Modelo de Estimación de RUL
¿Hagamos un Proyecto desde cero? Parte 1

Hace tiempo que me interesaba poder mostrar cómo realizar un proyecto desde cero (Al menos simular cómo hacerlo). Para ello me gustaría mostrar alguna de los problemas que me ha tocado resolver. Hoy día vamos a tratar de predecir el RUL. El RUL o Remaining Useful Life es un problema típico en Mecánica en el que se quiere al menos intentar predecir cuánto falta para que una maquinaria falle. Este es un problema sumamente difícil, porque para poder construir el modelo necesitamos construir data, y necesitamos hacer que maquinas fallen lo cual es caro. Si no tenemos maquinas que fallan, este modelo no funciona, porque necesitamos entender qué pasa justo el tiempo antes que la maquina falle. Lamentablemente, empresas hoy en día quieren que se haga magia adivinando cuando sus maquinas fallan, y peor aún, existen consultoras que prometen resolver este problema sin siquiera tener datos al respecto. Esto porque nadie está dispuesto a que sus maquinas fallen en favor de la ciencia.
Hoy día vamos a ver varios métodos tratando de ver cómo resolver este problema y por qué funciona. Para ello utilizaremos el dataset benchmark stándard que se utiliza para probar metodologías: El NASA CMAPPS. Este dataset contiene funcionamiento simulado de motores de aviones, que representan la realidad bastante bien.
Intetaremos por nuestra parte tratar de simular cómo se resuelve un proyecto de Data Science en la realidad, sólo que un poco más acotado.
No quiero que se aburran con tanto código.
Análisis Exploratorio (EDA)
Normalmente para realizar el análisis exploratorio utilizo un Notebook para poder ir mirando mis datos y dejar comentarios en el mismo lugar. El código completo del EDA está en el siguiente Colab.
Datos de Entrenamiento
En este caso particular, la data se encuentra en formato txt separado por espacios, y no tiene bien definidos los nombres. Por lo que se ingresarán todos de la siguiente forma:
index_names = ['unit_nr', 'time_cycles']
setting_names = ['setting_1', 'setting_2', 'setting_3']
sensor_names = ['s_{}'.format(i) for i in range(1,22)]
col_names = index_names + setting_names + sensor_names
df_train = pd.read_csv('../assets/CMAPSSData/train_FD001.txt', sep = '\s+', header = None, names = col_names)
df_train
| unit_nr | time_cycles | setting_1 | setting_2 | setting_3 | s_1 | s_2 | s_3 | s_4 | s_5 | ... | s_12 | s_13 | s_14 | s_15 | s_16 | s_17 | s_18 | s_19 | s_20 | s_21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | -0.0007 | -0.0004 | 100.0 | 518.67 | 641.82 | 1589.70 | 1400.60 | 14.62 | ... | 521.66 | 2388.02 | 8138.62 | 8.4195 | 0.03 | 392 | 2388 | 100.0 | 39.06 | 23.4190 |
| 1 | 1 | 2 | 0.0019 | -0.0003 | 100.0 | 518.67 | 642.15 | 1591.82 | 1403.14 | 14.62 | ... | 522.28 | 2388.07 | 8131.49 | 8.4318 | 0.03 | 392 | 2388 | 100.0 | 39.00 | 23.4236 |
| 2 | 1 | 3 | -0.0043 | 0.0003 | 100.0 | 518.67 | 642.35 | 1587.99 | 1404.20 | 14.62 | ... | 522.42 | 2388.03 | 8133.23 | 8.4178 | 0.03 | 390 | 2388 | 100.0 | 38.95 | 23.3442 |
| 3 | 1 | 4 | 0.0007 | 0.0000 | 100.0 | 518.67 | 642.35 | 1582.79 | 1401.87 | 14.62 | ... | 522.86 | 2388.08 | 8133.83 | 8.3682 | 0.03 | 392 | 2388 | 100.0 | 38.88 | 23.3739 |
| 4 | 1 | 5 | -0.0019 | -0.0002 | 100.0 | 518.67 | 642.37 | 1582.85 | 1406.22 | 14.62 | ... | 522.19 | 2388.04 | 8133.80 | 8.4294 | 0.03 | 393 | 2388 | 100.0 | 38.90 | 23.4044 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ||
| 20626 | 100 | 196 | -0.0004 | -0.0003 | 100.0 | 518.67 | 643.49 | 1597.98 | 1428.63 | 14.62 | ... | 519.49 | 2388.26 | 8137.60 | 8.4956 | 0.03 | 397 | 2388 | 100.0 | 38.49 | 22.9735 |
| 20627 | 100 | 197 | -0.0016 | -0.0005 | 100.0 | 518.67 | 643.54 | 1604.50 | 1433.58 | 14.62 | ... | 519.68 | 2388.22 | 8136.50 | 8.5139 | 0.03 | 395 | 2388 | 100.0 | 38.30 | 23.1594 |
| 20628 | 100 | 198 | 0.0004 | 0.0000 | 100.0 | 518.67 | 643.42 | 1602.46 | 1428.18 | 14.62 | ... | 520.01 | 2388.24 | 8141.05 | 8.5646 | 0.03 | 398 | 2388 | 100.0 | 38.44 | 22.9333 |
| 20629 | 100 | 199 | -0.0011 | 0.0003 | 100.0 | 518.67 | 643.23 | 1605.26 | 1426.53 | 14.62 | ... | 519.67 | 2388.23 | 8139.29 | 8.5389 | 0.03 | 395 | 2388 | 100.0 | 38.29 | 23.0640 |
| 20630 | 100 | 200 | -0.0032 | -0.0005 | 100.0 | 518.67 | 643.85 | 1600.38 | 1432.14 | 14.62 | ... | 519.30 | 2388.26 | 8137.33 | 8.5036 | 0.03 | 396 | 2388 | 100.0 | 38.37 | 23.0522 |
20631 rows × 26 columns
Como se puede ver el dataset tiene 26 columnas, las cuales corresponden a lo siguiente:
- unit_nr: Es el identificador del Motor. Hay 100 motores diferentes, desde su instalación hasta su falla.
- time_cycles: Es la unidad de tiempo. Cada Cycle es una medición hasta que muere en el último time_cycle.
- setting_1 y setting_2 corresponden a mediciones que fijan configuración del motor.
- s_1 a s_21 son mediciones hechas a distintos sensores del motor para detectar la posible falla.
Acá se pueden ver algunos de los elementos que son medidos en el motor (Pero para mí es chino). 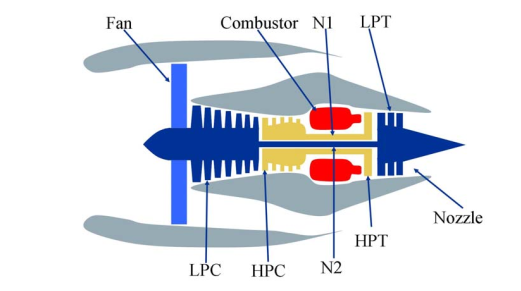
Este dataset no contiene un vector objetivo (algo que ocurre la mayor cantidad del tiempo en la realidad). Por lo tanto vamos a contar la cantidad de ciclos que quedan hasta la falla (RUL). Sabiendo que el último ciclo de cada motor tiene un RUL cero. Creamos el RUL con la siguiente función.
def add_rul(df):
max_cycles = df.groupby('unit_nr',as_index=False).time_cycles.max().rename(columns = {'time_cycles':'max_cycles'})
df = (df.merge(max_cycles, on = 'unit_nr', how = 'left')
.assign(rul = lambda x: x.max_cycles - x.time_cycles)
.drop(columns = 'max_cycles'))
return df
Al chequear la distribución del Máximo RUL por motor se tiene lo siguiente:
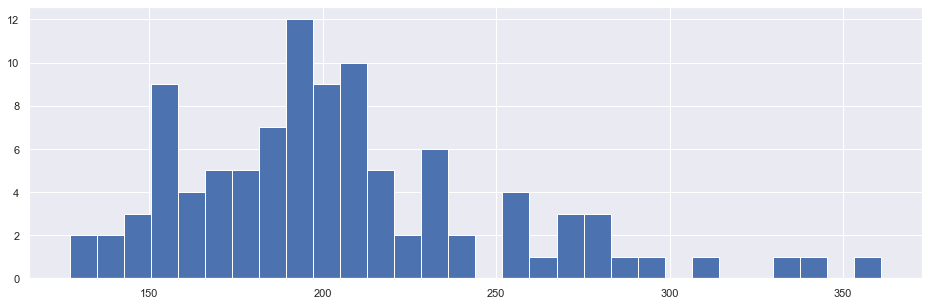
Número de Ciclos de Vida Promedio 205.31
STD Ciclos de Vida 46.34
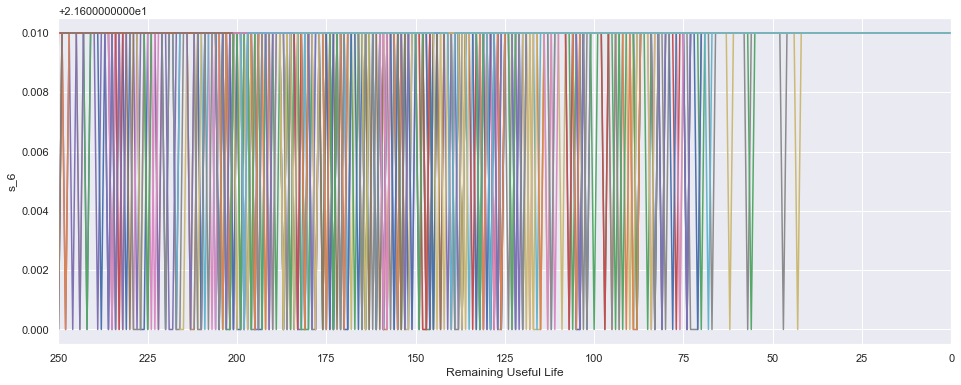
Luego una buena idea es chequear si los sensores utilizados en el proceso son capaces de detectar algo cuando efectivamente el motor va a fallar. Acá algunos ejemplos:
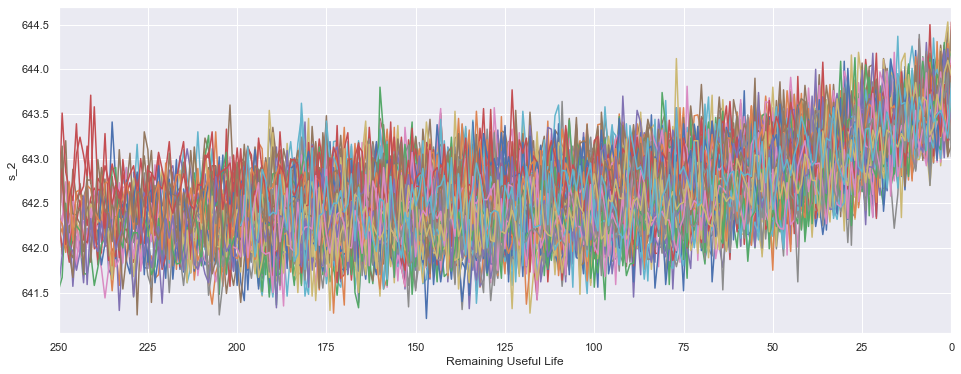
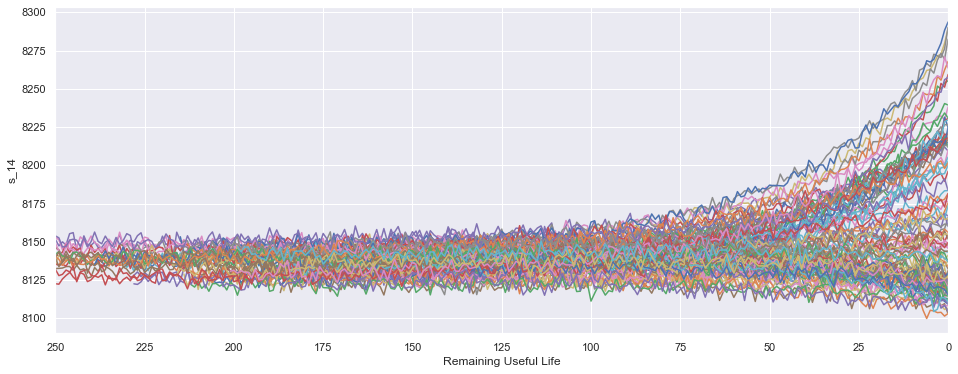
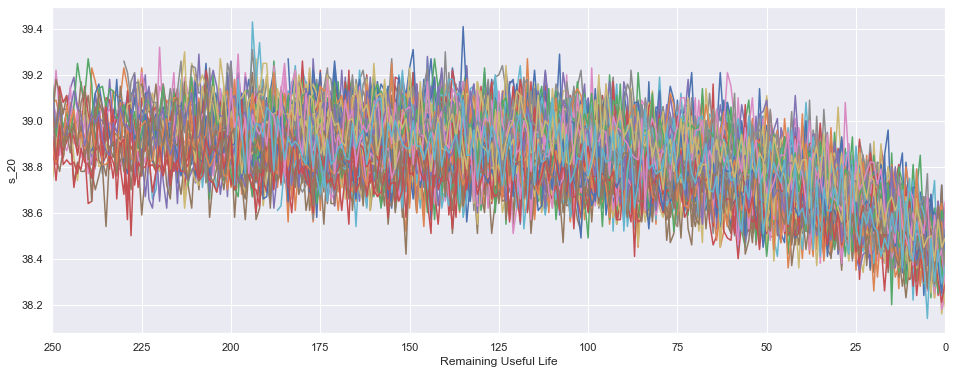
- Podemos ver que el sensor 2 tiene un aumento de su valor cuando un motor se acerca al fin de la vida útil.
- El sensor 6 por otro lado es dificil de interpretar pero pareciera tener un fuerte peak antes de morir.
- El sensor 14 tiene un comportamiento más disperso, algunos motores decrecen mientras que otros se incrementan, incluso algunos se mantienen.
- El sensor 19 tiene una fuerte baja en el último cuarto de su vida útil.
Si chequean el notebook verán que algunos sensores como el 1, 5, 10, 16, 18 y 19 no aportan información.
Datos de Validación
En este caso, la data de validación viene en dos archivos: El primero, un Test set muy similar al de entrenamiento con 100 motores y sus variables predictoras. Y un segundo archivo el cual contiene el valor real del RUL para el último ciclo de vida en el Test set. Cabe destacar que ha diferencia del train set, el test set contiene un número de ciclos que no necesariamente representa la vida completa del motor. Y ahí radica la tarea, generar una buena estimación del RUL para la última medición a los sensores. El formato de estos datos es similar al de entrenamiento y se puede importar así:
df_test = pd.read_csv('../assets/CMAPSSData/test_FD001.txt', sep = '\s+', header = None, names = col_names)
rul = pd.read_csv('../assets/CMAPSSData/RUL_FD001.txt', sep = '\s+', header = None, names = ['RUL'])
Por lo tanto, en el caso que queramos predecir utilizando el test set en modelos Shallow de Machine Learning (no Deep Learning) predeciremos en este set:
df_test.groupby('unit_nr', as_index=False).last()
| unit_nr | time_cycles | setting_1 | setting_2 | setting_3 | s_1 | s_2 | s_3 | s_4 | s_5 | ... | s_12 | s_13 | s_14 | s_15 | s_16 | s_17 | s_18 | s_19 | s_20 | s_21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 31 | -0.0006 | 0.0004 | 100.0 | 518.67 | 642.58 | 1581.22 | 1398.91 | 14.62 | ... | 521.79 | 2388.06 | 8130.11 | 8.4024 | 0.03 | 393 | 2388 | 100.0 | 38.81 | 23.3552 |
| 1 | 2 | 49 | 0.0018 | -0.0001 | 100.0 | 518.67 | 642.55 | 1586.59 | 1410.83 | 14.62 | ... | 521.74 | 2388.09 | 8126.90 | 8.4505 | 0.03 | 391 | 2388 | 100.0 | 38.81 | 23.2618 |
| 2 | 3 | 126 | -0.0016 | 0.0004 | 100.0 | 518.67 | 642.88 | 1589.75 | 1418.89 | 14.62 | ... | 520.83 | 2388.14 | 8131.46 | 8.4119 | 0.03 | 395 | 2388 | 100.0 | 38.93 | 23.2740 |
| 3 | 4 | 106 | 0.0012 | 0.0004 | 100.0 | 518.67 | 642.78 | 1594.53 | 1406.88 | 14.62 | ... | 521.88 | 2388.11 | 8133.64 | 8.4634 | 0.03 | 395 | 2388 | 100.0 | 38.58 | 23.2581 |
| 4 | 5 | 98 | -0.0013 | -0.0004 | 100.0 | 518.67 | 642.27 | 1589.94 | 1419.36 | 14.62 | ... | 521.00 | 2388.15 | 8125.74 | 8.4362 | 0.03 | 394 | 2388 | 100.0 | 38.75 | 23.4117 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | 96 | 97 | -0.0006 | 0.0003 | 100.0 | 518.67 | 642.30 | 1590.88 | 1397.94 | 14.62 | ... | 522.30 | 2388.01 | 8148.24 | 8.4110 | 0.03 | 391 | 2388 | 100.0 | 38.96 | 23.4606 |
| 96 | 97 | 134 | 0.0013 | -0.0001 | 100.0 | 518.67 | 642.59 | 1582.96 | 1410.92 | 14.62 | ... | 521.58 | 2388.06 | 8155.48 | 8.4500 | 0.03 | 395 | 2388 | 100.0 | 38.61 | 23.2953 |
| 97 | 98 | 121 | 0.0017 | 0.0001 | 100.0 | 518.67 | 642.68 | 1599.51 | 1415.47 | 14.62 | ... | 521.53 | 2388.09 | 8146.39 | 8.4235 | 0.03 | 394 | 2388 | 100.0 | 38.76 | 23.3608 |
| 98 | 99 | 97 | 0.0047 | -0.0000 | 100.0 | 518.67 | 642.00 | 1585.03 | 1397.98 | 14.62 | ... | 521.82 | 2388.02 | 8150.38 | 8.4003 | 0.03 | 391 | 2388 | 100.0 | 38.95 | 23.3595 |
| 99 | 100 | 198 | 0.0013 | 0.0003 | 100.0 | 518.67 | 642.95 | 1601.62 | 1424.99 | 14.62 | ... | 521.07 | 2388.05 | 8214.64 | 8.4903 | 0.03 | 396 | 2388 | 100.0 | 38.70 | 23.1855 |
100 rows × 26 columns
Lo cuál nos regresa 100 registros, el último para cada motor.
Modelamiento
Todo el proceso de modelamiento será utilizando las tecnologías que me gustan, es decir, DVC, Scikit-Learn y Pytorch Lightning cuando corresponda. Además el código será en formato Script. Voy a entrar en detalle de ciertas partes del código. Para todo lo demás incluiré al final un Colab con los pasos para analizar los resultados finales. También disponibilizaré los Scripts utilizados para que puedan analizarlos.
El Colab añadido tiene sólo comandos que capaces de reproducir el código. Mayoritariamente serán comandos de DVC. Cada uno de estos comandos irán llamando a los distintos Python Scripts según correspondan. Si realmente te interesa empezar a embarrarte las manos con códigos deberás investigar dichos Scripts.
Modelo Baseline: La querida Regresión Lineal
Lo primero a definir es la configuración que utilizaremos:
from pathlib import Path
import yaml
with open('params.yaml') as f:
params = yaml.safe_load(f)
class Config:
RANDOM_SEED = params['base']['random_seed']
ASSETS_PATH = Path('assets')
DATA_PATH = ASSETS_PATH / 'CMAPSSData'
TRAIN_FILE = DATA_PATH/ params['import']['train_name']
TEST_FILE = DATA_PATH / params['import']['test_name']
RUL_FILE = DATA_PATH / params['import']['rul_name']
FEATURES_PATH = ASSETS_PATH / 'features'
MODELS_PATH = ASSETS_PATH / 'models'
METRICS_PATH = ASSETS_PATH / 'train_metrics.json'
VAL_METRICS_PATH = ASSETS_PATH / 'val_metrics.json'
TEST_METRICS_PATH = ASSETS_PATH / 'test_metrics.json'
Con esto definimos parámetros de reproducibilidad, nuestros Paths de Input de Datos, y carpetas intermedias para almacenar features, modelos y métricas. Todos los parámetros utilizados acá son definidos en mi params.yaml el cual pueden ver en Colab.
1era Etapa: Featurize
import pandas as pd
from config import Config
import yaml
from utils import add_rul
with open('params.yaml') as f:
params = yaml.safe_load(f)['featurize']
#======================================================
# importing files
#======================================================
Config.FEATURES_PATH.mkdir(parents=True, exist_ok=True)
col_names = params['index_names'] + params['setting_names'] + params['sensor_names']
df_train = pd.read_csv(Config.TRAIN_FILE, sep = '\s+', header = None, names = col_names)
df_test = pd.read_csv(Config.TEST_FILE, sep = '\s+', header = None, names = col_names)
rul_test = pd.read_csv(Config.RUL_FILE, sep = '\s+', header = None, names = ['rul'])
#======================================================
# defining features
#======================================================
df_train = add_rul(df_train)
train_features = df_train[params['sensor_names']]
train_labels = df_train.rul
test_features = df_test.groupby('unit_nr').last()[params['sensor_names']]
test_labels = rul_test
#======================================================
# Export Files
#======================================================
train_features.to_csv(Config.FEATURES_PATH / 'train_features.csv', index = None)
train_labels.to_csv(Config.FEATURES_PATH / 'train_labels.csv', index = None)
test_features.to_csv(Config.FEATURES_PATH / 'test_features.csv', index = None)
test_labels.to_csv(Config.FEATURES_PATH / 'test_labels.csv', index = None)
- La etapa featurize básicamente crea la carpeta features, la cual guardará las features que eventualmente se creen.
- Importa train, test y rul y realiza lo siguiente:
- Define variables a utilizar de acuerdo al parámetro
sensor_names. O sea se están utilizando sólo variables del Sensor 1 al 21, sin importar si éste aporta o no información. - Agrega el RUL para el set de entrenamiento.
- Calcula las features de test (como se mostró en el Notebook).
- Guarda por separados train y test features además de train y test labels.
- Define variables a utilizar de acuerdo al parámetro
2da Etapa: Train
from config import Config
import pandas as pd
import joblib
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import numpy as np
import json
import yaml
import logging
log = logging.getLogger("Training")
Config.MODELS_PATH.mkdir(parents=True, exist_ok=True)
with open('params.yaml') as f:
params = yaml.safe_load(f)['train']
train_features = pd.read_csv(Config.FEATURES_PATH / 'train_features.csv')
train_labels = pd.read_csv(Config.FEATURES_PATH / 'train_labels.csv')
print(train_features.shape)
print(train_labels.shape)
model = LinearRegression()
#======================================================
# Validation Metrics
#======================================================
folds = KFold(n_splits=params['n_split'],
shuffle=True,
random_state=Config.RANDOM_SEED)
mae = np.zeros(5)
rmse = np.zeros(5)
r2 = np.zeros(5)
for fold_, (train_idx, val_idx) in enumerate(folds.split(X = train_features, y = train_labels)):
log.info(f'Training Fold: {fold_}')
X_train, X_val = train_features.iloc[train_idx], train_features.iloc[val_idx]
y_train, y_val = train_labels.iloc[train_idx], train_labels.iloc[val_idx]
model.fit(X_train, y_train)
val_preds = model.predict(X_val)
val_mae = mean_absolute_error(y_val, val_preds)
val_rmse = mean_squared_error(y_val, val_preds, squared=False)
val_r2 = r2_score(y_val, val_preds)
mae[fold_] = val_mae
rmse[fold_] = val_rmse
r2[fold_] = val_r2
log.info(f'Validation MAE for Fold {fold_}: {val_mae}')
log.info(f'Validation RMSE for Fold {fold_}: {val_rmse}')
log.info(f'Validation R2 for Fold {fold_}: {val_r2}')
val_metrics = dict(validation = dict(val_mae = mae.mean(),
val_rmse = rmse.mean(),
val_r2 = r2.mean())
)
log.info('Saving Validation Metrics')
with open(Config.VAL_METRICS_PATH, 'w') as outfile:
json.dump(val_metrics, outfile)
#======================================================
# Retrain Model
#======================================================
log.info('Model Retraining')
model.fit(train_features, train_labels)
joblib.dump(model, Config.MODELS_PATH / params['model_name'])
Esta segunda etapa realiza lo siguiente:
- Crear el directorio de Modelos.
- Cargar features y Labels de Entrenamiento.
- Instanciar el Modelo, en este caso una Regresión Lineal.
- Instanciar un proceso de KFold.
Es importante que hay formas muchas más sencillas de hacer un KFold. Entre ellas está utilizar cross_val_score(), cross_validate(), o el mismo GridSearchCV. Estoy acostumbrándome más a esta forma ya que si bien es más verbosa es muchísimo más flexible para formas de modelación más raras.
- Entrenar el Modelo en esquema de Validación y calcular R², RMSE y MAE de Validación.
- Se reentrena el modelo en toda la data y se guarda el modelo como
.joblib.
3era Etapa: Evaluate
import json
import joblib
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import pandas as pd
from utils import plot_oof, plot_importance
from config import Config
Config.IMAGE_PATH.mkdir(parents=True, exist_ok=True)
X_test = pd.read_csv(Config.FEATURES_PATH / 'test_features.csv')
y_test = pd.read_csv(Config.FEATURES_PATH / 'test_labels.csv')
model = joblib.load(Config.MODELS_PATH / 'model.joblib')
y_pred = model.predict(X_test)
#======================================================
# Metrics
#======================================================
test_metrics = dict(test = dict(test_mae = mean_absolute_error(y_test, y_pred),
test_rmse = mean_squared_error(y_test, y_pred, squared=False),
test_r2 = r2_score(y_test, y_pred))
)
with open(Config.TEST_METRICS_PATH, 'w') as outfile:
json.dump(test_metrics, outfile)
#======================================================
# Other Evaluation Curves
#======================================================
plot_oof(y_test, y_pred, s = 10, path = Config.IMAGE_PATH / 'F_vs_t.png')
plot_importance(model, X_test.columns, path = Config.IMAGE_PATH / 'Feature_Importance.png')
Esta etapa final es más cortita, por lo que sólo realizaremos lo siguiente:
- Se crea la carpeta de Imágenes para guardar las Curvas de Interés.
- Se carga la data de test.
- Se carga el modelo entrenado.
- Se calculan las mismas métricas pero ahora para validación.
- Se calculan una curva OOF para chequear qué partes son las que más falla el modelo.
Si quieres correr todo este proceso puedes usar este Google Colab.
Siguientes Pasos
Está claro que este no puede ser nuestro modelo final.
- No hemos limpiado variables que no aportan.
- No hemos creado variables nuevas.
- No hemos probado otros approaches.
- No hemos probado otros modelos.
En la parte 2 iremos agregando algunas de estas mejoras.
Entonces, la idea ahora es desafiarlos. ¿Qué tal nos dio el modelo? ¿Es bueno o es malo? ¿Se puede determinar algún grado de sobreajuste? Ojalá puedas ir comentando lo que pudiste revisar y vamos a ir dejando desafio mayores en cada parte.
Si les gustó la modalidad, y aprendieron algo nuevo, por fa denme una estrellita en el Repo.
Hasta la otra!!