Modelo de Estimación de RUL
¿Hagamos un Proyecto desde cero? Parte 2
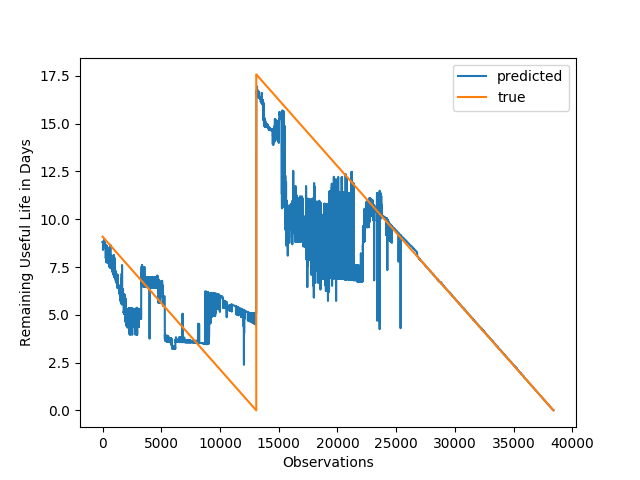
En este artículo estaremos continuando el proyecto que comenzamos la semana pasada. Si es que te perdiste el inicio del proyecto puedes revisar la primera parte acá. La idea es que este proyecto sea interactivo y puedas ir siguiendo las distintas etapas, pero por sobre todo reproduciendo el código y analizándolo.
Si seguiste la parte uno sabrás que implementamos un modelo baseline muy sencillo. Si entrenaste el modelo y visto sus resultados notarás que el modelo que hicimos no anda muy bien, y sería bueno probar nuevas estrategias para mejorar su performance. Mucho del trabajo duro de programación ya lo hicimos en la parte 1 por lo que ahora nos enfocaremos en las mejoras.
De acuerdo a nuestro Análisis Exploratorio vimos que existen sensores que no están aportando información. Por lo tanto, una primera cosa a probar sería eliminar de nuestras features aquellos sensores que no aportan información. Por otro lado, debido a que estamos utilizando una regresión lineal, podríamos crear interaciones entre variables para ver qué tal le va.
Finalmente si analizamos nuestro True vs Fitted Curve de la parte pasada podemos ver lo siguiente:
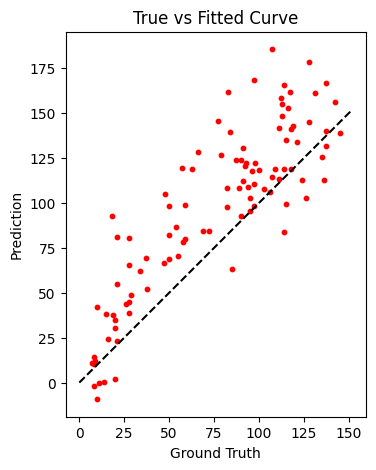
A partir de esto podemos concluimos lo siguiente:
- Parece ser que a medida que el RUL aumenta nuestros errores se hacen más grandes. Eso normalmente es esperable ya que que no hay evidencia para decir que el motor fallará cuando falta demasiado tiempo para su falla. Debido a la naturaleza del problema a nosotros nos interesa entender cuando queda poco tiempo para la falla y enfocarnos ahí. Una técnica utilizada para resolver este problea es usar un clipping. Es decir, yo permito un RUL máximo, todo lo que supere ese RUL máximo lo acoto a dicho nivel.
Implementemos esos cambios y tratemos de buscar el valor de RUL más apropiado.
Archivo de Configuración params.yaml
base:
random_seed: 42
import:
train_name: train_FD001.txt
test_name: test_FD001.txt
rul_name: RUL_FD001.txt
featurize:
index_names: [unit_nr, time_cycles]
setting_names: [setting_1, setting_2, setting_3]
sensor_names: [s_1, s_2, s_3, s_4, s_5, s_6, s_7, s_8, s_9, s_10, s_11, s_12, s_13,
s_14, s_15, s_16, s_17, s_18, s_19, s_20, s_21]
to_keep: [s_2, s_3, s_4, s_6, s_7, s_8, s_9, s_11, s_12, s_13, s_14, s_15, s_17,
s_20, s_21]
train:
model_name: model.joblib
n_split: 5
rul_clip: 50
En este nuevo archivo de configuración tenemos lo siguiente:
- En la etapa featurize agregamos el parámetro
to_keep, que nos perrmitirá determinar con qué sensores queremos quedarnos. Es decir, no consideramos los que no aportan información. La razón por la que hacemos eso es porquesensor_namestiene otra función que es darle el nombre a las variables a importar. - En la etapa train usaremos un clip de 50 inicialmente. Pero la idea es que implementemos una búsqueda de algún valor más óptimo.
Featurize
En esta etapa utilizaremos ahora la función create_features() que nos permitirá crear las interacciones con Scikit-Learn.
def create_features(df_train, df_test, params = None):
pf = PolynomialFeatures(interaction_only=True)
df_train = pd.DataFrame(pf.fit_transform(df_train), columns = pf.get_feature_names_out())
df_test = pd.DataFrame(pf.fit_transform(df_test), columns = pf.get_feature_names_out())
return df_train, df_test
Esta función aceptará un set de train y test y creará las interacciones correspondientes entre ellas.
Normalmente suelo usar la librería Feature Engine para hacer las transformaciones. Resulta que Feature Engine tenía un bug con el uso de PolynomialFeatures. Gracias a Soledad Galli (autora de Feature Engine) que me animó a solucionar el bug que reporté. Mi Pull Request ya es parte de la rama main de la librería y en el próximo release habrá código contribuido por mí, lo que me pone muy contento.

Finalmente en la etapa de definición de features se verá así:
to_keep = params['to_keep']
df_train = add_rul(df_train)
train_features = df_train[to_keep]
test_features = df_test.groupby('unit_nr').last()[to_keep]
train_features, test_features = create_features(train_features, test_features)
Notar que los set ingresados a create_features() son el train luego de crear el RUL y el test, luego de ser agrupado para obtener el último ciclo. La razón de esto se explicó en la la parte 1.
Train
Cuando entrenamos nuestro modelo ahora lo haremos con el RUL clippeado. Por lo tanto, el KFold CV cambia de la siguiente forma:
for fold_, (train_idx, val_idx) in enumerate(folds.split(X = train_features, y = train_labels)):
log.info(f'Training Fold: {fold_}')
X_train, X_val = train_features.iloc[train_idx], train_features.iloc[val_idx]
y_train, y_val = train_labels.iloc[train_idx], train_labels.iloc[val_idx]
model.fit(X_train, y_train.clip(upper = params['rul_clip']))
val_preds = model.predict(X_val)
val_mae = mean_absolute_error(y_val, val_preds)
val_rmse = mean_squared_error(y_val, val_preds, squared=False)
val_r2 = r2_score(y_val, val_preds)
mae[fold_] = val_mae
rmse[fold_] = val_rmse
r2[fold_] = val_r2
log.info(f'Validation MAE for Fold {fold_}: {val_mae}')
log.info(f'Validation RMSE for Fold {fold_}: {val_rmse}')
log.info(f'Validation R2 for Fold {fold_}: {val_r2}')
Notar que al momento del fit, ahora y_train irá con el clip indicado en mis parámetros.
Evaluate
En el caso de nuestro Evaluate, no tendremos ningún cambio, ya que realizaremos el mismo proceso.
Proceso de Experimentación
DVC es sumamente inteligente, y podemos utilizarlo para hacer nuestra búsqueda de Hiperparámetros. DVC automáticamente detecta qué etapas se deben reejecutar y cuáles se pueden reutilizar dependiendo de nuestras dependencias definidas en dvc.yaml (ejecutando dvc_config.sh).
Para definir nuestra búsqueda de Hiperparámetros utilizarmos exp_config.sh:
dvc exp run -S train.rul_clip=150
dvc exp run -S train.rul_clip=130
dvc exp run -S train.rul_clip=125
dvc exp run -S train.rul_clip=120
dvc exp run -S train.rul_clip=90
dvc exp run -S train.rul_clip=70
dvc exp run -S train.rul_clip=50
dvc exp run -S train.rul_clip=30
dvc exp run -S train.rul_clip=10
Si quieres entender el efecto de probar distintos valores de clipping te invito a seguir el experimento en el siguiente Colab:
Ahora les toca poder ejecutar todo este proceso en Colab. ¿Con cuántas features se entrenó el modelo?¿Sirvió de algo lo que implementamos? ¿Cuál es el mejor valor de Clipping? ¿Ves algún problema con las predicciones?
Esto fue todo por esta semana, espero que vayan siguiendo y los espero para revisar los resultados en la parte 3.
Nos vemos,