Creando un Recomendador de Películas
¿Cómo funciona un Sistema Recomendador?

Los sistemas de Recomendación están en todas partes. Abrimos Netflix, Amazon, Spotify, sin ir más lejos el mismo Mercado Libre, y todos siempre tienen algo que ofrecernos. Los sistemas de recomendación son otro tipo de modelos de modelos de Machine Learning, y son el eje principal en las grandes de Silicon Valley. Pero, conversando con Gustavo Prudencio de Cornershop, ambos estuvimos de acuerdo en que no son para nada Modelos Populares. Es más, particularmente en Chile, creo que es de los modelos más raros de ver. Probablemente Cornershop sea de los pioneros en esto (aunque no me quiso dar detalles de qué tienen actualmente implementado 😆).
En fin, no soy experto en modelos de recomendación. Pero por ahí en el 2019 me tocó armar un piloto en Cencosud Scotiabank utilizando filtrado colaborativo con librerías como implicit, surprise y lightfm pero nunca llegué a entenderlo a profundidad. Este fin de semana decidí aprender en más profundidad de esto e implementar un modelo de Recomendación en Pytorch (así como si tuviera tiempo de sobra, el cual no tengo).
Modelo de Recomendación
Entender el problema de recomendación es muy sencillo, hay dos tipos de recomendadores, los que usan rating explícito y rating implícito.
Rating Explícito: Es cuando un usuario de manera explícita califica un producto: Notas, estrellas, lo que sea. El tema con este tipo de data es que es rara porque normalmente no es obligatorio calificar un producto.
Rating Implícito: Es cuando la calificación del producto se da de manera implícita. Normalmente se puede dar como: compra o no compra un producto, ve o no ve un video, escucha o no una canción, etc.
El objetivo del modelo de Recomendación determinar qué producto sería bueno mostrarle al usuario. Para ello existen distintos approaches. El más común hoy el día es el filtrado colaborativo. Es una técnica que consiste en que se recomendarán productos que usuarios parecidos a ti hayan visto. Por lo tanto, no influye solo lo que tú has visto, sino que también lo que gente con gustos similares a los tuyos han visto.
Mi interés es poder implementar un modelo de Deep Learning que tenga esto en cosideración, por lo tanto, decidí utilizar el siguiente paper implementando un Neural Collaborative Filtering:
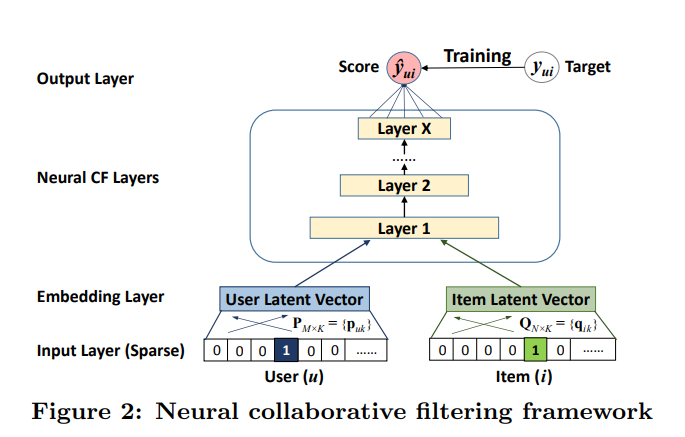
Este modelo está basado en Embeddings, que es una especie de Encoding en el cual se representa un espacio de alta dimensionalidad en un espacio de menor dimensionalidad en el cual la distancia de las representaciones pueden tener una cierta interpretación. Esto es particularmente importante porque normalmente los sistemas recomendadores están implementados cuando hay muchos usuarios y muchos productos.
Para el caso que quiero mostrar voy a utilizar un dataset llamado MovieLens 25M, el cual se puede descargar de acá. La razón por la que escogí este dataset es porque contiene una lista de usuarios y películas calificadas por usuarios hasta el 2019, que incluye muchas películas actuales (aunque pre-pandemia). El problema del dataset es que contiene 25 millones de ratings, 62423 películas y 162541 usuarios.
No voy a utilizar el dataset completo porque no quiero ensuciar las recomendaciones con películas antiguas, pero de igual manera quiero como desafío personal trabajar con una gran cantidad de datos. Es en este tipo de problemas cuando realmente es necesario tener buenas skills de programación para poder lidiar con alta cantidad de datos.
Esto no es Big Data, es harta data pero para que se vea el poder del Stack de Data Science no vamos a usar nada extraño, sólo Pandas, Scipy y Numpy.
Entonces para poder entender qué hace el modelo encontré el siguiente ejemplo: Supongamos que Bob no es muy fan de las peliculas de Romance, pero sí de ls películas de Acción, mientras que Joe, le gustan ambas. Podemos dependiendo del id de usuario y de las id de las películas vistas transformarlo en lo siguiente:
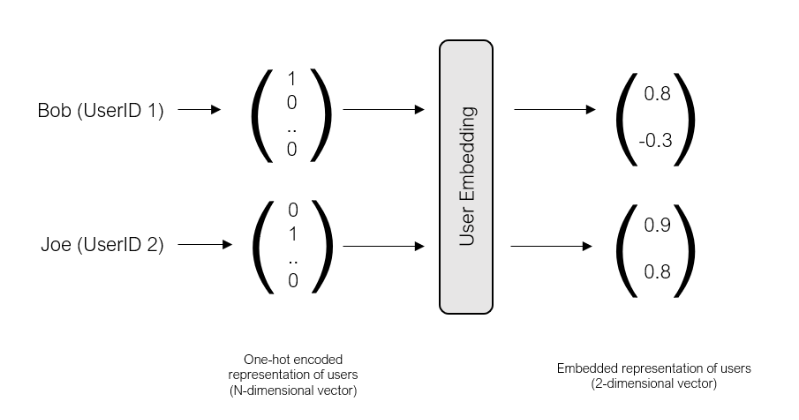
Luego su representación en el plano bidimensional Action x Romance nos permite identificar qué tan parecidos o distintos son Bob y Joe. Esto permitirá al modelo aprender las relaciones que existen entre usuarios al momento de poder recomendar.
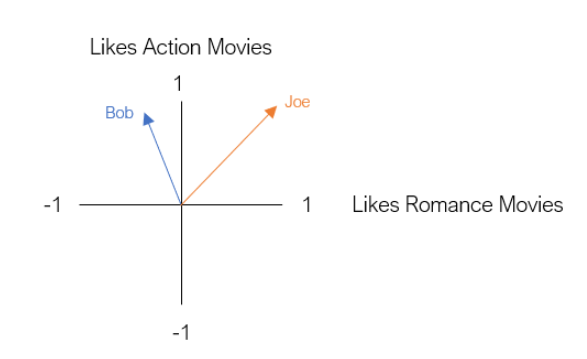
Teniendo estas ideas básicas del funcionamiento de un recomendador vamos a la implementación:
Entendiendo los datos
Películas
import pandas as pd
import numpy as np
movies = pd.read_csv('ml-25m/movies.csv')
print(movies.shape)
(62423, 3)
Index(['movieId', 'title', 'genres'], dtype='object')
El set de películas contiene sólo el Id de Película, el título y los géneros asociados a cada película. La verdad es que el formato no es mi favorito, por lo que decidí limpiar un poco la data para por ejemplo poder obtener el año de cada película. Además como dijimos anteriormente, no queremos recomendar películas viejas por lo que decidí mantener sólo las películas de 2010 en adelante.
year = 2010
movies['year'] = movies.title.str.extract(r'\((\d{4})\)').astype("float")
movie_id_removed = movies.query('year < @year').movieId.tolist()
movies = movies.query('year >= @year')
movies
| movieId | title | genres | year | |
|---|---|---|---|---|
| 14156 | 73268 | Daybreakers (2010) | Action|Drama|Horror|Thriller | 2010.0 |
| 14161 | 73319 | Leap Year (2010) | Comedy|Romance | 2010.0 |
| 14162 | 73321 | Book of Eli, The (2010) | Action|Adventure|Drama | 2010.0 |
| 14222 | 73744 | If You Love (Jos rakastat) (2010) | Drama|Musical|Romance | 2010.0 |
| 14256 | 73929 | Legion (2010) | Action|Fantasy|Horror|Thriller | 2010.0 |
| ... | ... | ... | ... | ... |
| 62412 | 209143 | The Painting (2019) | Animation|Documentary | 2019.0 |
| 62413 | 209145 | Liberté (2019) | Drama | 2019.0 |
| 62415 | 209151 | Mao Zedong 1949 (2019) | (no genres listed) | 2019.0 |
| 62418 | 209157 | We (2018) | Drama | 2018.0 |
| 62420 | 209163 | Bad Poems (2018) | Comedy|Drama | 2018.0 |
20489 rows × 4 columns
Esto nos dejó con 20489 películas pero que no deja de ser un número considerable.
Además es importante guardar los id de las películas removidas que fueron 41524. Estas tienen que retirarse también de los reviews de los usuarios.
len(movie_id_removed)
41524
Finalmente, creé un mapping entre el movieId y el nombre de la película. Esto será de gran utilidad al final del procedimiento, para poder identificar los movieId recomendado para ver si es que hacen sentido.
movies_mapping = movies[['movieId','title']].set_index('movieId').to_dict()['title']
Calificaciones
Por otro lado, tenemos el dataset de Ratings, el cual contiene los 25 millones de datos. Estos contienen los distintos usuarios con las películas vistas y sus reviews. Además incluye un timestamp para poder por ejemplo, tener información de cuando vió la película, en caso de que el orden también tenga relevancia para la recomendación.
ratings = pd.read_csv('ml-25m/ratings.csv', parse_dates=['timestamp'])
print(ratings.columns)
print(ratings.shape)
ratings.userId.nunique()
Index(['userId', 'movieId', 'rating', 'timestamp'], dtype='object')
(25000095, 4)
162541
Entonces, dentro del procesamiento de los datos tenemos que primero eliminar todas las películas anteriores a 2010 (por eso guardamos los movieId de las películas). Además modificaremos el rating a 1. Esto convertirá nuestro problema en un recomendador implícito. Es decir, el 1 significará que el usuario interactuó con la película, es decir, la vio. Esto es importante para el algoritmo de recomendación ya que entonces tendremos que modelar nuestro problema como un problema de clasificación.
ratings = ratings.query('movieId not in @movie_id_removed')
ratings['rating'] = 1
ratings['timestamp'] = pd.to_datetime(ratings['timestamp'], unit='s')
ratings
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 712 | 3 | 73268 | 1 | 2015-08-13 14:11:38 |
| 713 | 3 | 73321 | 1 | 2015-08-13 13:52:05 |
| 715 | 3 | 74458 | 1 | 2017-04-21 14:39:18 |
| 716 | 3 | 74789 | 1 | 2019-08-18 00:59:42 |
| 717 | 3 | 76077 | 1 | 2017-01-18 16:15:09 |
| ... | ... | ... | ... | ... |
| 24999773 | 162538 | 111617 | 1 | 2015-08-05 14:15:09 |
| 24999774 | 162538 | 112138 | 1 | 2015-08-05 14:14:35 |
| 24999775 | 162538 | 112556 | 1 | 2015-08-05 14:25:33 |
| 24999776 | 162538 | 116797 | 1 | 2015-08-05 13:25:21 |
| 24999777 | 162538 | 126548 | 1 | 2015-08-05 14:24:57 |
2711937 rows × 4 columns
Este es quizás uno de los proyectos que más he disfrutado haciendo, y la razón principal es porque el Proceso de un Motor de Recomendación es bastante más complejo que sólo entrenar el modelo. La data tiene que ser manipulada de muchas maneras distintas (incluyendo sus complejidades por el tamaño, así que veamos cómo me las ingenié)
Label Encoder
Debido a los recortes que hicimos en la data, nuetros Id, tanto de Usuarios como de películas no tienen porque ser consecutivos. Esto nos pueden traer algún problema para el algoritmo ya que el id va a representar una distancia en nuestro espacio de embeddings y no queremos que esto se vea alterado. Para ello entonces utilizaremos el LabelEncoder para crear un mapeo entre los ids reales y un id correlativo.
Esto es básicamente lo mismo que hicimos con el mapeo de películas, pero eventualmente al momento de produccionalizar esto tendremos que tener acceso rápido a nuestros mapeos, por lo que el LabelEncoder permite una fácil serialización de ellos, ya que las clases quedarán como listas.
from sklearn.preprocessing import LabelEncoder
user_encoder = LabelEncoder()
movie_encoder = LabelEncoder()
ratings['userId'] = user_encoder.fit_transform(ratings.userId)
ratings['movieId'] = movie_encoder.fit_transform(ratings.movieId)
Primer Tropezón
Dado que este es un recomendador implícito, va a ser modelado como un problema de clasificación binaria. Por lo que tenemos muchas películas que el usuario ha visto, pero no tenemos las que no ha visto. Para que el modelo pueda aprender bien leí que una buena idea es poder entregar casos negativos, es decir, películas que no ha visto. Y un buen ratio era 4:1, es decir 4 películas no vistas por cada película vista.
Mi primer approach fue este:
def create_negative_movies(df, userid = 'userId', movieid = 'movieId',neg_examples = 4):
unique_movies = set(df[movieid])
movies = []
uids = df[userid].unique()
for u in uids:
movies.extend(np.random.choice(list(unique_movies - set(df[movieid][df[userid] == u])), size = neg_examples))
return uids, movies
Intenté una implementación, que de partida estaba mala, pero que demoró 20 minutos en ejecutarse. Básicamente el código hace lo siguiente:
- Para cada usuario en la lista de usuarios.
- Calculo la diferencia entre todos los ids de películas y las que ha visto un usuario.
- A partir de las películas no vistas saco un random de 4 ejemplos.
Este approach está incorrecto porque generé sólo 4 ejemplos por usuario, unos 400K registros extras y demoró demasiado debido a los muchos usuarios, y debido a que filtrar un dataset tan grande tantas veces lo hace muy lento.
La solución
Si han estudiado el mecanismo de atención de los transformers, notarán que básicamente se basan en un one-hot encoder para utilizarla como una matriz de filtrado (si quieren estudiar esto en detalle pueden leerlo acá). Con esto podríamos crear una matriz cuyas filas sean los ids de los usuarios y las columnas los ids de las películas. Esto se conoce como una user-item matrix y basta con hacerla así:
user_item_matrix = ratings.pivot(index = 'userId', columns = 'movieId', values = 'rating').fillna(0)
El problema es que esta matriz es gigantesca y me dio el clásico error Unable to allocate 1010. MiB for an array with shape....
Entonces, aquí es donde hay que ponerse creativo. Básicamente la user-item matrix es una matriz rala (escasa, esparsa, llena de ceros, no sé cuál es la terminología correcta, sparse matrix en inglés…). Y scipy tiene matrices especiales para eso. csr_matrix sólo almacena los índices de los valores distintos de cero. Este tipo de matriz es extremadamente eficiente para sumas y productos matriciales, los cuales no vamos a usar, pero sí queremos beneficiarnos de la eficiencia.
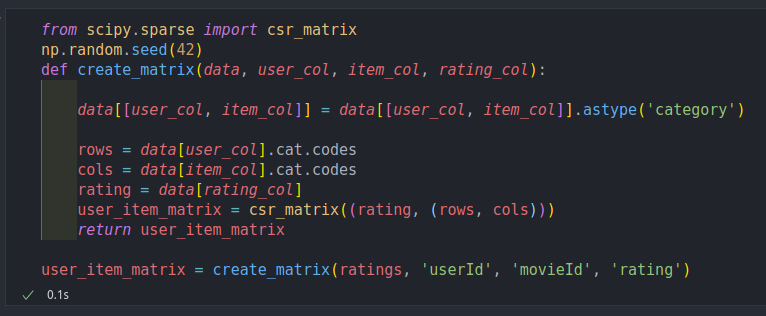
from scipy.sparse import csr_matrix
np.random.seed(42)
def create_matrix(data, user_col, item_col, rating_col):
data[[user_col, item_col]] = data[[user_col, item_col]].astype('category')
rows = data[user_col].cat.codes
cols = data[item_col].cat.codes
rating = data[rating_col]
user_item_matrix = csr_matrix((rating, (rows, cols)))
return user_item_matrix
user_item_matrix = create_matrix(ratings, 'userId', 'movieId', 'rating')
Encontré una implementación que básicamente toma los índices de usuarios y películas y en la cordenada (userId, movieId) rellena el 1 o cero si es que dicho usuario vio o no la película. Crear esto toma exactamente nada:
Antes eso sí de generar las clases negativas decidí generar el split de la data. Esto con el fin de poder evaluar el comportamiento del modelo:
La verdad es que en mi proceso real hice el split antes, pero luego me di cuenta que era mejor crear la user-item matrix primero. Esto porque si creaba este procedimiento después tendría que crear dos user-item matrix, una para el train_set y otra para el test_set. El gran problema de esto, es que los índices en test son películas que no están en train, por lo que iba a tener problemas para identificar el id correcto ya que el test_set iba a tener dimensiones distintas y el id 0 de test no iba a corresponder a la película con id cero, si no a la primera película del test_set que podría ser una película arbitraria. Esto me forzaría a hacer otro mapeo, el cual no quise hacer. Todo ese problema me lo evité haciendo el split después.
Train-Test Split
Para poder generar el split sin generar leakage se recomendaba utilizar el siguiente procedimiento:
ratings['test'] = ratings.groupby(['userId'])['timestamp'].rank(method='first', ascending=False)
train_ratings = ratings.query('test != 1').drop(columns = ['test', 'timestamp'])
test_ratings = ratings.query('test == 1').drop(columns = ['test', 'timestamp'])
Básicamente estamos aprendiendo de todas las películas excepto la última que cada usuario vió. La última película estará en el test_set, por lo que esperamos que nuestro recomendador efectivamente pueda recomendar la última película que vió.
Generación de Películas no vistas
Ahora generé otra implementación utilizando la user-item matrix. Debido a la fea sintáxis de numpy, el resultado dejaba muchas funciones anidadas, por lo que decidí escribirlo estilo Pytorch:
def create_negative_df(user_ids, user_item, neg_examples = 4, test = False):
movies_id = np.arange(user_item.shape[1])
negative_movies = []
examples = []
for i in range(len(user_ids)):
interacted = user_item[i].nonzero()[1]
x = ~np.isin(movies_id, interacted)
x = np.argwhere(x).squeeze(1)
if test:
size = neg_examples
else:
size = len(interacted)*neg_examples
x = np.random.choice(x, size = size)
negative_movies.extend(x)
examples.append(size)
negative_movies_df = pd.DataFrame(dict(userId = np.repeat(user_ids, examples),
movieId = negative_movies,
rating = np.zeros(len(negative_movies)))
)
return negative_movies_df
Esta función:
- Toma los ids de películas y para cada id de usuario detecta las películas con que interactuó.
- Genera un mask de películas no vistas, es decir, donde la user-item matrix no es uno.
- Calcula qué indices son las películas no vistas.
- Saca una muestra de toda las películas no vistas igual a
neg_examplesen el caso de test y deneg_examplespor el número de películas vistas en otro caso. - Finalmente combina todo eso en un DataFrame (con una lógica bien enredada que no sé muy bien como explicar así que pueden deducirlo del código).
Esta función la implementé solito (sin StackOverflow).
Esta función entonces sacará 4 ejemplos no vistos por cada película vista por un usuario en train. En el caso de test es un poco distinto, dado que cada usuario tiene sólo una película vista, sacaremos 99 casos no vistos (aleatorios). Luego la predicción del modelo será las 10 recomendaciones de los 100 casos, donde una de ellas ha sido vista por el usuario. Esperamos que en las 10 recomendaciones se encuentre la película que efectivamente vio.
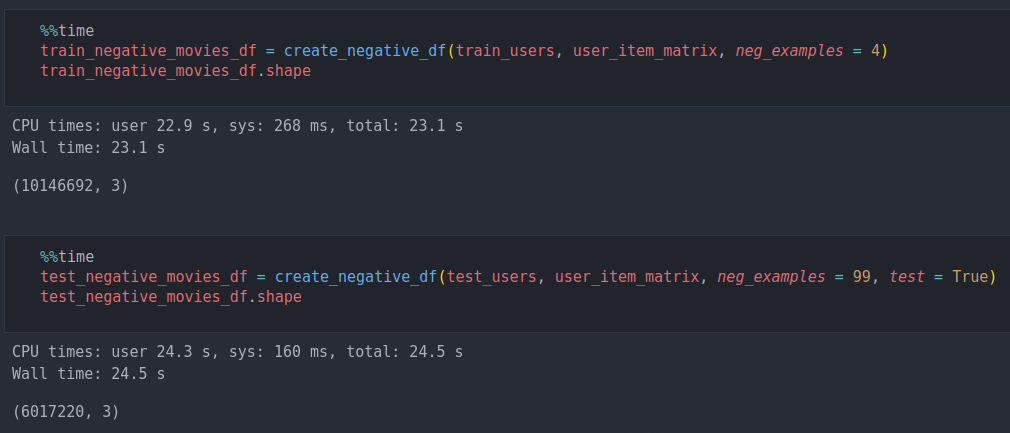
Como pueden ver esta implementación es muy rápida y eficiente y los resultados son 10 millones de registros para el train y 6 para el test.
Finalmente se combinan los casos vistos y no vistos obteniendo 12 millones para el train set y 6 millones para el test set.
full_training_df = train_ratings.append(train_negative_movies_df)
full_test_df = test_ratings.append(test_negative_movies_df)
full_training_df.shape, full_test_df.shape
((12797849, 3), (6078000, 3))
Neural Collaborative Filtering
Como siempre el modelo lo crearemos utilizando Pytorch Lightning. Justo actualicé Pytorch Lightning a la versión 1.6.1 el cuál trajo varios cambios en la API por lo que aprovecharé de mencionar dichos cambios:
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint
pl.seed_everything(42, workers=True)
Global seed set to 42
Primero que todo fijamos la semilla para la reproducibilidad. Además, encontré que utilizando workers=True se garantiza la reproducibilidad en los DataLoaders, que a veces no eran tan fáciles de reproducir debido a la carga de la data en GPU.
from torch.utils.data import Dataset, DataLoader
class MovieData(Dataset):
def __init__(self, users, movies, ratings):
self.users = users
self.movies = movies
self.ratings = ratings
def __len__(self):
return len(self.ratings)
def __getitem__(self, idx):
users = self.users.iloc[idx]
movies = self.movies.iloc[idx]
ratings = self.ratings.iloc[idx]
return dict(
users = torch.tensor(users, dtype=torch.long),
movies = torch.tensor(movies, dtype=torch.long),
ratings = torch.tensor(ratings, dtype=torch.float)
)
Creamos nuestro Pytorch Dataset, que básicamente tomará los usuarios, películas y ratings y los transformará en tensores.
class MovieDataModule(pl.LightningDataModule):
def __init__(self, train_df, test_df, batch_size = 512):
super().__init__()
self.train_df = train_df
self.test_df = test_df
self.batch_size = batch_size
def setup(self, stage=None):
self.train_data = MovieData(self.train_df.userId, self.train_df.movieId, self.train_df.rating)
self.test_data = MovieData(self.test_df.userId, self.test_df.movieId, self.test_df.rating)
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size, shuffle=True, pin_memory=True, num_workers = 10)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size=self.batch_size, shuffle=False, pin_memory=True, num_workers = 10)
En este caso el LightningDataModule tomará los set de train y test los transformará en tensores y los cargará en GPU con los DataLoader. Si se fijan el batch_size lo dejé en 512 porque es mucha data y batch size pequeños demoraban demasiado. El tema de usar batch_size alto es que hizo explotar mis DataLoaders muchas veces, y la razón de eso es porque tenía mi num_workers en 12 (que son todos mis core en mi laptop). Luego de mucho batallar, encontré que era mejor decisión bajar esto y dejar algunos libres. Hay que recordar que la función del DataLoader es cargar la data al modelo y en este caso hacer el traspaso a la GPU, pero este proceso se realiza en CPU, por lo que es bueno dejar unos cores para que el compu pueda sobrevivir el proceso de entrenamiento.
class NCF(nn.Module):
def __init__(self, dim_users, dim_movies, n_out = 1):
super().__init__()
self.user_embedding = nn.Embedding(dim_users, 8)
self.movie_embedding = nn.Embedding(dim_movies, 8)
self.encoder = nn.Sequential(
nn.Linear(16,64),
nn.ReLU(inplace=True),
nn.Linear(64,32),
nn.ReLU(inplace=True),
nn.Linear(32,n_out)
)
def forward(self, users, movies):
user_emb = self.user_embedding(users)
movie_emb = self.movie_embedding(movies)
x = torch.cat((user_emb, movie_emb), dim = 1)
x = self.encoder(x)
return x
El modelo de Neural Collaborative Filtering es una red neuronal que toma como entrada los usuarios y películas y devuelve un rating. En este caso el modelo es una red neuronal que parte con un embedding tanto para users como movies de 8 dimensiones, que se concatenan para entrar en un encoder compuesto por una capa de 64 dimensiones, una capa de 32 dimensiones y una capa de 1 dimension (el rating). (Pueden creer que el parrafo anterior lo escribió Github Copilot, es espectacular). Como es un modelo de clasificación, este debería terminar con una sigmoide, pero se recomienda no hacerlo y utilizar una Loss Function de BCEWithLogitsLoss, que es una Binary CrossEntropy más la sigmoide que provee mejor estabilidad numérica.
class RecSys(pl.LightningModule):
def __init__(self, model):
super().__init__()
self.model = model
self.criterion = nn.BCEWithLogitsLoss()
def forward(self,users, movies):
x = self.model(users, movies)
return x
def training_step(self, batch, batch_idx):
users, movies, ratings = batch['users'], batch['movies'], batch['ratings']
preds = self(users, movies)
# print('preds:', preds.shape)
# print('ratings: ', ratings.shape)
loss = self.criterion(preds, ratings.view(-1,1))
self.log('train_loss', loss, prog_bar = True, logger = True)
return {'loss': loss}
def configure_optimizers(self):
return torch.optim.Adam(self.model.parameters(), lr = 1e-3)
El LightningModule no tiene nada especial. Sólo mencionar que en este caso nuestra red neuronal recibe de cada batch los usuarios por un lado y las películas por otro. Esto es importante porque usuarios y películas tienen embeddings diferentes por lo que deben entrar al modelo por separado ya que los embeddings del modelo no van en serie sino en paralelo.
Finalmente para el entrenamiento instanciamos el modelo:
model = NCF(dim_users, dim_movies)
dm = MovieDataModule(full_training_df, full_test_df, batch_size=512)
recommender = RecSys(model)
Definimos el Callback:
mc = ModelCheckpoint(
dirpath = 'checkpoints',
#filename = 'best-checkpoint',
save_last = True,
save_top_k = 1,
verbose = True,
monitor = 'train_loss',
mode = 'min'
)
mc.CHECKPOINT_NAME_LAST = 'best-checkpoint-latest'
Un detalle acá es que aprendí que cambiando la variable CHECKPOINT_NAME_LAST se puede tener el mejor checkpoint con un nombre fijo. De esta manera podemos automatizar el rescate del mejor estado del modelo ya que siempre tendrá el mismo nombre y no un -v1, -v2, -v3, etc.
Definimos el Trainer:
trainer = pl.Trainer(max_epochs=5,
accelerator="gpu",
devices=1,
callbacks=[mc],
progress_bar_refresh_rate=30,
# fast_dev_run=True,
#overfit_batches=1
)
trainer.fit(recommender, dm)
Acá es importante destacar que hay cambios, ahora para ejecutar en gpu no utilizamos gpus=1 sino que definimos el accelerator que puede ser gpu, tpu, ipu, etc. Y definimos el devices que es el número de GPUs que queremos utilizar. Pueden ver comentado dos comandos que uso para debuggear que la red funcione correctamente antes de dejarla harto rato corriendo:
fast_dev_run=Trueejecuta una epoch de prueba para chequear por ejemplo que las dimensiones de los tensores funcionen bien.overfit_batches=1sobreajusta una batch por cada epoch. Si el overfit funciona es que el modelo efectivamente tiene la posibilidad de aprender. Con esto se puede chequear que el modelo no diverge.
Normalmente ejecuto esto antes de dejar la red corriendo y luego de una larga epoch de entrenamiento darme cuenta que falló.
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
------------------------------------------------
0 | model | NCF | 653 K
1 | criterion | BCEWithLogitsLoss | 0
------------------------------------------------
653 K Trainable params
0 Non-trainable params
653 K Total params
2.612 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
Epoch 0, global step 24996: 'train_loss' reached 0.08028 (best 0.08028), saving model to '/home/alfonso/Documents/kaggle/recom/checkpoints/epoch=0-step=24996.ckpt' as top 1
Epoch 1, global step 49992: 'train_loss' was not in top 1
Epoch 2, global step 74988: 'train_loss' reached 0.07823 (best 0.07823), saving model to '/home/alfonso/Documents/kaggle/recom/checkpoints/epoch=2-step=74988.ckpt' as top 1
Epoch 3, global step 99984: 'train_loss' reached 0.06737 (best 0.06737), saving model to '/home/alfonso/Documents/kaggle/recom/checkpoints/epoch=3-step=99984.ckpt' as top 1
Epoch 4, global step 124980: 'train_loss' reached 0.06487 (best 0.06487), saving model to '/home/alfonso/Documents/kaggle/recom/checkpoints/epoch=4-step=124980.ckpt' as top 1
Evaluación del Modelo
Otro cambio, esta vez en Pytorch 1.11, es la introducción de un decorador de inferencia. Hacer esto es equivalente al with torch.no_grad(). Básicamente vaciaremos nuestro dataloader al modelo, aplicaremos la sigmoide que no colocamos en nuestro modelo e increiblemente descargando las predicciones a la CPU funcionó más rápido que la GPU (esto porque evita el overhead de subir los datos a la GPU para poder predecir).
@torch.inference_mode()
def predict(model, dm):
model.eval()
preds = []
for item in dm.test_dataloader():
pred = torch.sigmoid(model(item['users'], item['movies']))
preds.extend(pred.cpu().detach().numpy())
return preds
Luego convertimos todo en un Numpy Array para poder incluirlo en nuestro full_test_df.
predictions= np.array(predict(recommender, dm))
print(predictions.shape)
full_test_df['preds'] = predictions
full_test_df
(6078000, 1)
| userId | movieId | rating | preds | |
|---|---|---|---|---|
| 734 | 0 | 230 | 1.0 | 0.987030 |
| 1066 | 1 | 929 | 1.0 | 0.749257 |
| 2855 | 2 | 465 | 1.0 | 0.911151 |
| 2889 | 3 | 2505 | 1.0 | 0.973490 |
| 3015 | 4 | 9907 | 1.0 | 0.959640 |
| ... | ... | ... | ... | ... |
| 6017215 | 60779 | 2442 | 0.0 | 0.006992 |
| 6017216 | 60779 | 10800 | 0.0 | 0.003167 |
| 6017217 | 60779 | 17767 | 0.0 | 0.000137 |
| 6017218 | 60779 | 7073 | 0.0 | 0.000070 |
| 6017219 | 60779 | 2124 | 0.0 | 0.000730 |
6078000 rows × 4 columns
Para evaluar el modelo utilizaremos la métrica HitRatio@10. Esto quiere decir que si dentro de las 10 mejores predicciones por usuario, el usuario tiene la película vista entonces eso es un éxito.
recomendations = full_test_df.sort_values(by = ['userId','preds'], ascending=[True, False]).groupby('userId').head(10)
En uno de los artículos que ví como referencia encontré la siguiente implementación:
# User-item pairs for testing
test_user_item_set = set(zip(test_ratings['userId'], test_ratings['movieId']))
# Dict of all items that are interacted with by each user
user_interacted_items = ratings.groupby('userId')['movieId'].apply(list).to_dict()
hits = []
for (u,i) in test_user_item_set:
interacted_items = user_interacted_items[u]
not_interacted_items = set(all_movieIds) - set(interacted_items)
selected_not_interacted = list(np.random.choice(list(not_interacted_items), 99))
test_items = selected_not_interacted + [i]
predicted_labels = np.squeeze(model(torch.tensor([u]*100),
torch.tensor(test_items)).detach().numpy())
top10_items = [test_items[i] for i in np.argsort(predicted_labels)[::-1][0:10].tolist()]
if i in top10_items:
hits.append(1)
else:
hits.append(0)
print("The Hit Ratio @ 10 is {:.2f}".format(np.average(hits)))
Sólo al verla me dio dolor de estomago, porque no la entiendo. Una manera mucho más sencilla es esta:
Sabemos que sólo hay un 1 en cada usuario, por lo tanto recomendations.rating.sum() nos dirá cuantas películas efectivamente vistas por nuestro usuario están en las 10 mejores recomendaciones. Si eso lo dividimos por el número de usuarios entonces tenemos el HitRatio@10
recomendations.rating.sum()/recomendations.userId.nunique()
0.9457880881869036
¿Cómo Utilizamos el Modelo?
Bueno para poder operacionalizar el modelo entonces tenemos que llevar a nuestros Ids originales:
def back_to_normal(df, user_encoder, movie_encoder, movies_mapping):
idx_movies = df.movieId.tolist()
idx_users = df.userId.tolist()
return pd.DataFrame(dict(userId = user_encoder.classes_[idx_users],
movieId = pd.Series(movie_encoder.classes_[idx_movies]).map(movies_mapping),
rating = df.rating.tolist()))
vistos= back_to_normal(train_ratings, user_encoder, movie_encoder, movies_mapping)
visto.shape
(2651157, 3)
recomendar = back_to_normal(recomendations, user_encoder, movie_encoder, movies_mapping)
recomendar.shape
(607800, 3)
visto corresponderá a las películas ya vistas por nuestro usuario, y recomendar a las 10 mejores recomendaciones. Ojo que agregamos el movies_mapping del principio para poder tener el nombre de la película y no sólo el Id.
Revisemos entonces algunas recomendaciones:
Al revisar los resultados me dí cuenta que sé muy poco de películas (a excepción de las películas de Marvel) pido perdón de antemano si mi análisis es un poco pobre, pero no soy muy cinéfilo XD.
Por ejemplo, el usuario 4 parece que le gustan las películas de acción y ciencia ficción. Correctamente predijimos John Carter, que es la película que vio y además dado que ha visto varias películas del MCU se le recomienda ver Thor 2 (que es muy mala película, pero bueno, nada que hacer).
user = 4
print(visto.query('userId == @user')['movieId'])
recomendar.query('userId == @user')
193 Shutter Island (2010)
194 Percy Jackson & the Olympians: The Lightning T...
195 How to Train Your Dragon (2010)
196 Clash of the Titans (2010)
197 Iron Man 2 (2010)
...
303 Spider-Man: Into the Spider-Verse (2018)
304 John Wick: Chapter 3 – Parabellum (2019)
305 Pokémon: Detective Pikachu (2019)
306 Ford v. Ferrari (2019)
307 Fast & Furious Presents: Hobbs & Shaw (2019)
Name: movieId, Length: 115, dtype: object
| userId | movieId | rating | |
|---|---|---|---|
| 10 | 4 | Thor: The Dark World (2013) | 0.0 |
| 11 | 4 | Margin Call (2011) | 0.0 |
| 12 | 4 | Kubo and the Two Strings (2016) | 0.0 |
| 13 | 4 | John Carter (2012) | 1.0 |
| 14 | 4 | Autómata (Automata) (2014) | 0.0 |
| 15 | 4 | You Were Never Really Here (2017) | 0.0 |
| 16 | 4 | Aloha (2015) | 0.0 |
| 17 | 4 | Thanks for Sharing (2012) | 0.0 |
| 18 | 4 | Eva (2011) | 0.0 |
| 19 | 4 | Magic Mike XXL (2015) | 0.0 |
El usuario 6225 parece que le gustan las películas de Romance, Miedo y Suspenso, y se recomienda correctamente Midnight in Paris que no tengo idea de qué trata pero podemos ver otras recomendaciones como Saw (Miedo), Friends with Benefits o Aladdin que serán medio Romance/Fantasía supongo.
user = 6265
print(visto.query('userId == @user')['movieId'])
recomendar.query('userId == @user')
100326 Cabin in the Woods, The (2012)
100327 Snowpiercer (2013)
100328 Gone Girl (2014)
100329 The Imitation Game (2014)
Name: movieId, dtype: object
| userId | movieId | rating | |
|---|---|---|---|
| 22630 | 6265 | Midnight in Paris (2011) | 1.0 |
| 22631 | 6265 | Friends with Benefits (2011) | 0.0 |
| 22632 | 6265 | Saw VII 3D - The Final Chapter (2010) | 0.0 |
| 22633 | 6265 | Searching (2018) | 0.0 |
| 22634 | 6265 | Aladdin (2019) | 0.0 |
| 22635 | 6265 | The Dark Tower (2017) | 0.0 |
| 22636 | 6265 | The BFG (2016) | 0.0 |
| 22637 | 6265 | ARQ (2016) | 0.0 |
| 22638 | 6265 | A Wrinkle in Time (2018) | 0.0 |
| 22639 | 6265 | Magic of Belle Isle, The (2012) | 0.0 |
El usuario 63 es como mi esposa, le gustan las películas livianitas, de monitos o para reirse, Tangled, Inside Out o Pitch Perfect sólo pueden recomendar algo como The Twilight Saga: Eclipse.
user = 63
print(visto.query('userId == @user')['movieId'])
recomendar.query('userId == @user')
623 Easy A (2010)
624 Tangled (2010)
625 Bridesmaids (2011)
626 Horrible Bosses (2011)
627 Crazy, Stupid, Love. (2011)
628 21 Jump Street (2012)
629 Pitch Perfect (2012)
630 Perks of Being a Wallflower, The (2012)
631 Great Gatsby, The (2013)
632 Now You See Me (2013)
633 We're the Millers (2013)
634 About Time (2013)
635 Wolf of Wall Street, The (2013)
636 Gone Girl (2014)
637 Inside Out (2015)
638 Room (2015)
639 Moana (2016)
640 Coco (2017)
Name: movieId, dtype: object
| userId | movieId | rating | |
|---|---|---|---|
| 200 | 63 | Spotlight (2015) | 0.0 |
| 201 | 63 | Twilight Saga: Eclipse, The (2010) | 1.0 |
| 202 | 63 | Sorcerer's Apprentice, The (2010) | 0.0 |
| 203 | 63 | Melancholia (2011) | 0.0 |
| 204 | 63 | Oz the Great and Powerful (2013) | 0.0 |
| 205 | 63 | Venom (2018) | 0.0 |
| 206 | 63 | Selma (2014) | 0.0 |
| 207 | 63 | Burlesque (2010) | 0.0 |
| 208 | 63 | Silent Hill: Revelation 3D (2012) | 0.0 |
| 209 | 63 | Double, The (2011) | 0.0 |
El usuario 162532 es de los míos, harta película de Acción, del MCU y como de Niños (Despicable Me) y se recomienda Guardians of the Galaxy (muy buena película) y Spy Kids que es de Acción e Infantil que también es rebuena.
user = 162532
print(visto.query('userId == @user')['movieId'])
recomendar.query('userId == @user')
2650878 How to Train Your Dragon (2010)
2650879 Kick-Ass (2010)
2650880 Exit Through the Gift Shop (2010)
2650881 Iron Man 2 (2010)
2650882 Despicable Me (2010)
2650883 Inception (2010)
2650884 Scott Pilgrim vs. the World (2010)
2650885 Social Network, The (2010)
2650886 Easy A (2010)
2650887 Harry Potter and the Deathly Hallows: Part 1 (...
2650888 King's Speech, The (2010)
2650889 Source Code (2011)
2650890 Thor (2011)
2650891 X-Men: First Class (2011)
2650892 Harry Potter and the Deathly Hallows: Part 2 (...
2650893 Captain America: The First Avenger (2011)
2650894 Avengers, The (2012)
2650895 Hugo (2011)
2650896 The Hunger Games (2012)
2650897 Dark Knight Rises, The (2012)
2650898 Sherlock Holmes: A Game of Shadows (2011)
2650899 Intouchables (2011)
2650900 Looper (2012)
2650901 Argo (2012)
2650902 Silver Linings Playbook (2012)
2650903 Hobbit: An Unexpected Journey, The (2012)
2650904 Iron Man 3 (2013)
Name: movieId, dtype: object
| userId | movieId | rating | |
|---|---|---|---|
| 607750 | 162532 | Guardians of the Galaxy (2014) | 1.0 |
| 607751 | 162532 | Only the Brave (2017) | 0.0 |
| 607752 | 162532 | Immigrant, The (2013) | 0.0 |
| 607753 | 162532 | Diary of a Wimpy Kid: Rodrick Rules (2011) | 0.0 |
| 607754 | 162532 | Spy Kids: All the Time in the World in 4D (2011) | 0.0 |
| 607755 | 162532 | The Belko Experiment (2017) | 0.0 |
| 607756 | 162532 | All the Way (2016) | 0.0 |
| 607757 | 162532 | Come Together (2016) | 0.0 |
| 607758 | 162532 | Batman: Gotham by Gaslight (2018) | 0.0 |
| 607759 | 162532 | Kizumonogatari Part 1: Tekketsu (2016) | 0.0 |
Conclusiones
Creo que el Modelo funciona sumamente bien. Cabe destacar que estamos haciendo el trabajo bien dificil porque en estricto rigor nosotros deberíamos predecir el Rating de todas las películas del catálogo y entregar las 10 mejores, y estamos haciendo un random de 99 películas que puede que no tengan nada que ver con el usuario y aún así el modelo es capaz de ordenar las predicciones de buena manera.
Es interesante que gran parte del modelo de Recomendación tiene que ver con el manejo de la data y cómo vamos a operacionalizarlo. No es llegar y hacer un predict sino que es necesario pensar en una estrategia para poder mostrar esto.
Una de las ventajas de este tipo de modelo es que podemos tener todas las predicciones hechas por ejemplo en la noche y luego operacionalizarlas en nuestro front-end. Esto es beneficioso también en el sentido que una inferencia en tiempo real para semejante cantidad de datos es difícil.
Una desventaja de este tipo de modelos es que sólo pueden entregar recomendaciones a los usuarios que ya han visto películas y que ya se encuentran en la user-item matrix. Esto es lo que se conoce como el cold-start problem. No sé muy bien como se soluciona pero en la forma en la que se planteó esta solución no es posible decir me gusta A, B, C, entonces, ¿qué me recomiendas? Deben existir otro tipo de modelos que sí pueden lidiar con esto, pero que no manejo.
Eso es todo por esta semana, espero les haya gustado y gracias Gustavo, aprendí harto de Sistemas Recomendadores (aunque me sacó canas verdes) durante este fin de semana.
Hasta la otra,