¿Cómo utilizar MlFlow local para organizar tus experimentos?
Tutorial MlFlow
Me encanta modelar, pero al mismo tiempo demanda lo mejor de mí en términos del orden, yo no soy muy ordenado en la vida real, entonces pedirme que sea ordenado al momento de experimentar con mis modelos es demasiado, por eso MLflow es una super buena alternativa para lograr una estructura al momento de modelar.

Cómo se usa MlFLow
Crear un modelo se trata de realizar muchos ensayos, básicamente prueba y error. Nunca es posible saber a priori que tipo de modelo, qué procesamiento, que selección de variables o qué hiperparámetros van a ser los que entreguen los mejores resultados. El tema es, ¿cómo organizar los modelos y como saber exactamente qué combinación usar?
Aquí es donde MlFlow entra en juego, ya que entrega una manera de tener todo organizado en una UI decente. Tengo que decir que nunca he utilizado MlFLow antes y al mismo tiempo nunca he encontrado un buen tutorial que me ayude a entender en detalle como funciona. Así que no me quedó otra que crearme un tutorial para mí mismo.
La idea es probar las distintas funcionalidades que tiene para eventualmente generar un workflow que me permita ser lo más eficiente posible al momento de modelar.
Entonces lo primero:
$ pip intall mlflow
Luego se puede inicializar la UI en http://localhost:5000 corriendo el siguiente comando:
$ mlflow ui
Para aprender cómo usar esta UI vamos a utilizar el dataset de Titanic. Para obtenerlo pueden descargarlo desde acá o si tienen instalada la API de kaggle pueden descargar esto como:
$ kaggle competitions download -c titanic
Tip: Recomiendo encarecidamente descargar la API de Kaggle para jugar con sus respectivos datasets. La verdad es fácil de instalar y de usar, acá las intrucciones de cómo instalarla.
Entonces empecemos con los datos:
import pandas as pd
import numpy as np
df = pd.read_csv('train.csv')
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Signing_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1911-05-17 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1911-07-23 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1911-09-08 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1911-06-26 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1911-10-25 |
Warnng: Inicialmente sólo se imputarán Nulos y encodearan variables categóricas como número ordinales. Obviamente este approach es sumamente isimplista y no es necesariamente la mejor opción para lograr buenos resultados, pero la idea es enfocarse en cómo funciona MlFlow.
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
Signing_date 0
dtype: int64
Se imputará Age con su media. Se dropearán Cabin y Signing_date, E imputará Embarked con la moda.
Ojo:Signing_date es una variable fake que inventé para otro proyecto y que no viene incluída en el dataset descargado desde Kaggle. Si no lo tienen, sólo omita esta parte.
import category_encoders as ce
mean_age = df.Age.mean()
mode_embarked = df.Embarked.mode()
mean_fare = df.Fare.mean()
def make_data_ready(data):
result = (data.fillna(value = {'Age': mean_age, 'Embarked': mode_embarked, 'Fare': mean_fare})
.drop(columns = ['Cabin','Signing_date'], errors = 'ignore')
.set_index('PassengerId')
)
ord = ce.OrdinalEncoder()
out = ord.fit_transform(result)
return out
df = make_data_ready(df)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||||
| 1 | 0 | 3 | 1 | 1 | 22.0 | 1 | 0 | 1 | 7.2500 | 1 |
| 2 | 1 | 1 | 2 | 2 | 38.0 | 1 | 0 | 2 | 71.2833 | 2 |
| 3 | 1 | 3 | 3 | 2 | 26.0 | 0 | 0 | 3 | 7.9250 | 1 |
| 4 | 1 | 1 | 4 | 2 | 35.0 | 1 | 0 | 4 | 53.1000 | 1 |
| 5 | 0 | 3 | 5 | 1 | 35.0 | 0 | 0 | 5 | 8.0500 | 1 |
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(df.drop(columns = 'Survived'),
df.Survived,
test_size = 0.25,
random_state = 123)
Modelo
Después de pasar un buen par de horas leyendo la documentación (algunas cosas terminaron siendo más difíciles de lo que me esperaba) Logré entender como hacer funcionar esto. Entonces la primera recomendación es crear un experimento. Esto se puede hacer en la UI directamente:
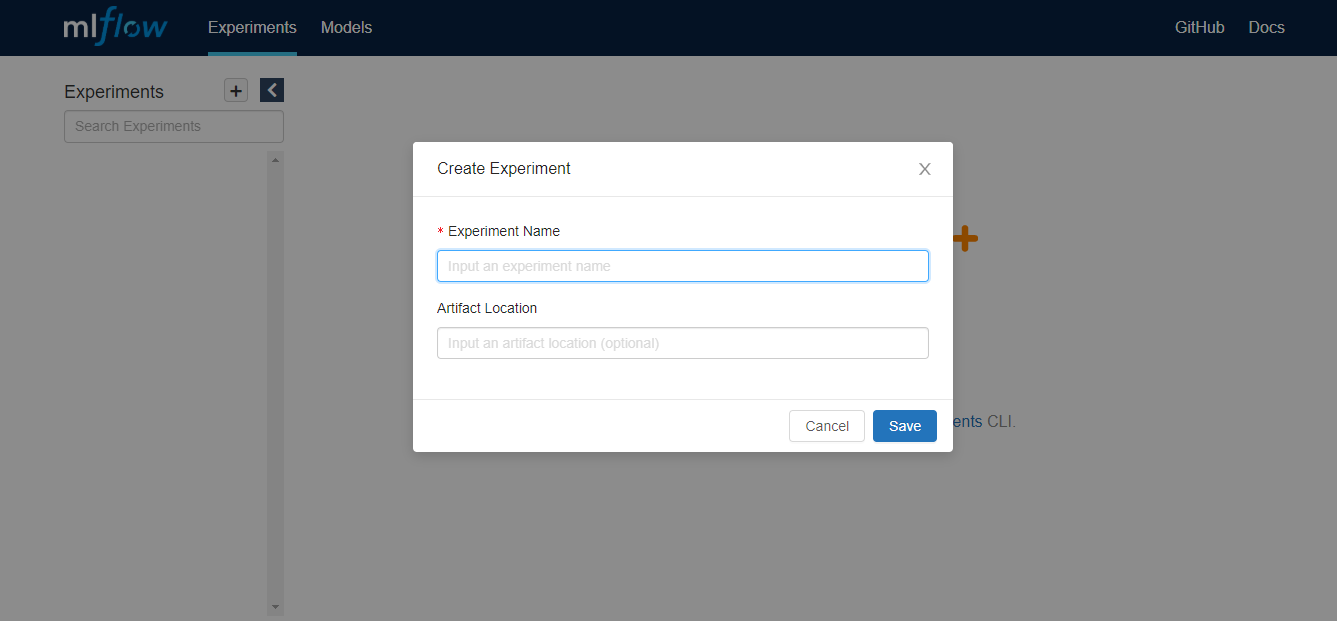
O por comando:
import mlflow
mlflow.set_experiment(experiment_name = 'New Experiment')
INFO: 'New Experiment' does not exist. Creating a new experiment
Este comando es bastante útil, porque creará un experimento en caso que no exista, o seteará el experimento como el “Activo” en caso de que ya exista. A pesar de que existe el comando .create_experiment() igual prefiero el anterior por su flexibilidad.
Luego la la lógica de MlFlow es super directa. Una vez que que se tiene el experimento hay que iniciar un Run, para ello lo mejor es utilizar mlflow.start_run() dentro de un context manager.
mlflow es la API de alto nivel que simplifica toda las cosas pero algunas de sus funcionalidades pueden ser bastante engorrosas cuando es primera vez que uno utiliza esto. Los pro de esta API es que todos los Id serán creados automáticamente, lo cual es bueno para evitar sobreescribir cosas cuando uno no quiere. El contra es que los Id son extremadamente complicados y dificiles de recordar y de acceder. En caso de querer controlar esto habrá que utilizar la API de bajo nivel llamada mlflow.tracking
Una vez que esto está claro, la lógica es sencilla, hay que abrir un Run y se pueden loguear lo siguiente:
parameters: Son generalmente Hiperparámetros del modelo o cualquier valor del notebook que se quiera trackear. Normalmente estos valores son dados por el modelador.
- metrics: Estos son valores que son entregados como resultado del proceso de modelamiento y deben ser medibles.
artifacts: Puede ser cualquier archivo que se quiera adjuntar, pueden ser gráficos, imágenes, etc.
- models: Este es el modelo, normalmente serializado como .pkl (la verdad no he revisado si soporta los .joblib, pero debería). Esta funcionalidad tiene una API distinta para cada libería de modelamiento, por ejemplo si es un modelo de
Scikit-Learnestámlflow.sklearn, si es unXgboost, entonces existemlflow.xgboosty así.
Para este ejemplo voy a correr una Regresión Logística. In this example, I’ll run a simple Logistic Regression, in which I will like to save some parameters such as: solver, C, and max_iter. I will open 3 Runs:
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
C = 1.5, max_iter = 1000, name = 'Run 1'
with mlflow.start_run(run_name = name) as run:
lr = LogisticRegression(solver = 'lbfgs', random_state = 123, max_iter = max_iter, C = C)
lr.fit(X_train,y_train)
acc = lr.score(X_val,y_val)
mlflow.log_param("run_id", run.info.run_id)
mlflow.log_param("solver", 'lbfgs')
mlflow.log_param("max_iter", max_iter)
mlflow.log_param("C", C)
mlflow.log_metric("Accuracy", acc)
mlflow.sklearn.log_model(lr, name)
La idea es correr un modelo similar al de arriba varias veces con distintos valores a loguear.
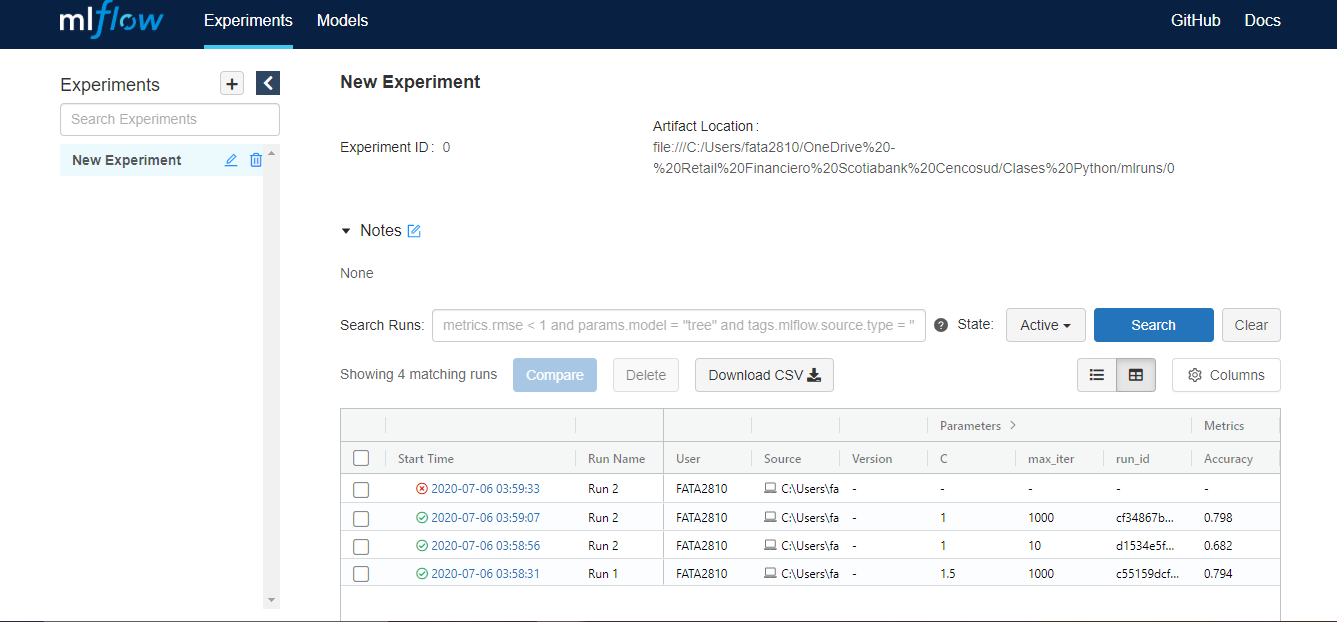
Se corrieron 4 Runs. Cada Run loguea automáticamente la hora de inicio. Justo al lado aparece un ícono rojo o verde dependiendo si el Run corrió sin errores. También es posible darle un Nombre a cada Run utilizando el parámetro run_name, esto es opcional pero recomendado, para saber de qué se trata el Run en cuestión.
Info:Se puede notar en este caso que el Run 2 está repetido, ya que en este caso se corrió 3 veces y en una de ellos falló. El identificador único de cada Run no es el Name si no el run_id
Encontré que el run_id es particularmene dificil de obtener y definirlo manualmente genera otros prolemas con los que no quiero lidiar. Por eso es sumamente importante que cuando se corra un Run se agregue mlflow.log_param("run_id", run.info.run_id) para almacenar el run_id. Esto va a ser particularmente útil luego para acceder otras funcionalidades de MlFlow.
Ahora, al clickear en uno de los Run se llega a la siguiente vista:
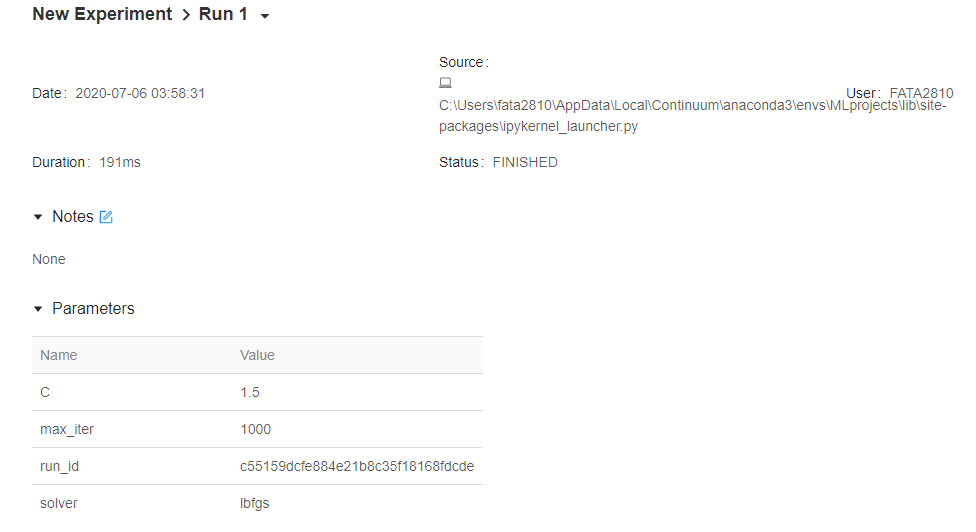
En esta parte se loguearán los parámetros más la información del: inicio de cada Run, duración del Run, etc. Lo cual es bastante útil para evitar magic commands como %%time.
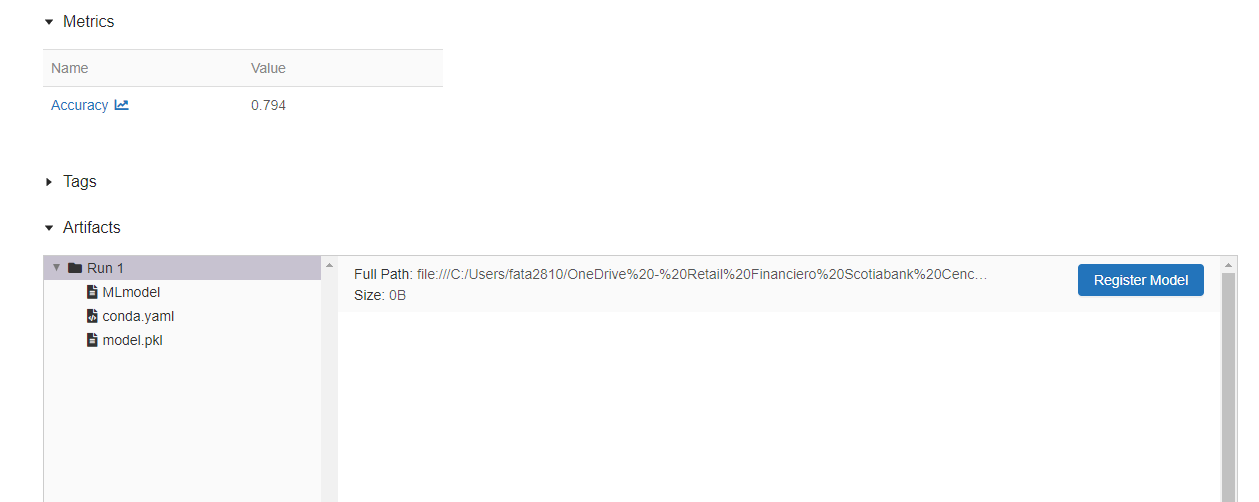
Y existe otra parte que muestra las métricas y los artefactos. En nuestro caso sólo se tiene el modelo como un archivo .pkl.
Existen otros comandos que son bastante útiles para acceder a los objetos logueados.
The format of this information is super complicated to deal with so I recommmend to convert it into a dictionary like this:
dict(mlflow.get_experiment_by_name('New Experiment'))
{'artifact_location': 'file:///C:/Users/fata2810/OneDrive%20-%20Retail%20Financiero%20Scotiabank%20Cencosud/Clases%20Python/mlruns/0',
'experiment_id': '0',
'lifecycle_stage': 'active',
'name': 'New Experiment',
'tags': {}}
El formato eso sí es super complicado así que mi recomendación es convertirlo a algo más amigable como un diccionario.
Para acceder a otro comandos hay que ingresar a la API de bajo nivel como por ejemplo:
Some other important commands are based in the mlflow.tracking API such as .get_run() that will provide the info about the runs and .list_run_infos that will retrieve basically all the run_ids but in a really ugly way.
Warning: El experiment_id es un String, aunque parezca ser un entero.
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.list_run_infos(experiment_id = '0')
[<RunInfo: artifact_uri='file:///C:/Users/fata2810/OneDrive%20-%20Retail%20Financiero%20Scotiabank%20Cencosud/Clases%20Python/mlruns/0/86ba898ad44049edb55203166cfab227/artifacts', end_time=1594022373954, experiment_id='0', lifecycle_stage='active', run_id='86ba898ad44049edb55203166cfab227', run_uuid='86ba898ad44049edb55203166cfab227', start_time=1594022373922, status='FAILED', user_id='FATA2810'>,
<RunInfo: artifact_uri='file:///C:/Users/fata2810/OneDrive%20-%20Retail%20Financiero%20Scotiabank%20Cencosud/Clases%20Python/mlruns/0/cf34867bb1ee45bc9755446eba6e073e/artifacts', end_time=1594022347517, experiment_id='0', lifecycle_stage='active', run_id='cf34867bb1ee45bc9755446eba6e073e', run_uuid='cf34867bb1ee45bc9755446eba6e073e', start_time=1594022347331, status='FINISHED', user_id='FATA2810'>,
<RunInfo: artifact_uri='file:///C:/Users/fata2810/OneDrive%20-%20Retail%20Financiero%20Scotiabank%20Cencosud/Clases%20Python/mlruns/0/d1534e5faf7642faa0f028bdaf68a6bd/artifacts', end_time=1594022336377, experiment_id='0', lifecycle_stage='active', run_id='d1534e5faf7642faa0f028bdaf68a6bd', run_uuid='d1534e5faf7642faa0f028bdaf68a6bd', start_time=1594022336288, status='FINISHED', user_id='FATA2810'>,
<RunInfo: artifact_uri='file:///C:/Users/fata2810/OneDrive%20-%20Retail%20Financiero%20Scotiabank%20Cencosud/Clases%20Python/mlruns/0/c55159dcfe884e21b8c35f18168fdcde/artifacts', end_time=1594022312153, experiment_id='0', lifecycle_stage='active', run_id='c55159dcfe884e21b8c35f18168fdcde', run_uuid='c55159dcfe884e21b8c35f18168fdcde', start_time=1594022311962, status='FINISHED', user_id='FATA2810'>]
client.get_run(run_id = 'c55159dcfe884e21b8c35f18168fdcde')
<Run: data=<RunData: metrics={'Accuracy': 0.7937219730941704}, params={'C': '1.5',
'max_iter': '1000',
'run_id': 'c55159dcfe884e21b8c35f18168fdcde',
'solver': 'lbfgs'}, tags={'mlflow.log-model.history': '[{"run_id": "c55159dcfe884e21b8c35f18168fdcde", '
'"artifact_path": "Run 1", "utc_time_created": '
'"2020-07-06 07:58:32.125378", "flavors": '
'{"python_function": {"loader_module": '
'"mlflow.sklearn", "python_version": "3.7.7", '
'"data": "model.pkl", "env": "conda.yaml"}, '
'"sklearn": {"pickled_model": "model.pkl", '
'"sklearn_version": "0.22.2.post1", '
'"serialization_format": "cloudpickle"}}}]',
'mlflow.runName': 'Run 1',
'mlflow.source.name': 'C:\\Users\\fata2810\\AppData\\Local\\Continuum\\anaconda3\\envs\\MLprojects\\lib\\site-packages\\ipykernel_launcher.py',
'mlflow.source.type': 'LOCAL',
'mlflow.user': 'FATA2810'}>, info=<RunInfo: artifact_uri='file:///C:/Users/fata2810/OneDrive%20-%20Retail%20Financiero%20Scotiabank%20Cencosud/Clases%20Python/mlruns/0/c55159dcfe884e21b8c35f18168fdcde/artifacts', end_time=1594022312153, experiment_id='0', lifecycle_stage='active', run_id='c55159dcfe884e21b8c35f18168fdcde', run_uuid='c55159dcfe884e21b8c35f18168fdcde', start_time=1594022311962, status='FINISHED', user_id='FATA2810'>>
A mi parecer el feature más importante de MlFlow es que permite guardar .pkl. Creo que esto en particular no está bien explicado y me costó montones hacerlo funcionar, pero aquí va:
Primero hay que importar el submodulo del modelo elegido y luego utilizar mlflow.sklearn.load_models() con un URI. Pero ¿Qué es un URI?
Es como un path y en MlFlow funciona así:
runs:/run_id/relative_path_to_models.
En forma simple, extraer un modelo funciona así:
- El run_id se puede obtener utilizando el UI o los comandos que ya se mostraron. El path relativo va a ser la información del segundo argumento de
mlflow.sklearn.log_model(lr, name). En este casonamecreará una carpeta con ese nombre.nameno es más que el Run Name.
import mlflow.sklearn
model_lr = mlflow.sklearn.load_model(f'runs:/c55159dcfe884e21b8c35f18168fdcde/Run 1') #Run 1 is the name of the first experiment
model_lr
LogisticRegression(C=1.5, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=123, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
Como se puede ver, ahora el modelo LR está cargado desde MlFlow en el ambiente de Python.
Esta fue una breve intro a MlFLow, mostrando sus funcionalidades básicas. Aunque la herramienta es bastante simple e intuitiva, la verdad me costó bastante entenderla porque no hay muchos tutoriales que expliquen todo en orden y que tengan códigos de ejemplo.
Voy a probar otras funcionalidades y les cuento. Nos Vemos!!