Competencia de Kaggle
Redes Neuronales para detectar emociones faciales

Tengo ganas de comenzar a revisar como me iría en competencias en Kaggle…
Pero me da miedo.
Así que me gustaría partir probando con competencias pasadas. A medida que comienzo a entender mejor como funciona Pytorch quiero ir adentrándome en datasets de mayor complejidad, pero documentando todo lo que voy aprendiendo. Pytorch la verdad es complejo al principio, y muchos se sientan más tentados en irse a Keras. Pero viniendo de utilizar Keras en mi memoria, me he dado cuenta que utilizar Pytorch me ha llevado a cuestionar por qué hago lo que hago. Al ser un framework de bajo nivel me obliga a entender cada pedacito de código que agrego. El código es más largo y se ve intimidante, pero siento que en estos cortos 4 meses (con muchos altibajos en el proceso) he logrado aprender mucho más que mis 4 años usando Keras.
Emociones en Imágenes
En el siguiente tutorial quiero revisar un Pipeline completo de Entrenamiento de un Modelo que tome imágenes de caras y pueda predecir su emoción. Esta fue una de las primeras competencias en Kaggle, dejo acá el link.
Esta competencia utilizaba como métrica el Accuracy.
Comencemos importando las librerías que vamos a estar utilizando:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import albumentations as A
from datetime import datetime
np.random.seed(123)
torch.manual_seed(0);
df = pd.read_csv('fer2013.csv')
df['Usage'] = df['Usage'].astype('category')
df.head()
| emotion | pixels | Usage | |
|---|---|---|---|
| 0 | 0 | 70 80 82 72 58 58 60 63 54 58 60 48 89 115 121... | Training |
| 1 | 0 | 151 150 147 155 148 133 111 140 170 174 182 15... | Training |
| 2 | 2 | 231 212 156 164 174 138 161 173 182 200 106 38... | Training |
| 3 | 4 | 24 32 36 30 32 23 19 20 30 41 21 22 32 34 21 1... | Training |
| 4 | 6 | 4 0 0 0 0 0 0 0 0 0 0 0 3 15 23 28 48 50 58 84... | Training |
df.dtypes
emotion int64
pixels object
Usage category
dtype: object
Como se puede apreciar el dataset consiste de 3 columnas:
- emotion: Contiene la etiqueta que define la emoción de la imágen. (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)
- pixels: Corresponden a los valores de cada uno de los pixeles. De acuerdo con las instrucciones de la competencia, las imágenes son de 48x48.
- Usage: Corresponde al set de datos correspondientes: Train, PublicTest, Private Test.
Si les interesa el dataset, pueden obtenerlo acá.
df.Usage.value_counts().plot(kind = 'bar')
plt.title('Distribución de los Datos', fontsize = 20);
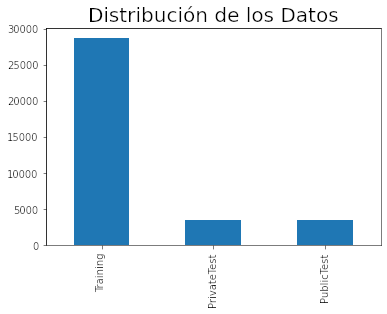
Como se puede ver, existen cerca de 28K imágenes que son utilizadas para entrenamiento. Todas estas imágenes contemplaban en la competencia una etiqueta por lo que podían ser utilizadas para entrenar.
Adicionalmente se pueden ver dos grupos, Public y Private Test que correspondían a los Sets de Validación. El set público era el que se usaba para evaluar los resultados al subirlos a la plataforma, mientras que el Private correspondía a los datos ocultos que se liberan sólo al finalizar la competencia para decidir a los ganadores.
Es importante destacar que el set no contiene Nulos, y que las etiquetas de Test ya se encuentran disponibles por lo que podremos determinar la efectividad de nuestro modelo inmediatamente.
df.isnull().sum()
emotion 0
pixels 0
Usage 0
dtype: int64
Data Split y Pytorch Data Class
Vamos entonces a dividir nuestro dataset en Train y Test, pero para Test utilizaremos ambos sets para determinar inmediatamente la performance de nuestro modelo.
train_data = df.query('Usage == "Training"')[['emotion','pixels']]
test_data = df.query('Usage in ["PublicTest","PrivateTest"]')[['emotion','pixels']]
print(train_data.shape)
print(test_data.shape)
(28709, 2)
(7178, 2)
Distribución de Labels
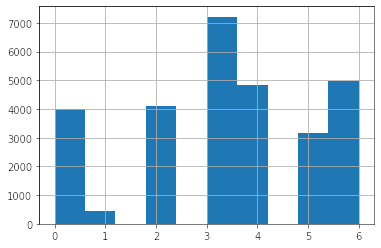
train_data.emotion.hist();
test_data.emotion.hist();
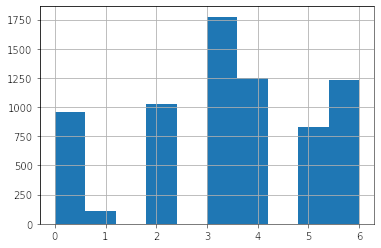
Podemos ver que las distribuciones son idénticas, muy probablemente este Test set fue generado siguiendo la misma distribución de etiquetas del Set de entrenamiento. Esto indica que la performance en nuestro set de entrenamiento debiera ser bastante similar a la del set de Test.
Esta fue una de mis hipótesis al iniciar a trabajar en este dataset. Pero, no podía estar más equivocado. Si bien la distribución es igual, los rostros del test set parece que eran bastante más difíciles de diferenciar de lo que esperaba.
Para poder cargar los datos en Pytorch estos deben ser parte de un Dataset Class. Esta clase debe contener 3 propiedades:
- Un Constructor __init__(), con los parámetros para instanciar la clase,
- Un __len__ que permita contar el número de elementos de la clase.
- Un __getitem__ que permita extraer los datos de la clase. Adicionalmente, en que caso de que alguna transformación (Data Augmentation, Pre-Processing) deba aplicarse, esta es la etapa donde implementar esto.
Las salidas de esta clase deben ser tensores de Pytorch!!
class EmoData(Dataset):
def __init__(self, data, transform = None):
self.data = data.reset_index(drop = True)
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
image = np.array(self.data.pixels[idx].split(),
dtype = np.float32, copy = True).reshape(1,48,48)
if self.transform is not None:
image = self.transform(image = image)['image'].copy()
label = np.array(self.data.emotion[idx])
return {'image': torch.from_numpy(image),
'label': torch.from_numpy(label)}
- La clase se construirá con un dataset (un pandas dataframe) y un Pipeline de transformaciones.
- El __len__ se realizará con un len().
- El __getitem__ tomará el string de pixeles de una fila, con split lo transformará en una lista para luego transformarlo en array de numpy de tamaño (1, 48,48) donde 1 es el canal (Blanco y Negro), y 48,48 es el tamaño. La razón por la que se transforma en un Numpy Array es porque haremos un poquito de Data Augmentation con Albumentations y esta librería espera esta estructura de dato.
Cabe destacar que se debe diferenciar una lógica cuando hay y cuando no hay transformaciones, para mayor robustez de la clase. Finalmente la salida serán tensores construidos desde numpy mediante torch.from_numpy().
Como Data Augmentations sólo aplicaremos un VerticalFlip, que permitirá invertir la foto y un Rotate, que permitirá de manera aleatoria rotar la imagen hasta en 22 grados con una probabilidad de 50% (de que se genere o no la rotación).
Notar que en la transformación agregamos un .copy(). Esto normalmente no debiera ser necesario, pero el verticalFlip introduce strides negativos que no pueden ser transformados en Pytorch Tensors. La sugerencia en el foro de Pytorch es utilizar el .copy() para solucionarlo.
transforms = A.Compose([
A.VerticalFlip(p=0.25),
A.Rotate(limit=22, p=0.5),
])
data_train = EmoData(train_data, transform = transforms)
data_test = EmoData(test_data)
Chequeando Nuestros elementos
data_train[0]
{'image': tensor([[[ 68.7500, 75.2500, 76.0000, ..., 53.0000, 45.2500, 41.7500],
[ 61.2500, 56.5000, 57.0000, ..., 54.2500, 53.0000, 44.7500],
[ 47.3750, 43.2188, 55.9688, ..., 47.2500, 54.0312, 46.5625],
...,
[ 84.2500, 54.1250, 42.7500, ..., 70.5000, 57.8750, 50.5000],
[ 82.6875, 75.0938, 63.9688, ..., 91.5938, 64.3125, 44.7812],
[ 77.0000, 76.0625, 81.9688, ..., 105.5938, 93.1562, 67.3750]]]),
'label': tensor(0)}
print('Tipo de Dato Imagen: ',type(data_train[0]['image']))
print('Tipo de Dato Etiqueta: ', type(data_train[0]['label']))
Tipo de Dato Imagen: <class 'torch.Tensor'>
Tipo de Dato Etiqueta: <class 'torch.Tensor'>
emotions = ['Angry','Disgust', 'Fear', 'Happy', 'Sad','Surprise','Neutral']
random_values = np.random.randint(1,len(data_train)+1, size = 10)
fig, ax = plt.subplots(1,10, figsize = (25,15))
for idx, value in enumerate(random_values):
label = data_train[value]['label']
img = data_train[value]['image'].numpy().transpose(1,2,0)
ax[idx].imshow(img, cmap = 'gray')
ax[idx].set_title(f'Emotion: {label}={emotions[label]}');

DataLoaders
Los DataLoaders son utilities provistos por Pytorch que nos permitirán cargar los datos de una manera más simple. Algunos aspectos a los que hay que poner atención:
- Se pueden incluir sólo elementos que sean clase Dataset, por eso el paso previo de transformar nuestros datos.
- Se debe definir el batch size dependiendo nuestra memoria RAM disponible en el caso de utilizar CPU, o del VRAM en caso de GPU. Si nuestra data no cabe en nuestra memoria el proceso explotará.
pin_memorydebe ser igual a True para pre alocar espacio en la GPU. Esto hará que el traspaso de CPU a GPU sea más eficiente.num_workerses la cantidad de núcleos que estarán encargados del proceso de cargar datos. Hay que recordar que el data augmentation se hace en CPU en Numpy, por lo tanto siempre habrá carga compartida entre CPU y GPU. He leído que librerías como Kornia permiten realizar el Data Augmentation directo en GPU, pero aún no la he probado, y por otro lado, Albumentations es por lejos la librería más popular en esta área.- Sólo el dataset de entrenamiento debe ser shuffleado. Esto es importante ya que queremos que el modelo aprenda de manera aleatoria, no ordenado por clases. Cuando se trata de predecir cambiar de orden no afecta demasiado, por lo que no es necesario.
batch_size = 128
train_loader = torch.utils.data.DataLoader(dataset = data_train,
batch_size = batch_size,
pin_memory = True,
num_workers = 10,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = data_test,
batch_size = batch_size,
pin_memory = True,
num_workers = 10,
shuffle = False)
Definición del Modelo
Acá definiremos una arquitectura de Redes Convolucionales. Como se puede ver, cada capa Convolucional estará definida por:
- Conv2d: Encargada de sacar el mapa de características aplicando distintos filtros que permitan extraer patrones de la imagen.
- Relu: Será la función de activación no-lineal.
- BatchNorm2d: Corresponde a una estandarización de los resultados al salir de las capas. Esto asegura que el rango de datos siempre esté acotado evitando problemas de Vanishing o Exploiting Gradients en Redes muy profundas.
- MaxPool2d: Será la encargada de reducir la dimensión de la imagen. De esa manera las capas más profundas podrán detectar patrones más específicos.
Sólo destacar que se está utilizando padding. Por lo tanto, la Capa Conv2d no reduce dimensión, sólo la MaxPool se encargará de esta tarea.
class CNN(nn.Module):
def __init__(self, classes, channels):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(channels, 32, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32, 32, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.MaxPool2d(2))
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2))
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 128, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2))
# Cálculo del tamaño de salida de una Capa Convolucional
# H_out = H_in + 2p - 2 --> p = 1 then H_out = H_in
# Tamaños por capa.
# 48 > 24 > 12 > 6
self.fc1 = nn.Linear(128*6*6,1024) #n_channels * size
self.fc2 = nn.Linear(1024, classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
x = F.dropout(x, p = 0.5)
x = F.relu(self.fc1(x))
x = F.dropout(x, p = 0.2)
x = self.fc2(x)
return x
Algunos puntos importantes:
- Pytorch exige que nosotros calculemos el número de Neuronas de entrada a las Redes Densas, es decir cuando hacemos el proceso de Flatten del output de la sección convolucional. La manera más fácil de entenderlo es que será el número de canales de la capa convolucional (128, que es el número de filtros o feature maps generados), multiplicado por el tamaño de la imagen (6x6).
- Entre las capas Densas se agrega un dropout del 50% que generará desconexiones aleatorias de las neuronas. Esto servirá para regularizar permitiendo evitar overfitting.
x.size(0)correponde al batch size que está siendo procesado. Por lo tanto hacer, un.view(x.size(0),-1)será equivalente a un Flatten manteniendo el batch size.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_cnn = CNN(classes = 7, channels = 1).to(device)
tensor_test = torch.randint(10, (1,1,48,48), dtype = torch.float32).to(device)
print(tensor_test.shape)
print(model_cnn(tensor_test).shape)
torch.Size([1, 1, 48, 48])
torch.Size([1, 7])
Si, por ejemplo, cargamos en el modelo un Tensor aleatorio de tamaño (1, 48,48) tal como espera la red, entonces obtendremos como salida un Tensor de (1,7) que equivale a las 7 clases involucradas en el proceso de entrenamiento.
La teoría dice que un modelo multiclase como el que tenemos debiera contener una SoftMax en la capa de salida. Lo cual es cierto. La documentación de Pytorch indica que la CrossEntropyLoss() incluye esta Softmax de manera interna y recomienda no agregarla. Esto puede ser confuso, pero la razón es que se quiere evitar problemas de una librería de bajo nivel, y es sabido que la Softmax tiene problemas de Overflow. Adicionalmente, la función Softmax tiene como único objetivo normalizar en el rango 0-1 las predicciones. Si se aplica un argmax a las predicciones con o sin Softmax los resultados serán los mismos.
Definición del Modelo
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model_cnn.parameters(), lr = 3e-4)
def train(epochs,
model,
train_loader = train_loader,
test_loader = test_loader,
criterion = criterion,
optimizer = optimizer):
train_losses = np.zeros(epochs)
test_losses = np.zeros(epochs)
for epoch in range(epochs):
model.train()
t0 = datetime.now()
train_loss = []
for batch in train_loader:
inputs, targets = batch['image'].to(device), batch['label'].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss.append(loss.item()) # for every batch
model.eval()
test_loss = []
for inputs, targets in test_loader:
inputs, targets = batch['image'].to(device), batch['label'].to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss.append(loss.item())
train_losses[epoch] = np.mean(train_loss)
test_losses[epoch] = np.mean(test_loss)
dt = datetime.now()-t0
print(f'Epoch {epoch + 1}/{epochs}, Train Loss : {train_losses[epoch]},
Test Loss: {test_losses[epoch]}, Duration: {dt}')
return train_losses, test_losses
train_losses, test_losses = train(100, model_cnn)
Epoch 1/100, Train Loss : 1.5685063775380452, Test Loss: 1.2704594323509617, Duration: 0:00:07.435770
Epoch 2/100, Train Loss : 1.2603482553693983, Test Loss: 1.1079302712490684, Duration: 0:00:07.444088
Epoch 3/100, Train Loss : 1.1342944939931234, Test Loss: 0.8338020611227605, Duration: 0:00:07.511595
Epoch 4/100, Train Loss : 1.0385073195563421, Test Loss: 0.8718564876338892, Duration: 0:00:07.482533
Epoch 5/100, Train Loss : 0.9491766696506077, Test Loss: 0.6855181549724779, Duration: 0:00:07.500322
Epoch 6/100, Train Loss : 0.8742057805591159, Test Loss: 0.875690011601699, Duration: 0:00:07.518833
Epoch 7/100, Train Loss : 0.7934442316161262, Test Loss: 0.7833965002444753, Duration: 0:00:07.434418
Epoch 8/100, Train Loss : 0.7144768076472813, Test Loss: 0.5617503481998778, Duration: 0:00:07.608059
Epoch 9/100, Train Loss : 0.63879125184483, Test Loss: 0.5762770824265062, Duration: 0:00:07.565074
Epoch 10/100, Train Loss : 0.5560832618342506, Test Loss: 0.5338366057789117, Duration: 0:00:07.601915
Epoch 11/100, Train Loss : 0.4954797455999586, Test Loss: 0.41823672150310715, Duration: 0:00:07.662693
Epoch 12/100, Train Loss : 0.4252561722861396, Test Loss: 0.35571027638619407, Duration: 0:00:07.611515
Epoch 13/100, Train Loss : 0.3790274261103736, Test Loss: 0.36090188460391864, Duration: 0:00:07.558588
Epoch 14/100, Train Loss : 0.32057919594976636, Test Loss: 0.31242866787994117, Duration: 0:00:07.543124
Epoch 15/100, Train Loss : 0.29527034911844463, Test Loss: 0.1746447071955915, Duration: 0:00:07.739053
Epoch 16/100, Train Loss : 0.25527051574654047, Test Loss: 0.19683076375932024, Duration: 0:00:07.464717
Epoch 17/100, Train Loss : 0.23869253536065418, Test Loss: 0.26103107892630395, Duration: 0:00:07.603391
Epoch 18/100, Train Loss : 0.21994226978884804, Test Loss: 0.20475874422935017, Duration: 0:00:07.746555
Epoch 19/100, Train Loss : 0.19642237140072716, Test Loss: 0.22932217832197221, Duration: 0:00:07.461090
Epoch 20/100, Train Loss : 0.18053082389963998, Test Loss: 0.07700058379978464, Duration: 0:00:07.512513
Epoch 21/100, Train Loss : 0.16869717508554458, Test Loss: 0.10648694957949613, Duration: 0:00:07.536264
Epoch 22/100, Train Loss : 0.1588599810666508, Test Loss: 0.1687137731596043, Duration: 0:00:07.620176
Epoch 23/100, Train Loss : 0.15015164507759943, Test Loss: 0.13657969295194275, Duration: 0:00:07.406986
Epoch 24/100, Train Loss : 0.16068544435832235, Test Loss: 0.06126316424393863, Duration: 0:00:07.601295
Epoch 25/100, Train Loss : 0.1384612077805731, Test Loss: 0.15503903942411407, Duration: 0:00:07.611390
Epoch 26/100, Train Loss : 0.14015942407978907, Test Loss: 0.12494414012160218, Duration: 0:00:07.519424
Epoch 27/100, Train Loss : 0.138336751576927, Test Loss: 0.14870665340047134, Duration: 0:00:07.558428
Epoch 28/100, Train Loss : 0.12155896463327938, Test Loss: 0.08628309143935903, Duration: 0:00:07.534769
Epoch 29/100, Train Loss : 0.12658149222532908, Test Loss: 0.10814279951808746, Duration: 0:00:07.645120
Epoch 30/100, Train Loss : 0.12068903764088948, Test Loss: 0.04974873393381897, Duration: 0:00:07.683308
Epoch 31/100, Train Loss : 0.11193837337195874, Test Loss: 0.0720434198319389, Duration: 0:00:07.539242
Epoch 32/100, Train Loss : 0.11211185306310653, Test Loss: 0.05287449228528299, Duration: 0:00:07.628909
Epoch 33/100, Train Loss : 0.11316721633076668, Test Loss: 0.11060049616846077, Duration: 0:00:07.609103
Epoch 34/100, Train Loss : 0.11567474385930432, Test Loss: 0.07041921711673862, Duration: 0:00:07.504278
Epoch 35/100, Train Loss : 0.11263563185930252, Test Loss: 0.06868898574458926, Duration: 0:00:07.755913
Epoch 36/100, Train Loss : 0.10689856818152799, Test Loss: 0.08863829491300541, Duration: 0:00:07.655458
Epoch 37/100, Train Loss : 0.09962744145757622, Test Loss: 0.14210738215530128, Duration: 0:00:07.570472
Epoch 38/100, Train Loss : 0.09796380882461865, Test Loss: 0.06018314052683612, Duration: 0:00:07.436209
Epoch 39/100, Train Loss : 0.10083840927316083, Test Loss: 0.10016214256093167, Duration: 0:00:07.509696
Epoch 40/100, Train Loss : 0.09468494282000595, Test Loss: 0.12459736853315119, Duration: 0:00:07.498488
Epoch 41/100, Train Loss : 0.0960030545749598, Test Loss: 0.08161365505503981, Duration: 0:00:07.535174
Epoch 42/100, Train Loss : 0.09389926384720537, Test Loss: 0.04796358167700339, Duration: 0:00:07.519741
Epoch 43/100, Train Loss : 0.09390132083661026, Test Loss: 0.05673542001137608, Duration: 0:00:07.573305
Epoch 44/100, Train Loss : 0.09025461648901303, Test Loss: 0.08360655176077496, Duration: 0:00:07.502636
Epoch 45/100, Train Loss : 0.08403305900593598, Test Loss: 0.04750340501369353, Duration: 0:00:07.453470
Epoch 46/100, Train Loss : 0.08960639404753844, Test Loss: 0.06931268976053648, Duration: 0:00:07.818265
Epoch 47/100, Train Loss : 0.08657769918441773, Test Loss: 0.09023804813133258, Duration: 0:00:07.719383
Epoch 48/100, Train Loss : 0.08682348894576232, Test Loss: 0.07446102340493285, Duration: 0:00:07.490357
Epoch 49/100, Train Loss : 0.08758400851653682, Test Loss: 0.08435347646866974, Duration: 0:00:07.531428
Epoch 50/100, Train Loss : 0.08807607942985164, Test Loss: 0.06930053225930846, Duration: 0:00:07.510667
Epoch 51/100, Train Loss : 0.08268367288427221, Test Loss: 0.054926761042065265, Duration: 0:00:07.372590
Epoch 52/100, Train Loss : 0.08228563147493535, Test Loss: 0.04609628090136603, Duration: 0:00:07.712100
Epoch 53/100, Train Loss : 0.07916777018871572, Test Loss: 0.07782311669730566, Duration: 0:00:07.504979
Epoch 54/100, Train Loss : 0.07559850578092867, Test Loss: 0.04013728676363826, Duration: 0:00:07.526296
Epoch 55/100, Train Loss : 0.07224051023936934, Test Loss: 0.043111531255897464, Duration: 0:00:07.406122
Epoch 56/100, Train Loss : 0.07718744946022828, Test Loss: 0.07142776953415912, Duration: 0:00:07.471825
Epoch 57/100, Train Loss : 0.08093264233320951, Test Loss: 0.05530937481671572, Duration: 0:00:07.417373
Epoch 58/100, Train Loss : 0.08302475418067641, Test Loss: 0.047892502762311905, Duration: 0:00:07.422260
Epoch 59/100, Train Loss : 0.07385869049363666, Test Loss: 0.11617032164021542, Duration: 0:00:07.558305
Epoch 60/100, Train Loss : 0.07124772776746087, Test Loss: 0.07351999339369829, Duration: 0:00:07.432816
Epoch 61/100, Train Loss : 0.07599356621089909, Test Loss: 0.050696157049714474, Duration: 0:00:07.434407
Epoch 62/100, Train Loss : 0.07651680830452177, Test Loss: 0.07371464999507002, Duration: 0:00:07.461533
Epoch 63/100, Train Loss : 0.07503578106769257, Test Loss: 0.030044139301600426, Duration: 0:00:07.414092
Epoch 64/100, Train Loss : 0.07195286623305745, Test Loss: 0.04880817435485752, Duration: 0:00:07.445999
Epoch 65/100, Train Loss : 0.0733366312003798, Test Loss: 0.04233049127894143, Duration: 0:00:07.475919
Epoch 66/100, Train Loss : 0.07087275899532769, Test Loss: 0.0524572796461973, Duration: 0:00:07.505872
Epoch 67/100, Train Loss : 0.0705122730591231, Test Loss: 0.07785954053530045, Duration: 0:00:07.444966
Epoch 68/100, Train Loss : 0.06780668049843774, Test Loss: 0.04306072274451716, Duration: 0:00:07.472458
Epoch 69/100, Train Loss : 0.06722409489047196, Test Loss: 0.04302919502451755, Duration: 0:00:07.501664
Epoch 70/100, Train Loss : 0.06952006546573507, Test Loss: 0.055185653154917975, Duration: 0:00:07.444122
Epoch 71/100, Train Loss : 0.06658242160247432, Test Loss: 0.05924268428791772, Duration: 0:00:07.715510
Epoch 72/100, Train Loss : 0.06553211441884438, Test Loss: 0.047623500685419956, Duration: 0:00:07.439461
Epoch 73/100, Train Loss : 0.07002890962693427, Test Loss: 0.03363820311221245, Duration: 0:00:07.608843
Epoch 74/100, Train Loss : 0.06213416441861126, Test Loss: 0.2318161659988395, Duration: 0:00:07.487735
Epoch 75/100, Train Loss : 0.0678380501601431, Test Loss: 0.023300537951862474, Duration: 0:00:07.434144
Epoch 76/100, Train Loss : 0.06472900836004152, Test Loss: 0.07539253030789264, Duration: 0:00:07.461610
Epoch 77/100, Train Loss : 0.06582127439065112, Test Loss: 0.06558436525805869, Duration: 0:00:07.538110
Epoch 78/100, Train Loss : 0.06716376890324884, Test Loss: 0.08527673967591111, Duration: 0:00:07.469946
Epoch 79/100, Train Loss : 0.06343599558911389, Test Loss: 0.04167751879676392, Duration: 0:00:07.508501
Epoch 80/100, Train Loss : 0.06065213031032019, Test Loss: 0.025225419397956056, Duration: 0:00:07.519629
Epoch 81/100, Train Loss : 0.06753878094255925, Test Loss: 0.0385604364830151, Duration: 0:00:07.661022
Epoch 82/100, Train Loss : 0.06263598236358828, Test Loss: 0.07652628122779884, Duration: 0:00:07.544583
Epoch 83/100, Train Loss : 0.06668933305061525, Test Loss: 0.03713336906787988, Duration: 0:00:07.362720
Epoch 84/100, Train Loss : 0.06254817017250591, Test Loss: 0.1531628537596318, Duration: 0:00:07.425869
Epoch 85/100, Train Loss : 0.05651402237307694, Test Loss: 0.11048766898742893, Duration: 0:00:07.450142
Epoch 86/100, Train Loss : 0.05745798922040396, Test Loss: 0.07903642457370695, Duration: 0:00:07.383123
Epoch 87/100, Train Loss : 0.06389108918193313, Test Loss: 0.06279676938592865, Duration: 0:00:07.441349
Epoch 88/100, Train Loss : 0.05415194539767173, Test Loss: 0.09837819013352457, Duration: 0:00:07.455767
Epoch 89/100, Train Loss : 0.05532779972586367, Test Loss: 0.1469461309413115, Duration: 0:00:07.413132
Epoch 90/100, Train Loss : 0.05850784854963422, Test Loss: 0.06693745355056435, Duration: 0:00:07.402546
Epoch 91/100, Train Loss : 0.06171296250075102, Test Loss: 0.028416935940632562, Duration: 0:00:07.341858
Epoch 92/100, Train Loss : 0.05977611617081695, Test Loss: 0.04383614388082111, Duration: 0:00:07.523273
Epoch 93/100, Train Loss : 0.059690083463986715, Test Loss: 0.057999318890404286, Duration: 0:00:07.510361
Epoch 94/100, Train Loss : 0.061289607377515896, Test Loss: 0.047553515678533075, Duration: 0:00:07.474080
Epoch 95/100, Train Loss : 0.051062224592185686, Test Loss: 0.05119612991907879, Duration: 0:00:07.465604
Epoch 96/100, Train Loss : 0.061366277289473345, Test Loss: 0.05825742180745134, Duration: 0:00:07.436581
Epoch 97/100, Train Loss : 0.05140511688672834, Test Loss: 0.04292277233642444, Duration: 0:00:07.463699
Epoch 98/100, Train Loss : 0.05849524927429027, Test Loss: 0.04304234534420334, Duration: 0:00:07.505132
Epoch 99/100, Train Loss : 0.0554230806314283, Test Loss: 0.05258329451010611, Duration: 0:00:07.657325
Epoch 100/100, Train Loss : 0.057363400128152636, Test Loss: 0.07595566923223566, Duration: 0:00:07.540040
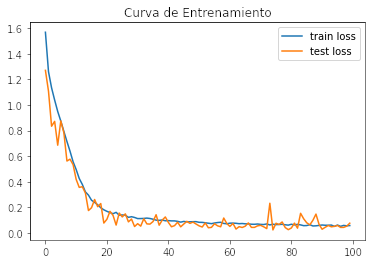
plt.plot(train_losses, label = 'train loss')
plt.plot(test_losses, label = 'test loss')
plt.title('Curva de Entrenamiento')
plt.legend()
plt.show()
n_correct = 0.
n_total = 0.
model_cnn.eval()
with torch.no_grad():
for batch in test_loader:
inputs, targets = batch['image'].to(device), batch['label'].to(device)
outputs = model_cnn(inputs)
_, predictions = torch.max(outputs, 1)
n_correct += (predictions == targets).sum().item()
n_total += targets.shape[0]
test_acc = n_correct / n_total
test_acc
0.6213429924770131
El resultado es bastante optimista. En un primer intento se obtuvo un 0.6213. Lo cual nos hubiera ubicado en el 11vo lugar, obteniendo una medalla de Plata. A pesar de eso pensé que sería un problema más sencillo al tener imágenes de baja resolución y con distribuciones similares en train y test.
Cómo mejorar el Modelo
Debido a que estamos utilizando sólo redes convolucionales ordinarias el espectro de mejora es bastante. A pesar de ser imágenes pequeñas resultó ser un problema que no generaliza tan bien. Algunas cosas para tomar en cuenta en el futuro y mejorar:
- Optimización de Hiperparámetros: Los valores que estamos usando son sólo valores estándar y no necesariamente los óptimos para el problema. Realizando algún proceso de tuning podríamos lograr mejores resultados. Me da la impresión que la parte de redes densas está muy compleja y hay demasiadas neuronas por lo que reduciendo el número de parámetros y/o aplicando una regularización más agresiva podría generar un aumento significativo en la performance.
- Arquitecturas más modernas: Obviamente en ese tiempo no existían arquitecturas como
EfficientNetsoViT, por lo que me da la impresión que podrían fácilmente mejorar la performance en este tipo de problemas. - Transfer learning: Combinar esta estrategia con arquitecturas del punto anterior debiera entregar mejores resultados.
- Callbacks: Siento que alterar el batch_size y el learning rate debiera ayudar. Mi intención era utilizar un batch_size pequeño ya que quería probar como andaba la RTX 2070. Siento que logra buenos tiempos de entrenamiento sin tener problemas de memoria. Acá pienso probar en el futuro utilizando Pytorch Lightning que entrega muchas más opciones de callbacks como
early stoppingy cambios en ellearning ratea medida que se entrena. - Balance de clases: Como se vió al inicio, este dataset tiene un problema de desbalance. Existen muchos más ejemplares de la clase 3 (Happy) y muy poquitos de la clase 1 (Angry) por lo que esto puede impactar negativamente en los resultados. Además al hacer una inspección manual de los datos se puede ver que emociones de miedo, triteza y neutral son bien parecidos y debe ser dificil para la red de identificar.
Espero que les haya gustado, cualquier duda que tengan no duden en contactarme.
Nos vemos