¿Cómo implementar un clasificador simple de imágenes?
Clasificando Imágenes, pero ahora en Pytorch
La verdad es que por mucho tiempo me resistí a esto. Nunca quise utilizar Pytorch. No me pregunten por qué… quizás una aversión debido a mi preferencia por R y mis ganas de nunca migrar a Python. Un amigo una vez me mostró el siguiente video, y nunca podía entender por qué todo el mundo aplaudía a Pytorch.
A funny Data Science meme, Matlab is my favorite reaction 😄 #datascience #memes pic.twitter.com/zmPx2V7Q6v— Amy Daali (@wdaali999) August 15, 2019
La verdad es que a inicio del año pasado le dí una mirada, y leí un poco de la documentación, y lo primero que pensé fue que esto es igual a Keras. Mucho de los nombres eran idénticos por lo que no encontré gran diferencia. El tema fue que este año al comenzar a hacer clases de Deep Learning con Keras, noté que me era umuy dificil explicar lo que sucedía “Behind the Scenes” porque Keras es estático y no puedo correr código de a poco. Además esconde mucho de los procesos de una red neuronal.
¿Cuáles son las diferencias?
En Keras creas tu red, compilas y fiteas, lo cual es muy conveniente porque es muy sencillo. El tema es que esto esconde demasiado que es lo que la red debe realizar. Además, si bien Tensorflow 2.0 ordena infinitamente más el tema de la documentación aún me pasa al querer buscar algo me pierdo, porque hay muchas formas de poder hacer lo mismo en Tensorflow/Keras. Puede que el problema sea yo, pero realmente me pierdo.
Pytorch por su lado tiene el inconveniente de que a veces codear un modelo es muy verboso, y es cierto, el no tener fit ni compile obliga a tener que crear mucho código repetitivo (aunque se soluciona con frameworks como Lightning), pero me permite entender y explicar de mejor manera como creo la arquitectura, hago un forward propagation, calculo el loss, backpropagation y update de los pesos. Es más largo, pero no esconde lo que sucede.
Otro punto que me gustó mucho es que hoy en día casi todos los Kaggle Grandmaster se movieron a Pytorch (se está notando que Pytorch está entregando mejores modelos en competencia) y comparten sus modelos. Por otra parte la Universidad de Stanford (donde estoy tomando mi especialización), también decido dejar de enseñr en Tensorflow y se movieron completamente a Pytorch. Es por esto que hoy en día aprender los modelos complejos no tradicionales, es mucho más sencillo encontrarlos impolementados en Pytorch que en Tensorflow.
Por esto, me muevo a Pytorch, y espero mostrar que es una mejor opción que Keras, no creo aún que sea mejor que Tensorflow porque es mucho más maduro, pero a la vez bastante más engorroso.
Entonces para partir, voy a empezar generando un Modelo muy sencillo para clasificar Dígitos con el Dataset MNIST. Mi idea es luego moverme a problemas más complejos que permitan sacarle provecho a Pytorch, normalmente cosas que nunca logré entender cómo implementar en Keras/Tensorflow.
MNIST
MNIST es un dataset ultra conocido, que tiene 60000 imágenes para entrenar y 10000 imágenes para testear de dígitos escritos a mano. En general es de los primeros dataset que se utilizan para poder comenzar en Redes Neuronales.
Este corresponde entonces a un Modelo Multiclase con 10 Labels (dígitos del 0 al 9) y utilizaremos una Red Neuronal “Fully Connected” para poder aprender cómo reconocer estos dígitos.
Implementación en Pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torchvision
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Cargando los Datos
Es importante recalcar que Pytorch tiene una filosofía al momento de cargar los datos. Si bien es cierto no es tan necesario para este problema, es bueno presentar desde algunas funciones que entregan flexibilidad al momento de cargar datos, por Batch
, que permiten ir cargando la GPU de manera paulatina para no quedarse sin memoria.
Lo primero es descargar los datos, para ello se utilizará la librería torchvision que contiene el MNIST.
Descarga
train_data = torchvision.datasets.MNIST(root = 'PYTORCH_NOTEBOOKS/Data',
train=True,
download=True,
transform = transforms.ToTensor())
test_data = torchvision.datasets.MNIST(root = 'PYTORCH_NOTEBOOKS/Data',
train=False,
download=True,
transform = transforms.ToTensor())
La manera en la que torchvision almacena los datos es del tipo PIL, es decir imágenes, al utilizar transform = transforms.ToTensor() generamos una transformación de estas imágenes en Tensores de Pytorch de manera muy sencilla.
Luego debido a la naturaleza aleatoria de los procesos, fijaremos una semilla, setearemos donde queremos trabajar (CPU o GPU), y crearemos el DataLoader para ir cargando los datos en Batches.
torch.manual_seed(101)
device = "cuda" if torch.cuda.is_available() else "cpu"
kwargs = {'num_workers': 10, 'pin_memory': True} if device=='cuda' else {}
Como pueden ver, una de las ventajas que ofrece Pytorch es que permite escoger un device de manera optativa. En este caso, si se reconoce una GPU la utilizará y si no trabajará directo en CPU. En especial para aquellos que no tienen GPU, este código debiera funcionar de la misma manera que para los que tienen GPU.
Data Loaders
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=100, **kwargs)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=500, **kwargs)
En este caso el batch_size es de 100 para entrenar y de 500 para testear. ¿Por qué esta diferencia? Esta es una de las cosas que sólo llegue a entender leyendo la documentación de Pytorch (y bueno estudiando un poco). El Batch Size se utiliza cuando tus datos no caben en memoria. También sirve como un mecanismo de Regularización ya que evita que el modelo memorice todo el dataset en cada Epoch. Es por esto que escoger un Batch_size influye directamente en el desempeño del proceso de entrenamiento, pero no tanto en el de test, por lo que al momento de Inferencia sólo es necesario fijarse que los datos quepan en Memoria.
Una muestra de los datos
from torchvision.utils import make_grid
for images, labels in train_loader:
break
print('Labels: ',labels[:12].numpy())
im = make_grid(images[:12],nrow = 12)
plt.figure(figsize = (10,4))
plt.imshow(np.transpose(im.numpy(),(1,2,0))) #reorder as wh and channel
Labels: [5 0 4 1 9 2 1 3 1 4 3 5]
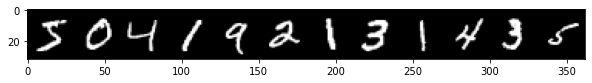
El modelo
Esto puede ser algo tedioso nuevamente, pero al final, termina siendo un forzoso llamado a las buenas prácticas. Pytorch define sus modelos mediante clases, lo cual obliga a aprender un poquito de OOP en Python pero también ordena el código de muy buena manera.
La manera en la que Pytorch define un modelo es como sigue:
def __init__(self, in_sz = 784, out_sz = 10, layers = [120,84]):
super().__init__()
self.fc1 = nn.Linear(in_sz, layers[0])
self.fc2 = nn.Linear(layers[0],layers[1])
self.fc3 = nn.Linear(layers[1],out_sz)
__init__() Corresponde a la función para instanciar una clase en Python, y permitirá en este caso definir la Arquitectura de una Red Neuronal, en este caso:
- Red Neuronal con 3 capas totalmente conectadas,es decir,
Linear(). - Cada capa define los valores de entrada y de salida, en este caso la
fc1, toma 784 valores de entrada que son el número de pixeles de una imágen MNIST ($28\times28$) y se conecta confc2que tiene 120 neuronas (layers[0]).fc2es una capa oculta que conecta 120 neuronas con 84 neuronas (valores elegidos aleatoriamente). Finalmente,fc3corresponde a una capa que une las 84 neuronas defc2con 10 neuronas que corresponden a las 10 clases a predecir.
Al menos en Pytorch, las capas definidas corresponden no a las capas de Neuronas, si no a las conexiones entre capa y capa. fc1 serán todos los pesos que unen la capa de entrada con la primera capa oculta de 120 neuronas, fc2 será un segundo grupo de pesos que unen 120 neuronas con otra capa oculta de 84 neuronas para que fc3 sea finalmente quien lleve de estas 84 neuronas a las 10 finales que son las encargadas de la predicción. En Keras, siempre me dio la impresión de que al definir la capa uno define el número de Neuronas de la capa, donde la capa es la configuración de dichas neuronas.
Luego existe la función forward, que permite definir cómo se realizará el “forward_propagation”. Nuevamente Pytorch no esconde lo que sucede en la red, si no que acá explicitamente se muestra por qué capas nuestros valores de entrada pasarán y qué funciones de activación alteraran de manera no-lineal nuestra Red. ESta función tiene especial sentido cuando no utilizamos capas secuenciales sino otras configuraciones más complejas (Se viene un tutorial de eso).
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim = 1)
En este caso los valores de entrada $x$ pasan por la capa fc1 y fc2 que se activa con ReLU, para llegar a a la capa de salida fc3. Debido a que se trata de un problema multiclase de clasificación es que para obtener probabilidades normalizadas entre 0 y 1 se utiliza la función Softmax.
class MultilayerPerceptron(nn.Module):
def __init__(self, in_sz = 784, out_sz = 10, layers = [120,84]):
super().__init__()
self.fc1 = nn.Linear(in_sz, layers[0])
self.fc2 = nn.Linear(layers[0],layers[1])
self.fc3 = nn.Linear(layers[1],out_sz)
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim = 1) # multiclass classification
model = MultilayerPerceptron().to(device)
model
MultilayerPerceptron(
(fc1): Linear(in_features=784, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
En el caso de que nos interese ver el número de parámetros podemos contarlos capa a capa de la siguyiente manera.
for param in model.parameters():
print(param.numel()) #total 105,214
94080
120
10080
84
840
10
Entrenamiento del Modelo
Esta parte puede llegar a ser la más tediosa, pero es donde creo que Pytorch brilla, ya que no esconde que sucede por detrás ya que es explícito en definir cada parte del proceso:
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.001)
import time
start_time = time.time() # utilizado para tomar tiempo
epochs = 10
train_losses = []
test_losses = []
train_correct = []
test_correct = []
for i in range(epochs):
trn_corr = 0
tst_corr = 0
for b, (X_train, y_train) in enumerate(train_loader):
b+=1
x,y = X_train.to(device), y_train.to(device)
y_pred = model(x.view(100,-1))
loss = criterion(y_pred, y)
predicted = torch.max(y_pred.data,1)[1]
batch_corr = (predicted == y).sum()
trn_corr += batch_corr
optimizer.zero_grad()
loss.backward()
optimizer.step()
if b%200 ==0:
acc = trn_corr.item()*100/(100*b)
print(f'Epoch {i} batch {b} loss: {loss.item()} accuracy: {acc}')
train_losses.append(loss)
train_correct.append(trn_corr)
with torch.no_grad():
for b, (X_test, y_test) in enumerate(test_loader):
x_t,y_t = X_test.to(device), y_test.to(device)
y_val = model(x_t.view(500,-1))
predicted = torch.max(y_val.data,1)[1]
tst_corr += (predicted==y_t).sum()
loss = criterion(y_val, y_t)
test_losses.append(loss)
test_correct.append(tst_corr)
total_time = time.time() - start_time
print(f'Duration: {total_time/60} mins')
Epoch 0 batch 200 loss: 0.36317500472068787 accuracy: 82.695
Epoch 0 batch 400 loss: 0.36911827325820923 accuracy: 87.03
Epoch 0 batch 600 loss: 0.2697577178478241 accuracy: 89.015
Epoch 1 batch 200 loss: 0.14277513325214386 accuracy: 94.415
Epoch 1 batch 400 loss: 0.22278247773647308 accuracy: 94.665
Epoch 1 batch 600 loss: 0.24916048347949982 accuracy: 94.91333333333333
Epoch 2 batch 200 loss: 0.07350048422813416 accuracy: 96.32
Epoch 2 batch 400 loss: 0.14101330935955048 accuracy: 96.33
Epoch 2 batch 600 loss: 0.22833894193172455 accuracy: 96.45333333333333
Epoch 3 batch 200 loss: 0.037917863577604294 accuracy: 97.38
Epoch 3 batch 400 loss: 0.0826350599527359 accuracy: 97.295
Epoch 3 batch 600 loss: 0.20671837031841278 accuracy: 97.355
Epoch 4 batch 200 loss: 0.028422381728887558 accuracy: 98.02
Epoch 4 batch 400 loss: 0.049470771104097366 accuracy: 97.905
Epoch 4 batch 600 loss: 0.17782554030418396 accuracy: 97.96833333333333
Epoch 5 batch 200 loss: 0.027242567390203476 accuracy: 98.51
Epoch 5 batch 400 loss: 0.02850380912423134 accuracy: 98.4025
Epoch 5 batch 600 loss: 0.1584969162940979 accuracy: 98.44666666666667
Epoch 6 batch 200 loss: 0.019592147320508957 accuracy: 98.82
Epoch 6 batch 400 loss: 0.02108437567949295 accuracy: 98.8075
Epoch 6 batch 600 loss: 0.13506217300891876 accuracy: 98.80666666666667
Epoch 7 batch 200 loss: 0.017968127503991127 accuracy: 99.08
Epoch 7 batch 400 loss: 0.014408771879971027 accuracy: 99.075
Epoch 7 batch 600 loss: 0.11232930421829224 accuracy: 99.05333333333333
Epoch 8 batch 200 loss: 0.015787210315465927 accuracy: 99.25
Epoch 8 batch 400 loss: 0.02655889466404915 accuracy: 99.2575
Epoch 8 batch 600 loss: 0.10637059807777405 accuracy: 99.25166666666667
Epoch 9 batch 200 loss: 0.01612943783402443 accuracy: 99.38
Epoch 9 batch 400 loss: 0.0067123305052518845 accuracy: 99.3675
Epoch 9 batch 600 loss: 0.09062175452709198 accuracy: 99.34666666666666
Duration: 0.299970281124115 mins
Este código puede ser bastante intimidante, pero lo analizaremos por parte. Básicamente Pytorch se entrena por Epochs y por Batches, y luego esto se loopea para todos los batches y todas las epochs necesarias.
Para conocer más del Equipo con el que entrené este modelo puedes venir acá.
x,y = X_train.to(device), y_train.to(device)
y_pred = model(x.view(100,-1))
loss = criterion(y_pred, y)
#conteo de correctos
predicted = torch.max(y_pred.data,1)[1]
batch_corr = (predicted == y).sum()
trn_corr += batch_corr
#IMPORTANTE
optimizer.zero_grad()
loss.backward()
optimizer.step()
El código línea a línea es bastante intuitivo:
- Se lanza el Batch de Entrenamiento (X e y) al device correspondiente (Si se entrena sólo en CPU este paso no es necesario)
- Se genera una predicción.
.viewactuará como un Flatten que transformara la imágen de $28\times28$ en $784\times 1$ en batches de 100. - Se calcula el Loss Function.
- Se cuentan cuántos correctos hay en cada batch, este paso es opcional y puede evitarse.
- Esta es la parte importante (estos pasos son obligatorios):
optimizer.zero_grad()reiniciará los gradientes, esto permite que no se acumulen entre epochs y batches.loss.backward()calcula los gradientes de la red. Este cálculo permitirá entonces actualizar los pesos dependiendo de la estrategia de optimización escogida.optimizer.step()genera la actualización de los pesos. Es decir, esta es la etapa donde el modelo efectivamente aprende.
if b % 200 ==0:
acc = trn_corr.item()*100/(100*b)
print(f'Epoch {i} batch {b} loss: {loss.item()} accuracy: {acc}')
Esta sección tiene como único objetivo reportar el avance del proceso de Entrenamiento. No es necesario incluirlo, pero ayudará a ir monitoreando el proceso de entrenamiento.
with torch.no_grad():
for b, (X_test, y_test) in enumerate(test_loader):
x_t,y_t = X_test.to(device), y_test.to(device)
y_val = model(x_t.view(500,-1))
predicted = torch.max(y_val.data,1)[1]
tst_corr += (predicted==y_t).sum()
loss = criterion(y_val, y_t)
test_losses.append(loss)
test_correct.append(tst_corr)
Este Context Manager
permite desactivar la acumulación de gradientes. Este paso básicamente le avisa al modelo que no está entrenándose por lo que no debe variar gradientes, sino que está evaluando.
Línea a Línea sería:
- Para cada Batch, en este caso de test
- Muevo los datos a la GPU en caso de estar disponible.
- Genera predicciones pero en este caso en batches de 500.
- Cuenta los valores correctos
- Almacena los valores de Loss, y número de Correctos.
Testeando el Modelo
De acuerdo a los resultados obtenidos, podríamos mirar las imágenes de los 12 primeros números, tal cual hicimos en la parte exploratoria, pero en este caso para los datos de Test:
im = make_grid(X_test[:12],nrow = 12)
plt.figure(figsize = (10,4))
plt.imshow(np.transpose(im.numpy(),(1,2,0)))
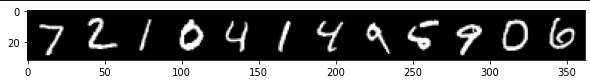
torch.argmax(y_val, dim = 1)[:12]
tensor([7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6], device='cuda:0')
Se puede ver que el modelo fue todo un éxito. Dada la buena arquitectura realizada fue posible obtener un puntaje de entrenamiento y validación suficientemente bueno que permite generalizar de muy buena manera. En este caso se puede ver que todos los números fueron correctamente predichos.
Esto ha sido todo, espero se entienda las capacidades de Pytorch, a pesar de que el código puede ser abrumante inicialmente la idea es poder efectivamente entender qué sucede en la red de manera interna.
¿Es necesario utilizar todo este montón de codigo siempre? Yo diría que para empezar sí, para entender qué hace la red. Pero pretendo mostrar Pytorch Lightning en el futuro, éste permite evitar todo el código repetitivo para enfocarse primordialmente en el diseño de la Red, pero para entender aquello creo que es muy beneicioso entender el proceso interno.
Nos vemos,