más que el desarrollo del modelo lo que nos importa acá es como poder operacionalizar un proceso de desarrollo del modelo.
Aún así, la data se ve como esto:
El Pipeline de Modelamiento lo vamos a descomponer en 4 partes: Creación del Dataset, Creación/Eliminación de Features, Entrenamiento y Evaluación.
El código va así:
from pathlib import Path
class Config:
RANDOM_SEED = 123
ASSETS_PATH = Path('./assets')
FILE_PATH = ASSETS_PATH / 'original_data' / 'nba_stats.csv'
DATASET_PATH = ASSETS_PATH / 'data'
FEATURES_PATH = ASSETS_PATH / 'features'
MODELS_PATH = ASSETS_PATH / 'models'
METRICS_PATH = ASSETS_PATH / 'metrics.json'
Vamos básicamente a definir una semilla aleatoria para garantizar reproducibilidad y definir distintas carpetas para guardar los archivos crudos, el dataset spliteado, features, modelos y métricas.
Luego, voy a descargar el dataset desde Google Drive. Para ello uso la librería gdown. La descarga se va a realizar luego de crear las carpetas assets y data.
import gdown
import pandas as pd
from sklearn.model_selection import train_test_split
Config.FILE_PATH.parent.mkdir(parents=True, exist_ok=True)
Config.DATASET_PATH.mkdir(parents=True, exist_ok=True)
gdown.download(
'https://drive.google.com/uc?id=1rwnNapcxlPM_DrYwBPSEC9uWVyEy70D1',
str(Config.FILE_PATH)
)
nba_df = pd.read_csv(Config.FILE_PATH, encoding='latin-1', sep = ';')
train_df, test_df = train_test_split(nba_df, test_size=0.25, random_state=Config.RANDOM_SEED)
train_df.to_csv(Config.DATASET_PATH / 'train.csv', index = None)
test_df.to_csv(Config.DATASET_PATH / 'test.csv', index = None)
Como se puede ver voy a ir almacenando todos los resultados de cada etapa. Pensando en que normalmente los procesos de ML incluyen data grande y pesada la idea es poder liberar memoria cuando se pueda, además de utilizarlos como checkpoints en caso de que algun proceso posterior falle.
Config.FEATURES_PATH.mkdir(parents=True, exist_ok=True)
train_df = pd.read_csv(Config.DATASET_PATH / 'train.csv')
test_df = pd.read_csv(Config.DATASET_PATH / 'test.csv')
def featurize(df):
df.query('Tm != "TOT"', inplace = True)
X = df.drop(columns = ['Rk','Player', 'Tm', 'Pos'])
y = df.Pos
return X,y
X_train, y_train = featurize(train_df)
X_test, y_test = featurize(test_df)
X_train.to_csv(Config.FEATURES_PATH / 'train_features.csv', index = None)
X_test.to_csv(Config.FEATURES_PATH / 'test_features.csv', index = None)
y_train.to_csv(Config.FEATURES_PATH / 'train_labels.csv', index = None)
y_test.to_csv(Config.FEATURES_PATH / 'test_labels.csv', index = None)
Al chequear el Dataset noté de que habían jugadores con un equipo llamado TOT. Esto significa que estuvieron en más de un equipo, lo cual implica que algunos jugadores tengan asignada más de una posición. Por lo tanto, este proceso se encargará de eliminar esos registros por simplicidad además de eliminar un ranking, el nombre del jugador, el equipo y la posición. Esto porque sólo nos interesa utilizar estadísticas para predecir la posicion de un jugador.
from sklearn.linear_model import LogisticRegression
import joblib
Config.MODELS_PATH.mkdir(parents=True, exist_ok=True)
X_train = pd.read_csv(Config.FEATURES_PATH / 'train_features.csv')
y_train = pd.read_csv(Config.FEATURES_PATH / 'train_labels.csv')
model = LogisticRegression(max_iter=10000, random_state=Config.RANDOM_SEED)
model.fit(X_train, y_train.to_numpy().ravel())
joblib.dump(model, Config.MODELS_PATH / 'model.joblib')
El entrenamiento es muy sencillo, sólo entrenaremos una regresión logística, ya que formularemos el problema como un problema de clasificación multiclase. El modelo va a ser serializado en formato joblib (si les interesa saber por qué no pickle puedan mirar acá).
import json
from sklearn.metrics import accuracy_score, recall_score
model = joblib.load(Config.MODELS_PATH / 'model.joblib')
X_test = pd.read_csv(Config.FEATURES_PATH / 'test_features.csv')
y_test = pd.read_csv(Config.FEATURES_PATH / 'test_labels.csv')
y_pred = model.predict(X_test)
output = dict( test_accuracy = accuracy_score(y_test, y_pred),
test_recall = recall_score(y_test, y_pred, average='macro'))
with open(Config.METRICS_PATH, 'w') as outfile:
json.dump(output, outfile)
Finalmente me interesa poder evaluar el comportamiento del modelo para poder determinar cómo le va. Esto lo hacemos con el modelo ya entrenado, pero evaluando sus predicciones en data no vista del test set.
Hasta acá es el proceso normal que se utiliza para entrenar un modelo. Obviamente, está un poco simplificado, ya que no estamos considerando estrategias de validación más avanzadas o tuning de hiperparámetros, pero creo que se entiende la idea.
Normalmente todo este proceso lo colocamos dentro de un Jupyter Notebook que suele ser la fuente de varias malas prácticas para experimentar. Si te sientes identificado con alguna es normal, todos lo hemos hecho alguna vez:
- Copiar y pegar el código abajo y modificar la Regresión Logística con otro modelo.
- Tener varios modelos comentados e ir descomentando dependiendo del que nos vaya dejando mejores resultados.
- Borrar de frentón un pedazo de código que no resultó y reemplazarlo por el que ahora nos parece funcionará mejor.
¿Cómo lo solucionamos?
Una opción es usar hydra. Tengo varios tutoriales que de hecho pueden revisar. Si bien Hydra es una muy buena herramienta, siento que tiene varios inconvenientes:
- Si bien lleva registros de los runs, sólo los puedes guardar de manera local. Es posible utilizar callbacks para almacenar en plataformas como S3, pero todo ese trabajo debes implementarlo por tu cuenta.
- Almacena los runs exitosos y los fallidos, por lo que cuando estás recién testeando puede guardar muchos logs de errores que no aportan mucho.
- Hydra es una librería de bajo nivel, por lo que cualquier idea que tengas hay que implementarla por cuenta propia.
- Tiene poco boilerplate, pero tiene. Eso quiere decir que el proceso de experimentación está dentro del código, lo cual enreda un poco el debugging cuando nos interesa el proceso del código y no el esqueleto de experimentación.
Con esto no quiero bajo ningún motivo decir que Hydra no es una buena herramienta. De hecho tengo varios proyectos en producción hechos en Hydra y voy a seguir recomendándola.
DVC abstrae todo eso. No hay que intervenir nuestro código con ningún código boilerplate para llevar registro. Y eso es maravilloso. Además permite separar el proceso en distintas etapas conectadas en forma de DAG (como Airflow, Metaflow, etc.) pero sin agregar código extra, sino que generando un archivo de configuración. Finalmente permite parametrizar el proceso desde un archivo YAML tal y como Hydra pero sin utilizar Omeconf ni decoradores extras.
Por fa, díganme que no suena prometedor.
Transformando nuestro proyecto en DVC.
Si bien tenemos que aplicar cambios, la verdad es que no son tantos. Como DVC está pensando en utilizar buenas prácticas de diseño de software lo primero será transformar nuestro Jupyter Notebook en un grupo de Scripts modularizados:
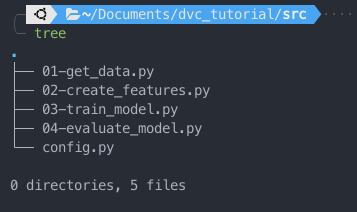
Cada uno de los archivos contendrá cada una de las etapas descritas anteriormente. Además el archivo config.py contendrá la clase de Configuración que definimos inicialmente.
Además definiremos un archivo llamado params.yaml, el cual se ve como sigue:
base:
random_seed: 123
data:
file_name: nba_stats.csv
features:
remove: [Rk, Player, Tm, Pos]
train:
C: 1
max_iter: 10000
model_name: model.joblib
Este archivo contiene parámetros para distintas etapas del proceso:
- base: Contiene la semilla aleatoria.
- data: El nombre del archivo original. A veces esto podría variar porque hay distintas versiones que incluyen información actualizada a un cierto periodo, etc.
- features: En este caso particular contiene una lista de features a eliminar.
- train: Contiene hiperparámetros específicos de la Regresión Logística y el nombre del modelo a serializar.
Luego nuestros scripts quedarán de la siguiente manera:
from pathlib import Path
import yaml
# importación de los parámetros desde el archivo params.yaml
with open('params.yaml') as file:
params = yaml.safe_load(file)
class Config:
RANDOM_SEED = params['base']['random_seed']
ASSETS_PATH = Path('./assets')
FILE_PATH = ASSETS_PATH / 'original_data' / params['data']['file_name']
DATASET_PATH = ASSETS_PATH / 'data'
FEATURES_PATH = ASSETS_PATH / 'features'
MODELS_PATH = ASSETS_PATH / 'models'
METRICS_PATH = ASSETS_PATH / 'metrics.json'
Acá llamamos desde params.yaml el random seed y el nombre del archivo a importar.
import gdown
import pandas as pd
from sklearn.model_selection import train_test_split
from config import Config
Config.FILE_PATH.parent.mkdir(parents=True, exist_ok=True)
Config.DATASET_PATH.mkdir(parents=True, exist_ok=True)
gdown.download(
'https://drive.google.com/uc?id=1rwnNapcxlPM_DrYwBPSEC9uWVyEy70D1',
str(Config.FILE_PATH)
)
nba_df = pd.read_csv(Config.FILE_PATH, encoding='latin-1', sep = ';')
train_df, test_df = train_test_split(nba_df, test_size=0.25, random_state=Config.RANDOM_SEED)
train_df.to_csv(Config.DATASET_PATH / 'train.csv', index = None)
test_df.to_csv(Config.DATASET_PATH / 'test.csv', index = None)
En este archivo llamamos los nombres de features a eliminar.
import pandas as pd
from config import Config
import yaml
#importamos sólo los parámetros relevantes para features
with open('params.yaml') as file:
params = yaml.safe_load(file)['features']
Config.FEATURES_PATH.mkdir(parents=True, exist_ok=True)
train_df = pd.read_csv(Config.DATASET_PATH / 'train.csv')
test_df = pd.read_csv(Config.DATASET_PATH / 'test.csv')
def featurize(df):
df.query('Tm != "TOT"', inplace = True)
X = df.drop(columns = params['remove'])
y = df.Pos
return X,y
X_train, y_train = featurize(train_df)
X_test, y_test = featurize(test_df)
X_train.to_csv(Config.FEATURES_PATH / 'train_features.csv', index = None)
X_test.to_csv(Config.FEATURES_PATH / 'test_features.csv', indeexp_show= None)
y_train.to_csv(Config.FEATURES_PATH / 'train_labels.csv', index = None)
y_test.to_csv(Config.FEATURES_PATH / 'test_labels.csv', index = None)
Entrenamos el Modelo.
import joblib
import pandas as pd
from sklearn.linear_model import LogisticRegression
from config import Config
import yaml
with open('params.yaml') as file:
params = yaml.safe_load(file)['train']
Config.MODELS_PATH.mkdir(parents=True, exist_ok=True)
X_train = pd.read_csv(Config.FEATURES_PATH / 'train_features.csv')
y_train = pd.read_csv(Config.FEATURES_PATH / 'train_labels.csv')
model = LogisticRegression(C = params['C'], max_iter=params['max_iter'], random_state=Config.RANDOM_SEED)
model.fit(X_train, y_train.to_numpy().ravel())
joblib.dump(model, Config.MODELS_PATH / params['model_name'])
Finalmente evaluamos la performance del modelo.
import json
import joblib
import pandas as pd
from sklearn.metrics import accuracy_score, recall_score
from config import Config
X_test = pd.read_csv(Config.FEATURES_PATH / 'test_features.csv')
y_test = pd.read_csv(Config.FEATURES_PATH / 'test_labels.csv')
model = joblib.load(Config.MODELS_PATH / 'model.joblib')
y_pred = model.predict(X_test)
output = dict( test_accuracy = accuracy_score(y_test, y_pred),
test_recall = recall_score(y_test, y_pred, average='macro'))
with open(Config.METRICS_PATH, 'w') as outfile:
json.dump(output, outfile)
Como se puede ver los cambios hechos al código son mínimos, y sólo se ingresaron los parámetros. De hecho, partes como evaluate_model.py casi no tienen código adicional. En estricto rigor, no agregamos nada que tenga que ver con el trackeo del proceso de experimentación.
DVC entra en juego!!
Entonces, ya que tenemos un primer bosquejo de nuestro código crearemos un repo de git e inicializaremos DVC (esto se puede hacer en cualquier momento, lo hago acá sólo por seguir el flujo del tutorial):
$ git init
$ dvc init
Initialized empty Git repository in /home/alfonso/Documents/dvc_tutorial/src/.git/
Initialized DVC repository.
You can now commit the changes to git.
Asegúrate de trabajar en Repos. dvc init sólo funciona en una carpeta que ya es un repo de GIT o lanzará un error.
Luego DVC permite la posibilidad de respaldar y llevar registro de la data tanto en local como en storage remotos. Lo más común, especialmente para poder compartir la data es utilizar storage remotos. A modo de explicar esto, utilizaremos Google Drive, pero DVC puede usarse en S3, Azure Blob, entre otros.
$ dvc remote add -d storage gdrive://1uvjM-tDGP577uB_DVxO8uoyHxeyZA3zO
Setting 'storage' as a default remote.
donde 1uvjM-tDGP577uB_DVxO8uoyHxeyZA3zO corresponde al id de una de sus carpetas de Google Drive, en este caso mi carpeta se llama remote y es donde almacené el archivo original que estamos usando. Como pueden ver el id se encuentra al final del link en la parte superior.
Cuando sincronizan Google Drive con su computador por primera vez les aparecerá un mensaje con instrucciones para garantizar que son ustedes. Síganlas al pie de la letra y no tendran problemas. Adicionalmente, no intenten usar este id si es que intentan reproducir el tutorial, ya que no tienen acceso a mis credenciales de Google, usen su propia cuenta 😇.
Como dijimos en el tutorial pasado Github no fue diseñado para llevar registro de archivos de gran tamaño por lo que si DVC se va a encargar de eso más vale asegurarse que GIT ignore estos archivos mediante nuestro .gitignore:
.vscode
__pycache__
assets/data
assets/features
assets/models
assets/original_data
De esta manera ignoramos la basura que podamos tener en nuestro Repo como los archivos de configuración de VSCode, cache, y las carpetas que almacenarán datos.
Luego entonces podemos armar el Pipeline. No es casualidad que los scripts tengan un orden asociado, y eso lo podemos replicar en DVC mediante el comando run. El comando puede ser un poco complicado de escribir en la línea de comando, por lo que decidí escribirlo en un archivo sh:
rm -f dvc.yaml
dvc run --no-exec -n get_data \
-d src/01-get_data.py \
-p base,data \
-o assets/data \
python src/01-get_data.py
dvc run --no-exec -n featurize \
-d src/02-create_features.py \
-d assets/data \
-p features \
-o assets/features \
python src/02-create_features.py
dvc run --no-exec -n train \
-d assets/features \
-d src/03-train_model.py \
-p base,train \
-o assets/models \
python src/03-train_model.py
dvc run --no-exec -n evaluate \
-d assets/features \
-d assets/models \
-d src/04-evaluate_model.py \
-M assets/metrics.json \
python src/04-evaluate_model.py
dvc run es el comando que permite crear una dependencia y a la vez ejecutar el Pipeline. Normalmente prefiero acompañarlo del flag --no-exec para realizar la ejecución después. El Script hace lo siguiente:
- La primera línea elimina el archivo
dvc.yamlen caso de existir. Este archivo es donde se generará esta configuración. -nes el nombre de las etapas: get_data, featurize, train y evaluate.-dson las dependencias. Esto me costó entenderlo, pero básicamente dice si es que DVC identifica que alguna de las dependencias cambió volverá a ejecutar esta etapa (esto quedará más claro con el ejemplo).-ocorresponde a los outputs. Todos los outputs serán trackeados por DVC y tendrán un respaldo en el storage definido.-pson los parámetros, en caso de que cambien DVC volverá a ejecutar el Pipeline, igual que con las dependencias.-Mcorresponde a métricas que se alamacenan en json y se usarán para comparar experimentos.- Finalmente, se coloca el comando que ejecutará dicha etapa.
Por ejemplo, tomemos una etapa cualquiera, la tercera:
- Su nombre es
train. - Si es que algo en la carpeta
assets/featureso si el scriptsrc/03-train_model.pycambia esta etapa se volverá a ejecutar. - Si es que alguno de los parámetros
baseotrainvaría también se volverá a ejecutar. - Los outputs del modelo se almacenarán en la carpeta
assets/models. - Esta etapa se lanza pidiéndole a DVC que ejecute el comando
python src/03-train_model.py.
Entonces para definir el Pipeline basta con ejecutar el archivo:
$ bash config_dvc.sh
Under the hood, esta configuración no hace más que organizar el archivo dvc.yaml, el cual tiene toda la información descrita pero en formato legible:
stages:
get_data:
cmd: python src/01-get_data.py
deps:
- src/01-get_data.py
params:
- base
- data
outs:
- assets/data
featurize:
cmd: python src/02-create_features.py
deps:
- assets/data
- src/02-create_features.py
params:
- features
outs:
- assets/features
train:
cmd: python src/03-train_model.py
deps:
- assets/features
- src/03-train_model.py
params:
- base
- train
outs:
- assets/models
evaluate:
cmd: python src/04-evaluate_model.py
deps:
- assets/features
- assets/models
- src/04-evaluate_model.py
metrics:
- assets/metrics.json:
cache: false
Si por alguna razón no se sienten cómodos utilizando archivos sh o la consola, primero que todo hay que empezar a acostumbrarse. Pero si de todas maneras prefieren crear de manera directa el dvc.yaml pueden hacerlo agregando o quitando partes que les interesen.
Al hacer esto entonces DVC ha sido configurado y en este punto sería una buena práctica hacer un commit:
$ git add .
$ git commit -m 'Configurando DVC'
DVC incluso permite ver el Pipeline como un DAG, el cual podemos visualizar haciendo lo siguiente:
$ dvc dag
+----------+
| get_data |
+----------+
*
*
*
+-----------+
| featurize |
+-----------+
** **
** *
* **
+-------+ *
| train | **
+-------+ *
** **
** **
* *
+----------+
| evaluate |
+----------+
DVC reconoce las distintas etapas y sus dependencias y lo muestra de manera gráfica. Entendiendo que el DAG está correctamente construido podemos ejecutar el proceso:
$ dvc repro
dvc repro implica reproducir el proceso. Recordemos que el objetivo principal de DVC es la reproducibilidad.
Running stage 'get_data':
> python src/01-get_data.py
Downloading...
From: https://drive.google.com/uc?id=1rwnNapcxlPM_DrYwBPSEC9uWVyEy70D1
To: /home/alfonso/Documents/dvc_tutorial/assets/original_data/nba_stats.csv
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 99.2k/99.2k [00:00<00:00, 6.02MB/s]
Generating lock file 'dvc.lock'
Updating lock file 'dvc.lock'
Running stage 'featurize':
> python src/02-create_features.py
Updating lock file 'dvc.lock'
Running stage 'train':
> python src/03-train_model.py
Updating lock file 'dvc.lock'
Running stage 'evaluate':
> python src/04-evaluate_model.py
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
Cada una de las etapas se ejecutó como corresponde, y DVC recomienda varias cosas para guardar cambios, las cuales las iremos revisando una a una. Algunos aspectos importantes de DVC:
Primero, si quiero revisar cómo le fue a mi ejecución:
$ dvc metrics show
Path test_accuracy test_recall
assets/metrics.json 0.43931 0.45895
Inmediatamente nos muestra las métricas que nosotros determinamos como relevantes para el problema.
¿Qué pasa si no estoy seguro si ejecuté todo o no? Ejecutemos el proceso de nuevo:
$ dvc repro
Stage 'get_data' didn't change, skipping
Stage 'featurize' didn't change, skipping
Stage 'train' didn't change, skipping
Stage 'evaluate' didn't change, skipping
Data and pipelines are up to date.
DVC entiende que ninguna de las dependencias ha cambiado. Por lo tanto, no ejecuta el proceso de nuevo, entendiendo que obtendríamos el mismo resultado. Esto es particularmente útil, ya que DVC nos permitirá ejecutar la menor cantidad de procesos para llevar a cabo nuestro proceso evitando tiempo de esperas innecesarios o costos computacionales en la nube.
Guardemos nuestro progreso entonces haciendo un commit.
$ git add .
$ git commit -m 'LR Baseline'
¿Qué sucedería si ahora quiero experimentar? Bueno para eso DVC posee comandos dedicados a dicha tarea. Probemos como le iría al modelo si es que C es 10 y 0.1
$ dvc exp run --set-param train.C=10
$ dvc exp run --set-param train.C=0.1
Stage 'get_data' didn't change skipping
Stage 'featurize' didn't change, skipping
Running stage 'train':
> python src/03-train_model.py
Updating lock file 'dvc.lock'
Running stage 'evaluate':
> python src/04-evaluate_model.py
Updating lock file 'dvc.lock'
DVC entiende que modificar ese parámetro sólo tiene impacto en las etapas train y evaluate, por lo tanto no vuelve a ejecutar las primeras etapas (esto lo deduce de las dependencias dadas, por lo que hay que poner mucho énfasis en configurar el Pipeline correctamente).
Luego podemos ver los resultados de la experimentación:
$ dvc exp show
DVC mostrará una tabla bien bonita con todos los experimentos, parámetros, hora de ejecución y métricas de resultado. workspace implica el último experimento ejecutado, en nuestro caso con C=0.1. master corresponde al último commit realizado que en este caso es nuestro Baseline.

Ahora, supongamos que nos interesa optimizar nuestro modelo para tener mejor Accuraccy, entonces el exp-f60e7 es el que nos interesa. Para poder promoverlo como el experimento que queremos dejar usamos:
$ dvc exp apply exp-f60e7
Changes for experiment 'exp-f60e7' have been applied to your current workspace.
De hecho podemos comparar nuestra mejora:
$ dvc metrics diff
Path Metric HEAD workspace Change
assets/metrics.json test_accuracy 0.43931 0.44509 0.00578
assets/metrics.json test_recall 0.45895 0.46103 0.00208
Este comando nos indica que nuestro experimento actual (workspace) es mejor en 0.00578 en accuracy y 0.00208 en recall.
dvc exp apply se va a encargar de modificar nuestros archivos de tal modo que dvc repro nos entregue el mismo resultado obtenido en la experimentación, es decir, DVC es capaz de modificar código, parámetros o data con tal de hacer el experimento reproducible.
Luego de esto podemos realizar el commit necesario para guardar los cambios:
$ git add .
$ git commit -m 'Mejorando la Regresion Logistica'
Finalmente podemos ver nuestras métricas actuales:
$ dvc metrics show
Path test_accuracy test_recall
assets/metrics.json 0.44509 0.46103
Un último aspecto importante es que todos los archivos en el output están siendo trackeados por DVC, pero debe llevarse el respaldo en el storage remoto utilizando dvc push. dvc push se encargará de tener un registro de los archivos. Esto porque DVC supone que los procesos de ML trabajan con archivos muy grandes y procesos de entrenamiento largos. Por lo tanto, si alguien quisiera clonar mi repo y ver mis resultados y la data asociada podría utilizar dvc pull para obtener los archivos de salida sin la necesidad de ejecutar todo el Pipeline de nuevo, que como dijimos puede tomar mucho tiempo debido a la naturaleza de los problemas que se están resolviendo.
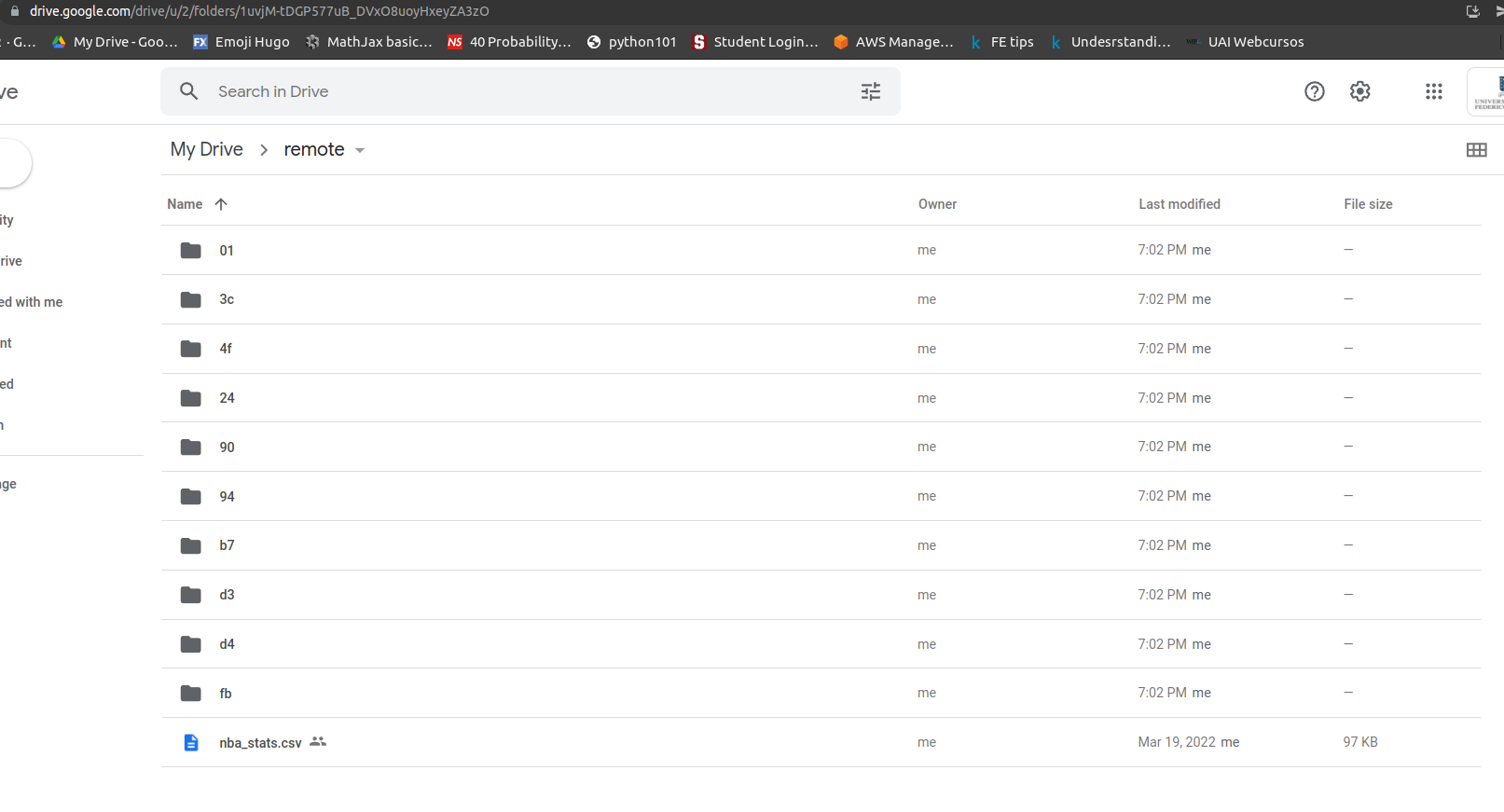
Si vamos a Google Drive podemos ver que todos los archivos tienen un respaldo con datos ininteligibles para nosotros, pero que DVC puede rápidamente interpretar para regenerar esos archivos. Es importante destacar que todos los archivos están en algún formato binario, que al menos yo no entiendo como poder leer sin pasar por DVC. Imagino que la razón de esto es para evitar que personas no autorizadas puedan mirar la data.
Finalmente podemos dejar respaldo en nuestro Github generando un push.
Este fue el tutorial de DVC, espero lo consideren útil y que desde ya puedan comenzar a incorporarlo dentro de su estructura de trabajo. Si les interesa seguir este tutorial o reproducirlo pueden encontrar todo el código en este repo.
Obviamente DVC no es el punto final. ¿No sería espectacular poder tener feedback de los procesos de entrenamiento de manera inmediata y que pudieramos tener el proceso de experimentación súper automatizado usando CI/CD?
Bueno, se viene en el tutorial que sigue…
Nos vemos a la otra,