Árboles de Decisión en Scikit-Learn
Supervivientes en el Titanic

Mi película favorita de todos los tiempos es Avengers Infinity War + Endgame. Pero cuando chico, Titanic fue realmente una pelicula que me partió el alma. Porque es demasiado triste, y no termina con el final esperado. Siempre me cuestioné por qué James Cameron mató a Jack, ¿habrá sido una buena decisión? Porque estoy seguro que no dejó a todos contentos y más de alguno cuestionó o sigue cuestionando la decisión tomada por el Director.
“The answer is very simple because it says on page 147 [of the script] that Jack dies. Very simple. . . . Obviously it was an artistic choice, the thing was just big enough to hold her, and not big enough to hold him . . . I think it’s all kind of silly, really, that we’re having this discussion 20 years later. But it does show that the film was effective in making Jack so endearing to the audience that it hurts them to see him die. Had he lived, the ending of the film would have been meaningless. . . . The film is about death and separation; he had to die.” James Cameron
La idea es poder ver si a través de los Datos es posible determinar si se trató de una buena decisión o no.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('Titanic.csv', index_col = 0)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Signing_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1911-05-17 |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1911-07-23 |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1911-09-08 |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1911-06-26 |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1911-10-25 |
En caso de querer descargar el dataset del titanic, es posible descargarlo desde acá o si es que tienes la API de Kaggle, puedes descargarla por línea de comando asi:
$ kaggle competitions download -c titanic
¿De qué se trata el Dataset?
Para esta parte se empleará sólo inspección visual, iremos revisando algunas aspectos de la data que son importantes de revisar:
En este dataset no estan todos los pasajeros ya que es sólo una muestra.
print(df.shape) #chequear nulos... ya que no se tiene la información de toda la gente
df.info()
(891, 12)
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Name 891 non-null object
3 Sex 891 non-null object
4 Age 714 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Ticket 891 non-null object
8 Fare 891 non-null float64
9 Cabin 204 non-null object
10 Embarked 889 non-null object
11 Signing_date 891 non-null object
dtypes: float64(2), int64(4), object(6)
memory usage: 90.5+ KB
df.describe()
| Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
Precaución: Podemos notar que sólo los campos Age, Embarked y Cabin poseen nulos, por lo tanto hay que tener cuidado con estos datos ya que los árboles de decisiones de Scikit-Learn no son compatibles con datos perdidos.
La idea sería poder utilizando algunas técnicas de Exploración de Datos para poder algunas preguntas y entender qué ocurrió en el accidente del Titanic. Por si alguien no vió la película.
¿Cuánta Gente Sobrevivió?
df['Survived'] = np.where(df.Survived > 0, 'Sobrevive', 'No Sobrevive')
df.Survived.value_counts(normalize = True)
No Sobrevive 0.616162
Sobrevive 0.383838
Name: Survived, dtype: float64
¿Cuántos Hombres y Mujeres hay?
df.Sex.value_counts()
male 577
female 314
Name: Sex, dtype: int64
¿Y cuántos de ellos sobrevivieron?
df.groupby('Sex').Survived.value_counts(normalize = True)
Sex Survived
female Sobrevive 0.742038
No Sobrevive 0.257962
male No Sobrevive 0.811092
Sobrevive 0.188908
Name: Survived, dtype: float64
Tip: Muchas veces la verdad es que es mucho más atractivo y más fácil de leer el mostrar los resultados mediante visualizaciones más que por números en tablas. Si quieres transmitir el mensaje de manera más clara, mejor utilizar visualizaciones.
df.groupby(['Sex']).Survived.value_counts().plot(kind = 'bar') # no tan bonito
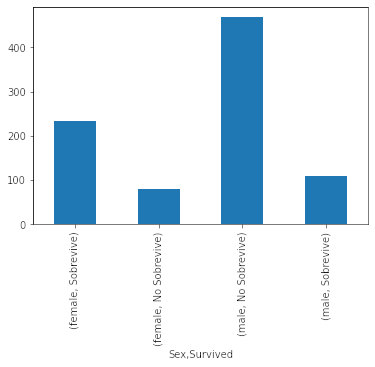
Si bien pandas incluye funcionalidades para visualizar muchas veces dejar el gráfico bonito no es tan fácil, por lo que en este caso cambiaremos a seaborn que permite crear gráficos bien bonitos de manera bien simple.
Usar seabron va ser sumamente sencillo, en caso de querer gráficar variables en la que al menos una de ellas es categórica, se utilizará sns.catplot()
sns.catplot(x = 'Sex', hue = 'Survived', data = df, kind = 'count')
plt.show()
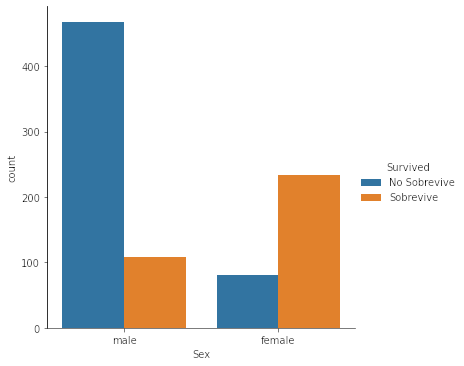
¿Cuánta Gente sobrevive por Clase?
sns.catplot(x = 'Sex', hue = 'Pclass', data = df, kind = 'count', col = 'Survived')
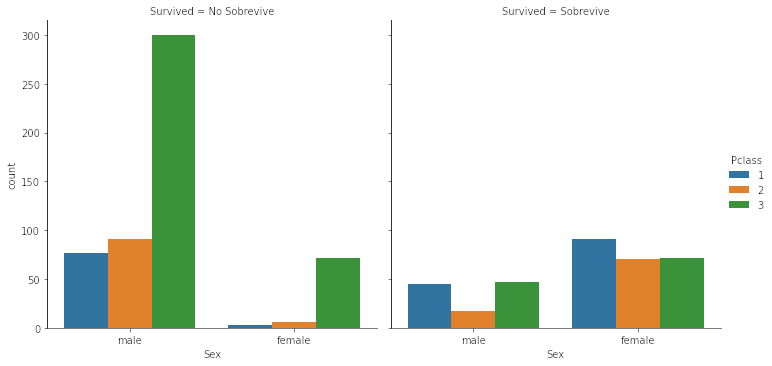
- Fabrizio y Jack eran de 3era clase
- Interesantemente los que más sobrevivieron fueron mujeres de 1era clase, y luego 2da y 3era casi de manera igualitaria. No tan condicente con lo que decía James Cameron.
- Los que menos sobrevivieron fueron hombres de 2da clase!!! No se muestran en la película.
¿Cuanto pagaba cada clase?
sns.catplot(x = 'Pclass', y = 'Fare', data = df, kind = 'bar', ci = None, estimator = np.mean) # promedio
plt.show()
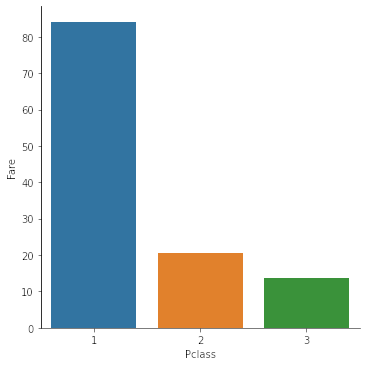
Fabrizio y Jack se ganaron los tickets jugando poker, mientras que Rose y el malo, los compraron.
En el caso que ambas variables sean de tipo numérica entonces se utilizará el comando sns.relplot()
sns.relplot(x = 'Age', y = 'Fare', data = df, style = 'Survived',
style_order = ['Sobrevive','No Sobrevive'], hue = 'Survived', col = 'Sex')
plt.show()
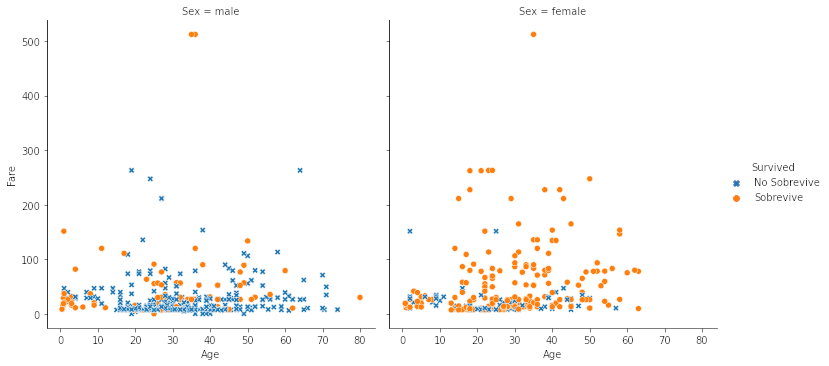
- Rango de tarifa más grande para el caso de mujeres
- Parece ser que pagar una tarifa extremadamente alta implicó salvarse.
Si revisamos quienes pagaron más de $240 dolares notamos que la mayoría sobrevive.
df.query('Fare > 240')
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Signing_date | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||
| 28 | No Sobrevive | 1 | Fortune, Mr. Charles Alexander | male | 19.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S | 1912-03-02 | Mr |
| 89 | Sobrevive | 1 | Fortune, Miss. Mabel Helen | female | 23.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S | 1911-10-27 | Miss |
| 119 | No Sobrevive | 1 | Baxter, Mr. Quigg Edmond | male | 24.0 | 0 | 1 | PC 17558 | 247.5208 | B58 B60 | C | 1911-09-28 | Mr |
| 259 | Sobrevive | 1 | Ward, Miss. Anna | female | 35.0 | 0 | 0 | PC 17755 | 512.3292 | NaN | C | 1911-11-16 | Miss |
| 300 | Sobrevive | 1 | Baxter, Mrs. James (Helene DeLaudeniere Chaput) | female | 50.0 | 0 | 1 | PC 17558 | 247.5208 | B58 B60 | C | 1912-02-12 | Mrs |
| 312 | Sobrevive | 1 | Ryerson, Miss. Emily Borie | female | 18.0 | 2 | 2 | PC 17608 | 262.3750 | B57 B59 B63 B66 | C | 1911-12-07 | Miss |
| 342 | Sobrevive | 1 | Fortune, Miss. Alice Elizabeth | female | 24.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S | 1912-02-28 | Miss |
| 439 | No Sobrevive | 1 | Fortune, Mr. Mark | male | 64.0 | 1 | 4 | 19950 | 263.0000 | C23 C25 C27 | S | 1912-01-01 | Mr |
| 680 | Sobrevive | 1 | Cardeza, Mr. Thomas Drake Martinez | male | 36.0 | 0 | 1 | PC 17755 | 512.3292 | B51 B53 B55 | C | 1911-11-09 | Mr |
| 738 | Sobrevive | 1 | Lesurer, Mr. Gustave J | male | 35.0 | 0 | 0 | PC 17755 | 512.3292 | B101 | C | 1911-08-05 | Mr |
| 743 | Sobrevive | 1 | Ryerson, Miss. Susan Parker "Suzette" | female | 21.0 | 2 | 2 | PC 17608 | 262.3750 | B57 B59 B63 B66 | C | 1912-03-13 | Miss |
- Lesurer: Sirviente de Cardeza, después sirvió en WW I.
- Ward: Era una empleada
- Cardeza: Fue un abogado de renombre.
Extracción de Variables
Muchas veces las variables entregadas no son tan informativas y es necesario algún proceso de extracción para poder encontrar algo que sea más significativo. En este caso trabajaremos cone el campo Name y extraeremos el título:
df.Name
PassengerId
1 Braund, Mr. Owen Harris
2 Cumings, Mrs. John Bradley (Florence Briggs Th...
3 Heikkinen, Miss. Laina
4 Futrelle, Mrs. Jacques Heath (Lily May Peel)
5 Allen, Mr. William Henry
...
887 Montvila, Rev. Juozas
888 Graham, Miss. Margaret Edith
889 Johnston, Miss. Catherine Helen "Carrie"
890 Behr, Mr. Karl Howell
891 Dooley, Mr. Patrick
Name: Name, Length: 891, dtype: object
df['Title'] = [x.split(', ')[1].split('.')[0] for x in df.Name]
df.groupby('Title').Survived.value_counts()
Title Survived
Capt No Sobrevive 1
Col No Sobrevive 1
Sobrevive 1
Don No Sobrevive 1
Dr No Sobrevive 4
Sobrevive 3
Jonkheer No Sobrevive 1
Lady Sobrevive 1
Major No Sobrevive 1
Sobrevive 1
Master Sobrevive 23
No Sobrevive 17
Miss Sobrevive 127
No Sobrevive 55
Mlle Sobrevive 2
Mme Sobrevive 1
Mr No Sobrevive 436
Sobrevive 81
Mrs Sobrevive 99
No Sobrevive 26
Ms Sobrevive 1
Rev No Sobrevive 6
Sir Sobrevive 1
the Countess Sobrevive 1
Name: Survived, dtype: int64
Es tremendamente interesante que al realizar esta descomposición encontramos personajes importantes, como por ejemplo, viajo una condeza o algunas personas del Ejercito: Peuchen sobrevivió y fue un Mayor de Ejército que cortó cuerdas en botes de rescate que quedarona atascados (se muestra algo de eso en la película, no con soldados, pero hay) y el caso de Butt, fue una de las personas que fue al salón de fumadores a esperar su muerte (también sale en la película).
ind = df.Name.str.contains('Countess')
df[ind]
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Signing_date | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||
| 760 | Sobrevive | 1 | Rothes, the Countess. of (Lucy Noel Martha Dye... | female | 33.0 | 0 | 0 | 110152 | 86.5 | B77 | S | 1911-04-12 | the Countess |
ind = df.Name.str.contains('Major')
df[ind]
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Signing_date | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||||
| 450 | Sobrevive | 1 | Peuchen, Major. Arthur Godfrey | male | 52.0 | 0 | 0 | 113786 | 30.50 | C104 | S | 1912-03-11 | Major |
| 537 | No Sobrevive | 1 | Butt, Major. Archibald Willingham | male | 45.0 | 0 | 0 | 113050 | 26.55 | B38 | S | 1911-12-21 | Major |
¿Sobrevivientes por lugar de Embarque?
df.groupby('Embarked').Survived.value_counts(normalize = True)
Embarked Survived
C Sobrevive 0.553571
No Sobrevive 0.446429
Q No Sobrevive 0.610390
Sobrevive 0.389610
S No Sobrevive 0.663043
Sobrevive 0.336957
Name: Survived, dtype: float64
¿Realmente Jack debia morir?
Una vez que hemos analizado los datos y ver que algunas cosas mostradas en la película realmente ocurrieron, me gustaría determinar mediante un modelo predictivo si es que Jack y Rose debían morir o sobrevivir respectivamente. Para ello generaremos un modelo de Machine Learning que nos permita determinar si estuvo bien la decisión de James Cameron o no.
X = df[['Pclass','Embarked','Sex','Title','SibSp','Parch', 'Fare','Age']]
y = df.Survived
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 123)
X_train.dtypes
Pclass int64
Embarked object
Sex object
Title object
SibSp int64
Parch int64
Fare float64
Age float64
dtype: object
Es una buena práctica revisar los tipos de dato de cada variable para hacer más eficiente el proceso de modelación además de ser útil para aplicar distintos tipos de preprocesamiento al momento de modelar.
pass_var = X_train[['Pclass']].columns
is_cat = X_train[['Embarked','Sex','Title']].columns
is_num = X_train.select_dtypes(np.number).drop(columns = ['Pclass']).columns
from sklearn.preprocessing import StandardScaler
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.tree import plot_tree, export_graphviz
from sklearn.metrics import classification_report
import graphviz
from sklearn import set_config
set_config(display = 'diagram')
num = Pipeline(steps = [
('imp_num', SimpleImputer(strategy = 'mean')),
('sc', StandardScaler())
])
cat = Pipeline(steps = [
('imp_cat', SimpleImputer(strategy = 'most_frequent')),
('ohe', OrdinalEncoder())
])
prep = ColumnTransformer(transformers = [
('pass', 'passthrough', pass_var),
('num', num, is_num),
('cat',cat, is_cat)
])
pipe = Pipeline(steps = [
('prep', prep),
('model', DecisionTreeClassifier(random_state = 123, ccp_alpha = 0.01))
])
pipe.fit(X_train, y_train)
El Pipeline determina cómo se tratarán las variables categóricas, numéricas y pass. Es importante recalcar que el último paso de un Pipeline siempre debe ser el modelo.
Pipeline(steps=[('prep',
ColumnTransformer(transformers=[('pass', 'passthrough',
Index(['Pclass'], dtype='object')),
('num',
Pipeline(steps=[('imp_num',
SimpleImputer()),
('sc',
StandardScaler())]),
Index(['SibSp', 'Parch', 'Fare', 'Age'], dtype='object')),
('cat',
Pipeline(steps=[('imp_cat',
SimpleImputer(strategy='most_frequent')),
('ohe',
OrdinalEncoder())]),
Index(['Embarked', 'Sex', 'Title'], dtype='object'))])),
('model',
DecisionTreeClassifier(ccp_alpha=0.01, random_state=123))])ColumnTransformer(transformers=[('pass', 'passthrough',
Index(['Pclass'], dtype='object')),
('num',
Pipeline(steps=[('imp_num', SimpleImputer()),
('sc', StandardScaler())]),
Index(['SibSp', 'Parch', 'Fare', 'Age'], dtype='object')),
('cat',
Pipeline(steps=[('imp_cat',
SimpleImputer(strategy='most_frequent')),
('ohe', OrdinalEncoder())]),
Index(['Embarked', 'Sex', 'Title'], dtype='object'))])Index(['Pclass'], dtype='object')
passthrough
Index(['SibSp', 'Parch', 'Fare', 'Age'], dtype='object')
SimpleImputer()
StandardScaler()
Index(['Embarked', 'Sex', 'Title'], dtype='object')
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
DecisionTreeClassifier(ccp_alpha=0.01, random_state=123)
y_pred_train= pipe.predict(X_train)
y_pred = pipe.predict(X_test)
print(classification_report(y_train, y_pred_train))
print(classification_report(y_test, y_pred))
precision recall f1-score support
No Sobrevive 0.83 0.85 0.84 435
Sobrevive 0.76 0.73 0.75 277
accuracy 0.81 712
macro avg 0.80 0.79 0.79 712
weighted avg 0.81 0.81 0.81 712
precision recall f1-score support
No Sobrevive 0.86 0.84 0.85 114
Sobrevive 0.74 0.77 0.75 65
accuracy 0.82 179
macro avg 0.80 0.81 0.80 179
weighted avg 0.82 0.82 0.82 179
Los valores de Accuracy del Modelo dan ~80% lo cual es un resultado decente. Una vez el modelo está entrenado, la idea sería predecir qué sucedería con Jack y Rose. Para ello es necesario rescatar información respecto a ellos. Para eso nuestra fuente será Wikipedia


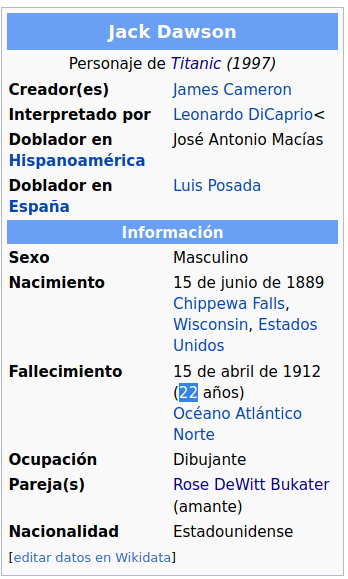
data = pd.DataFrame([[3, 'S', 'male','Mr',0,0,0,22],
[1,'S','female','Ms',0,1,250,17]],
columns = X_train.columns,
index = ['Jack','Rose'])
data
| Pclass | Embarked | Sex | Title | SibSp | Parch | Fare | Age | |
|---|---|---|---|---|---|---|---|---|
| Jack | 3 | S | male | Mr | 0 | 0 | 0 | 22 |
| Rose | 1 | S | female | Ms | 0 | 1 | 250 | 17 |
pipe.predict(data)
array(['No Sobrevive', 'Sobrevive'], dtype=object)
Es claro, James Cameron tenía razón, a pesar de que hubiera sido bonito que ambos se salvaran y vivieran su vida juntos, los datos respaldan la decisión de Cameron. El ser hombre y de 3era clase problamente pesó mucho al momento de supervivencia y su caballerosidad primó para que Rose viviera y él no.
Otro punto interesante que tienen los árboles de decisión es que permiten ser interpretados. A continuación se muestra el árbol de decisión que utiliza el modelo para escoger sus predicciones:
var_names = list(pass_var)+list(is_num)+list(is_cat)
plt.figure(figsize = (20,10))
dot_data = export_graphviz(pipe.named_steps.model,
feature_names= list(pass_var)+list(is_num)+list(is_cat),
class_names = ['N','Y'], filled = True, proportion = True)
graphviz.Source(dot_data)

- Sex: 1 = F, 2 = M
- Age: -1.322 = 13 años
- SibSp: 1.784= 2.5 personas.
Espero que esto ayude a entender un poco como llevar a cabo un proyecto de Data Science Express.