Obtener datos de los Códigos de Error de un Vehículo
Scrapping DTCs

No tenía idea que esa luz de Check Engine tiene muchos códigos asociados que indican a que se debe el error de tu vehículo. Al parecer existen muchas razones por las que un auto podría fallar y encender esa molesta luz que te hace pensar que tu auto va a fallar.
Buscando por la web me apareció este tremendo sitio llamado CodigosDTC.com el cual tiene una lista gigante de DTCs. DTC significa Diagnostic Trouble Codes, o Códigos de diagnostico de Problemas, y se utilizan para determinar los problemas que puede tener el vehículo mediante su computador interno. La página entrega esta información de la siguiente forma:

Investigando un poco más la página me dí cuenta que está muy bien organizada y podría ser una buena idea para poner en práctica un poco de Scrapping. El Scrapping es un método, un poco a fuerza Bruta, para descargar el contenido de un sitio web. Para ello, Python cuenta con una tremenda librería llamada BeautifulSoup4 que combinada con requests permite descargar la data del sitio web.
No pretendo hacer un tutorial intensivo de cómo utilizar BeautifoulSoup porque encontré que la documentación es bastante buena y la librería es bastante intuitiva. Por lo que explicaré cómo llegué a la implementación que estoy usando actualmente de manera rápida:
El problema
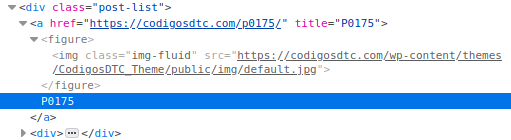
Al inspeccionar el sitio, pude notar que los nombre de los DTCs y su descripción viven en una clase CSS llamada post-list
. Además existe un tag <a> que tiene en su interior el nombre del DTC, un <div> que tiene una descripción corta y además un atributo href dentro del mismo tag <a> que tiene un link a información aún más detallada de cada DTC.
Por lo tanto, la implementación en BeautifulSoup tiene que realizar un llamado mediante requests a la URL de la página a scrapear. Esto permite que el HTML de la página se descargue en forma de Texto Plano:
import requests
url = 'https://codigosdtc.com/listado-de-codigos-dtc-obdii/page/142/'
page_pag = requests.get(url)
print(page_pag.text)
Ejecutar este código genera un HTML muy grande, el cual no mostraré acá, pero les dejo un pantallazo:
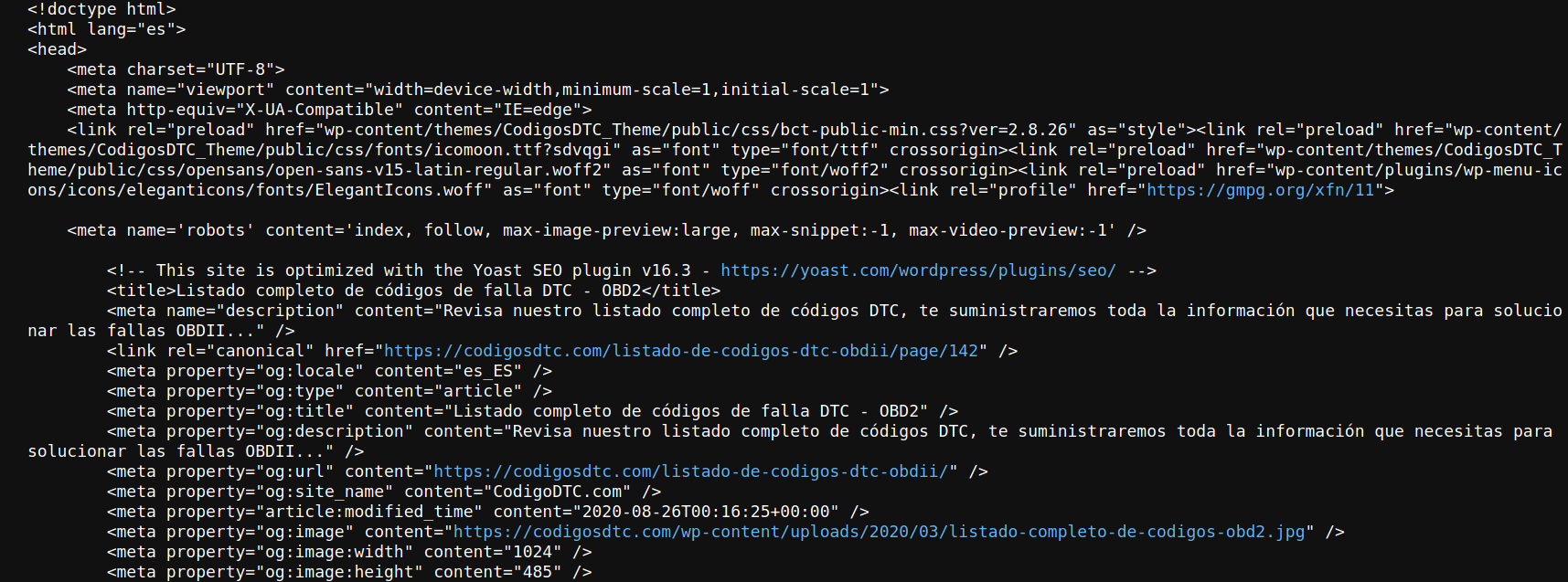
Este HTML es el mismo que genera el sitio web, pero en formato de texto plano. Por lo tanto, es posible explorarlo mediante BeautifulSoup. Lo primero que hay que hacer para esta exploración es instanciar un objeto BeautifulSoup utilizando el texto descargado con requests.
from bs4 import BeautifulSoup
soup_page = BeautifulSoup(page_pag.text, 'html.parser')
Una vez hecho esto, es posible acceder a este objeto mediante métodos muy convenientes. Por ejemplo .find_all() permite buscar todas las instancias de, por ejemplo, una clase. Dado que me pude percatar de que los DTC viven en objetos de clase 'post-list' es posible extraer todos los tags con dicha clase de la siguiente manera:
Muchos de los resultados que voy a estar mostrando son muy grandes e incluyendo tags de HTML. Dado que mi siito también funciona mediante HTML voy a entregar todos los outputs en forma de pantallazo para evitar cualquier tipo de problema con el renderizado del sitio.
soup_page.find_all(class_='post-list')[0]
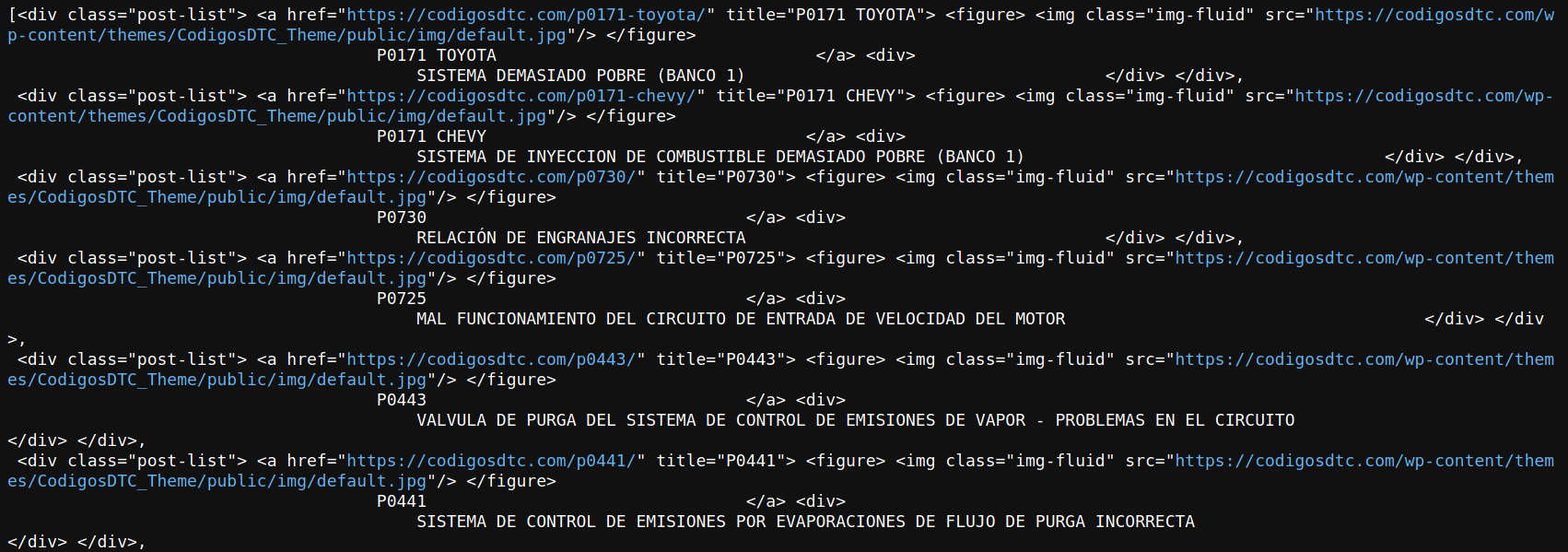
Observando los objetos extraídos y como mencioné anteriormente, me interesa rescatar el texto que se encuentra al interior de los Tags <a> y <div> además del atributo href. Para ello, BeautifulSoup tiene el método .find() para buscar al interior de algún tag en específico, el método .get_text() para extraer texto de su interior y el método .get() para rescatar info de algún atributo. Todo muy handy!! Para extraer todo lo que necesito puedo combinarlo con un List Comprehension y transformarlo en un DataFrame como sigue:
df = pd.DataFrame([[elemento.find('a').get_text().strip(),
elemento.find('div').get_text().strip(),
elemento.find('a').get('href')]
for elemento in soup.find_all(class_='post-list')],
columns = ['DTC', 'Short Description', 'URL'])
Adicionalmente estoy utilizando .strip() para eliminar espacios en blanco que el texto tiene antes y después para una mejor legibilidad. Como se puede ver el DataFrame resultante es muy ordenadito:
| DTC | Short Description | URL | |
|---|---|---|---|
| 0 | P0171 TOYOTA | SISTEMA DEMASIADO POBRE (BANCO 1) | https://codigosdtc.com/p0171-toyota/ |
| 1 | P0171 CHEVY | SISTEMA DE INYECCION DE COMBUSTIBLE DEMASIADO ... | https://codigosdtc.com/p0171-chevy/ |
| 2 | P0730 | RELACIÓN DE ENGRANAJES INCORRECTA | https://codigosdtc.com/p0730/ |
| 3 | P0725 | MAL FUNCIONAMIENTO DEL CIRCUITO DE ENTRADA DE ... | https://codigosdtc.com/p0725/ |
| 4 | P0443 | VALVULA DE PURGA DEL SISTEMA DE CONTROL DE EMI... | https://codigosdtc.com/p0443/ |
| 5 | P0441 | SISTEMA DE CONTROL DE EMISIONES POR EVAPORACIO... | https://codigosdtc.com/p0441/ |
| 6 | P0327 | CIRCUITO DE ENTRADA BAJA EN EL SENSOR KNOCK | https://codigosdtc.com/p0327/ |
| 7 | P0174 | SISTEMA DEMASIADO POBRE (BANCO 2) | https://codigosdtc.com/p0174/ |
| 8 | P0141 | MAL FUNCIONAMIENTO DEL CIRCUITO CALENTADOR DEL... | https://codigosdtc.com/p0141/ |
| 9 | P0136 | SENSOR DE O2 MAL FUNCIONAMIENTO DEL CIRCUITO (... | https://codigosdtc.com/p0136/ |
| 10 | P0106 | RENDIMIENTO INCORRECTO SENSOR DE PRESIÓN BAROM... | https://codigosdtc.com/p0106/ |
| 11 | P0305 | CILINDRO 5 DETECTADO FALLO DE ENCENDIDO | https://codigosdtc.com/p0305/ |
| 12 | P0105 | MAL FUNCIONAMIENTO DEL CIRCUITO MAP | https://codigosdtc.com/p0105/ |
| 13 | P0338 | “A” DE BUJÍAS INCANDESCENTES/ MAL FUNCIONAMIEN... | https://codigosdtc.com/p0338/ |
| 14 | P0171 FORD | SISTEMA DE INYECCIÓN DE COMBUSTIBLE DEMASIADO ... | https://codigosdtc.com/p0171-ford/ |
| 15 | P0340 NISSAN | SENSOR DE POSICIÓN DE ÁRBOL DE LEVAS (BANCO 1 ... | https://codigosdtc.com/p0340-nissan/ |
| 16 | P0010 | ACTUADOR POSICION ARBOL DE LEVAS (BANCO 1) – C... | https://codigosdtc.com/p0010/ |
| 17 | P0562 | BAJO VOLTAJE DEL SISTEMA | https://codigosdtc.com/p0562/ |
Eso es todo!! Beautiful Soup es tremendamente poderoso, me permitió de manera muy sencilla acceder a distintas partes del sitio web para poder extraer los datos que me interesaban. Gracias a la documentación y a muchos tutoriales que hay por ahí armé mi implementación en cerca de una hora. Se puede pensar que es mucho tiempo, pero lo que más me demoró no fue el código sino que entender como estaba estructurado el sitio web.
Ahora, mi implementación contempla no sólo extraer información básica del sitio. Si se fijan cada DTC tiene asociado un URL al clickear en cada nombre del mismo. Esta URL corresponde a una página con muchos detalles, entre ellos:
- Una Descripción Larga.
- Síntomas para detectar el DTC.
- Causas del Código DTC.
- Posibles Soluciones
Por lo tanto, la implementación final contempla el recorrer todas las páginas de DTC y todos los sitios de detalle del DTC. Al momento de la implementación, había una lista de más de 2500 DTC, por lo que correr está implementación toma tiempo y, en caso de querer probarla,sugiero aplicarla sólo a un pedazito Under your own Risk (No porque sea riesgoso, sino que porque toma tiempo).
def create_info(df_url):
page_pag = requests.get(df_url)
soup_page = BeautifulSoup(page_pag.text, 'html.parser')
titulos = ['Long Description','Symptom','Cause','Solution' ]
return {titulo: elemento.get_text().strip() for titulo, elemento in
zip(titulos, soup_page.find_all(class_='mt-3 text-content'))}
def get_DTC(url):
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
df = pd.DataFrame([[elemento.find('a').get_text().strip(),
elemento.find('div').get_text().strip(),
elemento.find('a').get('href')]
for elemento in soup.find_all(class_='post-list')], columns = ['DTC', 'Short Description', 'URL'])
info = pd.DataFrame([create_info(url) for url in df.URL])
return pd.concat([df, info], axis = 1)
Esta función es una composición entre el Scrapping de la página general y de la página de detalles. Además esta funcion contempla la concatenación de los resultados, ya que se irán extrayendo uno a uno.
A continuación se muestra el funcionamiento de la implementación para las primeras 4 páginas. El resultado se obtiene en alrededor de 1 minuto:
lista_vacia = []
for page in range(1,4):
url = f'https://codigosdtc.com/listado-de-codigos-dtc-obdii/page/{page}'
lista_vacia.append(get_DTC(url))
df = pd.concat(lista_vacia)
| DTC | Short Description | URL | Long Description | Symptom | Cause | Solution | |
|---|---|---|---|---|---|---|---|
| 0 | C1776 | Código de falla OBD2 | https://codigosdtc.com/c1776/ | C1776 TOYOTA, LEXUS: CIRCUITO DEL SENSOR DE VE... | Los Sensores de Velocidad son dispositivos ele... | Iluminada la luz Check Engine.\nEncendida la l... | Los motivos por los cuales es almacenado el có... |
| 1 | C1959 | Código de falla OBD2 | https://codigosdtc.com/c1959/ | C1959 FORD, MERCURY, LINCOLN: FALLO DEL CIRCUI... | El acelerómetro básicamente es un dispositivo ... | Se enciende la lámpara Check Engine.\nIluminad... | El código de diagnóstico C1959 OBD2 es almacen... |
| 2 | C1266 | Código de falla OBD2 | https://codigosdtc.com/c1266/ | C1266 CADILLAC, BUICK, CHEVROLET, GMC: MAL FUN... | Las Válvulas Solenoides y el motor de la bomba... | Encendida la lámpara Check Engine.\nLuz ilumin... | Las razones por las cuales se almacena el códi... |
| 3 | C1417 | Código de falla OBD2 | https://codigosdtc.com/c1417/ | C1417 CHRYSLER, DODGE, JEEP: CIRCUITO DE CONTR... | Formando parte del conjunto del eje delantero ... | Se enciende la lámpara Check Engine.\nSe ilumi... | Los motivos por los que se establece el código... |
| 4 | C1441 | Código de falla OBD2 | https://codigosdtc.com/c1441/ | C1441 TOYOTA, SCION, LEXUS: DISMINUCIÓN DEL RE... | Los frenos de los vehículos son operados desde... | Se enciende la luz Check Engine.\nIluminada la... | Los factores por los que se configura el códig... |
Ese fue el mini tutorial de BeautifulSoup. Como se pueden dar cuenta, la API es muy intuitiva y, sabiendo lo básico de HTML, es posible hacer una implementación relativamente compleja como esta, en la cual estamos armando prácticamente un dataset con toda la información disponible de DTCs que hay en el sitio web.
Espero les haya gustado,